文章目录
- NAME名称
- SYNOPSIS概要
- DESCRIPTION描述
- OPTIONS选项
- Generic Program Information通用程序信息
- Matcher Selection匹配器的选择
- 创建测试环境
- 匹配正则测试
- 只匹配字符串(包含特殊字符)
- Matching Control匹配控制
- 匹配多个正则表达式
- 从文件读取多个匹配样式匹配
- 忽略大小写
- 选择不匹配的行
- 只匹配包含此单词的行
- 仅选择与整行完全匹配的匹配项
- General Output Control
- 一般输出控制
- 打印匹配行数
- 匹配颜色
- 多个文件中查找匹配(或不匹配)的文件
- 指定最大数目的匹配行
- 只输出文件中匹配到的部分
- 静默输出
- Output Line Prefix Control输出行前缀控制
- 显示前缀加行号(1开始)和文件名
- Context Line Control上下行控制
- File and Directory Selection文件和目录选项
- 二进制文件的处理方式
- 设备等的处理方式
- 目录的处理方式(读取、递归、跳过)
- 递归查找目录下的文件
- 递归读取目录下的文件
- 包括或者排除指定文件
- 递归查找当前目录下.txt文件中匹配的行
- REGULAR EXPRESSIONS正则表达式
- Character Classes and Bracket Expressions字符类和方括号表达式
- Anchoring 锚定
- The Backslash Character and Special Expressions反斜杠字符和特殊表达式
- Repetition 重复
- Concatenation 连接
- Alternation交替
- Precedence优先级
- Basic vs Extended Regular Expressions基本正则表达式vs扩展正则表达式
- 其他实例
- 查询空行,查询以某个条件开头或者结尾的行
- 匹配特殊字符,查询有特殊含义的字符
- 目录的查询
NAME名称
grep, egrep, fgrep, rgrep - print lines matching a pattern 打印匹配模式的行
SYNOPSIS概要
grep [OPTIONS] PATTERN [FILE...]grep [OPTIONS] [-e PATTERN]... [-f FILE]... [FILE...]
DESCRIPTION描述
grep searches the named input FILEs for lines containing a match to the given PATTERN. If no files are specified, or if the file “-” is given, grep searches standard input. By default, grep prints the matching lines.grep在命名的输入文件中搜索与给定模式匹配的行。如果没有指定文件,或者给定文件“-”,grep将搜索标准输入。默认情况下,grep打印匹配的行。In addition, the variant programs egrep, fgrep and rgrep are the same as grep -E, grep -F, and grep -r, respectively. These variants are deprecated, but are provided for backward compatibility.此外,egrep、fgrep、rgrep分别与grep -E、grep -F、grep -r相同。这些变体已被弃用,但提供了向后兼容性。
OPTIONS选项
Generic Program Information通用程序信息
--help Output a usage message and exit.输出使用消息并退出。-V, --versionOutput the version number of grep and exit.输出grep的版本号并退出。
Matcher Selection匹配器的选择
-E, --extended-regexpInterpret PATTERN as an extended regular expression (ERE, see below).将模式解释为扩展正则表达式(ERE,参见下面)。-G, --basic-regexpInterpret PATTERN as a basic regular expression (BRE, see below). This is the default.将模式解释为基本正则表达式(BRE,见下文)。这是默认值。-P, --perl-regexpInterpret the pattern as a Perl-compatible regular expression (PCRE). This is highly experimental and grep -P may warn of unimplemented features.将模式解释为perl兼容的正则表达式(PCRE)。这是高度实验性的,grep -P可能会警告未实现的特性。
可见grep默认是支持正则表达式的,只不过支持的是基本正则表达式BRE,也支持ERE(grep -E),PCRE(grep -P)。
创建测试环境
在linux中先创建文本
hello.txt
ubuntu@ip-172-31-3-107:~$ cat > hello.txt
hello
123456
helloworld
12345
world
1234
hi
12
^C
hello1.txt
ubuntu@ip-172-31-3-107:~$ cat > hello1.txt
hello
123456
helloworld
^C
匹配正则测试
grep match_pattern file_name
grep "match_pattern" file_name
在多个文件中查找:
grep "match_pattern" file_1 file_2 file_3 ...
