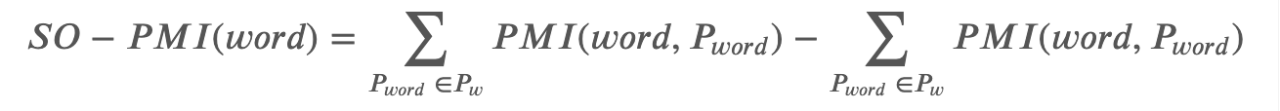本文主要是学习参考杨秀璋老师的博客,笔记总结。
原文链接
文章目录
- 书山有路勤为径,学海无涯苦作舟
- 原文链接
- 一.大连理工情感词典
- 二、七种情绪的计算
- 2.1 pandas读取数据
- 2.2 导入大连理工大学中文情感词典
- 2.3 统计七种情绪的分布情况
- 2.4 增加中文分词词典和自定义的停用词典
- 2.5 计算七种情绪特征值出现的频率
- 2.6 计算《庆余年》自定义数据集的七种情绪的分布
- 2.7 获取某种情绪
- 三、七种情绪的词云可视化
- 3.1词云的思想
- 3.2 统计七种情感词的的频次
- 3.3词云分析
- 四、自定义词典情感分析
- 五、SnowNLP庆余年情感分析
书山有路勤为径,学海无涯苦作舟

原文链接
原文链接
一.大连理工情感词典
情感的研究:情感分析 以及 情感的分类
情感分析的主要流程:
1)获取语料数据
2)对语料进行分词,标注词性
3)定义情感词典提取文本的情感吃
4)构建情感矩阵,计算情感分数
5)结果的评估
大致流程:

目前中国成熟的情感词典:
- 大连理工大学情感词汇本体库
- 知网的HowNet情感词典
- TW大学中文情感极性情感词典
- 等等
大连理工大学情感词典将情感分为:
1)乐
2)好
3)怒
4)哀
5)惧
6)恶
7)惊
分为7个大类,21个小类。
情感强度被设置为1,3,5,7,9五个等级。
情感的极性被分为:中性,褒义,贬义 。对应的计算机的编码分别为0,1,2。为了方便计算机情感计算,将贬义的极性值2改为-1。
词汇的情感值的计算公式为:

该中文情感词汇本体可解决:
- 多类别情感分类的问题
- 解决一般的倾向性分析的问题。
如下图所示,该词典共包括27466个词语,包含词语、词性种类、词义数、词义序号、情感分类、强度、极性、辅助情感分类、强度和极性:

情感分类:
一个情感词可能对应多个情感,情感分类就是对一个词存在的多种情感进行分类
辅助情感分类:
具有的主要情感以及含有的其他情感
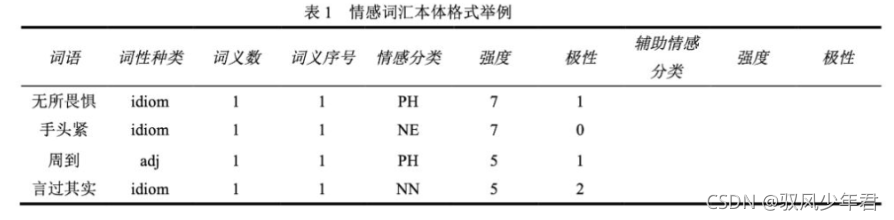
情感分类按照论文《情感词汇本体的构造》所述,情感分为7大类21 小类。情感强度分为1、3、5、7、9五档,9表示强度最大,1为强度最小。情感分类如下表所示:

情感词汇本体中词性的分类一共分为7种:
名词( noun )、动词(verb )、形容词( adj )、副词( adv )、网络词语( nw )、成语( idiom )、介词短语(prep )。
每个词在每一类情感下都对应了一个极性。0代表中性,1代表褒义,2代表贬义,3代表兼有褒贬两性。
否定词和程序副词,否定词会将情感强度乘以-1,程度副词代表不同级别的情感倾向。


二、七种情绪的计算
数据集,庆余年电视剧的电影评论,共计220条。
2.1 pandas读取数据
import pandas as pdf = open('','r',encoding = "utf8")weibo_df = pa.read_csv(f)
print(weibo_df)
输出结果:

主要的特征就是,用户名,id,以及用户评论。
2.2 导入大连理工大学中文情感词典
# coding: utf-8
import pandas as pd#-------------------------------------获取数据集---------------------------------
f = open('庆余年220.csv',encoding='utf8')
weibo_df = pd.read_csv(f)
print(weibo_df.head())#-------------------------------------情感词典读取-------------------------------
#注意:
#1.词典中怒的标记(NA)识别不出被当作空值,情感分类列中的NA都给替换成NAU
#2.大连理工词典中有情感分类的辅助标注(有NA),故把情感分类列改好再替换原词典中# 扩展前的词典
df = pd.read_excel('大连理工大学中文情感词汇本体NAU.xlsx')
print(df.head(10))df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()
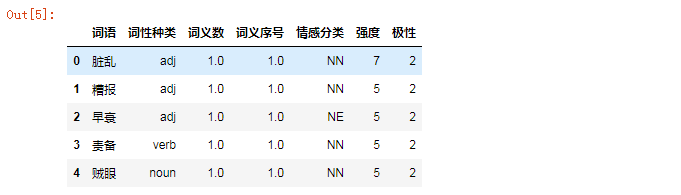
2.3 统计七种情绪的分布情况
情感词典中分别定义了所有情感词汇,及其分类。
定义不同情感分类的列表,将情感词典中的情感词,归类。
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []
初步设计积极情感和消极情感的值的计算规则:
Positive = Happy + Good + Surprise
Negative = Anger + Sad + Fear + Disgust
# coding: utf-8
import pandas as pd#-------------------------------------获取数据集---------------------------------
f = open('庆余年220.csv',encoding='utf8')
weibo_df = pd.read_csv(f)
print(weibo_df.head())#-------------------------------------情感词典读取-------------------------------
#注意:
#1.词典中怒的标记(NA)识别不出被当作空值,情感分类列中的NA都给替换成NAU
#2.大连理工词典中有情感分类的辅助标注(有NA),故把情感分类列改好再替换原词典中# 扩展前的词典
df = pd.read_excel('大连理工大学中文情感词汇本体NAU.xlsx')
print(df.head(10))df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()#-------------------------------------七种情绪的运用-------------------------------
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []#df.iterrows()功能是迭代遍历每一行
for idx, row in df.iterrows():if row['情感分类'] in ['PA', 'PE']:Happy.append(row['词语'])if row['情感分类'] in ['PD', 'PH', 'PG', 'PB', 'PK']:Good.append(row['词语']) if row['情感分类'] in ['PC']:Surprise.append(row['词语']) if row['情感分类'] in ['NB', 'NJ', 'NH', 'PF']:Sad.append(row['词语'])if row['情感分类'] in ['NI', 'NC', 'NG']:Fear.append(row['词语'])if row['情感分类'] in ['NE', 'ND', 'NN', 'NK', 'NL']:Disgust.append(row['词语'])if row['情感分类'] in ['NAU']: #修改: 原NA算出来没结果Anger.append(row['词语']) #正负计算不是很准 自己可以制定规则
