xsync放在家目录的bin下,其他脚本文件也放在该目录下
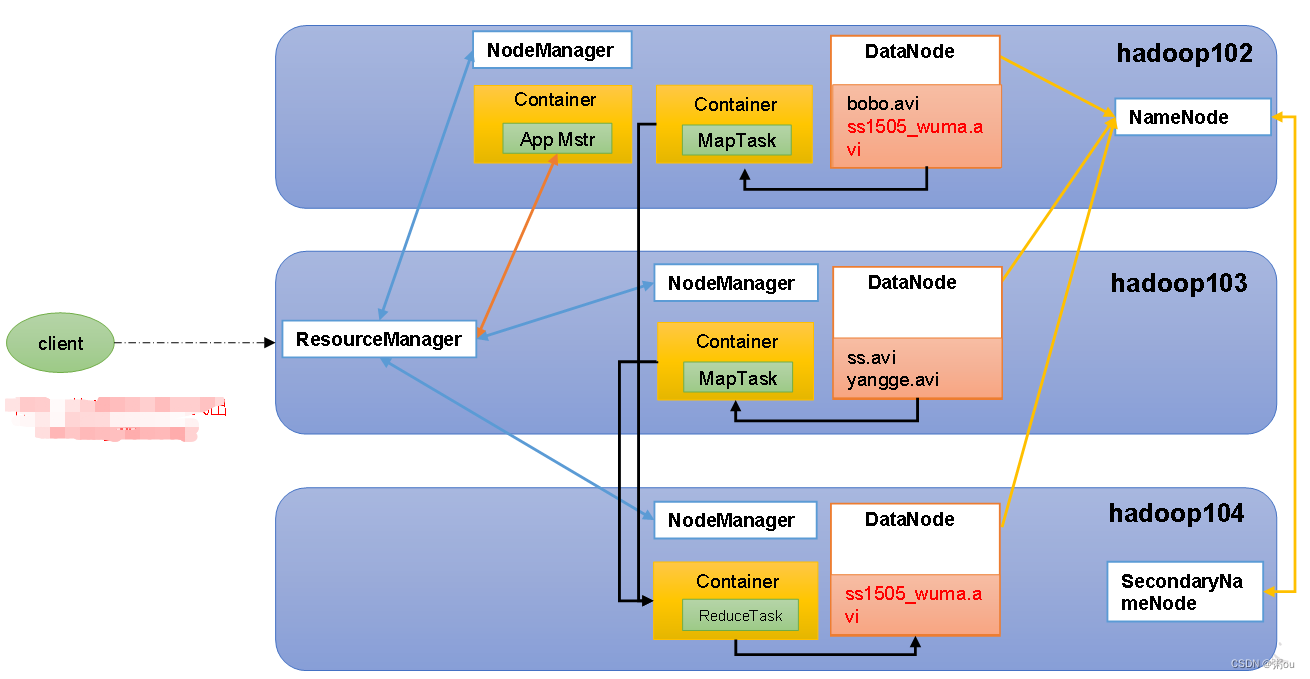
HDFS架构概述:
1)NameNode(nn):存储文件的元数据,如文件名,文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
相当于目录
2)DataNode(dn):再本地文件系统存储文件块数据,以及块数据的校验和
这才是具体的数据
3)Secondary NameDode(2nn):每隔一段时间对NameNode元数据备份
相当于nn的秘书
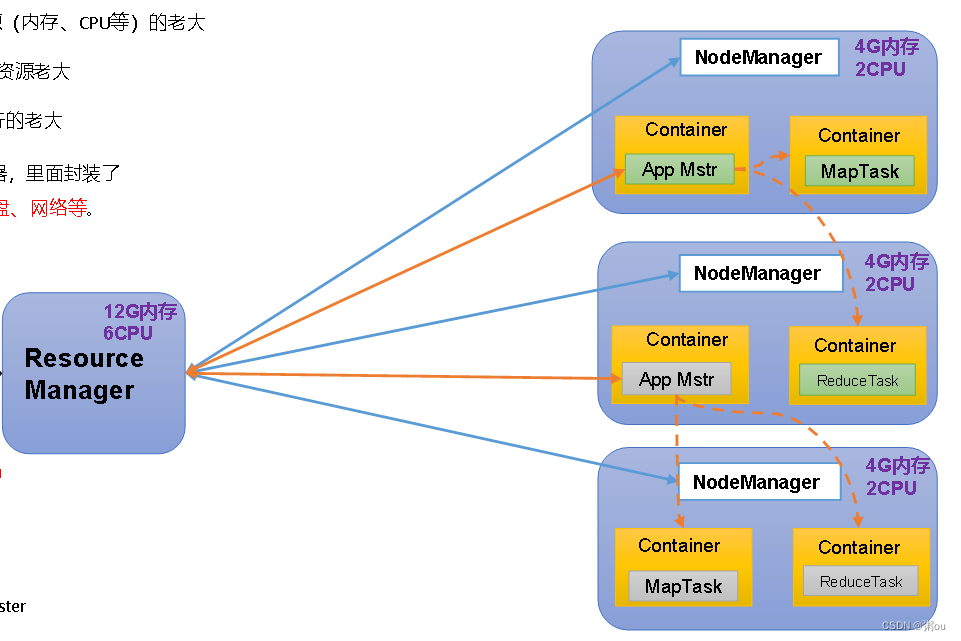
YARN架构概述:
Yet Another Resource Negotiator简称YARN ,另一种资源协调者,是Hadoop的资源管理器
1)ResourceManager(RM):整个集群资源(内存、CPU等)的老大
2)NodeManager(NM):单个节点服务器资源的老大
3)ApplicationMaster(AM):单个任务运行的老大
4)Container:容器,相当一台独立的服务器,里面封装了任务运行所需要的资源,如内存、cpu、磁盘、网络等
MapReduce架构概述:
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总
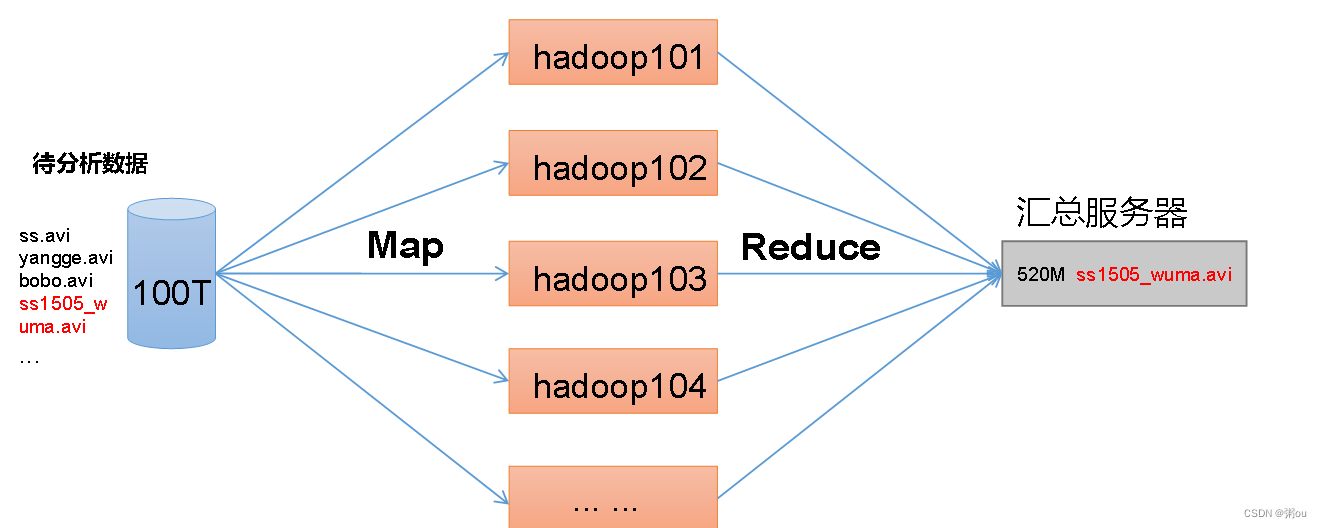
HDFS、YARN、MapReduce三者关系:
集群配置
1)集群部署规划: 有关配置文件都在~/opt/module/hadoop-3.1.3/etc/hadoop 目录下
NameNode和SecondaryNameNode不要安装在同一台服务器
ResourceManager也很消耗内存,不要和NameNode、SecondaryNameNode配置在同一台机器上
2)配置文件说明