grep "match_pattern" file_name --color=auto 标记匹配颜色 --color=auto 选项:
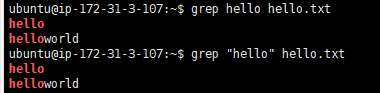
ubuntu@ip-172-31-3-107:~$ grep hello hello.txt
ubuntu@ip-172-31-3-107:~$ grep "hello" hello.txt
ubuntu@ip-172-31-3-107:~$ grep "hello" hello.txt --color=auto
ubuntu@ip-172-31-3-107:~$ grep "hello" hello.txt hello1.txt
需要匹配项加不加引号都可以,还有就是匹配到的字符会默认用红色字体

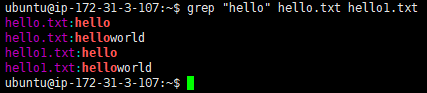
ubuntu@ip-172-31-3-107:~$ grep "[1-9]" hello.txt
ubuntu@ip-172-31-3-107:~$ grep -E "[1-9]" hello.txt 正则选项必须是大写
ubuntu@ip-172-31-3-107:~$ grep -P "[1-9]" hello.txt
上面三个命令输出都是一样的都支持基本的正则表达式

只匹配字符串(包含特殊字符)
-F, --fixed-stringsInterpret PATTERN as a list of fixed strings (instead of regular expressions), separated by newlines, any of which is to be matched.将模式解释为一个固定字符串列表(而不是正则表达式),由换行分隔,其中任何一个都要匹配。fgrep与运行grep -F相同。在这种模式下,grep将您的PATTERN字符串计算为“固定字符串” - 字符串中的每个字符都按字面处理。例如,如果您的字符串包含星号(“ * ”),grep将尝试将其与实际星号匹配,而不是将其解释为通配符。如果您的字符串包含多行(如果它包含换行符),则每行将被视为固定字符串,并且其中任何一行都可以触发匹配。
https://www.computerhope.com/unix/ugrep.htm
Matching Control匹配控制
匹配多个正则表达式
-e PATTERN, --regexp=PATTERNUse PATTERN as the pattern. If this option is used multiple times or is combined with the -f (--file) option, search for all patterns given. This option can be used to protect a pattern beginning with “-”.使用模式作为模式。如果此选项多次使用或与-f (- file)选项组合使用,则搜索给定的所有模式。此选项可用于保护以“-”开头的模式。
ubuntu@ip-172-31-3-107:~$ echo this is a text line | grep -e "[s]" -e "line"

从文件读取多个匹配样式匹配
-f FILE, --file=FILEObtain patterns from FILE, one per line. If this option is used multiple times or is combined with the -e (--regexp) option, search for all patterns given. The empty file contains zero patterns, and therefore matchesnothing.从文件中获取模式,每行一个。如果此选项多次使用或与-e(——regexp)选项组合使用,则搜索给定的所有模式。空文件包含零模式,因此匹配什么都没有。
可以使用-f选项来匹配多个样式,在样式文件中逐行写出需要匹配的字符
ubuntu@ip-172-31-3-107:~$ cat patfile
aaa
bbb
ubuntu@ip-172-31-3-107:~$ echo aaa bbb ccc ddd eee | grep -f patfile

忽略大小写
-i, --ignore-caseIgnore case distinctions in both the PATTERN and the input files.忽略模式和输入文件中的大小写差异。-y Obsolete synonym for -i. -i的过时同义词。echo "hello world" | grep -i "HELLO"

选择不匹配的行
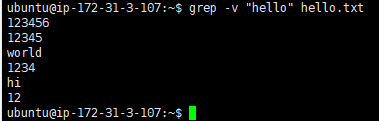
-v, --invert-matchInvert the sense of matching, to select non-matching lines.反转匹配的感觉,选择不匹配的行。
ubuntu@ip-172-31-3-107:~$ grep -v "hello" hello.txt
只匹配包含此单词的行
