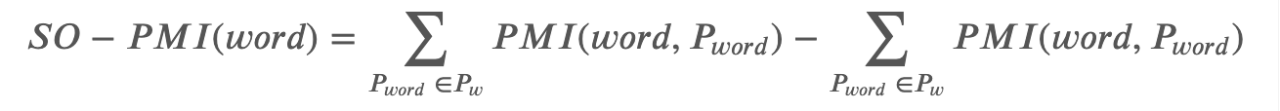目录
- 前言
- 一、模型构建
- 1.归类
- 2.判定
- 3.输出
- 二、代码实现
- 三、结果展示
前言
文本情感倾向性分析(也称为意见挖掘)是指识别和提取原素材中的主观信息,并对带有感情色彩的文本进行分析处理和归纳推理的过程。主要用于实时社交媒体的内容,如微博评论等。而BosonNLP情感词典是从微博、新闻、论坛等数据来源的上百万篇情感标注数据当中自动构建的情感极性词典。因为标注包括微博等网络社交媒体平台的数据,该词典囊括了很多网络用语及非正式简称,对非规范文本也有较高的覆盖率。本文主要基于BosonNLP情感词典,同时使用程度副词词典和否定词词典(借助《知网》情感分析用词语集等文本构建)和哈工大停用词表,共同通过情感打分的方式进行(这里以前文《利用Python系统性爬取微博评论》https://blog.csdn.net/kutalx/article/details/115242052)中获取的评论数据为依托)的情感倾向性分析。提示:代码实现部分参考了文章Python做文本情感分析之情感极性分析的内容,并在其基础上进行了优化,以适配个人需求。
一、模型构建
1.归类
采用的手段为遍历匹配相应的词性词典并对每条评论建立对应的位置词典。分词后文本内的所有词语彼此独立,故对于每一条评论,将其内部的每一个词分别归类于“情感词”、“否定词”、“程度词”和“其它词”四类中。具体步骤为先读取情感词典、否定词词典和程度副词词典,转化为“词语-分值”映射关系;再读取一条分词后评论,新建三个位置词典,内含“位置-分值”映射关系,依次对每个词进行分类,将每个词的位置录入对应的位置词典中。
2.判定
采用的手段为遍历每条评论的位置信息,输出情感分数。一条评论的初始分数为0;按位置遍历内部词语,若一个词被判定为“情感词”,则按照情感位置词典读取分数;若两个“情感词”之间有词语被判定为“否定词”或“程度词”,则按照否定位置词典或程度位置词典读取分数(“否定词”实则皆为-1),将之与后一个“情感词”分数相乘;最后将一条评论的所有情感词分数相加,得其总分数。算式如下:
S w = ( − 1 ) N n ∗ ∑ i = 1 N d D s ∗ S o S_w=(-1)^{N_n}*\sum_{i=1}^{N_d} D_s*S_o Sw=(−1)Nn∗i=1∑NdDs∗So
S s = ∑ i = 1 N o S o S_s=\sum_{i=1}^{N_o} S_o Ss=i=1∑NoSo
其中, S w S_w Sw为单一情感词的最终分数, N n N_n Nn、 N o N_o No为前缀否定词和程度词的数 D s D_s Ds、 S o S_o So为前缀每个程度词的分数和单一情感词的原始分数; S s S_s Ss为一票评论的最终分数, N o N_o No为该评论类情感词的个数。
3.输出
每部作品有多条评论,每条评论的分值分布是离散的。将评论分值划分为五个等级:5(正面),4(偏正面),3(中性),2(偏负面),1(负面)。根据分值的分布特征,算式如下:
