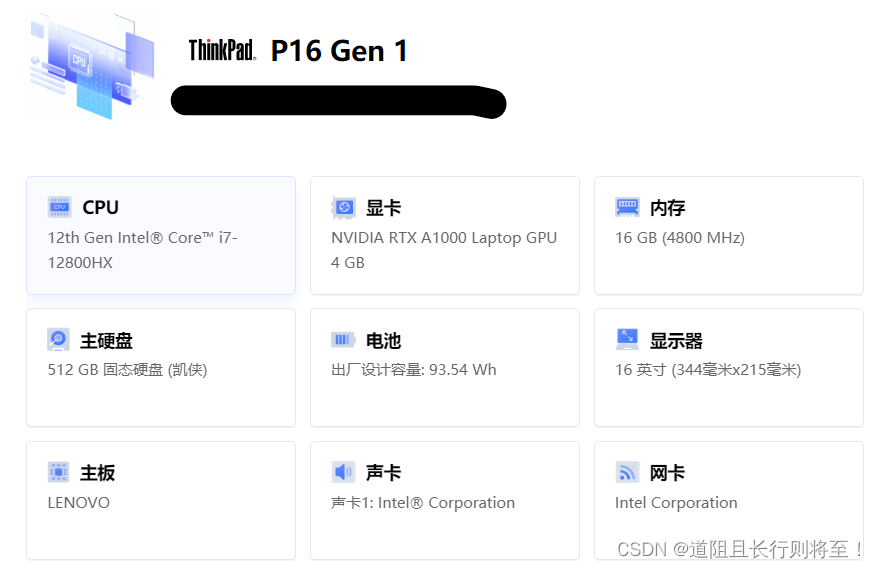
使用 hdf5 配置
1. 包含目录
E:\WorkSpace\SoftWare\hdf5\include
2.库目录
E:\WorkSpace\SoftWare\hdf5\lib\
3.链接器 -输入
hdf5.lib
hdf5_cpp.lib
4. C/C++ -预处理器定义
H5_BUILT_AS_DYNAMIC_LIB;
注意 使用 hdf5 用于 训练 过程
void dataToMat(vector<LandMark> & data, Mat & data_test, Mat & label_test)
{int length = data.size();const int test = length;const int cols_data = 10;const int cols_label = 2;data_test.create(test, cols_data, CV_32FC1);label_test.create(test, cols_label, CV_32FC1);for (size_t i = 0; i < length; i++){//testfloat * ptrd = data_test.ptr<float>(i);float * ptrl = label_test.ptr<float>(i);for (size_t j = 0; j < cols_data / 2; j++){ptrd[2 * j] = data[i].points[j].x;ptrd[2 * j + 1] = data[i].points[j].y;if (j < cols_label){ptrl[j] = data[i].direct[j];}}}
} int length = data.size();const int test = length;const int cols_data = 10;const int cols_label = 2;data_test.create(test, cols_data, CV_32FC1);label_test.create(test, cols_label, CV_32FC1);for (size_t i = 0; i < length; i++){//testfloat * ptrd = data_test.ptr<float>(i);float * ptrl = label_test.ptr<float>(i);for (size_t j = 0; j < cols_data / 2; j++){ptrd[2 * j] = data[i].points[j].x;ptrd[2 * j + 1] = data[i].points[j].y;if (j < cols_label){ptrl[j] = data[i].direct[j];}}}
}void mat2hdf5(Mat &data, Mat &label, const char * filepath, string dataset1, string dataset2)
{int data_cols = data.cols;int data_rows = data.rows;int label_cols = label.cols;int label_rows = label.rows;hid_t file_id;herr_t status;file_id = H5Fcreate(filepath, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);int rank_data = 2, rank_label = 2;hsize_t dims_data[2];hsize_t dims_label[2];dims_data[0] = data_rows;dims_data[1] = data_cols;dims_label[0] = label_rows;dims_label[1] = label_cols;hid_t data_id = H5Screate_simple(rank_data, dims_data, NULL);hid_t label_id = H5Screate_simple(rank_label, dims_label, NULL);hid_t dataset_id = H5Dcreate2(file_id, dataset1.c_str(), H5T_NATIVE_FLOAT, data_id, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);hid_t labelset_id = H5Dcreate2(file_id, dataset2.c_str(), H5T_NATIVE_FLOAT, label_id, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);int i, j;float* data_mem = new float[data_rows*data_cols];float **array_data = new float*[data_rows];for (j = 0; j < data_rows; j++) {array_data[j] = data_mem + j* data_cols;for (i = 0; i < data_cols; i++){array_data[j][i] = data.at<float>(j, i);}}float * label_mem = new float[label_rows*label_cols];float **array_label = new float*[label_rows];for (j = 0; j < label_rows; j++) {array_label[j] = label_mem + j*label_cols;for (i = 0; i < label_cols; i++){array_label[j][i] = label.at<float>(j, i);}}status = H5Dwrite(dataset_id, H5T_NATIVE_FLOAT, H5S_ALL, H5S_ALL, H5P_DEFAULT, array_data[0]);status = H5Dwrite(labelset_id, H5T_NATIVE_FLOAT, H5S_ALL, H5S_ALL, H5P_DEFAULT, array_label[0]);//关闭status = H5Sclose(data_id);status = H5Sclose(label_id);status = H5Dclose(dataset_id);status = H5Dclose(labelset_id);status = H5Fclose(file_id);delete[] array_data;delete[] array_label;