Positive = Happy + Good + Surprise
Negative = Anger + Sad + Fear + Disgust
print('情绪词语列表整理完成')
print(Anger)
df.iterrows()的返回值:

遍历每个词,将情感分类到自己设置的七种情感的列表
情感词词典实例:
2.4 增加中文分词词典和自定义的停用词典
#---------------------------------------中文分词---------------------------------
import jieba
import time#添加使用者词典和停用词
jieba.load_userdict("user_dict.txt") #自定义分词词典
stop_list = pd.read_csv('stop_words.txt',engine='python',encoding='utf-8',delimiter="\n",names=['t'])['t'].tolist()
def txt_cut(juzi):return [w for w in jieba.lcut(juzi) if w not in stop_list] #可增加len(w)>1
没有用的停用词,没有任何意义,对情感也没有帮助,所以需要进行过滤:
2.5 计算七种情绪特征值出现的频率
情绪包括anger、disgust、 fear、sadness、surprise、good、happy
#---------------------------------------中文分词---------------------------------
import jieba
import time#添加自定义词典和停用词
#jieba.load_userdict("user_dict.txt")
stop_list = pd.read_csv('stop_words.txt',engine='python',encoding='utf-8',delimiter="\n",names=['t'])#获取重命名t列的值
stop_list = stop_list['t'].tolist()def txt_cut(juzi):return [w for w in jieba.lcut(juzi) if w not in stop_list] #可增加len(w)>1#---------------------------------------情感计算---------------------------------
def emotion_caculate(text):positive = 0negative = 0anger = 0disgust = 0fear = 0sad = 0surprise = 0good = 0happy = 0wordlist = txt_cut(text)#wordlist = jieba.lcut(text)wordset = set(wordlist)wordfreq = []for word in wordset:freq = wordlist.count(word)if word in Positive:positive+=freqif word in Negative:negative+=freqif word in Anger:anger+=freq if word in Disgust:disgust+=freqif word in Fear:fear+=freqif word in Sad:sad+=freqif word in Surprise:surprise+=freqif word in Good:good+=freqif word in Happy:happy+=freqemotion_info = {'length':len(wordlist),'positive': positive,'negative': negative,'anger': anger,'disgust': disgust,'fear':fear,'good':good,'sadness':sad,'surprise':surprise,'happy':happy,}indexs = ['length', 'positive', 'negative', 'anger', 'disgust','fear','sadness','surprise', 'good', 'happy']return pd.Series(emotion_info, index=indexs)#测试
text="""
原著的确更吸引编剧读下去,所以跟《诛仙》系列明显感觉到编剧只看过故事大纲比,这个剧的编剧完整阅读过小说。
配乐活泼俏皮,除了强硬穿越的台词轻微尴尬,最应该尴尬的感情戏反而入戏,
故意模糊了陈萍萍的太监身份、太子跟长公主的暧昧关系,
整体观影感受极好,很期待第二季拍大东山之役。玩弄人心的阴谋阳谋都不狗血,架空的设定能摆脱历史背景,
服装道具能有更自由的发挥空间,特别喜欢庆帝的闺房。以后还是少看国产剧,太长了,
还是精短美剧更适合休闲,追这个太累。王启年真是太可爱了。
"""
res = emotion_caculate(text)
print(res)2.6 计算《庆余年》自定义数据集的七种情绪的分布
# coding: utf-8
import pandas as pd
import jieba
import time#-------------------------------------获取数据集---------------------------------
f = open('庆余年220.csv',encoding='utf8')
weibo_df = pd.read_csv(f)
print(weibo_df.head())#-------------------------------------情感词典读取-------------------------------
#注意:
#1.词典中怒的标记(NA)识别不出被当作空值,情感分类列中的NA都给替换成NAU
#2.大连理工词典中有情感分类的辅助标注(有NA),故把情感分类列改好再替换原词典中# 扩展前的词典
df = pd.read_excel('大连理工大学中文情感词汇本体NAU.xlsx')
print(df.head(10))df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()#-------------------------------------七种情绪的运用-------------------------------
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []#df.iterrows()功能是迭代遍历每一行
