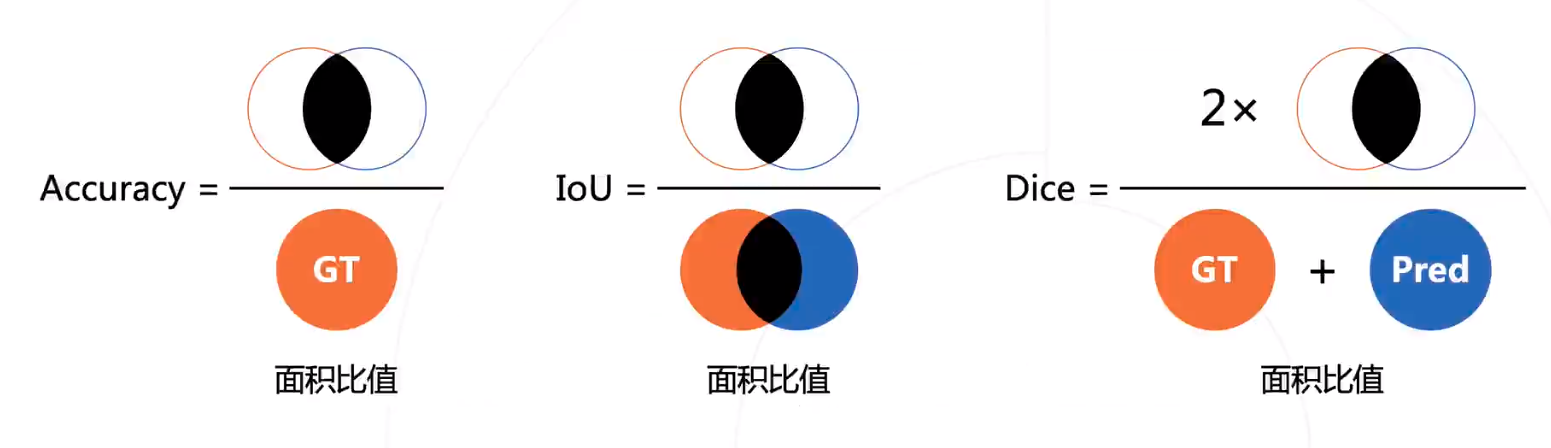
常用云检测数据集信息及下载
- 1.LandSat7云量评估数据集
- 2.LandSat8-Biome生物群落云量评估数据集
- 3.LandSat8-38Cloud数据集
- 4.高分系列-GF1-WHU遥感影像云数据集
- 5.Sentinel-2 Cloud Mask Catalogue
- 5.1.数据介绍
- 5.2.数据集目录编排
- 5.3.统计数据
- 5.4.错误和不确定性
- 6.CESBIO数据集(Sentinel-2)
- 6.1.数据介绍
- 6.2.数据集目录编排
- 6.3.数据描述
- 7.GSFC(LanSat8, Sentinel2)
- 8.Hollstein dataset (Sentinel-2)
- 8.1.数据介绍
- 8.2.数据描述
- 9.Pixbox(LanSat8, Sentinel2)
- 9.1.PixBox Sentinel-2
- 9.1.1.数据介绍
- 9.1.2.数据集目录编排
- 9.1.3.数据描述
- 9.2.PixBox Landsat 8
- 9.2.1.数据介绍
- 9.2.2.数据集目录编排
- 9.2.3.数据描述
- 10.SPARCS Cloud Dataset
- 10.1.数据介绍
- 10.2.数据描述
1.LandSat7云量评估数据集
数据下载
该集合包含206 个Landsat 7增强型主题映射器(ETM +)1G级场景,显示在以下生物群系中。手动生成的云遮罩用于训练和验证云覆盖评估算法,该算法又用于计算每个场景中云覆盖的百分比。 最初报告为207个Mask,但错误地计算了一个。
来自此数据集的102个场景用于Foga,Scaramuzza等人中描述的云验证研究中
[Foga, S., Scaramuzza, P.L., Guo, S., Zhu, Z., Dilley, R.D., Beckmann, T., Schmidt, G.L., Dwyer, J.L., Hughes, M.J. & Laue, B. (2017). Cloud detection algorithm comparison and validation for operational Landsat data products. Remote Sensing of Environment, 194, 379-390. ](doi: 10.1016/j.rse.2017.03.026.)