} int data_cols = data.cols;int data_rows = data.rows;int label_cols = label.cols;int label_rows = label.rows;hid_t file_id;herr_t status;file_id = H5Fcreate(filepath, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);int rank_data = 2, rank_label = 2;hsize_t dims_data[2];hsize_t dims_label[2];dims_data[0] = data_rows;dims_data[1] = data_cols;dims_label[0] = label_rows;dims_label[1] = label_cols;hid_t data_id = H5Screate_simple(rank_data, dims_data, NULL);hid_t label_id = H5Screate_simple(rank_label, dims_label, NULL);hid_t dataset_id = H5Dcreate2(file_id, dataset1.c_str(), H5T_NATIVE_FLOAT, data_id, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);hid_t labelset_id = H5Dcreate2(file_id, dataset2.c_str(), H5T_NATIVE_FLOAT, label_id, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);int i, j;float* data_mem = new float[data_rows*data_cols];float **array_data = new float*[data_rows];for (j = 0; j < data_rows; j++) {array_data[j] = data_mem + j* data_cols;for (i = 0; i < data_cols; i++){array_data[j][i] = data.at<float>(j, i);}}float * label_mem = new float[label_rows*label_cols];float **array_label = new float*[label_rows];for (j = 0; j < label_rows; j++) {array_label[j] = label_mem + j*label_cols;for (i = 0; i < label_cols; i++){array_label[j][i] = label.at<float>(j, i);}}status = H5Dwrite(dataset_id, H5T_NATIVE_FLOAT, H5S_ALL, H5S_ALL, H5P_DEFAULT, array_data[0]);status = H5Dwrite(labelset_id, H5T_NATIVE_FLOAT, H5S_ALL, H5S_ALL, H5P_DEFAULT, array_label[0]);//关闭status = H5Sclose(data_id);status = H5Sclose(label_id);status = H5Dclose(dataset_id);status = H5Dclose(labelset_id);status = H5Fclose(file_id);delete[] array_data;delete[] array_label;
}double predict(Mat &img, MCLC & mclc, int net_id, LandMark & landmark, int mark_num)
{double time = 0;double t0 = (double)cvGetTickCount();vector<Mat> imgdata;imgdata.push_back(img);unordered_map<std::string, DataBlob> result = mclc.Forward(imgdata, net_id);double t1 = (double)cvGetTickCount();time = (t1 - t0) / ((double)cvGetTickFrequency() * 1000);//cout << "time is:" << time << " ms" << endl;for (unordered_map<string, DataBlob>::iterator iter = result.begin(); iter != result.end(); iter++) {string key = iter->first;DataBlob result1 = iter->second;vector<int> mt = result1.size;if (result1.name == "ip2"){for (int i = 0; i < mark_num; i++){landmark.direct[i] = *(result1.data);(result1.data)++;}}}return time;
}//预测代码
main()
{
for (int i = 0; i < 20; i++){Rect rect(0, i, 10, 1);LandMark landmark;Mat pointM = data_test(rect);//cout << pointM << endl; 打印看 pointM 是否是正确的。predict(pointM, mclc, id_3, landmark, 3);for (size_t j = 0; j < 3; j++){cout << landmark.direct[j] << " : " <<label_test.at<float>(i, j) << " :::"<<getRoll(pointM)<< endl;}}
}注意:数量类型 如果数量是 Float 就使用 CV_32FC1 如果 是Int 就使用 CV_32SC1
Tip:
如果想生成 矩阵类型的数据,一定要保证 数据是连续的可以访问的。
例如下面 的
data_mem = new float[data_rows*data_cols];
或者是 如果知道 矩阵的长和宽 直接用 二维数组 arr[rows][cols] ; 这样的也是连续的。
void mat2hdf5(Mat &data, Mat &label, const char * filepath)
{int data_cols = data.cols;int data_rows = data.rows;int label_cols = label.cols;int label_rows = label.rows;hid_t file_id;herr_t status;file_id = H5Fcreate(filepath, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);int rank_data = 2, rank_label = 2;hsize_t dims_data[2];hsize_t dims_label[2];dims_data[0] = data_rows;dims_data[1] = data_cols;dims_label[0] = label_rows;dims_label[1] = label_cols;hid_t data_id = H5Screate_simple(rank_data, dims_data, NULL);hid_t label_id = H5Screate_simple(rank_label, dims_label, NULL);hid_t dataset_id = H5Dcreate2(file_id, "data", H5T_NATIVE_FLOAT, data_id, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);hid_t labelset_id = H5Dcreate(file_id, "label", H5T_NATIVE_FLOAT, label_id, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);int i, j;float* data_mem = new float[data_rows*data_cols];float **array_data = new float*[data_rows];for (j = 0; j < data_rows; j++) {array_data[j] = data_mem + j* data_cols;for (i = 0; i < data_cols; i++){array_data[j][i] = data.at<float>(j, i);}}float * label_mem = new float[label_rows*label_cols];float **array_label = new float*[label_rows];for (j = 0; j < label_rows; j++) {array_label[j] = label_mem + j*label_cols;for (i = 0; i < label_cols; i++){array_label[j][i] = label.at<float>(j, i);}}status = H5Dwrite(dataset_id, H5T_NATIVE_FLOAT, H5S_ALL, H5S_ALL, H5P_DEFAULT, array_data[0]);status = H5Dwrite(labelset_id, H5T_NATIVE_FLOAT, H5S_ALL, H5S_ALL, H5P_DEFAULT, array_label[0]);//关闭status = H5Sclose(data_id);status = H5Sclose(label_id);status = H5Dclose(dataset_id);status = H5Dclose(labelset_id);status = H5Fclose(file_id);delete[] array_data;delete[] array_label;
}
3. HDF5文件结构
3.1 HDF5文件格式
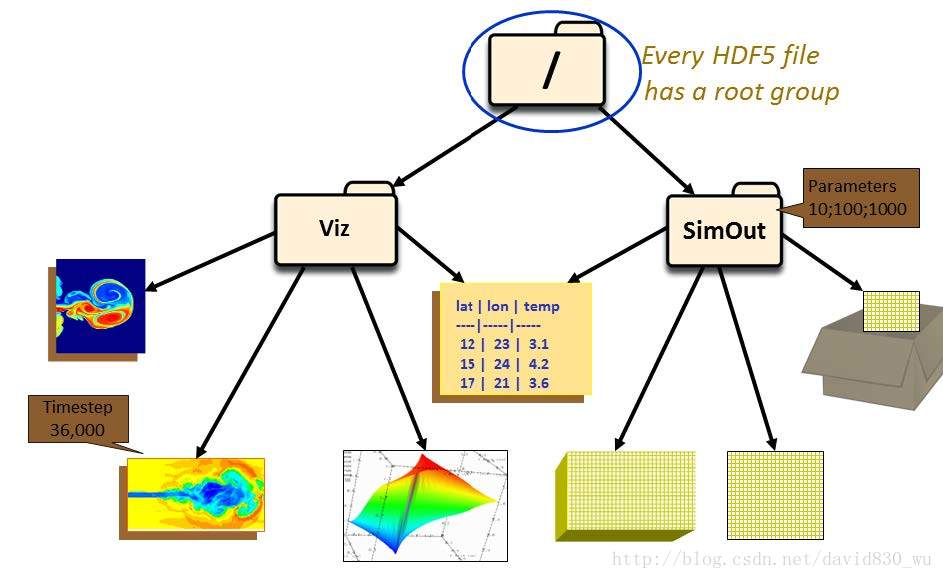
3.2 HDF5结构模型
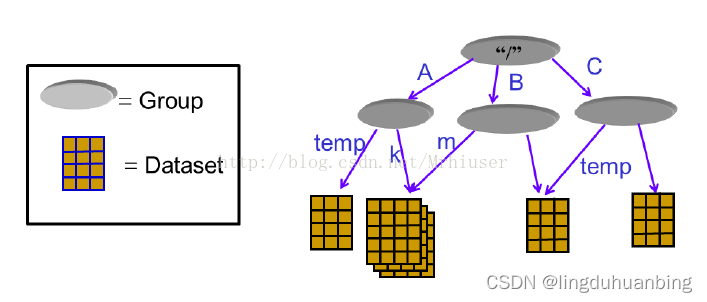
为了方便数据的组织,HDF5文件通过group的方式组织成树状结构,每个group都是树的节点。
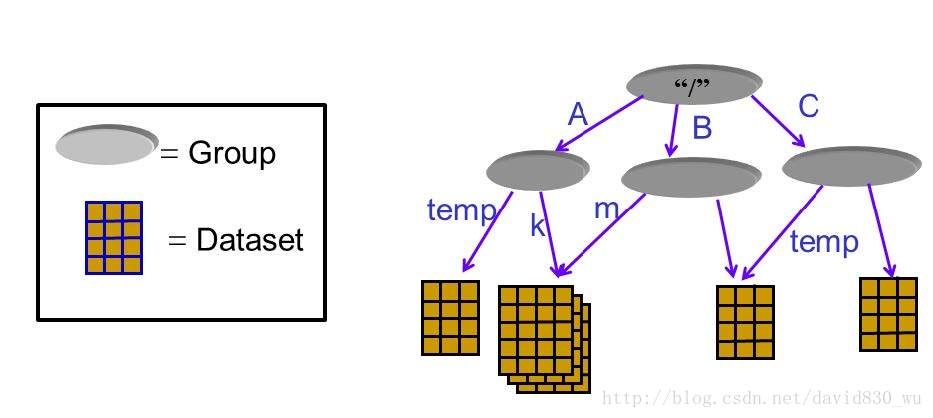
每一个dataset包含两部分的数据,Metadata和Data。其中Metadata包含Data相关的信息,而Data则包含数据本身。
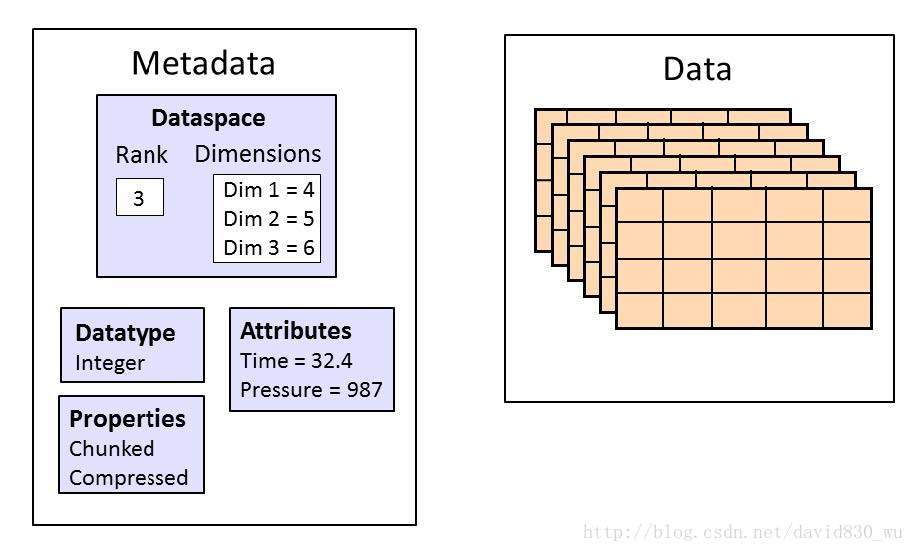
3.3 内置数据类型
| C类型 | HDF5内存类型 | HDF5文件类型1 |
|---|---|---|
| Integer : | ||
| int | H5T_NATIVE_INT | H5T_STD_I32BE or H5T_STD_I32LE |
| short | H5T_NATIVE_SHORT | H5T_STD_I16BE or H5T_STD_I16LE |
| long | H5T_NATIVE_LONG | H5T_STD_I32BE, H5T_STD_I32LE, H5T_STD_I64BE or H5T_STD_I64LE |
| long long | H5T_NATIVE_LLONG | H5T_STD_I64BE or H5T_STD_I64LE |
| unsigned int | H5T_NATIVE_UINT | H5T_STD_U32BE or H5T_STD_U32LE |
| unsigned short | H5T_NATIVE_USHORT | H5T_STD_U16BE or H5T_STD_U16LE |
| unsigned long | H5T_NATIVE_ULONG | H5T_STD_U32BE, H5T_STD_U32LE, H5T_STD_U64BE or H5T_STD_U64LE |
| unsigned long long | H5T_NATIVE_ULLONG | H5T_STD_U64BE or H5T_STD_U64LE |
| Float : | ||
| float | H5T_NATIVE_FLOAT | H5T_IEEE_F32BE or H5T_IEEE_F32LE |
| double | H5T_NATIVE_DOUBLE | H5T_IEEE_F64BE or H5T_IEEE_F64LE |
3.4 HDF5工具群
- h5dump
- hDFview
- h5cc/h5c++
4. HDF5快速上手全攻略
一般的操作一个HDF5对象的步骤是
- 打开这个对象;
- 对这个对象进行操作;
- 关闭这个对象。
特别要注意的是,一定要在操作结束后关闭对象。因为之前的操作只是生成操作的流程,并不真正执行操作,只有关闭对象操作才会真正出发对对象进行的修改。
4.1 文件(Files)创建/打开/关闭
Python代码
import h5py
# 以写入方式打开文件
# r 只读,文件必须已存在
# r+ 读写,文件必须已存在
# w 新建文件,若存在覆盖
# w- 或x,新建文件,若存在报错
# a 如存在则读写,不存在则创建(默认)
file = h5py.File('file.h5', 'w')
file.close()# 打开文件
file_open = h5py.File('file.h5', 'r+')
file_open.close()
C代码
#include "hdf5.h"
int main(){// hid_t是HDF5对象id通用数据类型,每个id标志一个HDF5对象hid_t file_id;// herr_t是HDF5报错和状态的通用数据类型herr_t status;// 文件id = H5Fcreate(const char *文件名,// unsigned 是否覆盖的flags,// - H5F_ACC_TRUNC->能覆盖// - H5F_ACC_EXCL->不能覆盖,报错// hid_t 建立性质,hid_t 访问性质);file_id = H5Fcreate("file.h5", H5F_ACC_TRUNC,H5P_DEFAULT, H5P_DEFAULT);status = H5Fclose(file_id);// 打开刚建立的HDF文件并关闭// 文件id = H5Fopen(const char *文件名, // unsigned 读写flags,// - H5F_ACC_RDWR可读写// - H5F_ACC_RDONLY只读 // hid_t 访问性质)hit_t file_open_id;file_id = H5Fopen("file.h5", H5F_ACC_RDWR, H5P_DEFAULT);status = H5Fclose(file_id);return 0;
}
4.2 群(Group)的建立
Python中将文件树表述成一个dict,keys值是groups成员的名字,values是成员对象(groups或者datasets)本身。文件对象本身作为root group。