for idx, row in df.iterrows():if row['情感分类'] in ['PA', 'PE']:Happy.append(row['词语'])if row['情感分类'] in ['PD', 'PH', 'PG', 'PB', 'PK']:Good.append(row['词语']) if row['情感分类'] in ['PC']:Surprise.append(row['词语']) if row['情感分类'] in ['NB', 'NJ', 'NH', 'PF']:Sad.append(row['词语'])if row['情感分类'] in ['NI', 'NC', 'NG']:Fear.append(row['词语'])if row['情感分类'] in ['NE', 'ND', 'NN', 'NK', 'NL']:Disgust.append(row['词语'])if row['情感分类'] in ['NAU']: #修改: 原NA算出来没结果Anger.append(row['词语']) #正负计算不是很准 自己可以制定规则
Positive = Happy + Good + Surprise
Negative = Anger + Sad + Fear + Disgust
print('情绪词语列表整理完成')
print(Anger)#---------------------------------------中文分词---------------------------------#添加自定义词典和停用词
#jieba.load_userdict("user_dict.txt")
stop_list = pd.read_csv('stop_words.txt',engine='python',encoding='utf-8',delimiter="\n",names=['t'])#获取重命名t列的值
stop_list = stop_list['t'].tolist()def txt_cut(juzi):return [w for w in jieba.lcut(juzi) if w not in stop_list] #可增加len(w)>1#---------------------------------------情感计算---------------------------------
def emotion_caculate(text):positive = 0negative = 0anger = 0disgust = 0fear = 0sad = 0surprise = 0good = 0happy = 0anger_list = []disgust_list = []fear_list = []sad_list = []surprise_list = []good_list = []happy_list = []wordlist = txt_cut(text)#wordlist = jieba.lcut(text)wordset = set(wordlist)wordfreq = []for word in wordset:freq = wordlist.count(word)if word in Positive:positive+=freqif word in Negative:negative+=freqif word in Anger:anger+=freqanger_list.append(word)if word in Disgust:disgust+=freqdisgust_list.append(word)if word in Fear:fear+=freqfear_list.append(word)if word in Sad:sad+=freqsad_list.append(word)if word in Surprise:surprise+=freqsurprise_list.append(word)if word in Good:good+=freqgood_list.append(word)if word in Happy:happy+=freqhappy_list.append(word)emotion_info = {'length':len(wordlist),'positive': positive,'negative': negative,'anger': anger,'disgust': disgust,'fear':fear,'good':good,'sadness':sad,'surprise':surprise,'happy':happy,}indexs = ['length', 'positive', 'negative', 'anger', 'disgust','fear','sadness','surprise', 'good', 'happy']#return pd.Series(emotion_info, index=indexs), anger_list, disgust_list, fear_list, sad_list, surprise_list, good_list, happy_listreturn pd.Series(emotion_info, index=indexs)#测试 (res, anger_list, disgust_list, fear_list, sad_list, surprise_list, good_list, happy_list)
text = """
原著的确更吸引编剧读下去,所以跟《诛仙》系列明显感觉到编剧只看过故事大纲比,这个剧的编剧完整阅读过小说。
配乐活泼俏皮,除了强硬穿越的台词轻微尴尬,最应该尴尬的感情戏反而入戏,
故意模糊了陈萍萍的太监身份、太子跟长公主的暧昧关系,
整体观影感受极好,很期待第二季拍大东山之役。玩弄人心的阴谋阳谋都不狗血,
架空的设定能摆脱历史背景,服装道具能有更自由的发挥空间,
特别喜欢庆帝的闺房。以后还是少看国产剧,太长了,还是精短美剧更适合休闲,追这个太累。王启年真是太可爱了。
"""
#res, anger, disgust, fear, sad, surprise, good, happy = emotion_caculate(text)
res = emotion_caculate(text)
print(res)#---------------------------------------情感计算---------------------------------
start = time.time()
emotion_df = weibo_df['review'].apply(emotion_caculate)
end = time.time()
print(end-start)
print(emotion_df.head())#输出结果
output_df = pd.concat([weibo_df, emotion_df], axis=1)
output_df.to_csv('庆余年220_emotion.csv',encoding='utf_8_sig', index=False)
print(output_df.head())2.7 获取某种情绪