每个文件包含.TIF格式的1级数据带文件、元数据文件(MTL.txt)和.TIF格式的手动掩码。
每个手动掩码中的位解释如下:
| Value | Interpretation |
|---|---|
| 0 | Fill |
| 64 | Cloud Shadow |
| 128 | Clear |
| 192 | Thin Cloud |
| 255 | Cloud |
2.LandSat8-Biome生物群落云量评估数据集
数据下载
该集合包含96个Landsat 8操作性陆地成像仪(OLI)热红外传感器(TIRS)地形校正(Level-1T)场景,显示在以下生物群系中。手动生成的云遮罩用于验证云覆盖评估算法,该算法又用于计算每个场景中云覆盖的百分比。
每个文件都包含.TIF格式的Landsat 8 Level-1数据带文件,质量带.TIF文件,元数据文件(MTL.txt)和.img(ENVI)格式的手动掩码。
CCA:cloud cover assessment (CCA)
近似云状态列使用以下指南表示每个场景的估计云百分比:
| 场景云量等级 | 条件 |
|---|---|
| Clear | 低于35% |
| Mid Cloud | 35%-65% |
| Cloudy | 高于65% |
| 每个手动掩码中的位解释如下: | |
| Value | Interpretation |
| – | – |
| 0 | Fill |
| 64 | Cloud Shadow |
| 128 | Clear |
| 192 | Thin Cloud |
| 255 | Cloud |
3.LandSat8-38Cloud数据集
数据下载
这些场景的整个图像被裁剪成多个384 384碎片,适用于基于深度学习的语义分割算法。每个碎片具有4个相应的光谱通道,其为红色(带4),绿色(带3),蓝色(带2)和近红外(带5)。与其他计算机视觉图像不同,这些通道不会组合在一起。相反,它们对应于目录中。
该数据集包含38个Landsat 8场景图像及其手动提取的像素级地面真相,用于进行云检测。
这些场景的整个图像被裁剪为多个384384个补丁,以适合于基于深度学习的语义分割算法。有用于训练的8400补丁和用于测试的9201补丁。每个贴片具有4个对应的光谱通道,分别是红色(波段4),绿色(波段3),蓝色(波段2)和近红外(波段5)。与其他计算机视觉图像不同,这些通道不会合并在一起。相反,它们位于其对应目录中。
- 薄云(薄雾)也被视为云(以及厚云)。
- 自然彩色图像是用于进一步可视化目的的伪彩色图像。在[1]和[2]的训练和测试阶段尚未使用它们。
- 一些补丁中没有有用的信息(0像素值)。这是因为Landsat 8图像周围的黑色空白。为方便起见,可以在数据集文件夹或此处,找到csv文件(training_patches_38-cloud_nonempty.csv)中的列表,其中包括信息性补丁的名称(信息性像素/非零像素超过80%的补丁)
- training_patches_38-Cloud.csv文件存了每个patch的后缀,因此同一个patch,主要是前缀green、blue、red、nir、gt的不同
4.高分系列-GF1-WHU遥感影像云数据集
下载地址:
百度网盘-密码rbwb
Google Drive
其中包括108个GF-1宽视野(WFV)2A级场景及其参考云和云阴影遮罩。利用这些数据集对MFC算法在GF-1wfv云和云影检测中的性能进行了评价。全球分布的验证图像采集于2013年5月至2016年8月。参考遮罩是由经验丰富的用户目测后手工绘制云/云影边界得到的。
场景在中提供。焦油.gz格式,以及.tif fromat中的掩码,其中每个像素值表示:
| Value | Interpretation |
|---|---|
| 0 | Fill |
| 1 | Clear |
| 128 | Cloud Shadow |
| 255 | Cloud |
5.Sentinel-2 Cloud Mask Catalogue
数据下载
5.1.数据介绍
该数据集包含513个1022 × 1022像素子场景的云遮罩,分辨率为20米,随机采样自2018年1c级Sentinel-2存档。这个数据集的设计遵循了一些关于云遮蔽的观察
