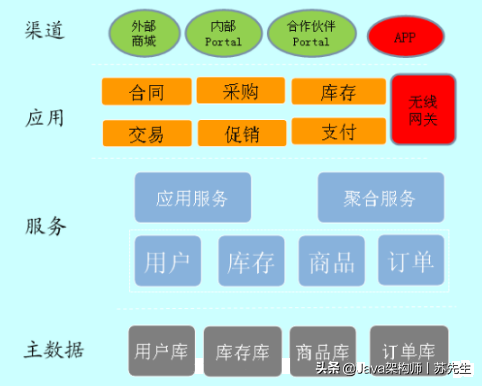
最近在使用storm做一个实时计算的项目,Spout需要从 KAFKA 集群中读取数据,为了提高开发效率,直接使用了Storm提供的KAFKA插件。今天抽空看了一下KafkaSpout的源码,记录下心得体会。
KafkaSpout基于kafka.javaapi.consumer.SimpleConsumer实现了consumer客户端的功能,包括 partition的分配,消费状态的维护(offset)。同时KafkaSpout使用了storm的可靠API,并实现了spout的ack 和 fail机制。KafkaSpout的基本处理流程如下:
1. 建立zookeeper客户端,在zookeeper zk_root + "/topics/" + _topic + "/partitions" 路径下获取到partition列表
2. 针对每个partition 到路径Zk_root + "/topics/" + _topic + "/partitions"+"/" + partition_id + "/state"下面获取到leader partition 所在的broker id
3. 到/broker/ids/broker id 路径下获取broker的host 和 port 信息,并保存到Map中Partition_id –-> learder broker
4. 获取spout的任务个数和当前任务的index,然后再根据partition的个数来分配当前spout 所消费的partition列表
5. 针对所消费的每个broker建立一个SimpleConsumer对象用来从kafka上获取数据
6. 提交当前partition的消费信息到zookeeper上面保存
下面对几个关键点进行下分析:
一、partition 的分配策略
1. 在KafkaSpout中获取spout的task的个数,也就是consumer的个数,代码如下:
| 1 | int totalTasks = context.getComponentTasks(context.getThisComponentId()).size(); |
2. 在KafkaSpout中获取当前spout的 task index,注意,task index和task id是不同的,task id是当前spout在整个topology中的id,而task index是当前spout在组件中的id,取值范围为[0, spout_task_number-1],代码如下:
| 1 | _coordinator = new ZkCoordinator(_connections, conf, _spoutConfig, _state, context.getThisTaskIndex(), totalTasks, _uuid); |
3. 获取partiton与leader partition所在broker的映射关系,代码的调用顺序如下:
ZkCoordinator:
| 1 | GlobalPartitionInformation brokerInfo = _reader.getBrokerInfo(); |
DynamicBrokersReader:
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | /** * Get all partitions with their current leaders */ public GlobalPartitionInformation getBrokerInfo() throws SocketTimeoutException { GlobalPartitionInformation globalPartitionInformation = new GlobalPartitionInformation(); try { int numPartitionsForTopic = getNumPartitions(); String brokerInfoPath = brokerPath(); for ( int partition = 0 ; partition < numPartitionsForTopic; partition++) { int leader = getLeaderFor(partition); String path = brokerInfoPath + "/" + leader; try { byte [] brokerData = _curator.getData().forPath(path); Broker hp = getBrokerHost(brokerData); globalPartitionInformation.addPartition(partition, hp); } catch (org.apache.zookeeper.KeeperException.NoNodeException e) { LOG.error( "Node {} does not exist " , path); } } } catch (SocketTimeoutException e) { throw e; } catch (Exception e) { throw new RuntimeException(e); } LOG.info( "Read partition info from zookeeper: " + globalPartitionInformation); return globalPartitionInformation; } |
4. 获取当前spout消费的partition
KafkaUtils:

public static List<Partition> calculatePartitionsForTask(GlobalPartitionInformation partitionInformation, int totalTasks, int taskIndex) {Preconditions.checkArgument(taskIndex < totalTasks, "task index must be less that total tasks");//获取所有的排序后的partition列表List<Partition> partitions = partitionInformation.getOrderedPartitions();int numPartitions = partitions.size();if (numPartitions < totalTasks) {LOG.warn("there are more tasks than partitions (tasks: " + totalTasks + "; partitions: " + numPartitions + "), some tasks will be idle");}List<Partition> taskPartitions = new ArrayList<Partition>();//此处是核心分配算法,举个例子来说明分配策略//假设spout的并发度是3,当前spout的task index 是 1,总的partition的个数为5,那么当前spout消费的partition id为1,4for (int i = taskIndex; i < numPartitions; i += totalTasks) {Partition taskPartition = partitions.get(i);taskPartitions.add(taskPartition);}logPartitionMapping(totalTasks, taskIndex, taskPartitions);return taskPartitions;}