-w, --word-regexpSelect only those lines containing matches that form whole words. The test is that the matching substring must either be at the beginning of the line, or preceded by a non-word constituent character. Similarly, it mustbe either at the end of the line or followed by a non-word constituent character. Word-constituent characters are letters, digits, and the underscore.只选择包含构成整个单词的匹配项的行。测试是匹配的子字符串必须位于行首,或者位于非单词组成字符的前面。同样,它必须行尾或后跟非单词组成字符。单词组成字符是字母、数字和下划线。
ubuntu@ip-172-31-3-107:~$ grep -w "hello" hello.txt
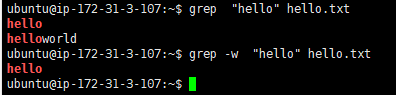
grep -w "hope" myfile.txt
在文件myfile.txt中搜索包含“hope”的行。只有包含不同单词“hope”的行才会匹配。将“hope”作为单词一部分的行将不匹配。
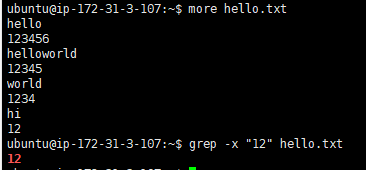
仅选择与整行完全匹配的匹配项
-x, --line-regexpSelect only those matches that exactly match the whole line. For a regular expression pattern, this is like parenthesizing the pattern and then surrounding it with ^ and $.只选择那些与整行完全匹配的匹配项。对于一个正则表达式模式,这就像周围加上括弧模式然后^和$。
General Output Control
一般输出控制
打印匹配行数
-c, --countSuppress normal output; instead print a count of matching lines for each input file. With the -v, --invert-match option (see below), count non-matching lines.抑制正常输出;而是为每个输入文件打印匹配行的计数。使用-v,——reverse -match选项(见下文),计算不匹配的行。
- 计算匹配到的行数
grep -c "hello" hello.txt 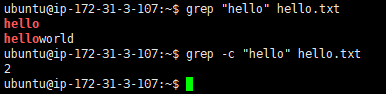
- 查找data.txt文件有多少个空行:
grep '^$' data.txt -c
匹配颜色
--color[=WHEN], --colour[=WHEN]Surround the matched (non-empty) strings, matching lines, context lines, file names, line numbers, byte offsets, and separators (for fields and groups of context lines) with escape sequences to display them in color onthe terminal. The colors are defined by the environment variable GREP_COLORS. The deprecated environment variable GREP_COLOR is still supported, but its setting does not have priority. WHEN is never, always, or auto.用转义序列将匹配(非空)字符串、匹配行、上下文行、文件名、行号、字节偏移量和分隔符(用于字段和上下文行组)包围起来,以彩色显示它们终端。颜色由环境变量GREP_COLORS定义。仍然支持已弃用的环境变量GREP_COLOR,但是它的设置没有优先级。当不是,总是,或自动。
Viewing grep output in color
If we use the --color option, our successful matches will be highlighted for us:
using grep with the --color option to highlight matches

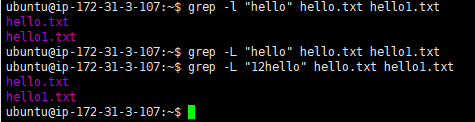
多个文件中查找匹配(或不匹配)的文件
-L, --files-without-matchSuppress normal output; instead print the name of each input file from which no output would normally have been printed. The scanning will stop on the first match.抑制正常输出;而是打印通常不会输出的每个输入文件的名称。扫描将在第一场比赛中停止。-l, --files-with-matchesSuppress normal output; instead print the name of each input file from which output would normally have been printed. The scanning will stop on the first match.抑制正常输出;而是打印输出通常打印的每个输入文件的名称。扫描将在第一场比赛中停止。搜索多个文件并查找匹配文本在哪些文件中:
grep -l "text" file1 file2 file3...
