一、论文贡献
1、提出了一种任意尺度的数据增强方法,以促进模型从具有不同尺度的图像中学习深度尺度。
2、开发了一种双高分辨率网络,具有多尺度特征融合,使用新的跨尺度深度一致性损失训练。
二、相关工作
三、方法
3.1参照monodepth2
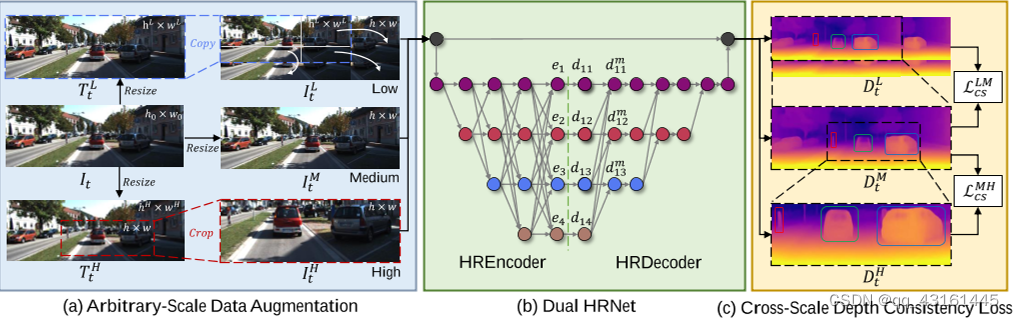
3.2分辨率自适应自监督框架
概述:
除了使用了论文自身的Dual HRNet,数据增强,其它计算与monodepth2相同。
数据增强:
对于形状为 (c, h0, w0) 的单个原始图像 I,我们首先获得三个不同分辨率的图像 (T L, T M 和 T H)通过调整大小操作。 T M 的分辨率固定为 (h, w ),表示中间刻度。 T L 和 T H 的分辨率在连续范围内随机变化,分别由比例因子 sL 和 sH 控制。 sL 和 sH 的范围分别为 [0.7, 0.9] 和 [1.1, 2.0]。通过图像拼接的方式从 T L 生成一个低比例图像 IL,T M 直接视为中间比例图像 IM ,从高分辨率图像 IH通过 RandomCrop得到TH。(三者分辨率相同)(在本文中,(c, h0, w0) 是 (3, 375, 1242), (c, h, w ) 是 (3, 192, 640))(细节参照图2和算法1)

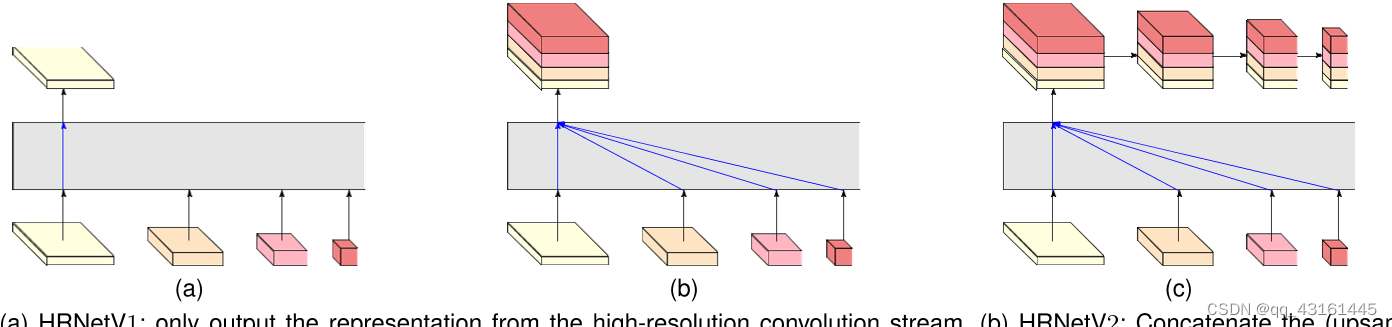
Dual HRNet:
解码器对编码器输出进行逐步解码,仿照编码器,并非是一步到位的上采样到高分辨率。
解释为对,比当前层次低的低分辨率的特征进行上采样与1*1卷积后累加,再加上当前层次的特征,也就是该阶段的内容。(参照图2(b)与公式)
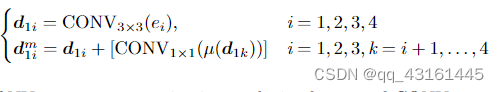
(下图是HRNet的编码与解码)

跨尺度深度一致性损失:
根据已知的尺度因子 sL 和 sH 以及算法 1 中 RandomCrop 的裁剪位置,我们可以得到 DL t 、 DM t 和 DH t 之间的像素对应关系。
对于 DM t 和 DH t ,我们首先找到 DH t 在 DM t 中的对应位置,由 DM t 中的黑色虚线框(命名为 ̃DM t )表示。然后我们调整 DH t 的大小以保持与 ̃DM t 相同的大小以获得 ̃DH t 。
高中尺度之间与中低尺度之间的光度误差
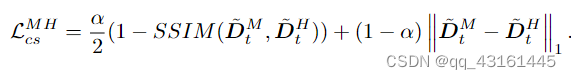
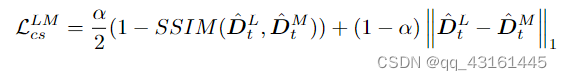
训练损失:
加权三个尺度的最小重投影损失 + 加权三个尺度的平滑损失 + 加权跨尺度深度一致性损失
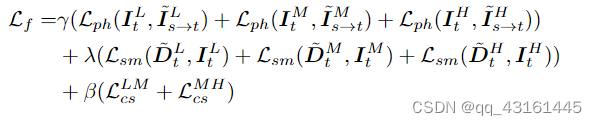
四、实验
实施:
为了提高训练速度,我们只为深度估计网络输出单尺度深度并计算单尺度深度上的损失,而不是计算深度估计网络的多尺度输出上的损失。
结果:
Monodepth2预测的深度图在不同分辨率下是不一致的,RA-Depth 在不同分辨率下显示出可信且一致的深度预测,这表明 RA-Depth 可以学习场景深度的尺度不变性。
消融实验:
1、Effects of Arbitrary-Scale Data Augmentation:
AS-Aug 生成三个具有三种不同尺度的训练图像,让模型隐式学习场景深度的尺度不变性。
ASAug 直接在原始图像上进行裁剪,以便保留图像的详细信息。另一方面,将三个尺度的图像输入到网络中,可以模拟三种相机内在函数。
2、Effects of Cross-Scale Depth Consistency Loss:
实验表明,CSLoss的显式约束可以进一步帮助模型学习场景深度的尺度不变性,从而增强模型的分辨率适应能力。
3、Effects of Dual HRNet:相对比较轻量,参数和计算复杂度低。