车牌识别具有广泛的应用前景,基于传统方法的车牌识别效果一般比较差,随着计算机视觉技术的快速发展,深度学习的方法能够更好的完成车牌识别任务。
本文提供了车牌识别方案的部署链接,您可以在网页上体验该模型的效果:车牌识别方案在线体验
本文介绍了使用PaddleOCR完成车牌识别任务的方法,其检测效果如下图:
原图如下:

检测结果如下:

目录
一、概述
二、使用
1、数据集准备
2、检测模型
3、识别模型
4、模型导出
5、联合推理
三、总结
附录:
一、概述
基于深度学习的车牌识别任务可以拆解为2个步骤:车牌检测-车牌识别。其中车牌检测的目的是确认图片中车牌的位置,根据检测到的车牌位置把图片中的ROI裁剪出来,车牌识别算法用于识别裁剪出的车牌图像中的具体内容。
本文使用PaddleOCR工具实现了车牌识别任务,首先使用PaddleOCR的检测算法DBNet检测出车牌位置,再将车牌位置裁剪送入文本识别算法CRNN来识别车牌的具体内容。
PaddleOCR github:https://github.com/PaddlePaddle/PaddleOCR.git
二、使用
1、数据集准备
本文选择的数据集为CCPD2020,下载链接为:CCPD2020(New energy plate) - 飞桨AI Studio
CPPD数据集的图片文件名具有特殊规则,具体规则如下:
例如: 025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg
每个名称可以分为七个字段,以-符号作为分割。这些字段解释如下。
-
025:车牌面积与整个图片区域的面积比。025 (25%)
-
95_113:水平倾斜程度和垂直倾斜度。水平 95度 垂直 113度
-
154&383_386&473:左上和右下顶点的坐标。左上(154,383) 右下(386,473)
-
386&473_177&454_154&383_363&402:整个图像中车牌的四个顶点的精确(x,y)坐标。这些坐标从右下角顶点开始。(386,473) (177,454) (154,383) (363,402)
-
0_0_22_27_27_33_16:CCPD中的每个图像只有一个车牌。每个车牌号码由一个汉字,一个字母和五个字母或数字组成。有效的中文车牌由七个字符组成:省(1个字符),字母(1个字符),字母+数字(5个字符)。“ 0_0_22_27_27_33_16”是每个字符的索引。这三个数组定义如下。每个数组的最后一个字符是字母O,而不是数字0。我们将O用作“无字符”的符号,因为中文车牌字符中没有O。因此以上车牌拼起来即为 皖AY339S
-
37:牌照区域的亮度。 37 (37%)
-
15:车牌区域的模糊度。15 (15%)
下载好了数据集,需要把数据集转换为PaddleOCR需要的标注格式,代码如下(修改图片的存储路径为自己的路径):
import cv2
import os
import json
from tqdm import tqdm
import numpy as npprovinces = ["皖", "沪", "津", "渝", "冀", "晋", "蒙", "辽", "吉", "黑", "苏", "浙", "京", "闽", "赣", "鲁", "豫", "鄂", "湘", "粤", "桂", "琼", "川", "贵", "云", "藏", "陕", "甘", "青", "宁", "新", "警", "学", "O"]
alphabets = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', 'O']
ads = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'J', 'K', 'L', 'M', 'N', 'P', 'Q', 'R', 'S', 'T', 'U', 'V', 'W', 'X', 'Y', 'Z', '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'O']def make_label(img_dir, save_gt_folder, phase):crop_img_save_dir = os.path.join(save_gt_folder, phase, 'crop_imgs')os.makedirs(crop_img_save_dir, exist_ok=True)f_det = open(os.path.join(save_gt_folder, phase, 'det.txt'), 'w', encoding='utf-8')f_rec = open(os.path.join(save_gt_folder, phase, 'rec.txt'), 'w', encoding='utf-8')i = 0for filename in tqdm(os.listdir(os.path.join(img_dir, phase))):str_list = filename.split('-')if len(str_list) < 5:continuecoord_list = str_list[3].split('_')txt_list = str_list[4].split('_')boxes = []for coord in coord_list:boxes.append([int(x) for x in coord.split("&")])boxes = [boxes[2], boxes[3], boxes[0], boxes[1]]lp_number = provinces[int(txt_list[0])] + alphabets[int(txt_list[1])] + ''.join([ads[int(x)] for x in txt_list[2:]])# detdet_info = [{'points':boxes, 'transcription':lp_number}]f_det.write('{}\t{}\n'.format(os.path.join(phase, filename), json.dumps(det_info, ensure_ascii=False)))# recboxes = np.float32(boxes)img = cv2.imread(os.path.join(img_dir, phase, filename))# crop_img = img[int(boxes[:,1].min()):int(boxes[:,1].max()),int(boxes[:,0].min()):int(boxes[:,0].max())]crop_img = get_rotate_crop_image(img, boxes)crop_img_save_filename = '{}_{}.jpg'.format(i,'_'.join(txt_list))crop_img_save_path = os.path.join(crop_img_save_dir, crop_img_save_filename)cv2.imwrite(crop_img_save_path, crop_img)f_rec.write('{}/crop_imgs/{}\t{}\n'.format(phase, crop_img_save_filename, lp_number))i+=1f_det.close()f_rec.close()def get_rotate_crop_image(img, points):'''img_height, img_width = img.shape[0:2]left = int(np.min(points[:, 0]))right = int(np.max(points[:, 0]))top = int(np.min(points[:, 1]))bottom = int(np.max(points[:, 1]))img_crop = img[top:bottom, left:right, :].copy()points[:, 0] = points[:, 0] - leftpoints[:, 1] = points[:, 1] - top'''assert len(points) == 4, "shape of points must be 4*2"img_crop_width = int(max(np.linalg.norm(points[0] - points[1]),np.linalg.norm(points[2] - points[3])))img_crop_height = int(max(np.linalg.norm(points[0] - points[3]),np.linalg.norm(points[1] - points[2])))pts_std = np.float32([[0, 0], [img_crop_width, 0],[img_crop_width, img_crop_height],[0, img_crop_height]])M = cv2.getPerspectiveTransform(points, pts_std)dst_img = cv2.warpPerspective(img,M, (img_crop_width, img_crop_height),borderMode=cv2.BORDER_REPLICATE,flags=cv2.INTER_CUBIC)dst_img_height, dst_img_width = dst_img.shape[0:2]if dst_img_height * 1.0 / dst_img_width >= 1.5:dst_img = np.rot90(dst_img)return dst_imgimg_dir = 'CCPD2020/ccpd_green' # 改成自己的路径
save_gt_folder = 'CCPD2020/PPOCR' # 改成自己的路径
# phase = 'train' # change to val and test to make val dataset and test dataset
for phase in ['train','val','test']:make_label(img_dir, save_gt_folder, phase)2、检测模型
准备好了数据集,首先需要训练车牌检测模型,这里我们使用PaddleOCR提供的文本检测预训练模型进行fine-tuning,这样可以减少训练时间,首先下载预训练检测模型(先进入PaddleOCR文件夹):
mkdir models
cd models
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_distill_train.tar
tar -xf ch_PP-OCRv3_det_distill_train.tar
cd PaddleOCR下载好了预训练模型,下面训练检测模型(其中的data_dir和label_file_list换成自己的数据集路径):
python tools/train.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \Global.pretrained_model=models/ch_PP-OCRv3_det_distill_train/student.pdparams \Global.save_model_dir=output/CCPD/det \Global.eval_batch_step="[0, 772]" \Optimizer.lr.name=Const \Optimizer.lr.learning_rate=0.0005 \Optimizer.lr.warmup_epoch=0 \Train.dataset.data_dir=CCPD2020/ccpd_green \Train.dataset.label_file_list=[CCPD2020/PPOCR/train/det.txt] \Eval.dataset.data_dir=CCPD2020/ccpd_green \Eval.dataset.label_file_list=[CCPD2020/PPOCR/test/det.txt]训练好了模型以后,可以使用下面的命令验证一下精度(此步可以跳过,也要更换data_dir和label_file_list路径):
python tools/eval.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \Global.pretrained_model=output/CCPD/det/best_accuracy.pdparams \Eval.dataset.data_dir=CCPD2020/ccpd_green \Eval.dataset.label_file_list=[CCPD2020/PPOCR/test/det.txt]可以使用如下命令来实现检测模型推理(路径修改为自己需要的路径):
python3 tools/infer_det.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml \-o Global.infer_img="src.jpg" Global.pretrained_model="./output/CCPD/det/best_accuracy" \PostProcess.box_thresh=0.6 PostProcess.unclip_ratio=2.03、识别模型