- 整个产品的性能是高度相关的,因此子场景比全场景提供更多的像素值,
- 当前的云掩蔽数据集往往集中在特定的区域,或手动选择使用的产品,这引入了数据集的偏差,不能代表真实世界的数据,
- 云遮罩性能似乎与表面类型和云结构高度相关,因此测试应包括与这些变量相关的失效模式分析。使用IRIS工具包对数据进行半自动注释,该工具包允许用户动态训练Random Forest(使用LightGBM实现),通过迭代改进预测来加快注释速度,但保留了注释器在需要时进行最终手工更改的能力。这种混合方法使我们能够处理比手动更多的遮罩,我们认为这对于创建一个足够大的数据集来近似整个Sentinel-2存档的统计数据至关重要。
除了像素级3类(CLEAR, CLOUD, CLOUD_SHADOW)分割遮罩,我们还为用户提供了每个子场景的二进制分类“标签”,可以用于测试,以确定在特定情况下的性能。这些包括: - 表面类型:11类
- 云类型:7类
- 相对云高度:低,高
- 云厚度:薄,厚
- 云范围:孤立,延伸
在实际应用中,云的阴影也被注释,然而这有时是不可能的,因为高地形,或大的歧义。总共有424个阴影被标记(如果存在),89个阴影由于非常模糊的阴影边界或地形投射显著的阴影而无法标注。如果用户希望训练一个算法专门为云阴影的淹掩模,我们建议他们清除那些影子89图像是不可能的,但是,记住,这将系统地减少阴影类相比,实际使用的难度,因为这些例子包含最困难的影子。除了采样的20m的子场景和蒙版,我们还为用户提供了定义蒙版在原始Sentinel-2场景上的边界的shapefile。如果用户希望以原来的分辨率检索L1C频带,他们可以使用这些。
5.2.数据集目录编排

- classification_tags.csv
csv文件包含几个对用户有帮助的参数。所有的分类标签都是非排他的,仅仅意味着给定的子场景包含了该特征的一部分。例如,被雪覆盖的山顶在较低的山谷中有森林,将被标记为森林/丛林、雪/冰和小山/山脉。类似地,同一映像中可以存在多个云类型。所有标签都是通过对图像和SURFACE TYPE的其他高分辨率图像(如BingMaps和谷歌Earth)的目视检查确定的。这种客观的分类是不可能的,我们这里所有的分类都是用主观判断来进行的。我们将每一列(分为多个大类)描述如下- 一般信息
- Scene:字符串,Sentinel-2产品ID。
- difficulty:int,从1->5为标注难度的主观度量。
-
- 近乎完美的
-
- 非常好的
-
- 大多好
-
- 可能是一些小错误。
-
- annotator:两个注释器中,A还是B,创建了mask /中使用的掩码(注意,alt_masks/可能包含其他注释器的掩码,如果两者都标记了该子场景)。
- Shadows_marked: boolean,如果为0则没有阴影标记。如果1,阴影被标记在存在的地方。
- clear_percent: float, 0 -> 100 for percentage of pixels marked clear
- cloud_percent: float, 0 -> 100 for percentage of pixels marked cloud
- CLOUD shadow_percent: float, 0 -> 100 for percentage of pixels marked CLOUD_SHADOW
- dataset:字符串,表示子场景是否属于校准、主要或验证标签阶段的一部分(在“注释策略”章节中描述)
- 一般信息
- subscenes
每个子场景都是一个1022 × 1022 × 13 numpy数组,大气顶反射值作为float32数字。这些数据直接取自与它们同名的Sentinel-2 L1C产品,随机裁剪(但重新取样,直到找到一个没有任何无数据值的区域)。不在20m的波段使用双线性插值重新采样到20m。希望在原始分辨率使用波段的用户需要下载L1C产品,并使用提供的shapefile提取口罩区域。numpy数组的第三维Sentinel-2波段的顺序是按数字顺序排列的,8A波段位于8和9波段之间。根据Sentinel-2 L1C产品规范中的建议,所有值都是通过将原始L1C整数值除以10’000来检索反射率。请注意,许多值大于1,因为如果表面在一个角度接收到的光比表面在观察角度上可能的更多,表观反射率可能大于1。 - masks
