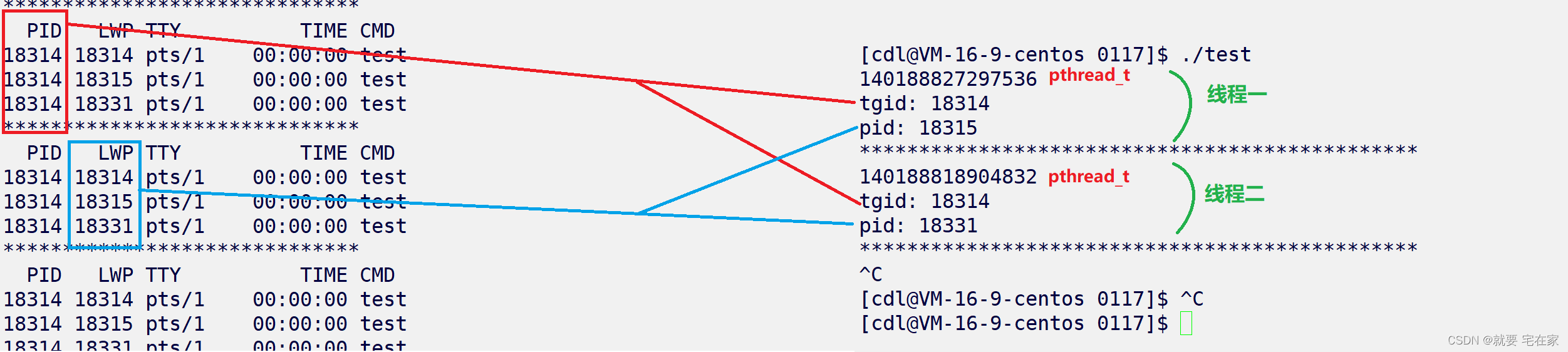
参考:https://blog.csdn.net/j824117879/article/details/82019545
crc这个名词听着特别熟悉,但是由于工作性质的原因很少接触到,但最近工作中却碰到了crc校验,开发资料给了crc的初值和使用的crc表格,就只能根据这个初值和表格计算出最终的crc校验了,下面所说的这些也许只适用于某些特定场合,因为我对算法根本一点都不理解,不知道下面的是否通用,但用在我这个项目上还是很正确的。
于是就大量的搜索crc算法,发现网上的资源真实良莠不齐,虽说每个人都把自己理解的东西写了出来,但感觉都很不负责啊,几乎都是抄袭,估计crc原理都是从同一个地方抄过来的,看的我是头大啊,每个人上来就讲什么“模2除法”,然后给了一个数据流和一个多项式就开始了计算流程,然后就说怎么怎么样了,最后把代码一附就结束了,对于我这样的小白来说看起来有点头大,而且照着这些博文给的代码写个测试例子,发现跟我想要得到的crc结果差很多,而且那么大一堆数据怎么进行“模2除法”,难不成要把所有发送的数据做成一个特别长的二进制数去和多项式除数做除法,找到余数吗?不禁有点想骂人的感觉,也许是我在这方面太菜了吧!!写这篇文章的目的不仅是记录自己的一些想法,还希望有了解的朋友能给指点一下,因为本人对CRC算法真的是不理解。
吐槽了这么多,说一下我的心得。
从网上看了那么多,https://blog.csdn.net/j824117879/article/details/82019545这篇文章对我帮助最大,我会把该博主关于算法理解的内容附在最后,下面说一下我的理解,如果想了解“模2除法”的可以自己百度。参考上面那个博主的内容CRC16算法有3种实现方式:1.按位计算;2.按字节计算;3.按半字计算,我个人认为“模2”除法只是在计算单个字节的时候使用,大量数据之间crc的计算有不同的一个规则,根据计算规则先求出传输数据每个字节的余数,上一个字节的余数和下一个字节是如何配合工作的,在特定算法中指定。如按字节计算crc,其算法如下
#include<stdio.h>
#include"crc.h"
typedef unsigned short uint16_t;
char buf[] = {0xAA,0x55,0x23,0x15};
int main(){int len = sizeof(buf);int i = 0;uint16_t crc_result = 0xFFFF;uint16_t crc_h8, crc_l8;for(i = 0;i < len;i ++){crc_h8 = (crc_result >> 8); crc_l8 = (crc_result << 8);
// table是余数表,下方会给出crc_result = crc_l8 ^ table [(crc_h8 ^ buf[i]) & 0xFF];} crc_result &= 0xFFFF;printf("crc_result is %x\n",crc_result);return 0;
}
举个例子说明一下:
如计算 0xAA,0x55,0x23,0x15这个四个字节的crc校验:a202,余数的初值设为0xFFFF,多项式为0x1021,算法如下,由于余数初值为0xFFFF,故计算第一个字节时,
crc_h8 = 0xFFFF >> 8 = 0xFF;
crc_l8 = 0xFFFF << 8 = 0xFF00;
数组索引值的计算结果:
crc_h8 ^ 0xAA = 0xFF ^ 0xAA = 0x55;
查余数索引表
table[85] = 0x0a50;
crc_l8 ^ table[85] = 0xFF00 ^ 0x0a50 = 0xF550
第一个字节的余数为0xF550,接下来计算第2个字节,此时的余数初值变为了0xF550,重复上边的操作
crc_h8 = 0xF550 >> 8 = 0xF5;
crc_l8 = 0xF550 << 8 = 0x5000;
数组索引值的计算结果:
crc_h8 ^ 0x55 = 0xF5 ^ 0x55 = 0xA0;
查余数索引表
table[160] = 0xB5EA;
crc_l8 ^ table[160] = 0x5000 ^ 0xB5EA = 0xE5EA
第2个字节的余数为0xE5EA,接下来计算第3个字节,此时的余数初值变为了0xE5EA,重复上边的操作
crc_h8 = 0xE5EA >> 8 = 0xE5;
crc_l8 = 0xE5EA << 8 = 0xEA00;
数组索引值的计算结果:
crc_h8 ^ 0x23 = 0xE5 ^ 0x23 = 0xC6;
查余数索引表
table[198] = 0xB98A;
crc_l8 ^ table[198] = 0EA00 ^ 0xB98A = 0x538A
第3个字节的余数为0x538A,接下来计算第4个字节,此时的余数初值变为了0x538A,重复上边的操作