训练好了检测模型,再来训练识别模型,同样先下载预训练权重再fine-tuning,下载权重命令如下:
mkdir models
cd models
wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_train.tar
tar -xf ch_PP-OCRv3_rec_train.tar
cd PaddleOCR这个权重中包含不需要的内容(Teacher的权重),需要提取需要的权重:
import paddle
# 加载预训练模型
all_params = paddle.load("models/ch_PP-OCRv3_rec_train/best_accuracy.pdparams")
# 查看权重参数的keys
print(all_params.keys())
# 学生模型的权重提取
s_params = {key[len("Student."):]: all_params[key] for key in all_params if "Student." in key}
# 查看学生模型权重参数的keys
print(s_params.keys())
# 保存
paddle.save(s_params, "models/ch_PP-OCRv3_rec_train/student.pdparams")开启训练(注意路径):
python tools/train.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \Global.pretrained_model=models/ch_PP-OCRv3_rec_train/student.pdparams \Global.save_model_dir=output/CCPD/rec/ \Global.eval_batch_step="[0, 90]" \Optimizer.lr.name=Const \Optimizer.lr.learning_rate=0.0005 \Optimizer.lr.warmup_epoch=0 \Train.dataset.data_dir=CCPD2020/PPOCR \Train.dataset.label_file_list=[PPOCR/train/rec.txt] \Eval.dataset.data_dir=CCPD2020/PPOCR \Eval.dataset.label_file_list=[PPOCR/test/rec.txt]验证精度:
python tools/eval.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \Global.pretrained_model=output/CCPD/rec/best_accuracy.pdparams \Eval.dataset.data_dir=CCPD2020/PPOCR \Eval.dataset.label_file_list=[PPOCR/test/rec.txt]使用如下命令测试识别模型的效果(需要注意的是,识别模型的输入是车牌号图片,不是完整的图片,可以使用数据集处理时的PPOCR文件夹内生成的裁剪后的车牌图片):
python3 tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="output/CCPD/det/infer" --image_dir="/home/aistudio/src.jpg" --use_gpu=True4、模型导出
上面训练好的模型都是动态图模型,将他们导出为静态图模型来部署,可以加快速度,首先导出检测模型:
python tools/export_model.py -c configs/det/ch_PP-OCRv3/ch_PP-OCRv3_det_student.yml -o \Global.pretrained_model=output/CCPD/det/best_accuracy.pdparams \Global.save_inference_dir=output/CCPD/det/infer测试一下导出的检测模型推理效果(注意图片路径):
python3 tools/infer/predict_det.py --det_algorithm="DB" --det_model_dir="output/CCPD/det/infer" --image_dir="src.jpg" --use_gpu=True下面导出识别模型:
python tools/export_model.py -c configs/rec/PP-OCRv3/ch_PP-OCRv3_rec.yml -o \Global.pretrained_model=output/CCPD/rec/best_accuracy.pdparams \Global.save_inference_dir=output/CCPD/rec/infer测试一下导出的识别模型推理效果(注意图片路径):
python3 tools/infer/predict_rec.py --image_dir="PPOCR/test/crop_imgs" \--rec_model_dir="output/CCPD/rec/infer" --rec_image_shape="3, 48, 320" --rec_char_dict_path="ppocr/utils/ppocr_keys_v1.txt"5、联合推理
训练好了检测和识别模型,下面就是联合推理,测试效果,命令如下(det_model_dir和rec_model_dir是上面导出的模型文件夹):
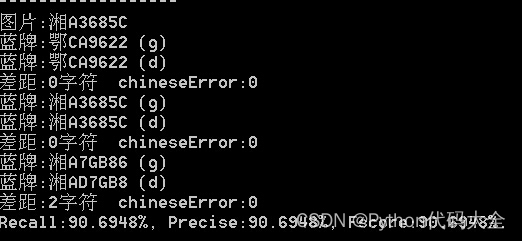
python tools/infer/predict_system.py \--det_model_dir=output/CCPD/det/infer/ \--rec_model_dir=output/CCPD/rec/infer/ \--image_dir="src.jpg" \--rec_image_shape=3,48,320这是识别的结果:

三、总结
本文总结了PaddleOCR提供的车牌识别方案,并进行了简化,根据识别的结果来看可以很好地检测车牌图像。
附录:
PaddleOCR轻量级车牌识别方案
本文提供了车牌识别方案的部署链接,您可以再网页上体验该模型的效果:
车牌识别方案在线体验













![[网络安全自学篇] 一.入门笔记之看雪Web安全学习及异或解密示例](http://lovexiaoluo.com/1011111.jpg)