Python代码
import h5py
f = h5py.File('foo.hdf5','w')
f.name # output = '/'
[k for k in f.keys()] # output = []# 创建一个group
# 1. 相对地址方法
grp = f.create_group("bar")
grp.name # output = '/bar'
subgrp = grp.create_group("baz")
subgrp.name # output = '/bar/baz'
# 2. 绝对地址创建多个group
grp2 = f.create_group("/some/long/path")
grp2.name # output = '/some/long/path'
grp3 = f['/some/long']
grp3.name # output = '/some/long'
# 3. 删除一个group
del f['bar']# 最终一定要记得关闭文件才能保存
f.close()
在C/C++中组的创建使用一个宏H5Gcreate(),这个宏将调用不同版本的组创建函数H5Gcreate1()和H5Gcreate2(),其中1.8.x版本的宏指向H5Gcreate2()。
注意: 在C库中,group只能一层一层创建,子group只有在创建好父group后才能创建,不能一次创建多层group。
C代码
#include <iostream>
#include <string>
#include "hdf5.h"int main(int argc, char* argv[]) {// 打开HDF5文件hid_t file_id;herr_t status;file_id = H5Fcreate("my_file.h5", H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);// 创建groupshid_t group_id, group2_id;// new_group_id = H5Gcreate2(group_id,// 绝对或者相对group链接名,// 链接(link)创建性质,// group创建性质,// group访问性质);group_id = H5Gcreate(file_id, "/MyGroup1", H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);group2_id = H5Gcreate(group_id, "/MyGroup1/MyGroup2"), H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);// 上面绝对路径也可用下面的相对路径替代//group2_id = H5Gcreate(group_id, "MyGroup2"), H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);//group2_id = H5Gcreate(group_id, "./MyGroup2"), H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);// 关闭group组status = H5Gclose(group2_id);status = H5Gclose(group_id);// 利用H5Gopen打开一个组// group_id = H5Gopen2(父group_id,// 绝对或者相对group链接名,// group访问性质);group_id = H5Gopen(file_id, "MyGroup1/MyGroup2", H5P_DEFAULT);status = H5Gclose(group_id);// 关闭文件,保存更改status = H5Fclose(file_id);return 0;
}
那么对于一个组,我们想知道它是否存在在,应该如何检测呢?如果直接进行读取,那么HDF5会进行报错,所以,我们需要先关闭报错机制,然后进行检验。代码如下
#include <iostream>
#include "hdf5.h"int main(int argc, char* argv[]) {// 打开HDF5文件hid_t file_id;herr_t status;file_id = H5Fcreate("my_file.h5", H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);// 创建"/MyGroup1/MyGroup2"hid_t group_id, group2_id;group_id = H5Gcreate(file_id, "/MyGroup1", H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);group2_id = H5Gcreate(group_id, "/MyGroup1/MyGroup2"), H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);// 关闭group组status = H5Gclose(group2_id);status = H5Gclose(group_id);// 检查"/MyGroup1/MyGroup2"是否存在// 临时关闭错误堆栈自动打印功能// herr_t H5Eset_auto2( hid_t estack_id, 要设置的错误堆栈,当前堆栈是H5E_DEFAULT// H5E_auto2_t func, 遇到错误时调用的,默认是类型转换为(H5E_auto2_t)后的H5Eprint2,将错误堆栈打印// void *client_data 传递给错误处理函数的数据,默认是标准错误流stderr)status = H5Eset_auto(H5E_DEFAULT, NULL, NULL);// 获取组的信息// H5Lget_info( hid_t link_loc_id, 连接(link)位置id// const char *link_name, 连接名字id// H5L_info_t *link_buff, 连接的信息结构体buffer,详见H5L_info_t// hid_t lapl_id 访问性质列表)status = H5Lget_info(file_id, "MyGroup1/MyGroup2", NULL, H5P_DEFAULT);printf("/MyGroup1/MyGroup2: ");if (status == 0) printf("The group exists.\n");elseprintf("The group either does NOT exist or some other error occurred.\n");// 检查"/MyGroup1/MyGroupABC"是否存在status = H5Lget_info(file_id, "MyGroup1/MyGroupABC", NULL, H5P_DEFAULT);printf("/MyGroup1/GroupABC: ");if (status == 0)printf("The group exists.\n");elseprintf("The group either does NOT exist or some other error occurred.\n");// 开启错误堆栈自动打印功能status = H5Eset_auto(H5E_DEFAULT, (H5E_auto2_t)H5Eprint2, stderr);// close the filestatus = H5Fclose(file_id);return 0;