crc_h8 = 0x538A >> 8 = 0x53;
crc_l8 = 0x538A << 8 = 0x8A00;
数组索引值的计算结果:
crc_h8 ^ 0x15 = 0x53 ^ 0x15 = 0x46;
查余数索引表
table[70] = 0x2802;
crc_l8 ^ table[70] = 0x8A00 ^ 0x2802 = 0xA202
最终的crc校验码为0xA202依照上面的算法过程可以解释为:把余数初值右移8位与数据单个字节进行异或操作得到值A,取出值A在余数索引表格中的值B,再把余数初值左移8位得到值C,然后B和C进行异或得到值D,D再和下一个字节进行同样的操作,直到最后一个字节。(跟参考博文的博主解释的算法不一致,我也不清楚原因,这点还希望高手给指点一下)。到此,按字节计算crc可以告一段落了,不管是按字节计算,还是按位计算与按半字计算,所得到的结果都是一样的。
按字节计算的余数索引表格:
const uint16_t crc_table[256] ={
0x0000, 0x1021, 0x2042, 0x3063, 0x4084, 0x50a5, 0x60c6, 0x70e7, 0x8108, 0x9129, 0xa14a, 0xb16b, 0xc18c, 0xd1ad, 0xe1ce, 0xf1ef, 0x1231, 0x0210, 0x3273, 0x2252, 0x52b5, 0x4294, 0x72f7, 0x62d6, 0x9339, 0x8318, 0xb37b, 0xa35a, 0xd3bd, 0xc39c, 0xf3ff, 0xe3de, 0x2462, 0x3443, 0x0420, 0x1401, 0x64e6, 0x74c7, 0x44a4, 0x5485, 0xa56a, 0xb54b, 0x8528, 0x9509, 0xe5ee, 0xf5cf, 0xc5ac, 0xd58d, 0x3653, 0x2672, 0x1611, 0x0630, 0x76d7, 0x66f6, 0x5695, 0x46b4, 0xb75b, 0xa77a, 0x9719, 0x8738, 0xf7df, 0xe7fe, 0xd79d, 0xc7bc, 0x48c4, 0x58e5, 0x6886, 0x78a7, 0x0840, 0x1861, 0x2802, 0x3823, 0xc9cc, 0xd9ed, 0xe98e, 0xf9af, 0x8948, 0x9969, 0xa90a, 0xb92b, 0x5af5, 0x4ad4, 0x7ab7, 0x6a96, 0x1a71, 0x0a50, 0x3a33, 0x2a12, 0xdbfd, 0xcbdc, 0xfbbf, 0xeb9e, 0x9b79, 0x8b58, 0xbb3b, 0xab1a, 0x6ca6, 0x7c87, 0x4ce4, 0x5cc5, 0x2c22, 0x3c03, 0x0c60, 0x1c41, 0xedae, 0xfd8f, 0xcdec, 0xddcd, 0xad2a, 0xbd0b, 0x8d68, 0x9d49, 0x7e97, 0x6eb6, 0x5ed5, 0x4ef4, 0x3e13, 0x2e32, 0x1e51, 0x0e70, 0xff9f, 0xefbe, 0xdfdd, 0xcffc, 0xbf1b, 0xaf3a, 0x9f59, 0x8f78, 0x9188, 0x81a9, 0xb1ca, 0xa1eb, 0xd10c, 0xc12d, 0xf14e, 0xe16f, 0x1080, 0x00a1, 0x30c2, 0x20e3, 0x5004, 0x4025, 0x7046, 0x6067, 0x83b9, 0x9398, 0xa3fb, 0xb3da, 0xc33d, 0xd31c, 0xe37f, 0xf35e, 0x02b1, 0x1290, 0x22f3, 0x32d2, 0x4235, 0x5214, 0x6277, 0x7256, 0xb5ea, 0xa5cb, 0x95a8, 0x8589, 0xf56e, 0xe54f, 0xd52c, 0xc50d, 0x34e2, 0x24c3, 0x14a0, 0x0481, 0x7466, 0x6447, 0x5424, 0x4405, 0xa7db, 0xb7fa, 0x8799, 0x97b8, 0xe75f, 0xf77e, 0xc71d, 0xd73c, 0x26d3, 0x36f2, 0x0691, 0x16b0, 0x6657, 0x7676, 0x4615, 0x5634, 0xd94c, 0xc96d, 0xf90e, 0xe92f, 0x99c8, 0x89e9, 0xb98a, 0xa9ab, 0x5844, 0x4865, 0x7806, 0x6827, 0x18c0, 0x08e1, 0x3882, 0x28a3, 0xcb7d, 0xdb5c, 0xeb3f, 0xfb1e, 0x8bf9, 0x9bd8, 0xabbb, 