二、partition的更新策略
如果出现broker宕机,spout挂掉的情况,那么spout是要重新分配parition的,KafkaSpout并没有监听zookeeper上broker、partition和其他spout的状态,所以当有异常发生的时候KafkaSpout并不知道的,它采用了两种方法来更新partition的分配。
1. 定时更新
根据ZkHosts中的refreshFreqSecs字段来定时更新partition列表,我们可以通过修改配置来更改定时刷新的间隔。每一次调用kafkaspout的nextTuple方法时,都会首先调用ZkCoordinator的getMyManagedPartitions方法来获取当前spout消费的partition列表
public void nextTuple() {List<PartitionManager> managers = _coordinator.getMyManagedPartitions();//getMyManagedPartitions方法中会判断是否已经到了该刷新的时间,如果到了就重新分配partitionpublic List<PartitionManager> getMyManagedPartitions() {if (_lastRefreshTime == null || (System.currentTimeMillis() - _lastRefreshTime) > _refreshFreqMs) {refresh();_lastRefreshTime = System.currentTimeMillis();}return _cachedList; }
2.异常更新
当调用kafkaspout的nextTuple方法出现异常时,强制更新当前spout的partition消费列表
public void nextTuple() {List<PartitionManager> managers = _coordinator.getMyManagedPartitions();for (int i = 0; i < managers.size(); i++) {try {EmitState state = managers.get(_currPartitionIndex).next(_collector);} catch (FailedFetchException e) {_coordinator.refresh();}}
三、消费状态的维护
1.首先要分析一下当spout启动的时候是怎么获取初始offset的。在每个spout获取到消费的partition列表时,会针对每个partition来创建PartitionManager对象,下面看一下PartitionManager的初始化过程:
public PartitionManager(DynamicPartitionConnections connections, String topologyInstanceId, ZkState state, Map stormConf, SpoutConfig spoutConfig, Partition id) {_partition = id;_connections = connections;_spoutConfig = spoutConfig;_topologyInstanceId = topologyInstanceId;//到连接池里注册partition和partition leader所在的broker host,如果连接池里有该broker的连接,则直接返回该连接、//如果连接池里没有,则建立broker的连接,并返回连接_consumer = connections.register(id.host, id.partition);_state = state;_stormConf = stormConf;numberAcked = numberFailed = 0;String jsonTopologyId = null;Long jsonOffset = null;//获取zookeeper上offset的提交路径String path = committedPath();try {//从提交路径上读取信息,提取记录的该partition的消费offset//如果zookeeper上没有该路径则表示当前topic没有被spout消费过Map<Object, Object> json = _state.readJSON(path);LOG.info("Read partition information from: " + path + " --> " + json );if (json != null) {jsonTopologyId = (String) ((Map<Object, Object>) json.get("topology")).get("id");jsonOffset = (Long) json.get("offset");}} catch (Throwable e) {LOG.warn("Error reading and/or parsing at ZkNode: " + path, e);}//从broker上获取当前partition的offset,默认为获取最新的offset,如果用户配置forceFromStart(KafkaConfig),则获取该partition最早的offset,//也就是consume from beginningLong currentOffset = KafkaUtils.getOffset(_consumer, spoutConfig.topic, id.partition, spoutConfig);//情况1: 如果从zookeeper上没有获取topology和消费信息,则直接用从broker上获取到的offsetif (jsonTopologyId == null || jsonOffset == null) { // failed to parse JSON?_committedTo = currentOffset;LOG.info("No partition information found, using configuration to determine offset");//情况2: 获取到的topology id 不一致 或者用户要求从新获取数据的时候,则从kafka上获取offset//可以和情况1 合并,在KafkaUtils.getOffset已经判断过forceFromStart,此处无需再次判断} else if (!topologyInstanceId.equals(jsonTopologyId) && spoutConfig.forceFromStart) {_committedTo = KafkaUtils.getOffset(_consumer, spoutConfig.topic, id.partition, spoutConfig.startOffsetTime);LOG.info("Topology change detected and reset from start forced, using configuration to determine offset");}//情况3: 使用zookeeper上保留的offset进行消费 else {_committedTo = jsonOffset;LOG.info("Read last commit offset from zookeeper: " + _committedTo + "; old topology_id: " + jsonTopologyId + " - new topology_id: " + topologyInstanceId );}//如果上次消费的offset已经过了保质期,则直接消费新数据if (currentOffset - _committedTo > spoutConfig.maxOffsetBehind || _committedTo <= 0) {LOG.info("Last commit offset from zookeeper: " + _committedTo);_committedTo = currentOffset;LOG.info("Commit offset " + _committedTo + " is more than " +spoutConfig.maxOffsetBehind + " behind, resetting to startOffsetTime=" + spoutConfig.startOffsetTime);}LOG.info("Starting Kafka " + _consumer.host() + ":" + id.partition + " from offset " + _committedTo);_emittedToOffset = _committedTo;}
2. 然后看一下partition消费offset是怎么保存和维护的
PartitionManager 中的 _emittedToOffset用来保存当前消费的offset,在每一次获取到消息的时候都会更新这个值
private void fill() {if (!had_failed || failed.contains(cur_offset)) {numMessages += 1;_pending.add(cur_offset);_waitingToEmit.add(new MessageAndRealOffset(msg.message(), cur_offset));//更新_emittedToOffset_emittedToOffset = Math.max(msg.nextOffset(), _emittedToOffset);if (had_failed) {failed.remove(cur_offset);}}}_fetchAPIMessageCount.incrBy(numMessages);}}
3.提交offset到zookeeper
offset的提交是周期性的,提交的周期可在SpoutConfig中的stateUpdateIntervalMs中来配置。每次调用kafkaspout的nextTuple方法后都会判断是否需要提交offset
public void nextTuple() {if ((now - _lastUpdateMs) > _spoutConfig.stateUpdateIntervalMs) {commit();}}
如果需要提交则调用kafkaspout的commit方法,使用轮巡的方式提交每个partition的消费状况
private void commit() {_lastUpdateMs = System.currentTimeMillis();for (PartitionManager manager : _coordinator.getMyManagedPartitions()) {manager.commit();} }
具体的提交是委托PartitionManager来完成的
public void commit() {//获取当前要提交的offset,如果有pending的offset的话,就说明还有一些消息没有完成处理,则提交pending消息的最小的offset//如果没有pending的消息,则提交当前消费的offsetlong lastCompletedOffset = lastCompletedOffset();//用来判断是否有新的offset需要提交if (_committedTo != lastCompletedOffset) {LOG.debug("Writing last completed offset (" + lastCompletedOffset + ") to ZK for " + _partition + " for topology: " + _topologyInstanceId);Map<Object, Object> data = (Map<Object, Object>) ImmutableMap.builder().put("topology", ImmutableMap.of("id", _topologyInstanceId,"name", _stormConf.get(Config.TOPOLOGY_NAME))).put("offset", lastCompletedOffset).put("partition", _partition.partition).put("broker", ImmutableMap.of("host", _partition.host.host,"port", _partition.host.port)).put("topic", _spoutConfig.topic).build();_state.writeJSON(committedPath(), data);_committedTo = lastCompletedOffset;LOG.debug("Wrote last completed offset (" + lastCompletedOffset + ") to ZK for " + _partition + " for topology: " + _topologyInstanceId);} else {LOG.debug("No new offset for " + _partition + " for topology: " + _topologyInstanceId);} }
四、kafkaspout ack 和 fail的处理
1. 首先还是说说kafkaspout消息的发送
当调用kafkaspout的nextTuple方法时,kafkaspout委托PartitionManager next方法来发送数据
public void nextTuple() {List<PartitionManager> managers = _coordinator.getMyManagedPartitions();for (int i = 0; i < managers.size(); i++) {try {// in case the number of managers decreased_currPartitionIndex = _currPartitionIndex % managers.size();EmitState state = managers.get(_currPartitionIndex).next(_collector);if (state != EmitState.EMITTED_MORE_LEFT) {_currPartitionIndex = (_currPartitionIndex + 1) % managers.size();} }public EmitState next(SpoutOutputCollector collector) { //判断等待队列是否为空,如果为空则调用fill方法从broker上取数据进行填充if (_waitingToEmit.isEmpty()) {fill();}while (true) {MessageAndRealOffset toEmit = _waitingToEmit.pollFirst();if (toEmit == null) {return EmitState.NO_EMITTED;}//对kafka的消息进行解码Iterable<List<Object>> tups = KafkaUtils.generateTuples(_spoutConfig, toEmit.msg);if (tups != null) {for (List<Object> tup : tups) {//如果tuple不为null,则发送该tuple,messageID为new KafkaMessageId(_partition, toEmit.offset)//这样在ack 或者 fail的时候才能根据_partition找到相应的PartitionManagercollector.emit(tup, new KafkaMessageId(_partition, toEmit.offset));}break;} else {ack(toEmit.offset);}}if (!_waitingToEmit.isEmpty()) {return EmitState.EMITTED_MORE_LEFT;} else {return EmitState.EMITTED_END;} }
2. 在PartitionManager会维护一个pending 列表,用来保存已经发送但是没有被成功处理的消息,一个failed列表,用来保存已经失败的消息
3. 当一个消息成功处理时会调用spout的ack方法,kafkaspout会根据message id中包含的partition id 来委托相应的PartitionManager来处理
public void ack(Object msgId) {KafkaMessageId id = (KafkaMessageId) msgId;PartitionManager m = _coordinator.getManager(id.partition);if (m != null) {m.ack(id.offset);}}//PartitionManager 接收到ack消息后,会判断pending的最早的一条消息是否已经过质保,如果过质保,则清除队列中所有过保的消息//如果没有过保的消息,则在pending队列中移除当前消息public void ack(Long offset) {if (!_pending.isEmpty() && _pending.first() < offset - _spoutConfig.maxOffsetBehind) {// Too many things pending!_pending.headSet(offset - _spoutConfig.maxOffsetBehind).clear();}_pending.remove(offset);numberAcked++;}
4. 当一条消息处理失败时,会调用spout的fail方法,同样,kafkaspout会根据message id中包含的partition id 来委托相应的PartitionManager来处理
public void fail(Object msgId) {KafkaMessageId id = (KafkaMessageId) msgId;PartitionManager m = _coordinator.getManager(id.partition);if (m != null) {m.fail(id.offset);}}//PartitionManager接收到fail消息,会判断失败的消息是否已经过保,如果过保则忽略掉public void fail(Long offset) {if (offset < _emittedToOffset - _spoutConfig.maxOffsetBehind) {LOG.info("Skipping failed tuple at offset=" + offset +" because it's more than maxOffsetBehind=" + _spoutConfig.maxOffsetBehind +" behind _emittedToOffset=" + _emittedToOffset);} //如果在保质期内,则加入failed列表,如果没有成功响应的消息,并且失败的消息个数已经超过保质期个数,则认为没有消息成功,系统有问题,丢异常else {LOG.debug("failing at offset=" + offset + " with _pending.size()=" + _pending.size() + " pending and _emittedToOffset=" + _emittedToOffset);failed.add(offset);numberFailed++;if (numberAcked == 0 && numberFailed > _spoutConfig.maxOffsetBehind) {throw new RuntimeException("Too many tuple failures");}}}//对于failed的消息会进行重发private void fill() {//如果有失败的消息,则获取第一个的offsetfinal boolean had_failed = !failed.isEmpty();if (had_failed) {offset = failed.first();} else {offset = _emittedToOffset;}ByteBufferMessageSet msgs = null;try {msgs = KafkaUtils.fetchMessages(_spoutConfig, _consumer, _partition, offset);} catch (UpdateOffsetException e) {_emittedToOffset = KafkaUtils.getOffset(_consumer, _spoutConfig.topic, _partition.partition, _spoutConfig);LOG.warn("Using new offset: {}", _emittedToOffset);// fetch failed, so don't update the metricsreturn;}if (msgs != null) {int numMessages = 0;for (MessageAndOffset msg : msgs) {final Long cur_offset = msg.offset();if (cur_offset < offset) {// Skip any old offsets.continue;}//如果该消息在failed列表中,则重新发送,并将其从failed列表中删除if (!had_failed || failed.contains(cur_offset)) {numMessages += 1;_pending.add(cur_offset);_waitingToEmit.add(new MessageAndRealOffset(msg.message(), cur_offset));_emittedToOffset = Math.max(msg.nextOffset(), _emittedToOffset);if (had_failed) {failed.remove(cur_offset);}}}_fetchAPIMessageCount.incrBy(numMessages);}}