指定最大数目的匹配行
-m NUM, --max-count=NUMStop reading a file after NUM matching lines. If the input is standard input from a regular file, and NUM matching lines are output, grep ensures that the standard input is positioned to just after the last matchingline before exiting, regardless of the presence of trailing context lines. This enables a calling process to resume a search. When grep stops after NUM matching lines, it outputs any trailing context lines. When the-c or --count option is also used, grep does not output a count greater than NUM. When the -v or --invert-match option is also used, grep stops after outputting NUM non-matching lines.在NUM匹配行之后停止读取文件。如果输入是来自常规文件的标准输入,并且NUM匹配行是输出的,则grep确保将标准输入定位在最后一次匹配之后退出前的行,而不管是否存在尾随上下文行。这允许调用进程恢复搜索。当grep在NUM匹配行之后停止时,它输出任何尾随上下文行。当使用-c或-count选项时,grep输出的count不大于NUM,使用-v或- reverse -match选项时,grep输出NUM不匹配行后停止。

当m后的数字为0时,什么也不匹配
当m后的数字为1时,最多获取一个匹配行
当m后的数字为5时,最多获取五个匹配行
只输出文件中匹配到的部分
-o, --only-matchingPrint only the matched (non-empty) parts of a matching line, with each such part on a separate output line.只打印匹配行中匹配的(非空的)部分,并将每一部分打印在单独的输出行中。
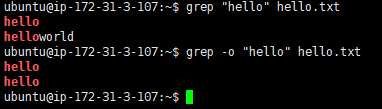
这个应该不常用
静默输出
-q, --quiet, --silentQuiet; do not write anything to standard output. Exit immediately with zero status if any match is found, even if an error was detected. Also see the -s or --no-messages option.安静的;不要向标准输出写入任何内容。如果发现任何匹配,立即退出,状态为零,即使检测到错误。还可以查看-s或-no-messages选项。-s, --no-messagesSuppress error messages about nonexistent or unreadable files.禁止关于不存在或不可读文件的错误消息。
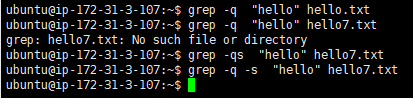
不会输出任何信息,如果命令运行成功返回0,失败则返回非0值。一般用于条件测试。
Output Line Prefix Control输出行前缀控制
显示前缀加行号(1开始)和文件名
-H, --with-filenamePrint the file name for each match. This is the default when there is more than one file to search.打印每个匹配项的文件名。当需要搜索多个文件时,这是默认设置。-h, --no-filenameSuppress the prefixing of file names on output. This is the default when there is only one file (or only standard input) to search.在输出中取消文件名的前缀。这是默认情况下,只有一个文件(或只有标准输入)搜索。-n, --line-numberPrefix each line of output with the 1-based line number within its input file.在输出的每行前面加上输入文件中基于1的行号。

Context Line Control上下行控制
-A NUM, --after-context=NUMPrint NUM lines of trailing context after matching lines. Places a line containing a group separator (--) between contiguous groups of matches. With the -o or --only-matching option, this has no effect and a warning isgiven.在匹配行之后打印尾随上下文的NUM行。在连续的匹配组之间放置一行包含组分隔符(——)的行。如果使用-o或——only-matching选项,则不会有任何效果,并且会有一个警告考虑到。-B NUM, --before-context=NUMPrint NUM lines of leading context before matching lines. Places a line containing a group separator (--) between contiguous groups of matches. With the -o or --only-matching option, this has no effect and a warning isgiven.在匹配行之前打印前导上下文的NUM行。在连续的匹配组之间放置一行包含组分隔符(——)的行。如果使用-o或——only-matching选项,则不会有任何效果,并且会有一个警告考虑到。-C NUM, -NUM, --context=NUMPrint NUM lines of output context. Places a line containing a group separator (--) between contiguous groups of matches. With the -o or --only-matching option, this has no effect and a warning is given.打印输出上下文的NUM行。在连续的匹配组之间放置一行包含组分隔符(——)的行。对于-o或——only-matching选项,这没有效果,会给出一个警告。
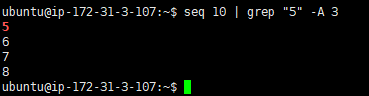
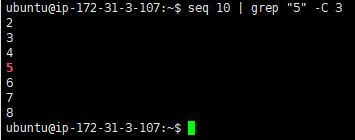
