背景
在做文本相关的任务时,难免会遇见csv,tsv等格式的数据,但有时只是读取,然后传入到下一个任务中而已,并不会做过多的操作。在这种情况下,可以使用pandas读取,但是难免有些臃肿,还引入了pandas中的数据结构,虽然在NLP任务中torchtext可以处理相关格式的文本数据,但是其更侧重于为了模型训练做准备的,这个时候也不太适用了。
其实,Python中自带了csv格式数据的读取和写入的包,使用起来也是比较简洁的,如果经常处理csv,tsv格式数据的话,可以将其封装成对应的工具包。下面记录一下csv这个包的具体使用。当然,最权威的使用当属于官方文档:https://docs.python.org/zh-cn/3.8/library/csv.html?highlight=csv#module-csv。
下文代码使用vscode编写,使用vscode中的Excel Viewer插件查看。
生成csv文件
这里主要介绍生成csv文件的两种方式:csv.writer、csv.DictWriter。
按行写入程序案例
csv格式数据写入案例:
import csvhead = ["head" + str(i) for i in range(1, 6)] # 生成csv headdata_list = [[(i + 1) * j for i in range(5)] for j in range(1, 10)] # 生成数据# newline='',否则会在两行之间插入空白行
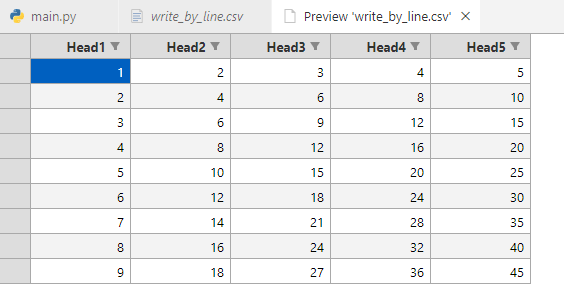
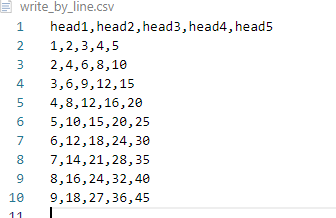
with open('write_by_line.csv', 'w', encoding='utf8', newline="") as f:writer = csv.writer(f) # 构建csv按行书写对象writer.writerow(head) # 单行写入表头writer.writerows(data_list) # 多行数据写入
csv数据如下:
tsv格式数据写入案例,其与csv格式的差别就是在实例化csv按行写入对象中设置delimiter参数为\t。
import csvhead = ["head" + str(i) for i in range(1, 6)] # 生成csv headdata_list = [[(i + 1) * j for i in range(5)] for j in range(1, 10)] # 生成数据# newline='',否则会在两行之间插入空白行
with open('write_by_line.tsv', 'w', encoding='utf8', newline="") as f:writer = csv.writer(f, delimiter='\t') # 构建csv按行书写对象writer.writerow(head) # 单行写入表头writer.writerows(data_list) # 多行数据写入
生成数据如下:
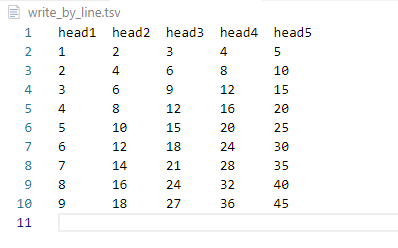
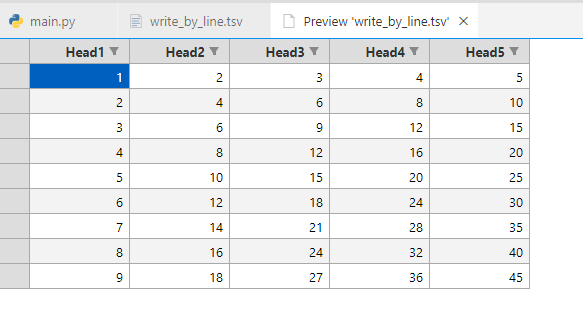
如果生成的文件后缀名不修改成tsv的话,使用Excel Viewer会出现显示异常的情况。
按字典写入对象案例
有时候需要已有的字典数据写入到csv数据中,csv也提供根据字典的key值进行写入,为了更具通用性,下面的程序将按行写入的模块也加入了,最后的代码如下:
import csvdef write_data(style='csv', write_style='list') -> None:head = ["head" + str(i) for i in range(1, 6)] # 生成csv headif write_style == 'list':data_list = [[(i + 1) * j for i in range(5)] for j in range(1, 10)] # 生成数据elif write_style == 'dict':data_list = [{key: j for key in head} for j in range(1, 10)]else:raise Exception(f'this write_style {write_style}, not in ["list", "dict"]')if style == 'csv':delimiter = ','file_name = write_style+"_writer_by_list.csv"elif style == 'tsv':delimiter = '\t'file_name = write_style+"_writer_by_list.tsv"else:raise Exception(f"this style {style} not in ['csv', 'tsv']")# newline='',否则会在两行之间插入空白行with open(file_name, 'w', encoding='utf8', newline="") as f:if write_style == 'list':writer = csv.writer(f, delimiter=delimiter) # 构建csv按行书写对象writer.writerow(head) # 单行写入表头else:writer = csv.DictWriter(f, head)writer.writeheader()writer.writerows(data_list) # 多行数据写入if __name__ == '__main__':write_data(write_style='dict')