0xbb9a, 0x4a75, 0x5a54, 0x6a37, 0x7a16, 0x0af1, 0x1ad0, 0x2ab3, 0x3a92, 0xfd2e, 0xed0f, 0xdd6c, 0xcd4d, 0xbdaa, 0xad8b, 0x9de8, 0x8dc9, 0x7c26, 0x6c07, 0x5c64, 0x4c45, 0x3ca2, 0x2c83, 0x1ce0, 0x0cc1, 0xef1f, 0xff3e, 0xcf5d, 0xdf7c, 0xaf9b, 0xbfba, 0x8fd9, 0x9ff8, 0x6e17, 0x7e36, 0x4e55, 0x5e74, 0x2e93, 0x3eb2, 0x0ed1, 0x1ef0};
下面我再来谈一下”模2“除法计算方法,:如数据为0xAA,多项式还是0x1021,当然也可以直接从上述表格中查找0xA0的索引,得到对应的余数值0x14A0,计算过程如下:

虽然根据自己找的资料能准确把结果计算出来了,但还是感觉对crc一点都不理解,也许上面的方法就是crc的计算规则,或者是根据"模二"除法经过转换就得到了上面的方法,反正感觉挺神奇的,暂且记录下来,以后自己用的话起码也有一个参考方法,下面把参考的博主的对算法的理解粘贴在下面
二、算法的理解:
1、按位计算:
首先CRC算法即为一个序列与多项式(CCITT:0x11021)进行模2除法,然后按位计算CRC可以理解为首先将第一个位与多项式进行模二除法,得到一个余数,再将余数右移一位加上(不进位加法)第二个位再与多项式进行模二除法,直到计算到最后一位
2、按字节计算:
由于按位计算计算量较大,因此出现有了按字节计算,按字节位计算CRC可以理解为首先将第一个字节与多项式进行模二除法,得到一个余数,再将余数右移八位加上(不进位加法)第二个字节再与多项式进行模二除法,直到计算到最后一字节。在将一个字节与多项式进行模二除法时运算量较大,因此将0x00-0xff与多项式的计算结果提前计算出来,保存为一个数组,从而减小运算量,因此按字节计算CRC的表格由此而来。
3、按半字计算:
由于按字节计算需要存在256个16位数据,所以需要512个字节的空间,对于部分系统存在空间不足的情况,因此出现了按半字节计算的方式,由于半字节只能表示0-15,所以只需16个16位的数据,32个字节空间
原文:https://blog.csdn.net/j824117879/article/details/82019545
下面再把我自己按字节与按位计算的测试例程写在下面,以供参考
#include<stdio.h>
#include"crc.h"
typedef unsigned short uint16_t;
char buf[] = {0xAA,0x55,0x23,0x15};
int main(){int len = sizeof(buf);int i = 0;uint16_t crc_result = 0xFFFF;uint16_t crc_h8, crc_l8;uint16_t crc16 = 0xFFFF;char * data = NULL; unsigned char index = 0;for(i = 0;i < len;i ++){crc_h8 = (crc_result >> 8); crc_l8 = (crc_result << 8); printf("crc_l8 is %x\n",crc_l8);printf("crc_h8 is %x\n",crc_h8);index = (crc_h8 ^ buf[i]) & 0xFF;printf("index = %d\n",index);printf("table[index] = %04X\n",table[index]);crc_result = crc_l8 ^ table [index];} crc_result &= 0xFFFF;printf("crc_result is %x\n",crc_result);data = buf;while(len --){for(i=0x80; i!=0; i>>=1) {if((crc16 & 0x8000) != 0) {crc16 = crc16 << 1;crc16 = crc16 ^ 0x1021;} else {crc16 = crc16 << 1;} if((*data & i) != 0) {crc16 = crc16 ^ 0x1021; //crc16 = crc16 ^ (0x10000 ^ 0x11021)} } data ++; } crc16 &= 0xFFFF;printf("crc16 is %x\n",crc16);return 0;}










![[Linux]线程概念_线程控制(线程与进程的区别与联系 | 线程创建 | 线程等待 | 线程终止 | 线程分离 | LWP)](https://img-blog.csdnimg.cn/16d5aafb3844436e88a1785fefd5c34d.png)