}4.3 数据集(Dataset)的创建
H5py中的dataset很类似与Numpy中的array,但支持一些列透明(针对连续存储的选择操作对分块存储同样有效)的存储特性,还支持分块,压缩,和错误校验。
新的数据集可以通过group.create_dateset()或者group.require_dateset()记性创建。已经存在的数据已可以通过群的所以语法进行访问dset = group[“dset_name”]。
python代码
import h5py
import numpy as np
f = h5py.File('file.h5','w')#创建数据集
# dataset = group.create_dateset(name,
# shape=None,
# dtype=None,
# data=None)
dset = f.create_dateset("default", (100,))
dset = f.create_dateset("ints", (100,), dtype='i8')
dset = f.create_dateset("init", data=np.arange(100))# 读取数据集可以采用索引操作
read_dset = f["default"]# 数据集的删除,注意这样做只是删除链接,但文件中所申请的空间无法收回
f.__delitem__("ints") # version 1
del f['init'] # version 2f.close()
在C/C++语言中,dataspace一共有三种形式
- H5S_SCALAR: 标量,只有一个元素,rank为0
- H5S_SIMPLE:正常的数组形式的元素
- H5S_NULL:没有数据元素
其中最常用的是H5S_SIMPLE类型,它有一个直接的生成函数H5Screate_simple()
其中H5Dwrite()函数匹配内存spaceid和文件spaceid的行为如下,
| mem_space_id | file_space_id | Behavior |
|---|---|---|
| 有效id | 有效id | mem_space_id specifies the memory dataspace and the selection within it. file_space_id specifies the selection within the file dataset’s dataspace. |
| H5S_ALL | 有效id | The file dataset’s dataspace is used for the memory dataspace and the selection specified with file_space_id specifies the selection within it. The combination of the file dataset’s dataspace and the selection from file_space_id is used for memory also. |
| 有效id | H5S_ALL | mem_space_id specifies the memory dataspace and the selection within it. The selection within the file dataset’s dataspace is set to the “all” selection. |
| H5S_ALL | H5S_ALL | The file dataset’s dataspace is used for the memory dataspace and the selection within the memory dataspace is set to the “all” selection. The selection within the file dataset’s dataspace is set to the “all” selection. |
写入程序
#include <iostream>
#include <string>
#include "hdf5.h"int main(int argc, char* argv[]) {// 为矩阵matrix进行内存分配,这里采用了技巧分配了连续内存int rows = 10;int columns = 8;double* data_mem = new double[rows*columns];double** matrix = new double*[rows];for (int i = 0; i < rows; i++)matrix[i] = data_mem + i*columns;// 为matrix矩阵填入数据,元素个数的整数部分为行号,分数部分为列号for (int r = 0; r < rows; r++) {for (int c = 0; c < columns; c++) {matrix[r][c] = r + 0.01*c;}}// 打开HDF5文件hid_t file_id;herr_t status;file_id = H5Fcreate("my_file.h5", H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);// 创建数据集的metadata中的dataspace信息项目unsigned rank = 2;hsize_t dims[2];dims[0] = rows;dims[1] = columns;hid_t dataspace_id; // 数据集metadata中dataspace的id// dataspace_id = H5Screate_simple(int rank, 空间维度// const hsize_t* current_dims, 每个维度元素个数// - 可以为0,此时无法写入数据// const hsize_t* max_dims, 每个维度元素个数上限// - 若为NULL指针,则和current_dim相同,// - 若为H5S_UNLIMITED,则不舍上限,但dataset一定是分块的(chunked).dataspace_id = H5Screate_simple(rank, dims, NULL);// 创建数据集中的数据本身hid_t dataset_id; // 数据集本身的id// dataset_id = H5Dcreate(loc_id, 位置id// const char *name, 数据集名// hid_t dtype_id, 数据类型// hid_t space_id, dataspace的id// 连接(link)创建性质,// 数据集创建性质,// 数据集访问性质)dataset_id = H5Dcreate(file_id, "/dset", H5T_NATIVE_DOUBLE, dataspace_id, H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);// 将数据写入数据集// herr_t 写入状态 = H5Dwrite(写入目标数据集id,// 内存数据格式,// memory_dataspace_id, 定义内存dataspace和其中的选择// - H5S_ALL: 文件中dataspace用做内存dataspace,file_dataspace_id中的选择作为内存dataspace的选择// file_dataspace_id, 定义文件中dataspace的选择// - H5S_ALL: 文件中datasapce的全部,定义为数据集中dataspace定义的全部维度数据// 本次IO操作的转换性质,// const void * buf, 内存中数据的位置status = H5Dwrite(dataset_id, H5T_NATIVE_DOUBLE, H5S_ALL, H5S_ALL, H5P_DEFAULT, matrix[0]);// 关闭dataset相关对象status = H5Dclose(dataset_id);status = H5Sclose(dataspace_id);// 关闭文件对象status = H5Fclose(file_id);// 释放动态分配的内存delete[] matrix;delete[] data_mem;return 0;