#显示fear、negative数据集
fear_content = output_df.sort_values(by='fear',ascending=False)
print(fear_content)
print(fear_content.iloc[0:5]['review'])negative_content = output_df.sort_values(by='negative',ascending=False)
print(negative_content)
print(negative_content.iloc[0:5]['review'])三、七种情绪的词云可视化
3.1词云的思想
- 调用WordCloud扩展包画图
- 调用PyEcharts中的WordCloud子包画图
Pyrcharts绘制词云的代码如下:
需要先统计出每个词出现的频次,将词与对应的词频,归置于列表中传入函数。
# coding=utf-8
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType# 数据
words = [('背包问题', 10000),('大整数', 6181),('Karatsuba乘法算法', 4386),('穷举搜索', 4055),('傅里叶变换', 2467),('状态树遍历', 2244),('剪枝', 1868),('Gale-shapley', 1484),('最大匹配与匈牙利算法', 1112),('线索模型', 865),('关键路径算法', 847),('最小二乘法曲线拟合', 582),('二分逼近法', 555),('牛顿迭代法', 550),('Bresenham算法', 462),('粒子群优化', 366),('Dijkstra', 360),('A*算法', 282),('负极大极搜索算法', 273),('估值函数', 265)
]# 渲染图
def wordcloud_base() -> WordCloud:c = (WordCloud().add("", words, word_size_range=[20, 100], shape='diamond') # SymbolType.ROUND_RECT.set_global_opts(title_opts=opts.TitleOpts(title='WordCloud词云')))return c# 生成图
wordcloud_base().render('词云图.html')
Pycharts词云的核心函数:
add(name, attr, value, shape=“circle”, word_gap=20, word_size_range=None, rotate_step=45)
- name -> str:图例名称
- attr -> list:属性名称
-value -> list:属性所对应的值 - o shape -> list:词云图轮廓,有’circle’ , 'cardioid , 'diamond , triangleforward , ‘triangle’, ‘pentagon’, 'star’可选.
- word_gap -> int:单词间隔,默认为20
- word_size_range -> list:单词字体大小范围,默认为[12,60]
- rotate_step -> int:旋转单词角度,默认为45
3.2 统计七种情感词的的频次
统计特征词的词频,写入CSV文件
# coding: utf-8
import pandas as pd
import jieba
import time
import csv#-------------------------------------获取数据集---------------------------------
f = open('庆余年220.csv',encoding='utf8')
weibo_df = pd.read_csv(f)
print(weibo_df.head())#-------------------------------------情感词典读取-------------------------------
#注意:
#1.词典中怒的标记(NA)识别不出被当作空值,情感分类列中的NA都给替换成NAU
#2.大连理工词典中有情感分类的辅助标注(有NA),故把情感分类列改好再替换原词典中# 扩展前的词典
df = pd.read_excel('大连理工大学中文情感词汇本体NAU.xlsx')
print(df.head(10))df = df[['词语', '词性种类', '词义数', '词义序号', '情感分类', '强度', '极性']]
df.head()#-------------------------------------七种情绪的运用-------------------------------
Happy = []
Good = []
Surprise = []
Anger = []
Sad = []
Fear = []
Disgust = []#df.iterrows()功能是迭代遍历每一行
for idx, row in df.iterrows():if row['情感分类'] in ['PA', 'PE']:Happy.append(row['词语'])if row['情感分类'] in ['PD', 'PH', 'PG', 'PB', 'PK']:Good.append(row['词语']) if row['情感分类'] in ['PC']:Surprise.append(row['词语']) if row['情感分类'] in ['NB', 'NJ', 'NH', 'PF']:Sad.append(row['词语'])if row['情感分类'] in ['NI', 'NC', 'NG']:Fear.append(row['词语'])if row['情感分类'] in ['NE', 'ND', 'NN', 'NK', 'NL']:Disgust.append(row['词语'])if row['情感分类'] in ['NAU']: #修改: 原NA算出来没结果Anger.append(row['词语']) #正负计算不是很准 自己可以制定规则
Positive = Happy + Good + Surprise
Negative = Anger + Sad + Fear + Disgust
print('情绪词语列表整理完成')
print(Anger)#---------------------------------------中文分词---------------------------------#添加自定义分词词典和停用词
#jieba.load_userdict("user_dict.txt")
stop_list = pd.read_csv('stop_words.txt',engine='python',encoding='utf-8',delimiter="\n",names=['t'])#获取重命名t列的值