每个掩码都是一个1022 × 1022 × 3的numpy数组,使用布尔热编码(每个像素在最后一个维度上都有一个True值)。最后一个维度中的类顺序是:CLEAR、CLOUD、CLOUD_SHADOW。即使阴影标记不可能为一个给定的子场景,第三通道仍然包括在内。掩码使用场景的相应产品id来命名。 - shapefiles
每个场景的Esri形状文件,描述所提取的子场景的多边形。如果用户需要,这些数据可以用于从Sentinel-2 L1C场景中提取原始频带数据。 - thumbnails
一组下采样的png图像,显示子场景,加上它们周围的一小块区域。不用于任何处理,包含它们是为了提供一种简单的方式来浏览数据 - alt_masks
对于两个注释器都进行了注释的场景(校准中10个注释器,验证中50个注释器——关于这个过程的更多细节,请参阅附录B),其他注释器掩码提供了完整性。这可用于验证我们使用它们执行的统计测试,或作为备份掩码,如果您发现了出于任何原因希望使用的掩码。选择是随机的,所以它们和那些在面具折叠中发现的一样有效
5.3.统计数据

5.4.错误和不确定性
不幸的是,云屏蔽是一项固有的模糊任务。当被构建为一个二元分割任务时,一个注释者必须决定如何区分云和清晰,他们的定义和另一个注释者的定义之间的差异是不可避免的。我们使用我们的校准流程来确保两个注释器尽可能相似,并且我们的决定尽可能一致。然而,错误仍然存在于整个数据集。其中一些是可以估计的,而另一些是已知的,但不一定可以解释。在本节中,我们首先概述一些不容易量化的已知问题,然后,我们使用一些统计指标来量化注释者之间的协议级别。
6.CESBIO数据集(Sentinel-2)
数据下载
论文出处
6.1.数据介绍
数据集为 38 个 Sentinel-2 场景提供了参考云掩码数据集。这些参考掩模是使用ALCD工具创建的,该工具由Louis Baetens开发,在CESBIO / CNES的Olivier Hagolle的指导下。它们的创建是为了验证MAJA软件生成的云掩码.
空间分辨率为60m
6.2.数据集目录编排
说明 每个场景目录的名称是相应 Sentinel-2 L1C 产品的名称。
在场景目录中,可以找到三个子目录。
- “分类Classification”
- “样本Samples`
- “统计Statistics”
6.3.数据描述
Classification/classification_map.tif
主产品,即分类场景。有7个类型可供选择。每个都用不同的整数表示。
- 0:no_data。
- 1:未使用。
- 2:低云。
- 3:高云。
- 4:云影。
- 5:土地。
- 6:水。
- 7:雪。
Classification/confidence_enhanced.tif
增强的分类置信度图。这些值介于 0 和 255 之间(以 1 位编码)。
对于每个像素,原始置信度图是多数类的投票比例,因为分类图是通过随机森林算法创建的。
中位数过滤器已应用于此置信度图。最后,该值保存在 1 位上,导致值介于 0 和 255 之间。
Classification/contours.png
分类地图中类的等值线,叠加在场景中。颜色代码取决于每个类别。
绿色:低云和高云。黄色:云影。蓝色:水。紫色:雪。
Classification/used_parameters.json
用于对场景进行分类的参数。它包括磁贴代码、模糊和清晰的日期,以及他们的产品参考。
Samples/
此目录包含所有 shapefile,每个类一个
Statistics/k_fold_summary.json
现场10倍交叉验证的结果。
按“metrics_names”中给出的顺序计算 5 个指标。“all_metrics”是 10 个折叠的列表,每个折叠的 5 个指标按正确的顺序排列。“均值”和“stds”是 10 倍的均值和标准差。
7.GSFC(LanSat8, Sentinel2)
数据下载
论文出处