}
读出程序
#include <iostream>
#include <string>
#include "hdf5.h"int main(int argc, char* argv[]) {// 为矩阵matrix进行内存分配,这里采用了技巧分配了连续内存int rows = 10;int columns = 8;double* data_mem = new double[rows*columns];double** matrix = new double*[rows];for (int i = 0; i < rows; i++)matrix[i] = data_mem + i*columns;// 打开HDF5文件hid_t file_id;herr_t status;file_id = H5Fopen("my_file.h5", H5F_ACC_RDWR, H5P_DEFAULT);// 创建数据集中的数据本身hid_t dataset_id; // 数据集本身的id// dataset_id = H5Dopen(group位置id,// const char *name, 数据集名// 数据集访问性质)dataset_id = H5Dopen(file_id, "/dset", H5P_DEFAULT);// 将数据写入数据集// herr_t 读取状态 = H5Dread(写入目标数据集id,// 内存数据类型,// memory_dataspace_id, 定义内存dataspace和其中的选择// - H5S_ALL: 文件中dataspace用做内存dataspace,file_dataspace_id中的选择作为内存dataspace的选择// file_dataspace_id, 定义文件中dataspace的选择// - H5S_ALL: 文件中datasapce的全部,定义为数据集中dataspace定义的全部维度数据// 本次IO操作的转换性质,// const void * buf, 内存中接受数据的位置status = H5Dread(dataset_id, H5T_NATIVE_DOUBLE, H5S_ALL, H5S_ALL, H5P_DEFAULT, matrix[0]);// 关闭dataset相关对象status = H5Dclose(dataset_id);status = H5Sclose(dataspace_id);// 关闭文件对象status = H5Fclose(file_id);// 释放动态分配的内存delete[] matrix;delete[] data_mem;return 0;
}
4.4 数据集读取与子集索引(Subsetting)
4.4.1 Python部分
h5py库采用numpy的切片语法来读写文件中的数据集,因此熟悉numpy的索引规则用起HDF5的“hyperslab”选择是非常容易的,这也是快速读且HDF5文件中数据集的方法。
下面是四个能够被识别的用法
- 索引
- 切片(比如[:]或者[0:10])
- 域名,在符合数据中使用
- 最多一个省略(Ellipsis),即(…),对象
例如
>>> dset = f.create_dataset("MyDataset", (10,10,10), 'f')
>>> dset[0,0,0]
>>> dset[0,2:10,1:9:3]
>>> dset[:,::2,5]
>>> dset[0]
>>> dset[1,5]
>>> dset[0,...]
>>> dset[...,6]
>>> # 对于符合数据
>>> dset["FieldA"]
>>> dset[0,:,4:5, "FieldA", "FieldB"]
>>> dset[0, ..., "FieldC"]
>>> # 广播在索引中依然被支持
>>> dset[0,:,:] = np.arange(10) # 广播到(10,10)
>>> # 对于标量数据集,采用和numpy相同的语法结果,利用空tuple做索引,即
>>> scalar_result = dset[()]
花式索引(Fancy Indexing)
一部分numpy花式索引在HDF5中也支持,比如
>>> dset.shape
(10, 10)
>>> result = dset[0, [1,3,8]]
>>> result.shape
(3,)
>>> result = dset[1:6, [5,8,9]]
>>> result.shape
(5, 3)单使用受到一些限制
- 选择列表不能为空
- 选择坐标必须要以升序方式给出
- 重复项忽略
- 长列表(>1k元素)将速度很慢
numpy的逻辑索引可以用来进行选择,比如
>>> arr = numpy.arange(100).reshape((10,10))
>>> dset = f.create_dataset("MyDataset", data=arr)
>>> result = dset[arr > 50]
>>> result.shape
(49,)
和numpy一样,len()函数返回dataset中第一个轴的长度。但是如果在32位平台上第一个轴长度超过2^32时len(dataset)将失效,因此推荐使用dataset.len()方法。
4.4.2 C/C++部分
在C语言中,访问原数据集子集的关键在于构造内存的dataspace,通过内存和文件中dataspace的配合实现访问选择子集的效果。在HDF5中,有两种选择,元素(element)选择和超块(hyperslab)选择,分别通过函数H5Sselect_elements()和H5Sselect_hyperslab()两个函数实现。这两个函数都会修改传入dataspace_id对应的dataspace空间性质,以此实现选择的子集。
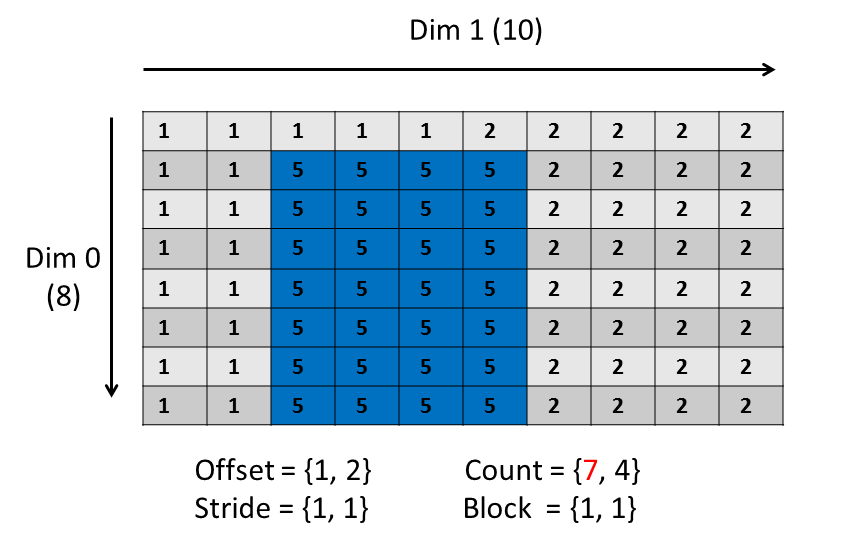
和MPI的子集选择方法相同,HDF5的子集选择定义子集四大件:
- offset: 位置补偿
- stride: 间隙
- count: 块数
- block: 块大小
例如想要从一个(8,10)的dataspace中选择一个如图(7,4)的dataspace,需要定义的四大件如下。

C/C++代码
#include "hdf5.h"#define FILE "subset.h5"
#define DATASETNAME "IntArray"
#define RANK 2#define DIM0_SUB 3 // 子集的维度
#define DIM1_SUB 4 #define DIM0 8 // 原集的维度
#define DIM1 10 int main(int argc, char* argv[]){// 先创建一个文件并写入原始数据集hid_t file_id;file_id = H5Fcreate(FILE, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);hsize_t dims[2];dims[0] = DIM0;dims[1] = DIM1;hid_t dataspace_id, dataset_id;dataspace_id = H5Screate_simple(RANK, dims, NULL);dataset_id = H5Dcreate2(file_id, DATASETNAME, H5T_STD_I32BE, dataspace_id,H5P_DEFAULT, H5P_DEFAULT, H5P_DEFAULT);// 创建写入数据集/* 写入文件中的数据为[1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2]*/int i, j;int data[DIM0][DIM1];for (j = 0; j < DIM0; j++) {for (i = 0; i < DIM1; i++)if (i < (DIM1 / 2))data[j][i] = 1;elsedata[j][i] = 2;}herr_t status;status = H5Dwrite(dataset_id, H5T_NATIVE_INT, H5S_ALL, H5S_ALL,H5P_DEFAULT, data);status = H5Sclose(dataspace_id);status = H5Dclose(dataset_id);status = H5Fclose(file_id);// ************ 对子集进行操作 *****************************// 打开文件中数据集,对子集进行编辑file_id = H5Fopen(FILE, H5F_ACC_RDWR, H5P_DEFAULT);dataset_id = H5Dopen2(file_id, DATASETNAME, H5P_DEFAULT);// 定义子集四大件,补偿,个数,间隔和块大小hsize_t count[2]; // 块的大小hsize_t offset[2]; // 补偿,即开始位置hsize_t stride[2]; // 间隔hsize_t block[2]; // 块的个数offset[0] = 1;offset[1] = 2;count[0] = DIM0_SUB;count[1] = DIM1_SUB;stride[0] = 1;stride[1] = 1;block[0] = 1;block[1] = 1;// 创建内存中的dataspce空间hsize_t dimsm[2];dimsm[0] = DIM0_SUB;dimsm[1] = DIM1_SUB;hid_t memspace_id;memspace_id = H5Screate_simple(RANK, dimsm, NULL);// 读取文件中dataset的dataspace空间dataspace_id = H5Dget_space(dataset_id);// 选取文件中空间的子集和内存空间相对应// stauts = H5Sselect_hyperslab(hid_t space_id, 要修改的space的句柄id// H5S_seloper_t op, 进行的操作// - H5S_SELECT_SET 替换已有选择// - H5S_SELECT_OR 交集// - H5S_SELECT_AND 并集// - H5S_SELECT_XOR 异或,反色操作// - H5S_SELECT_NOTB 减去B// - H5S_SELECT_NOTA 减去A// const hsize_t *start, 位置补偿// const hsize_t *stride, 间隙// const hsize_t *count, 块数// const hsize_t *block 块大小)status = H5Sselect_hyperslab(dataspace_id, H5S_SELECT_SET, offset,stride, count, block);// 生成要填入子集的矩阵int sdata[DIM0_SUB][DIM1_SUB];for (j = 0; j < DIM0_SUB; j++) {for (i = 0; i < DIM1_SUB; i++)sdata[j][i] = 5;}// 文件中的子集写入数据/* 现在文件中的数据为[1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 5, 5, 5, 5, 2, 2, 2, 2;1, 1, 5, 5, 5, 5, 2, 2, 2, 2;1, 1, 5, 5, 5, 5, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2;1, 1, 1, 1, 1, 2, 2, 2, 2, 2]*/status = H5Dwrite(dataset_id, H5T_NATIVE_INT, memspace_id,dataspace_id, H5P_DEFAULT, sdata);status = H5Sclose(memspace_id);status = H5Sclose(dataspace_id);status = H5Dclose(dataset_id);status = H5Fclose(file_id);//************* 完成子集操作 *********************return 0;
}
4.5 添加注释——创建属性(Attribute)
属性是一种dataset的元数据(metadata),它描述了数据的相关信息,可以把属性理解成注释,所有的group和datasets都支持属性。
h5py采用dataset.attrs方法访问属性,比如
import h5py
f = h5py.File('file.h5','w')# 创建数据集
dset = f.create_dateset("mydataset", (100,))
# 为数据集创建注释
dset.attrs['temperature'] = 99.5f.close()
4.6 数据压缩(Compression)
HDF5的数据集默认是连续空间存储的。单可以通过设置让HDF5吧数据进行分块(chunked)存储,也就是说将数据分割为固定大小的小块分开存储,再通过B-Tree进行索引。
分块存储的方式是的数据集可以改变大小,也可以进行压缩过滤。
块的分割大小大概在10KiB到1MiB之间,数据集越大,则块也相应越多。分块以后数据读取将整块郑块的进行,如果对分块干到困惑,python中允许可以直接使用h5py的自动大小(chunks=True)
import h5py
f = h5py.File('file.h5','w')#创建分块数据集
dset_chunk = f.create_dateset("chunked", (1000,1000), chunks=(100,100))
dset_auto = f.create_dateset("chunked_auto", (1000,1000), chunks=True)f.close()
有了分块的数据集,就可以对数据集进行压缩了,通过无损的压缩过滤器可以将数据集进行无损失的压缩,利用函数group.create_dateset(compression=”filter”)。
import h5py