stop_list = stop_list['t'].tolist()def txt_cut(juzi):return [w for w in jieba.lcut(juzi) if w not in stop_list] #可增加len(w)>1#---------------------------------------情感计算---------------------------------
#文件写入
c = open("Emotion_features.csv", "a+", newline='', encoding='gb18030')
writer = csv.writer(c)
writer.writerow(["Emotion","Word","Num"])#情感统计
def emotion_caculate(text):positive = 0negative = 0anger = 0disgust = 0fear = 0sad = 0surprise = 0good = 0happy = 0anger_list = []disgust_list = []fear_list = []sad_list = []surprise_list = []good_list = []happy_list = []wordlist = txt_cut(text)#wordlist = jieba.lcut(text)wordset = set(wordlist)wordfreq = []for word in wordset:freq = wordlist.count(word)tlist = []if word in Positive:positive+=freqif word in Negative:negative+=freqif word in Anger:anger+=freqanger_list.append(word)tlist.append("anger")tlist.append(word)tlist.append(freq)writer.writerow(tlist)if word in Disgust:disgust+=freqdisgust_list.append(word)tlist.append("disgust")tlist.append(word)tlist.append(freq)writer.writerow(tlist)if word in Fear:fear+=freqfear_list.append(word)tlist.append("fear")tlist.append(word)tlist.append(freq)writer.writerow(tlist)if word in Sad:sad+=freqsad_list.append(word)tlist.append("sad")tlist.append(word)tlist.append(freq)writer.writerow(tlist)if word in Surprise:surprise+=freqsurprise_list.append(word)tlist.append("surprise")tlist.append(word)tlist.append(freq)writer.writerow(tlist)if word in Good:good+=freqgood_list.append(word)tlist.append("good")tlist.append(word)tlist.append(freq)writer.writerow(tlist)if word in Happy:happy+=freqhappy_list.append(word)tlist.append("happy")tlist.append(word)tlist.append(freq)writer.writerow(tlist)emotion_info = {'length':len(wordlist),'positive': positive,'negative': negative,'anger': anger,'disgust': disgust,'fear':fear,'good':good,'sadness':sad,'surprise':surprise,'happy':happy,}indexs = ['length', 'positive', 'negative', 'anger', 'disgust','fear','sadness','surprise', 'good', 'happy']#return pd.Series(emotion_info, index=indexs), anger_list, disgust_list, fear_list, sad_list, surprise_list, good_list, happy_listreturn pd.Series(emotion_info, index=indexs)#---------------------------------------情感计算---------------------------------
start = time.time()
emotion_df = weibo_df['review'].apply(emotion_caculate)
end = time.time()
print(end-start)
print(emotion_df.head())#输出结果
output_df = pd.concat([weibo_df, emotion_df], axis=1)
output_df.to_csv('庆余年220_emotion.csv',encoding='utf_8_sig', index=False)
print(output_df.head())#结束统计
c.close()输出结果:

3.3词云分析
利用pandas获取不同情绪的特征词,以及频次:
# coding: utf-8
import csv
import pandas as pd#读取数据
f = open('Emotion_features.csv')
data = pd.read_csv(f)
print(data.head())#统计结果
groupnum = data.groupby(['Emotion']).size()
print(groupnum)
print("")#分组统计
for groupname,grouplist in data.groupby('Emotion'):print(groupname)print(grouplist)输出结果:
Emotion Word Num
0 good 人心 1
1 good 极好 1
2 good 活泼 1
3 disgust 强硬 1
4 disgust 尴尬 2Emotion
anger 2
disgust 208
fear 9
good 254
happy 39
sad 42
surprise 11
dtype: int64angerEmotion Word Num
133 anger 气愤 1
382 anger 报仇 3disgustEmotion Word Num
3 disgust 强硬 1
4 disgust 尴尬 2
8 disgust 模糊 1
.. ... ... ...