GSFC云参考数据是通过NASA戈达德航天飞行中心(GSFC)收集的(Skakun等人,2021)。该地区非常不均匀,主要土地覆盖类别为森林(约52%)和不透水表面(31%),其中有自然植被斑块和耕地(总计17%)(图3)。NASA GSFC还有一个AERONET站(Holben等人,1998年),提供气溶胶光学厚度(AOT)和水蒸汽。2017年至2019年间,使用带有鱼眼镜头的智能手机摄像头采集了地面天空图像。这些数据是在陆地卫星8号和哨兵2号天桥期间手动收集的。收集了6个陆地卫星8和28个哨兵-2场景的参考数据。目的是捕捉各种云层条件和季节变化。将卫星图像标记为云、薄云(半透明)、阴影和透明类(图3)。由于云的确切边界存在很大的不确定性,尤其是在Sentinel-2图像上,云边界内的区域被排除在参考数据之外(Skakun等人,2021)。为了便于标记过程,Sentinel-2和Landsat 8图像以各种光谱组合呈现,包括真彩色(红-绿-蓝)和假彩色(近红外-红-绿,SWIR1-近红外-红),并使用卷云带(1.38μm)。Skakun等人(2021)对GSFC数据集进行了详细描述。
8.Hollstein dataset (Sentinel-2)
数据下载
论文出处
8.1.数据介绍
“S2 Hollstein数据集”是一个人工标记的哨兵2A云光谱数据库(Hollstein等人,2016)。通过不同的光谱工具,选择像素并将其分为以下六类之一(图4):云(不透明云)、卷云(卷云、半透明云和蒸汽轨迹)、雪(雪和冰)、阴影(来自云、卷云、山脉、建筑物等的阴影)、水(湖泊、河流、海洋)和晴空(其他剩余区域)。光谱工具包括Sentinel-2图像的假彩色合成、图像增强和光谱的图形可视化。其目的是创建具有均衡像素数的高度异构类。共有59个Sentinel-2场景和1593911个参考(标记)像素。
空间分辨率为20m
8.2.数据描述
我们的数据集总共由N = 5647725像素组成。像素信息保存在 HDF5 文件的不同表中。相对于 Sentinel-2 的空间和光谱分辨率:
- band 将band位置与其标签相关联
- 进一步的波段描述可以在bandwidth_nm,central_wavelength_nm和spatial_sampling_m相对于类中找到:
- classes (1xN 表)包括与数据集中的每个像素关联的类 ID
- class_ids描述了与class_names相对于光谱“中显示的每个类相关联的 id:
- spectra(13xN表)收集每个像素的光谱值。Sentinel-2仪器采样13个光谱波段。相对于图像元数据:
- 纬度和经度收集像素坐标
- 每个像素都位于一个granule_id中,其中几个颗粒对应于与product_id关联的图像。
- 同一产品将共享感应日期-日期-,四种不同的采样角度-sun_azimuth_angle,sun_zenith_angle,viewing_azimuth_angle,viewing_zenith_angle-和地理位置-大陆和国家。
9.Pixbox(LanSat8, Sentinel2)
PixBox的总体思想是对像素分类质量的定量评估,这是自动化算法/程序的结果。像素分类定义为为图像像素分配一定数量的属性,例如云,晴朗的天空,水,土地,内陆水,洪水,雪等。此类像素分类属性通常用于进一步指导更高级别的处理。
9.1.PixBox Sentinel-2
数据下载
9.1.1.数据介绍
PixBox-S2-CMIX数据集被用作2019年在委员会地球观测卫星(CEOS)校准与验证工作组(WGCV)内进行的第一个云掩码相互比较eXercise(CMIX)中的验证参考。PixBox-S2-CMIX像素集合在CMIX之前就已经存在,并且已经在2018年进行了。
PixBox-S2-CMIX 数据集是一个像素集合,包含从 29 个 Sentinel-2 A & B Level 1C 产品中手动收集的 17,351 个像素。数据集在空间、时间和主题上分布良好。
9.1.2.数据集目录编排
PixBox-S2-CMIX 数据集由两个主要的 ZIP 文件组成,一个保存像素集合和描述,另一个包含所有使用的 Sentinel-2 L1C 数据。数据集的结构如下:
- PixBox-S2-CMIX.zip
收集的要素(CSV 文件)。
所有类别和类别的描述,包括与使用的Sentinel-2 L1C产品的链接。 - 哨兵-2_L1C.zip
29 个压缩的哨兵-2 级 L1C 产品[1],用于生成数据集。
9.1.3.数据描述