f = h5py.File('file.h5','w')#创建采用gzip压缩过滤器的无损压缩数据集
dset_compress = f.create_dateset("chunked", (1000,1000), compression="gzip")
dset_compressmax = f.create_dateset("chunked_auto", (1000,1000), compression="gzip", compression_opts=9)f.close()
常见的无损压缩过滤器有
- GZIP过滤器(“gzip”): 每个HDF5的标配,中等速度高压缩率,具有参数compression_opts取值从0到9控制压缩等级,默认值为4
- LZF过滤器(“lzf”): 快速但压缩率中等的压缩器
- SZIP过滤器(“szip”): NASA开发的专利保护压缩器
在C++中,分块和压缩性质都是dataset创建性质列表中的内容,通过下面的步骤就可以方便的创建数据集的压缩性质
- 创建数据集创建性质列表
- 在性质列表中设置分块性质
- 在相纸列表中添加压缩过滤器
之后数据集的读写就如同正常的数据集了。演示代码如下
C/C++代码
#include <iostream>
#include "hdf5.h"#define FILE "cmprss.h5"
#define RANK 2
#define DIM0 10000
#define DIM1 200int main() {// 创建文件hid_t file_id;file_id = H5Fcreate(FILE, H5F_ACC_TRUNC, H5P_DEFAULT, H5P_DEFAULT);// 创建数据集空间hsize_t dims[2];dims[0] = DIM0;dims[1] = DIM1;hid_t dataspace_id;dataspace_id = H5Screate_simple(RANK, dims, NULL);// 定义数据集分块性质,压缩需要分块进行hid_t plist_id;// 创建数据集生成的性质列表// hid_t H5Pcreate(hid_t cls_id) 创建性质列表// - H5P_FILE_CREATE 创建文件性质// - H5P_FILE_ACCESS 访问文件性质// - H5P_DATASET_CREATE 数据集创建性质 -> 包含分块性质// - H5P_DATASET_XFER 原始数据转换性质// - H5P_MOUNT 文件挂载性质plist_id = H5Pcreate(H5P_DATASET_CREATE);hsize_t cdims[2];cdims[0] = 200;cdims[1] = 20;herr_t status;// 创建分块的性质// herr_t H5Pset_chunk(hid_t plist, dataset创建性质列表的id// int ndims, 必须和dataset的rank相同// const hsize_t * dim) 给定分块每个维度的元素个数// 该函数会自动将数据集的layout改为H5D_CHUNKEDstatus = H5Pset_chunk(plist_id, 2, cdims);// 设置压缩方法, 'z'为zlib, 's'为szip。char method = 'z';if (method == 'z') {// 开启压缩锁等级为6的ZLIB / DEFLATE压缩,算法和gzip相同// H5Pset_deflate()将创建性质列表中压缩方法设为H5Z_FILTER_DEFLATE过滤器,并设置压缩等级// herr_t H5Pset_deflate( hid_t plist, 数据集创建性质列表的id // uint level ) 压缩等级0-9,压缩等级越高,目标体积越小,压缩率越高,耗时越长status = H5Pset_deflate(plist_id, 6);}else if (method == 's') {// 设置szip压缩// H5Pset_szip将创建数据集性质列表中压缩方法设为H5Z_FILTER_SZIP过滤器,并设置压缩像素大小// herr_t H5Pset_szip(hid_t plist, 数据集创建性质列表的id // unsigned int options_mask, 编码方法设置 // - H5_SZIP_EC_OPTION_MASK 采用熵编码方法:适合处理过的数据,适合小数字// - H5_SZIP_NN_OPTION_MASK 采用最近邻编码:最近邻处理后再调用熵编码处理// unsigned int pixels_per_block) 分块中的像素数,必须比分块小,典型值8,10,16,32,64.// 像素值变化越小,该值应该越小,为了得到最优化表现,推荐数据集变化最快的维度应等于128*分块中像素数status = H5Pset_szip(plist_id, H5_SZIP_NN_OPTION_MASK, 32);}else {std::cerr << "method must be 'z' or 's'" << std::endl;status = H5Pclose(plist_id);status = H5Sclose(dataspace_id);status = H5Fclose(file_id);return -1;}hid_t dataset_id;// 应在数据创建属性列表中填入刚才创建的plist_iddataset_id = H5Dcreate2(file_id, "Compressed_Data", H5T_STD_I32BE,dataspace_id, H5P_DEFAULT, plist_id, H5P_DEFAULT);int* buf_data = new int[DIM0*DIM1];int** buf = new int*[DIM0];for (int i = 0; i < DIM0; i++)buf[i] = buf_data + DIM1*i;for (int i = 0; i< DIM0; i++)for (int j = 0; j<DIM1; j++)buf[i][j] = i + j;status = H5Dwrite(dataset_id, H5T_NATIVE_INT, H5S_ALL, H5S_ALL, H5P_DEFAULT, buf[0]);status = H5Sclose(dataspace_id);status = H5Dclose(dataset_id);status = H5Pclose(plist_id);status = H5Fclose(file_id);// 重新打开刚才写好的文件file_id = H5Fopen(FILE, H5F_ACC_RDWR, H5P_DEFAULT);dataset_id = H5Dopen2(file_id, "Compressed_Data", H5P_DEFAULT);// 读取压缩的数据集无需其他操作,直接读取数据即可status = H5Dread(dataset_id, H5T_NATIVE_INT, H5S_ALL, H5S_ALL,H5P_DEFAULT, buf[0]);status = H5Dclose(dataset_id);status = H5Fclose(file_id);delete[] buf;delete[] buf_data;return 0;
}

![[HDF5]如何使用CMake一起编译自己的代码和HDF5库](https://img-blog.csdnimg.cn/80aad4c59d4d4b2582804c416e00a2b5.jpg)