558 disgust 紧张 1
560 disgust 紧张 1
561 disgust 刺激 1
[208 rows x 3 columns]fearEmotion Word Num
93 fear 鸿门宴 1
111 fear 吓人 1
148 fear 可怕 1
170 fear 没头苍蝇 1
211 fear 厉害 1
290 fear 刀光剑影 1
292 fear 忌惮 1
342 fear 无时无刻 1
559 fear 紧张 1goodEmotion Word Num
0 good 人心 1
1 good 极好 1
.. ... ... ...问题:不同情绪的分布不均匀,扩展词典的非常有必要的。
词云实例:
由于数据集小,杨老师将 词频*5
# coding: utf-8
import csv
import pandas as pd
import operator#------------------------------------统计结果------------------------------------
#读取数据
f = open('Emotion_features.csv')
data = pd.read_csv(f)
print(data.head())#统计结果
groupnum = data.groupby(['Emotion']).size()
print(groupnum)
print("")#分组统计
for groupname,grouplist in data.groupby('Emotion'):print(groupname)print(grouplist)#生成数据 word = [('A',10), ('B',9), ('C',8)] 列表+Tuple
i = 0
words = []
counts = []
while i<len(data):if data['Emotion'][i] in "sad": #相等k = data['Word'][i]v = data['Num'][i]n = 0flag = 0while n<len(words):#如果两个单词相同则增加次数if words[n]==k:counts[n] = counts[n] + vflag = 1breakn = n + 1#如果没有找到相同的特征词则添加if flag==0:words.append(k)counts.append(v)i = i + 1#添加最终数组结果
result = []
k = 0
while k<len(words):result.append((words[k], int(counts[k]*5))) #注意:因数据集较少,作者扩大5倍方便绘图k = k + 1
print(result)#------------------------------------词云分析------------------------------------
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType# 渲染图
def wordcloud_base() -> WordCloud:c = (WordCloud().add("", result, word_size_range=[5, 200], shape=SymbolType.ROUND_RECT).set_global_opts(title_opts=opts.TitleOpts(title='情绪词云图')))return c# 生成图
wordcloud_base().render('情绪词云图.html')最终四个情绪Sad | Happy | Good | Disgust 对比图如下图所示∶

四、自定义词典情感分析
下面进行基于大连理工自定义词典的情感分析
核心模块是load_sentiment_dict(self,dict_path),功能如下︰
- 调用大连理工词典,选取其中要用的列
- 将情感极性转化一下,并计算得出真正的情感值(强度×极性(转后))
- 找到情感词所属的大类
- 分词=>情感词间是否有否定词/程度词+前后顺序=>情感分数累加
完整代码:
# coding: utf-8
import sys
import gzip
from collections import defaultdict
from itertools import product
import jieba
import csv
import pandas as pdclass Struct(object):def __init__(self, word, sentiment, pos,value, class_value):self.word = wordself.sentiment = sentimentself.pos = posself.value = valueself.class_value = class_valueclass Result(object):def __init__(self,score, score_words,not_word, degree_word ):self.score = scoreself.score_words = score_wordsself.not_word = not_wordself.degree_word = degree_wordclass Score(object):# 七个情感大类对应的小类简称: 尊敬score_class = {'乐':['PA','PE'],'好':['PD','PH', 'PG','PB','PK'],'怒':['NA' ],'哀':['NB','NJ','NH', 'PF'],'惧':['NI', 'NC', 'NG'],'恶':['NE', 'ND', 'NN','NK','NL'],'惊':['PC']}# 大连理工大学 -> ICTPOS 3.0POS_MAP = {'noun': 'n','verb': 'v','adj': 'a','adv': 'd','nw': 'al', # 网络用语'idiom': 'al','prep': 'p',}# 否定词NOT_DICT = set(['不','不是','不大', '没', '无', '非', '莫', '弗', '毋','勿', '未', '否', '别', '無', '休'])def __init__(self, sentiment_dict_path, degree_dict_path, stop_dict_path ):self.sentiment_struct,self.sentiment_dict = self.load_sentiment_dict(sentiment_dict_path)self.degree_dict = self.load_degree_dict(degree_dict_path)self.stop_words = self.load_stop_words(stop_dict_path)def load_stop_words(self, stop_dict_path):stop_words = [w for w in open(stop_dict_path).readlines()]#print (stop_words[:100])return stop_wordsdef remove_stopword(self, words):words = [w for w in words if w not in self.stop_words]return wordsdef load_degree_dict(self, dict_path):"""读取程度副词词典Args:dict_path: 程度副词词典路径. 