- pixbox_sentinel2_cmix_20180425.csv
此文件包含所有收集的 CSV 格式的像素信息。所有收集的类都存储为整数值。类别的描述和类名的整数的定义在附加描述文件中给出。
- pixbox_sentinel2_cmix_20180425_description.txt
此文件提供了类别和类的清晰描述。它可用于将存储在 CSV 中的类 ID 号转换为类字符串。此外,它还将 CSV 中给出的卫星产品 ID 链接到 Sentinel-2 L1C 产品名称。
9.2.PixBox Landsat 8
数据下载
9.2.1.数据介绍
PixBox-L8-CMIX数据集被用作2019年在委员会地球观测卫星(CEOS)校准与验证工作组(WGCV)内进行的第一个云掩码相互比较eXercise(CMIX)中的验证参考。PixBox-L8-CMIX像素集合在CMIX之前就已经存在,并且已经在2015年进行了。
PixBox-L8-CMIX 数据集是一个像素集合,包含从 11 个 Landsat 8 Level 1 产品中手动收集的 18,830 个像素。数据集在时间上分布良好。在空间上,它主要集中在沿海地区,主要是在欧洲。从主题上讲,它侧重于沿海地区,但仍然代表陆地和水面。
9.2.2.数据集目录编排
PixBox-L8-CMIX 数据集由两个主要的 ZIP 文件组成,一个包含像素集合和描述,另一个包含所有使用的 Landsat 8 L1 数据。数据集的结构如下:
- PixBox-L8-CMIX.zip
收集的要素(CSV 文件)。
所有类别和类的说明,包括与所使用的Landsat 8 L1产品的链接。
- Landsat8_L1.zip
11 个压缩 Landsat 8 1 级产品[1],用于生成数据集。
9.2.3.数据描述
- pixbox_landsat8_cmix_20150527.csv
此文件包含所有收集的 CSV 格式的像素信息。所有收集的类都存储为整数值。类别的描述和类名的整数的定义在附加描述文件中给出。
- pixbox_landsat8_cmix_20150527_description.txt
此文件提供了类别和类的清晰描述。它可用于将存储在 CSV 中的类 ID 号转换为类字符串。此外,它还将 CSV 中给出的卫星产品 ID 链接到 Sentinel-2 L1C 产品名称。11 个采用 ZIP 格式的 Landsat 8 L1 产品。
10.SPARCS Cloud Dataset
数据下载
10.1.数据介绍
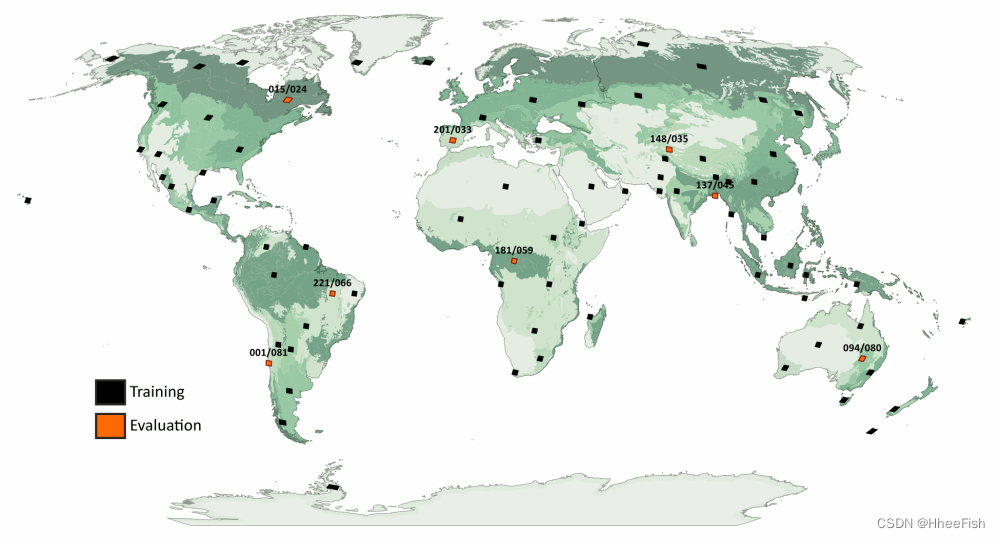
通过从 14 个世界野生动物基金会陆地主要栖息地类型中的每一个以及 7 个生物地理领域中的每一个的“内陆水域”和“岩石和冰”中选择一个场景来选择位置(64 个场景,并非所有栖息地类型都出现在每个领域) . 另外,每个随机选择的 MHT 的附加场景(最初用于测试算法)。
10.2.数据描述
对于 80 个场景中的每一个,zip 文件包含:
- *_labels.tif:编码的云、阴影、水、冰面具(代码见下文)。
- *_data.tif:1-10 波段子场景的原始 USGS 数据的 10 波段 geotiff。
- *_mtl.txt:整个场景的原始元数据文件(子场景的范围没有改变)
- *_photo.png : 发送给口译员的图像
- *_qmask.tif:子场景的原始 USGS 质量掩码
- *_c1bqa.tif:与子场景的 Collection 1 数据关联的质量掩码。有关这两个质量掩码之间差异的更多信息,请访问:QA 工具用户指南。请注意,LC81130672013142LGN01 未包含在 Collection 1 中,因此没有此文件。
| Mask Code | Feature | Mapped Color |
|---|---|---|
| 0 | Cloud Shadow | Black |
| 1 | Cloud Shadow over Water | Dk. Blue |
| 2 | Water | Blue |
| 3 | Ice/Snow | Cyan |
| 4 | Land | Grey |
| 5 | Clouds | White |
| 6 | Flooded | Gold |