- 显示匹配某个结果之后的3行,使用 -A 选项:
seq 10 | grep "5" -A 3
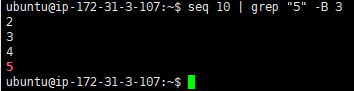
- 显示匹配某个结果之前的3行,使用 -B 选项:
seq 10 | grep "5" -B 3
- 显示匹配某个结果的前三行和后三行,使用 -C 选项:
seq 10 | grep "5" -C 3
File and Directory Selection文件和目录选项
二进制文件的处理方式
-a, --textProcess a binary file as if it were text; this is equivalent to the --binary-files=text option.像处理文本一样处理二进制文件;这相当于——二进制文件=文本选项。--binary-files=TYPEIf the first few bytes of a file indicate that the file contains binary data, assume that the file is of type TYPE. By default, TYPE is binary, and grep normally outputs either a one-line message saying that a binaryfile matches, or no message if there is no match. If TYPE is without-match, grep assumes that a binary file does not match; this is equivalent to the -I option. If TYPE is text, grep processes a binary file as if itwere text; this is equivalent to the -a option. When processing binary data, grep may treat non-text bytes as line terminators; for example, the pattern '.' (period) might not match a null byte, as the null byte mightbe treated as a line terminator. Warning: grep --binary-files=text might output binary garbage, which can have nasty side effects if the output is a terminal and if the terminal driver interprets some of it as commands.-I Process a binary file as if it did not contain matching data; this is equivalent to the --binary-files=without-match option.以不包含匹配数据的方式处理二进制文件;这相当于——二进制文件=无匹配选项。设备等的处理方式
-D ACTION, --devices=ACTIONIf an input file is a device, FIFO or socket, use ACTION to process it. By default, ACTION is read, which means that devices are read just as if they were ordinary files. If ACTION is skip, devices are silentlyskipped.如果输入文件是设备、FIFO或套接字,则使用ACTION来处理它。默认情况下,操作是读取的,这意味着读取设备就像读取普通文件一样。如果动作是跳过,则设备是静默的
目录的处理方式(读取、递归、跳过)
-d ACTION, --directories=ACTIONIf an input file is a directory, use ACTION to process it. By default, ACTION is read, i.e., read directories just as if they were ordinary files. If ACTION is skip, silently skip directories. If ACTION is recurse,read all files under each directory, recursively, following symbolic links only if they are on the command line. This is equivalent to the -r option.如果输入文件是一个目录,则使用ACTION来处理它。默认情况下,读取操作,即就像读取普通文件一样读取目录。如果操作是跳过,则静默地跳过目录。如果动作是递归的,递归地读取每个目录下的所有文件,仅在符号链接位于命令行中时才跟随它们。这相当于-r选项。
递归查找目录下的文件

递归读取目录下的文件
-r, --recursiveRead all files under each directory, recursively, following symbolic links only if they are on the command line. Note that if no file operand is given, grep searches the working directory. This is equivalent to the -drecurse option.递归地读取每个目录下的所有文件,仅在符号链接位于命令行中时才跟随它们。注意,如果没有给定文件操作数,grep将搜索工作目录。这就等于-d递归选项。-R, --dereference-recursiveRead all files under each directory, recursively. Follow all symbolic links, unlike -r.递归地读取每个目录下的所有文件。遵循所有符号链接,不像-r。如果某个目录下有快捷方式,-r不读取, -R会读取
grep "text" . -r -n
# .表示当前目录。
包括或者排除指定文件
--exclude=GLOBSkip files whose base name matches GLOB (using wildcard matching). A file-name glob can use *, ?, and [...] as wildcards, and \ to quote a wildcard or backslash character literally.跳过基名称与GLOB匹配的文件(使用通配符匹配)。文件名称glob可以使用*、?和[…]]作为通配符,并且\从字面上引用通配符或反斜杠字符。--exclude-from=FILESkip files whose base name matches any of the file-name globs read from FILE (using wildcard matching as described under --exclude).跳过那些基名称与从文件中读取的任何文件名全局变量匹配的文件(使用通配符匹配,如——exclude下所述)。--exclude-dir=DIRExclude directories matching the pattern DIR from recursive searches.从递归搜索中排除匹配模式DIR的目录。--include=GLOBSearch only files whose base name matches GLOB (using wildcard matching as described under --exclude).只搜索基名称与GLOB匹配的文件(使用通配符匹配,如下面所述——exclude)。
递归查找当前目录下.txt文件中匹配的行
ubuntu@ip-172-31-3-107:~$ grep -r "hello" ./ --include="*.txt"
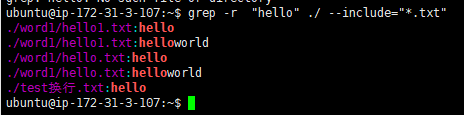
之前还遇到一种错误的写法

REGULAR EXPRESSIONS正则表达式
A regular expression is a pattern that describes a set of strings. Regular expressions are constructed analogously to arithmetic expressions, by using various operators to combine smaller expressions.正则表达式是描述一组字符串的模式。正则表达式的构造类似于算术表达式,它使用各种运算符组合较小的表达式。The fundamental building blocks are the regular expressions that match a single character. Most characters, including all letters and digits, are regular expressions that match themselves. Any meta-character with specialmeaning may be quoted by preceding it with a backslash.基本的构建块是匹配单个字符的正则表达式。大多数字符,包括所有字母和数字,都是匹配它们自己的正则表达式。任何特殊元字符意思可以在前面加上反斜杠。The period . matches any single character. 这段时间。匹配任何单个字符。
Character Classes and Bracket Expressions字符类和方括号表达式
Within a bracket expression, a range expression consists of two characters separated by a hyphen. It matches any single character that sorts between the two characters, inclusive, using the locale's collating sequence andcharacter set. For example, in the default C locale, [a-d] is equivalent to [abcd]. Many locales sort characters in dictionary order, and in these locales [a-d] is typically not equivalent to [abcd]; it might be equivalent to[aBbCcDd], for example. To obtain the traditional interpretation of bracket expressions, you can use the C locale by setting the LC_ALL environment variable to the value C.在方括号表达式中,范围表达式由两个用连字符分隔的字符组成。它使用语言环境的排序序列和匹配在两个字符之间排序的任何单个字符(包括)例如,在默认C语言环境中,[a-d]等价于[abcd]。许多地区按照字典顺序对字符进行排序,在这些地区[a-d]通常不等于[abcd];它可能等于例如,[aBbCcDd]。要获得括号表达式的传统解释,可以使用C语言环境,方法是将LC_ALL环境变量设置为值C。Finally, certain named classes of characters are predefined within bracket expressions, as follows. Their names are self explanatory, and they are [:alnum:], [:alpha:], [:cntrl:], [:digit:], [:graph:], [:lower:], [:print:],[:punct:], [:space:], [:upper:], and [:xdigit:]. For example, [[:alnum:]] means the character class of numbers and letters in the current locale. In the C locale and ASCII character set encoding, this is the same as[0-9A-Za-z]. (Note that the brackets in these class names are part of the symbolic names, and must be included in addition to the brackets delimiting the bracket expression.) Most meta-characters lose their special meaninginside bracket expressions. To include a literal ] place it first in the list. Similarly, to include a literal ^ place it anywhere but first. Finally, to include a literal - place it last.最后,在括号表达式中预定义了某些命名的字符类,如下所示。它们的名称不言自明,分别是[:alnum:]、[:alpha:]、[:cntrl:]、[:digit:]、[:graph:]、[:lower:]、[:print:]、[punct:],[空间:],[:上:],[xdigit:]。例如,[[:alnum:]]表示当前地区数字和字母的字符类。在C语言环境和ASCII字符集编码中,这是一样的[0-9A-Za-z]。(注意,这些类名中的括号是符号名的一部分,必须包括在分隔括号表达式的括号之外。)大多数元字符失去了它们的特殊意义括号内的表达式。把它放在列表的第一位。同样,包括文字^但首先把它任何地方。最后,包括一个字面上的地方,它最后。
Anchoring 锚定
The caret ^ and the dollar sign $ are meta-characters that respectively match the empty string at the beginning and end of a line.插入符号^和美元符号$元字符,分别与空字符串的开始和结束。
The Backslash Character and Special Expressions反斜杠字符和特殊表达式
The symbols \< and \> respectively match the empty string at the beginning and end of a word. The symbol \b matches the empty string at the edge of a word, and \B matches the empty string provided it's not at the edge of aword. The symbol \w is a synonym for [_[:alnum:]] and \W is a synonym for [^_[:alnum:]].符号\<和\>分别匹配单词开头和结尾的空字符串。符号\b匹配单词边缘的空字符串,而\b匹配不位于单词a边缘的空字符串词。象征\ w是同义词(_ [:alnum:]]和\ w是同义词(^ _ [:alnum:]]。
Repetition 重复
A regular expression may be followed by one of several repetition operators: 正则表达式后面可以跟着几个重复运算符之一:? The preceding item is optional and matched at most once. 前一项是可选的,最多匹配一次。* The preceding item will be matched zero or more times. 前一项将匹配0次或更多次。+ The preceding item will be matched one or more times. 前一项将匹配一次或多次。{n} The preceding item is matched exactly n times. 前一项正好匹配n次。{n,} The preceding item is matched n or more times. 前一项匹配n次或更多次。{,m} The preceding item is matched at most m times. This is a GNU extension. 前一项最多匹配m次。这是一个GNU扩展。{n,m} The preceding item is matched at least n times, but not more than m times. 前一项匹配至少n次,但不超过m次。
Concatenation 连接
Two regular expressions may be concatenated; the resulting regular expression matches any string formed by concatenating two substrings that respectively match the concatenated expressions.两个正则表达式可以连接在一起;得到的正则表达式匹配通过连接两个分别匹配所连接表达式的子字符串而形成的任何字符串。
Alternation交替
Two regular expressions may be joined by the infix operator |; the resulting regular expression matches any string matching either alternate expression.两个正则表达式可以由中缀运算符|连接;得到的正则表达式匹配任何匹配任一备选表达式的字符串。Precedence优先级
Repetition takes precedence over concatenation, which in turn takes precedence over alternation. A whole expression may be enclosed in parentheses to override these precedence rules and form a subexpression.
重复优先于串联,串联又优先于交替。可以用圆括号括起整个表达式,以覆盖这些优先规则并形成子表达式。
Basic vs Extended Regular Expressions基本正则表达式vs扩展正则表达式
In basic regular expressions the meta-characters ?, +, {, |, (, and ) lose their special meaning; instead use the backslashed versions \?, \+, \{, \|, \(, and \).在基本正则表达式中,元字符?、+、{、|、(和)失去了它们的特殊含义;而是使用反斜杠版本\?\+, \{, \|, \(,和)。其他实例
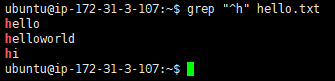
查询空行,查询以某个条件开头或者结尾的行
若是希望取得第一行是h开头的字符行
ubuntu@ip-172-31-3-107:~$ grep "^h" hello.txt
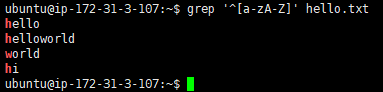
若是希望取得以英文字符开头的字符
grep '^[a-zA-Z]' hello.txt
查询以abc开头的行
grep -n "^abc" hello.txt
取得不是以英文字符开头的信息
grep '^[^a-zA-Z]' hello.txt // 里面的^是取反 外面的^是以上面开头
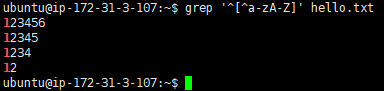
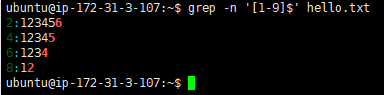
取得以数字结尾的行
ubuntu@ip-172-31-3-107:~$ grep -n '[1-9]$' hello.txt
查询以abc结尾的行
grep -n "abc$" hello.txt
取得一个空行的方式
ubuntu@ip-172-31-3-107:~$ grep -n '^$' test换行.txt //这里就是取空行了

匹配特殊字符,查询有特殊含义的字符
诸如$ . ’ " * [] ^ | \ + ? ,必须在特定字符前加\
grep "\." hello.txt (#在hello.txt中查询包含“.”的所有行)
grep "my\.conf" hello.txt (#查询有文件名my.conf的行)
取得小数点结尾的行
grep '\.$' hello.txt //小数点是特殊字符 需要用\进行转义
目录的查询
ls –l |grep “^d” (#如果要查询目录列表中的目录)
ls -l | grep "^[^d]" (#在一个目录中查询不包含目录的所有文件)