格式为 word\tdegree所有的词可以分为6个级别,分别对应极其, 很, 较, 稍, 欠, 超Returns:返回 dict = {word: degree}"""degree_dict = {}with open(dict_path, 'r', encoding='UTF-8') as f:for line in f:line = line.strip()word, degree = line.split('\t')degree = float(degree)degree_dict[word] = degreereturn degree_dictdef load_sentiment_dict(self, dict_path):"""读取情感词词典Args:dict_path: 情感词词典路径. 格式请看 README.mdReturns:返回 dict = {(word, postag): 极性}"""sentiment_dict = {}sentiment_struct = []with open(dict_path, 'r', encoding='UTF-8') as f:#with gzip.open(dict_path) as f:for index, line in enumerate(f):if index == 0: # title,即第一行的标题continueitems = line.split('\t')word = items[0]pos = items[1]sentiment=items[4]intensity = items[5] # 1, 3, 5, 7, 9五档, 9表示强度最大, 1为强度最小.polar = items[6] # 极性# 将词性转为 ICTPOS 词性体系pos = self.__class__.POS_MAP[pos]intensity = int(intensity)polar = int(polar)# 转换情感倾向的表现形式, 负数为消极, 0 为中性, 正数为积极# 数值绝对值大小表示极性的强度 // 分成3类,极性:褒(+1)、中(0)、贬(-1); 强度为权重值value = Noneif polar == 0: # neutralvalue = 0elif polar == 1: # positivevalue = intensityelif polar == 2: # negtivevalue = -1 * intensityelse: # invalidcontinue#key = (word, pos, sentiment )key = wordsentiment_dict[key] = value#找对应的大类for item in self.score_class.items():key = item[0]values = item[1]#print(key)#print(value)for x in values:if (sentiment==x):class_value = key # 如果values中包含,则获取keysentiment_struct.append(Struct(word, sentiment, pos,value, class_value))return sentiment_struct, sentiment_dictdef findword(self, text): #查找文本中包含哪些情感词word_list = []for item in self.sentiment_struct:if item.word in text:word_list.append(item)return word_listdef classify_words(self, words):# 这3个键是词的序号(索引)sen_word = {} not_word = {}degree_word = {}# 找到对应的sent, not, degree; words 是分词后的列表for index, word in enumerate(words):if word in self.sentiment_dict and word not in self.__class__.NOT_DICT and word not in self.degree_dict:sen_word[index] = self.sentiment_dict[word]elif word in self.__class__.NOT_DICT and word not in self.degree_dict:not_word[index] = -1elif word in self.degree_dict:degree_word[index] = self.degree_dict[word]return sen_word, not_word, degree_worddef get2score_position(self, words):sen_word, not_word, degree_word = self.classify_words(words) # 是字典score = 0start = 0# 存所有情感词、否定词、程度副词的位置(索引、序号)的列表sen_locs = sen_word.keys()not_locs = not_word.keys()degree_locs = degree_word.keys()senloc = -1# 遍历句子中所有的单词words,i为单词的绝对位置for i in range(0, len(words)):if i in sen_locs:W = 1 # 情感词间权重重置not_locs_index = 0degree_locs_index = 0# senloc为情感词位置列表的序号,之前的sen_locs是情感词再分词后列表中的位置序号senloc += 1#score += W * float(sen_word[i])if (senloc==0): # 第一个情感词,前面是否有否定词,程度词start = 0elif senloc < len(sen_locs): # 和前面一个情感词之间,是否有否定词,程度词# j为绝对位置start = previous_sen_locsfor j in range(start,i): # 词间的相对位置# 如果有否定词if j in not_locs:W *= -1not_locs_index=j# 如果有程度副词elif j in degree_locs:W *= degree_word[j]degree_locs_index=j# 判断否定词和程度词的位置:1)否定词在前,程度词减半(加上正值);不是很 2)否定词在后,程度增强(不变),很不是if ((not_locs_index>0) and (degree_locs_index>0 )):if (not_locs_index < degree_locs_index ):degree_reduce = (float(degree_word[degree_locs_index]/2))W +=degree_reduce#print (W)score += W * float(sen_word[i]) # 直接添加该情感词分数#print(score)previous_sen_locs = ireturn score#感觉get2score用处不是很大def get2score(self, text):word_list = self.findword(text) ##查找文本中包含哪些正负情感词,然后分别分别累计它们的数值pos_score = 0pos_word = []neg_score = 0neg_word=[]for word in word_list:if (word.value>0):pos_score = pos_score + word.valuepos_word.append(word.word)else:neg_score = neg_score+word.valueneg_word.append(word.word)print ("pos_score=%d; neg_score=%d" %(pos_score, neg_score))#print('pos_word',pos_word)#print('neg_word',neg_word)def getscore(self, text):word_list = self.findword(text) ##查找文本中包含哪些情感词# 增加程度副词+否定词not_w = 1not_word = []for notword in self.__class__.NOT_DICT: # 否定词if notword in text:not_w = not_w * -1not_word.append(notword)degree_word = []for degreeword in self.degree_dict.keys():if degreeword in text:degree = self.degree_dict[degreeword]#polar = polar + degree if polar > 0 else polar - degreedegree_word.append(degreeword)# 7大类找对应感情大类的词语,分别统计分数= 词极性*词权重result = []for key in self.score_class.keys(): #区分7大类score = 0score_words = []for word in word_list:if (key == word.class_value):score = score + word.valuescore_words.append(word.word)if score > 0:score = score + degreeelif score<0:score = score - degree # 看分数>0,程度更强; 分数<0,程度减弱?score = score * not_wx = '{}_score={}; word={}; nor_word={}; degree_word={};'.format(key, score, score_words,not_word, degree_word)print (x)result.append(x)#key + '_score=%d; word=%s; nor_word=%s; degree_word=%s;'% (score, score_words,not_word, degree_word))return resultif __name__ == '__main__':sentiment_dict_path = "sentiment_words_chinese.tsv" degree_dict_path = "degree_dict.txt"stop_dict_path = "stop_words.txt"#文件读取f = open('庆余年220.csv',encoding='utf8')data = pd.read_csv(f)#文件写入c = open("Result.csv", "a+", newline='', encoding='gb18030')writer = csv.writer(c)writer.writerow(["no","review","score"])#分句功能 否定词程度词位置判断score = Score(sentiment_dict_path, degree_dict_path, stop_dict_path )n = 1for temp in data['review']:tlist = []words = [x for x in jieba.cut(temp)] #分词#print(words) words_ = score.remove_stopword(words)print(words_)#分词->情感词间是否有否定词/程度词+前后顺序->分数累加result = score.get2score_position(words_) print(result)tlist.append(str(n))tlist.append(words)tlist.append(str(result))writer.writerow(tlist)n = n + 1#句子-> 整句判断否定词/程度词 -> 分正负词#score.get2score(temp) #score.getscore(text)c.close()输出结果如下图所示,每条评论对应一个情感分析分数,总体效果较好,差评和好评基本能区分

但是有些’白瞎’、“烂"、“"难受”、“尴尬“这些特征词没有识别,应该和大连理工情感词典有关。
所以我们在情感分析时,可以考虑融合多个特征词典
五、SnowNLP庆余年情感分析
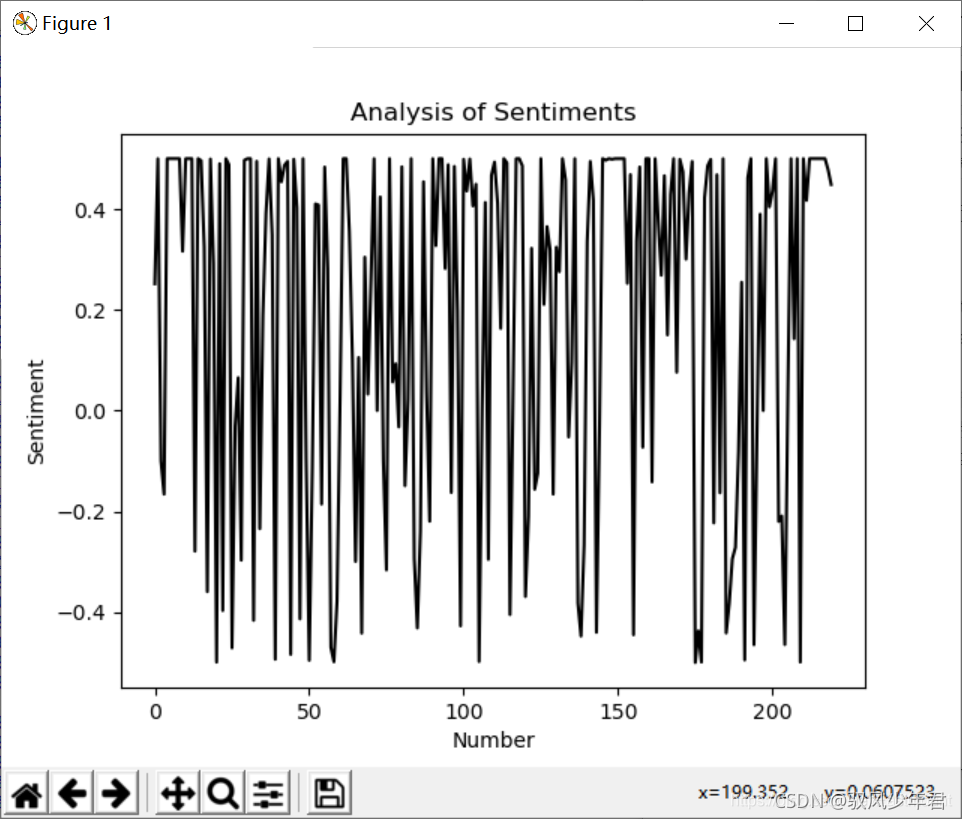
《庆余年》电视剧部分评论进行情感分析。在做情感分析的时候,将情感区间从[0,1.0)]转换为-0.5,0.5],这样的曲线更加好看,位于O以上的是积极评论,反之消极评论。
最终代码如下︰
# -*- coding: utf-8 -*-
from snownlp import SnowNLP
import codecs
import os
import pandas as pd#获取情感分数
f = open('庆余年220.csv',encoding='utf8')
data = pd.read_csv(f)
sentimentslist = []
for i in data['review']:s = SnowNLP(i)print(s.sentiments)sentimentslist.append(s.sentiments)#区间转换为[-0.5, 0.5]
result = []
i = 0
while i<len(sentimentslist):result.append(sentimentslist[i]-0.5)i = i + 1#可视化画图
import matplotlib.pyplot as plt
import numpy as np
plt.plot(np.arange(0, 220, 1), result, 'k-')
plt.xlabel('Number')
plt.ylabel('Sentiment')
plt.title('Analysis of Sentiments')
plt.show()结果: