1978年在英特尔公司的历史中是很不平凡的一年。这一年它满10岁了,员工数首次超过1万人。这一年,它卖掉了竞争激烈的电子表(digital watch)业务。最重要的是,在这一年6月,它推出了具有跨时代意义的8086芯片。

在8086的宣传彩页里,第一页画着一轮初升的太阳。标题写着“8086的时代已经来了。”

太多人喜欢8086了,据说它的生产一直持续到90年代。它如此完美,让很多同行都想模仿。它的后代很多,形成一个庞大的x86谱系。
8086的工作频率有5M、8M、10M和4M等多种,最初版本是5MHz。这意味着,每个时钟周期的时间是:
1/(5*10^6) 秒= 0.2 * 10^-6秒 = 0.2微妙
在从1978年开始的20多年中,8086及其后代风行天下。工作频率不断提升,1994年的改进版本奔腾处理器首次达到100MHz。
| Intel® Pentium® Processor | 100 MHz 90 MHz | Mar. 7, 1994 | 0.6-micron | 3.3 million | Desktops |
2000年5月,改进版本的奔腾III处理器发布,首次达到1GHz主频。在22年时间里,8086的工作频率从5MHz发展到1GHz,刚好200倍。
| Intel® Pentium® III Processor | 1 GHz 933 MHz 866 MHz 850 MHz | May-00 | 0.18-micron | 28 million | 256 KB Advanced Transfer Cache |
同年11月,包含众多新设计的奔腾4处理器首次发布,把最高工作频率的纪录刷新为2GHz。
在接下来的几年中,英特尔的奔腾4团队持续努力,向4GHz主频冲刺。所做的努力是多方面的。一方面是改进生产工艺,把晶体管做小。2004年初,英特尔发布90nm工艺的奔腾4。这标志着芯片生产工艺从微米计量进入到纳米。另一方面是增大风扇,提高散热能力。奔腾4的微架构名叫NetBurst,别名火球。内部运算单元的流水线特别长。这样的流水线在高频率下工作时会产生大量的热量。2003年,我加入英特尔。最初的一些项目都是基于奔腾4的,至今还记得当年那些个头很大的风扇,转速很大,声音很响。
无论如何,奔腾4向4G主频冲刺的目标没能实现。据说,当时的CEO,Craig Barrett曾经向合作伙伴诚恳道歉,因为没有实现承诺。
或许是上帝已经安排了,或许任何事物的发展都应该有个极限,或许就该在这里多停留一些时间。
2006年1月,英特尔发布最后一款奔腾4,这不仅意味着一个微架构的结束,也意味着依靠提高频率来不断提升性能的时代结束了。从此,整个产业开始向多核方向发展。一个时代结束了,多核时代开始了。
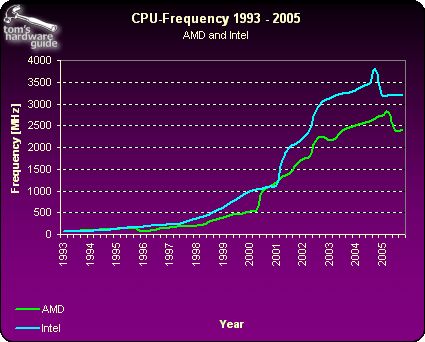
从上面这幅来自Tom's Hardware的频率走势图来看,2004年左右,频率达到3.8GHz的高峰,而后出现回调。
2018年7月,英特尔为了纪念8086发布40年,也是为了纪念整个公司成立50年,特别发布了一个特殊版本酷睿i7处理器,取名为8086K。 
8086K的标称频率为4GHz,最高工作频率为5GHz,刚好是40年前的8086始祖的1000倍。40年时间,从5MHz发展到5GHz。
# of Cores 6
# of Threads 12
Processor Base Frequency 4.00 GHz
Max Turbo Frequency 5.00 GHz
Cache 12 MB SmartCache
Bus Speed 8 GT/s DMI3
TDP 95 W
今天,大多数处理器的频率都是1~5GHz,从低端的ARM芯片,到高端的i7、i9以及至强(Xeon)。
对于1~5GHz的处理器,每个时钟周期的时间是多久呢?
1/((1~5)*10^9)=1~0.2*10^-9秒 = 1~0.2纳秒
对于跳频工作在5GHz的8086K来说,每个时钟周期的长度是0.2纳秒,刚好是始祖8086的千分之一。40年时间,每个时钟周期,从0.2微妙加快到0.2纳秒(ns)。换言之,在1纳秒时间里,8086K最多可以跑5个时钟。
1纳秒是多长时间呢?以光来衡量的话,1纳秒时间里,光可以在真空中行进大约30厘米。
光速大约30万公里每秒 3*10 * 10^4 * 10^3m/s
1 ns = 10^ -9 s
d = 3*10^8*10^-9 =3*10^-1 m = 0.3m
为了更简略地描述这个距离,科学家们创造了一个专门的单位,叫光尺(light-foot)。简单说,“光的速度是每纳秒一英尺”("The speed of light is one foot per nanosecond.“),其精确长度是29.9792458 cm
,与普通的1英尺(30.48厘米)略有差别。
现代计算机的一位伟大拓荒者,编译器的发明人,Grace Hopper曾经努力推动光尺这个计量单位,鼓励大家使用这个单位来更精确地计量、思考和交流。

顺便说一下,美国海军的著名导弹驱逐舰(Missile Destroyer) USS Hopper(DGG 70)就是为纪念Grace Hopper而命名的。在这个军事站点有很详细的介绍,https://www.navysite.de/dd/ddg70.htm。

下面这张表格归纳了计算机世界里常见操作所需的时间。
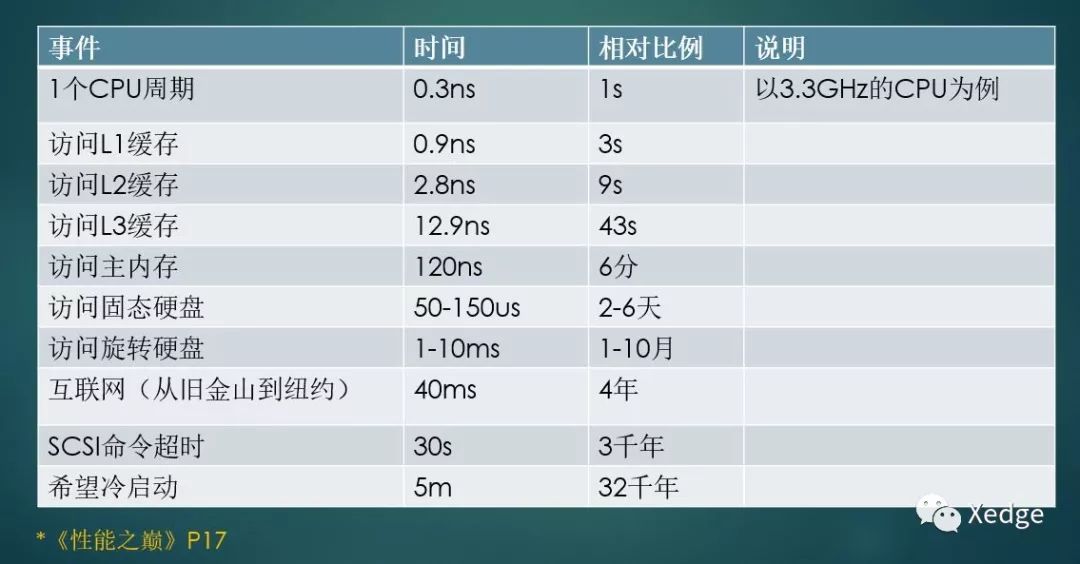
从这张表里,可以看出,CPU是在纳秒级别工作的。对于内部有多条流水线的x86处理器来说,每纳秒可以跑几条,甚至十几条指令(与指令类型和CPI有关)。
那么在今天,优化软件时应该如何计量时间呢?首先值得说明的是,一些老的取时间的方法已经跟不上时代了。比如,POSIX标准中的clock()函数的时间精度只有10ms。
很多程序中使用gettimeofday()来取时间,它的精度如何呢?其实也只能达到微秒级别(下文会通过试验来测试)。
对于需要深度优化的场景,今天最好的取时间方法是使用CPU的专有机制来读取CPU的时间戳计数器,比如x86的rdtsc指令。
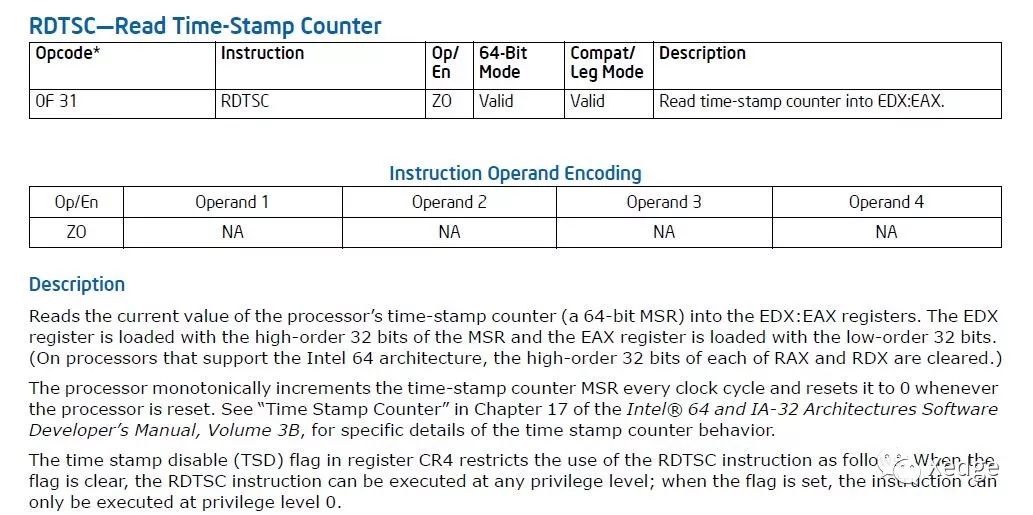
关于rdtsc指令,很多同行有个困惑。既然今天的CPU常常会自动调频工作,那么rdtsc读到的时钟数会不会快慢不均呢?
其实这个顾虑是不必要的。虽然英特尔的手册里没有明确说明这个问题,但其实rdtsc返回的时钟数总是已经按CPU的标定频率做过规范化的。
比如,在笔者的E580 Thinkpad上,CPU的标称频率是1.8GHz。在Linux系统中,执行lscpu命令,在Model name中包含着标称频率。
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
CPU(s): 8
On-line CPU(s) list: 0-7
Thread(s) per core: 2
Core(s) per socket: 4
Socket(s): 1
NUMA node(s): 1
Vendor ID: GenuineIntel
CPU family: 6
Model: 142
Model name: Intel(R) Core(TM) i7-8550U CPU @ 1.80GHz
Stepping: 10
CPU MHz: 800.036
CPU max MHz: 4000,0000
CPU min MHz: 400,0000
BogoMIPS: 3984.00
Virtualization: VT-x
L1d cache: 32K
L1i cache: 32K
L2 cache: 256K
L3 cache: 8192K
NUMA node0 CPU(s): 0-7
Flags: fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm pbe syscall nx pdpe1gb rdtscp lm constant_tsc art arch_perfmon pebs bts rep_good nopl xtopology nonstop_tsc cpuid aperfmperf tsc_known_freq pni pclmulqdq dtes64 monitor ds_cpl vmx est tm2 ssse3 sdbg fma cx16 xtpr pdcm pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer xsave avx f16c rdrand lahf_lm abm 3dnowprefetch cpuid_fault epb invpcid_single pti ssbd ibrs ibpb stibp tpr_shadow vnmi flexpriority ept vpid fsgsbase tsc_adjust bmi1 avx2 smep bmi2 erms invpcid mpx rdseed adx smap clflushopt intel_pt xsaveopt xsavec xgetbv1 xsaves dtherm ida arat pln pts hwp hwp_notify hwp_act_window hwp_epp flush_l1d
其中的CPU MHz是实际工作频率,多次执行lscpu,可以看到这个值是经常变化的。
通过一小段代码就可以感受到tdtsc返回的时钟数是稳定的,不会受频率跳动的影响。
int measure_sleep(int us)
{
long begin, end,delta;
int i=0;
for(int i=0;i<10;i++)
{
begin = __builtin_ia32_rdtsc();
usleep(us);
end = __builtin_ia32_rdtsc();
delta += end - begin;
}
printf("usleep(%ld) 10 times took %ld ticks. %ld ticks in average.\n",
us, delta, delta/10);
}
编译执行这段代码,然后绑定7号CPU执行:
taskset 80 ./nano s 1000000
故意sleep 1s时间,其结果为:
Nano utility by Raymond rev0.1 2018/12/30
usleep(1000000) 10 times took 19927224841 ticks. 1992722484 ticks in average.
重复执行多次,可以看到只有后面的四位略有波动。其结果约为1.99G,理论上,1秒钟的标称时钟数应该为1.8G,但因为实际执行时,ussleep内包含系统调用,还有线程挂起和唤醒的时间,所以数值超过了1.8G。
使用下面的函数,可以策略测量gettimeofday的精度。
int gtd_resolution(long loops)
{
struct timeval t1,t2;
long begin, end;
long i = loops;
begin = __builtin_ia32_rdtsc();
while(i--)
{
gettimeofday(&t1);
do {
gettimeofday(&t2);
}while(t2.tv_usec==t1.tv_usec);
};
end = __builtin_ia32_rdtsc();
printf("Resolution of gettimeofday is %f ticks.\n", (end-begin)*1.0/loops);
return 0;
}
上面代码反复调用gettimeofday函数,记录所取到微秒数变化时的时钟间隔数。在E580上测试到的结果为大约1微妙。
gedu@ThinkE580:~/labs/nano$ ./nano r
Nano utility by Raymond rev0.1 2018/12/30
Resolution of gettimeofday is 1997.566240 ticks.
伟大的Grace Hopper很早预见到了纳秒计量的意义。可惜,她没能看到每纳秒跳动几个时钟的计算机。
无比幸运,我们今天正在经历着计算机的纳秒时代。在纳秒级别对软件做优化是很有挑战也非常有趣的一个领域。
在2018年即将结束之际,特别写作这样一篇短文,纪念这个具有独特意义的年份,也作为格蠹科技公众号的开篇之作。各位朋友,新年快乐!
*****************************
格蠹科技(XEDGE.AI)致力于纳秒级软件优化,发挥芯片每个时钟的效能,提供快速高可用的软件栈
欢迎关注格蠹科技官方公众号