生成的数据如下:
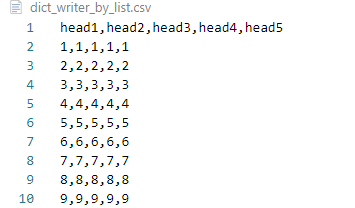
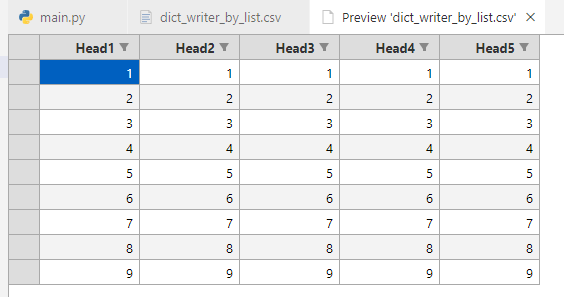
csv数据读取
有了csv文件后,按理也应该有两种读取数据的方式。实例如下:
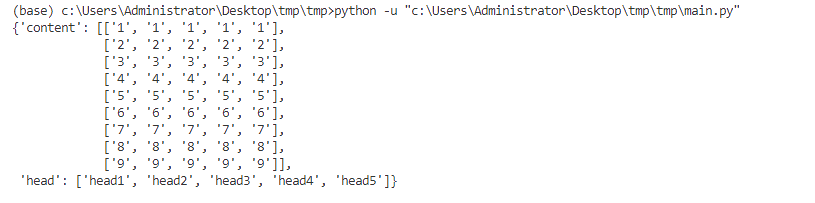
def read_data(file_path, style='csv', delimiter=',') -> Any:assert delimiter in [',', '\t'], f"delimiter must in [',','\t'], you input {delimiter}"data = {}with open(file_path, 'r', encoding='utf8') as f:if style == 'csv':reader = csv.reader(f, delimiter=delimiter)else:reader = csv.DictReader(f, delimiter=delimiter)data["head"] = next(reader)data['content'] = list(reader)return dataif __name__ == '__main__':import pprintdata = read_data("dict_writer_by_list.csv")pprint.pprint(data)
运行结果如下:
总结
总的来说,使用csv内建包,无论数据写入还是数据读取都比较简洁方便,定制化也比较容易,可以根据自己实际的工程需要进行定制化开发。以上的全部代码如下:
import csv
from typing import Anydef write_data(style='csv', write_style='list') -> None:head = ["head" + str(i) for i in range(1, 6)] # 生成csv headif write_style == 'list':data_list = [[(i + 1) * j for i in range(5)] for j in range(1, 10)] # 生成数据elif write_style == 'dict':data_list = [{key: j for key in head} for j in range(1, 10)]else:raise Exception(f'this write_style {write_style}, not in ["list", "dict"]')if style == 'csv':delimiter = ','file_name = write_style+"_writer_by_list.csv"elif style == 'tsv':delimiter = '\t'file_name = write_style+"_writer_by_list.tsv"else:raise Exception(f"this style {style} not in ['csv', 'tsv']")# newline='',否则会在两行之间插入空白行with open(file_name, 'w', encoding='utf8', newline="") as f:if write_style == 'list':writer = csv.writer(f, delimiter=delimiter) # 构建csv按行书写对象writer.writerow(head) # 单行写入表头else:writer = csv.DictWriter(f, head) # 传入头writer.writeheader() # 写入头writer.writerows(data_list) # 多行数据写入def read_data(file_path, style='csv', delimiter=',') -> Any:assert delimiter in [',', '\t'], f"delimiter must in [',','\t'], you input {delimiter}"data = {}with open(file_path, 'r', encoding='utf8') as f:if style == 'csv':reader = csv.reader(f, delimiter=delimiter)else:reader = csv.DictReader(f, delimiter=delimiter)data["head"] = next(reader)data['content'] = list(reader)return dataif __name__ == '__main__':import pprint# write_data(write_style='dict')data = read_data("dict_writer_by_list.csv")pprint.pprint(data)
感谢不错的话,记得给我 “一键三连” 哦