D e g r e e = { 5 S s ≥ 3 4 0.5 ≤ S s < 3 3 − 0.5 < S s < 0.5 2 − 3 < S s ≤ − 0.5 1 S s ≤ − 3 Degree=\left\{ \begin{array}{rcl} 5 & & {S_s≥3}\\ 4 & & {0.5≤S_s<3}\\ 3 & & {-0.5<S_s<0.5}\\ 2 & & {-3<S_s≤-0.5}\\ 1 & & {S_s≤-3} \end{array} \right. Degree=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧54321Ss≥30.5≤Ss<3−0.5<Ss<0.5−3<Ss≤−0.5Ss≤−3
由此即可得整体情感倾向水平。
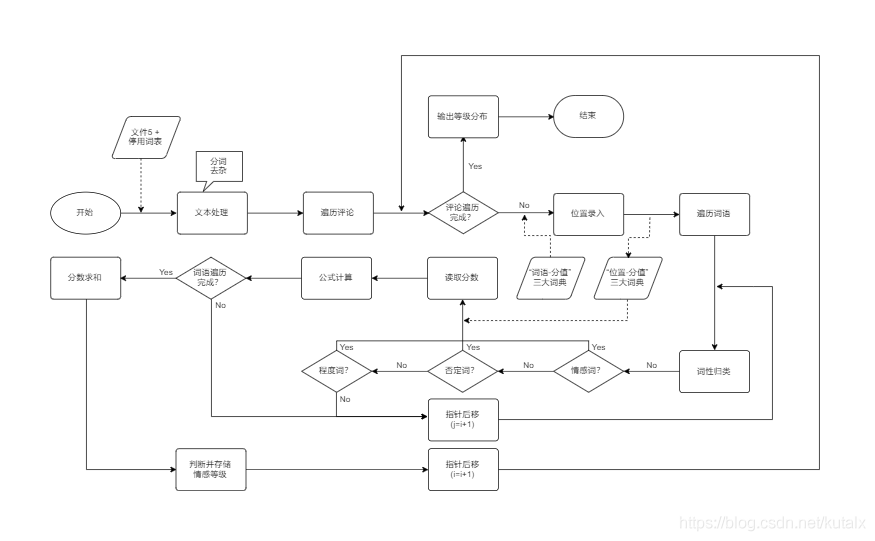
流程如上;其中,“文件5”为评论文本文档,以微博id命名方便后续对应读取。
二、代码实现
使用python实现模型,代码如下:
from collections import defaultdict
import os
import re
import jieba
import codecs
def classifyWords(wordDict):senList = open(存储路径-情感词典).readlines()senDict = defaultdict()for s in senList:ls=s.split(' ',1)if len(ls)==2:senDict[ls[0]] = ls[1]notList = open(存储路径-否定词典).readlines()degreeList = open(存储路径-程度词典).readlines()degreeDict = defaultdict()for d in degreeList:ls2 = d.split(',', 1)if len(ls2) == 2:degreeDict[ls2[0]] = ls2[1]senWord = defaultdict()notWord = defaultdict()degreeWord = defaultdict()for word in wordDict.keys():if word in senDict.keys() and word not in notList and word not in degreeDict.keys():senWord[wordDict[word]] = senDict[word]elif word in notList and word not in degreeDict.keys():notWord[wordDict[word]] = -1elif word in degreeDict.keys():degreeWord[wordDict[word]] = degreeDict[word]return senWord, notWord, degreeWord
def scoreSent(senWord, notWord, degreeWord, segResult):W = 1score = 0senLoc = senWord.keys()notLoc = notWord.keys()degreeLoc = degreeWord.keys()senloc = -1for i in range(0, len(segResult)):if i in senLoc:senloc += 1score += W * float(senWord[i])if senloc < len(senLoc) - 1:for j in range(list(senLoc)[senloc], list(senLoc)[senloc + 1]):if j in notLoc:W *= -1if j in degreeLoc:W *= float(list(degreeWord)[j])if senloc < len(senLoc) - 1:i = list(senLoc)[senloc + 1]return score
uid=#微博id列表
for n in uid:#多个微博的评论文本分别评分txt = open(存储路径-文件5).readlines()stop = open(存储路径-停用词表).readline()line=[]for i in range(len(txt)):line.append(list(jieba.cut(txt[i])))ScoreList=[]for i in range(len(line)):words=line[i]num=list(range(0,len(words)))d=dict(zip(words,num))s,no,d=classifyWords(d)Score=scoreSent(s, no, d, words)ScoreList.append(Score)VBIG=0BIG=0SMALL=0VSMALL=0MID=0for score in ScoreList:if score>=3:VBIG=VBIG+1elif score>=0.5:BIG=BIG+1elif score>=-0.5:MID=MID+1elif score>-3:SMALL=SMALL+1else:VSMALL=VSMALL+1print(VBIG,BIG,MID,SMALL,VSMALL)print("---")
三、结果展示
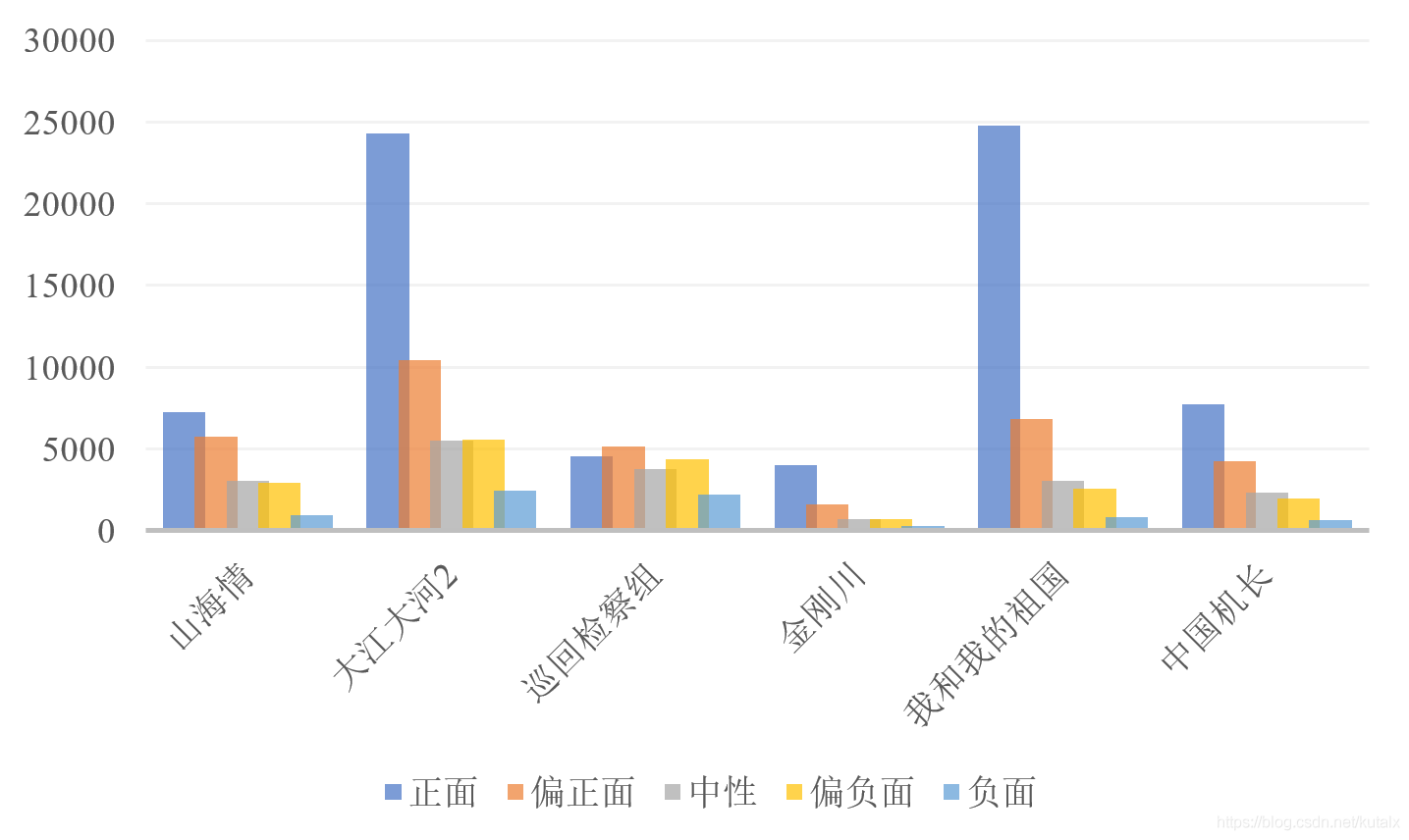
分别选取《山海情》《大江大河2》《巡回检察组》《金刚川》《我和我的祖国》《中国机长》六部作品对应的官方微博下的所有评论,使用上述模型进行分析,结果如上。
在《山海情》19996条评论中,“正面”、“偏正面”、“中性”、“偏负面”、“负面”评论对应的数目分别为7268条,5771条,3042条2946条和969条;在《大江大河2》48264条评论中,分别有24289条,10445条,5518条5582条和2430条;在《巡回检察组》20090条评论中,分别有4577条,5173条,3751条,4356条和2233条;在《金刚川》7296条评论中,分别有4016条,1600条,714条700条和266条;在《我和我的祖国》38053条中,分别有24772条,6855条,3039条2579条和808条;在《中国机长》16900条中,分别有7747条,4231条,2343条1951条和628条。
可以看出,每部作品的正面评价往往略多于或远多于消极评价,符合实际网络评论的情况;而《巡回检察组》相对而言具有最差的口碑,这也符合客观观看评价的情况。