hadoop配置文件分两类:默认配置文件和自定义配置文件,只有用户想修改某一默认配置值时,才需要修改自定义配置文件,更改相应属性值


3)配置集群
#注意里这里是 etc/hadoop etc前不能加/,否则就找不到(因为加了后是再根下面找)
[xwt@hadoop102 etc]$ cd /opt/module/hadoop-3.1.3/
[xwt@hadoop102 hadoop-3.1.3]$ ll
总用量 176
drwxr-xr-x. 2 xwt xwt 183 9月 12 2019 bin
drwxr-xr-x. 3 xwt xwt 20 9月 12 2019 etc
drwxr-xr-x. 2 xwt xwt 106 9月 12 2019 include
drwxr-xr-x. 3 xwt xwt 20 9月 12 2019 lib
drwxr-xr-x. 4 xwt xwt 288 9月 12 2019 libexec
-rw-rw-r--. 1 xwt xwt 147145 9月 4 2019 LICENSE.txt
-rw-rw-r--. 1 xwt xwt 21867 9月 4 2019 NOTICE.txt
-rw-rw-r--. 1 xwt xwt 1366 9月 4 2019 README.txt
drwxr-xr-x. 3 xwt xwt 4096 9月 12 2019 sbin
drwxr-xr-x. 4 xwt xwt 31 9月 12 2019 share
[xwt@hadoop102 hadoop-3.1.3]$ cd etc
[xwt@hadoop102 etc]$ ll
总用量 4
drwxr-xr-x. 3 xwt xwt 4096 9月 12 2019 hadoop
[xwt@hadoop102 etc]$ cd hadoop/
[xwt@hadoop102 hadoop]$ ls -al
总用量 176
drwxr-xr-x. 3 xwt xwt 4096 9月 12 2019 .
drwxr-xr-x. 3 xwt xwt 20 9月 12 2019 ..
-rw-r--r--. 1 xwt xwt 8260 9月 12 2019 capacity-scheduler.xml
-rw-r--r--. 1 xwt xwt 1335 9月 12 2019 configuration.xsl
-rw-r--r--. 1 xwt xwt 1940 9月 12 2019 container-executor.cfg
-rw-r--r--. 1 xwt xwt 774 9月 12 2019 core-site.xml
-rw-r--r--. 1 xwt xwt 3999 9月 12 2019 hadoop-env.cmd
-rw-r--r--. 1 xwt xwt 15903 9月 12 2019 hadoop-env.sh
-rw-r--r--. 1 xwt xwt 3323 9月 12 2019 hadoop-metrics2.properties
-rw-r--r--. 1 xwt xwt 11392 9月 12 2019 hadoop-policy.xml
-rw-r--r--. 1 xwt xwt 3414 9月 12 2019 hadoop-user-functions.sh.example
-rw-r--r--. 1 xwt xwt 775 9月 12 2019 hdfs-site.xml
-rw-r--r--. 1 xwt xwt 1484 9月 12 2019 httpfs-env.sh
-rw-r--r--. 1 xwt xwt 1657 9月 12 2019 httpfs-log4j.properties
-rw-r--r--. 1 xwt xwt 21 9月 12 2019 httpfs-signature.secret
-rw-r--r--. 1 xwt xwt 620 9月 12 2019 httpfs-site.xml
-rw-r--r--. 1 xwt xwt 3518 9月 12 2019 kms-acls.xml
-rw-r--r--. 1 xwt xwt 1351 9月 12 2019 kms-env.sh
-rw-r--r--. 1 xwt xwt 1747 9月 12 2019 kms-log4j.properties
-rw-r--r--. 1 xwt xwt 682 9月 12 2019 kms-site.xml
-rw-r--r--. 1 xwt xwt 13326 9月 12 2019 log4j.properties
-rw-r--r--. 1 xwt xwt 951 9月 12 2019 mapred-env.cmd
-rw-r--r--. 1 xwt xwt 1764 9月 12 2019 mapred-env.sh
-rw-r--r--. 1 xwt xwt 4113 9月 12 2019 mapred-queues.xml.template
-rw-r--r--. 1 xwt xwt 758 9月 12 2019 mapred-site.xml
drwxr-xr-x. 2 xwt xwt 24 9月 12 2019 shellprofile.d
-rw-r--r--. 1 xwt xwt 2316 9月 12 2019 ssl-client.xml.example
-rw-r--r--. 1 xwt xwt 2697 9月 12 2019 ssl-server.xml.example
-rw-r--r--. 1 xwt xwt 2642 9月 12 2019 user_ec_policies.xml.template
-rw-r--r--. 1 xwt xwt 10 9月 12 2019 workers
-rw-r--r--. 1 xwt xwt 2250 9月 12 2019 yarn-env.cmd
-rw-r--r--. 1 xwt xwt 6056 9月 12 2019 yarn-env.sh
-rw-r--r--. 1 xwt xwt 2591 9月 12 2019 yarnservice-log4j.properties
-rw-r--r--. 1 xwt xwt 690 9月 12 2019 yarn-site.xml(1)核心配置文件 配置core-site.xml
[xwt@hadoop102 hadoop]$ vim core-site.xml
#zai configuration下粘贴<!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop102:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/module/hadoop-3.1.3/data</value></property><!-- 配置HDFS网页登录使用的静态用户为xwt --><property><name>hadoop.http.staticuser.user</name><value>xwt</value></property>(2)HDFS配置文件 配置hdfs-site.xml 得让别人能从外部访问
[xwt@hadoop102 hadoop]$ vim hdfs-site.xml
#插入
<!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop102:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop104:9868</value></property>(3)YARN配置文件 配置yarn-site.xml
[xwt@hadoop102 hadoop]$ vim yarn-site.xml
#插入
<!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop103</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>(4)MapReduce配置文件 配置mapred-site.xml
[xwt@hadoop102 hadoop]$ vim mapred-site.xml
#插入
<!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>注意,这里全都是再102(在/opt/module/hadoop-3.1.3/etc/hadoop/)上进行操作,还需要将这里的配置分发到103、104
群起集群
1)配置workers 集群上有几个节点就配置几个主机名称
注意:该文件中添加的内容结尾不允许有空格,文件中不允许有空行。
[xwt@hadoop102 hadoop]$ vim workers 记得同步一下xsync workers
2)启动集群
如果集群是第一次启动,需进行格式化
[xwt@hadoop102 hadoop-3.1.3]$ hdfs namenode -format查看当前服务器的版本号
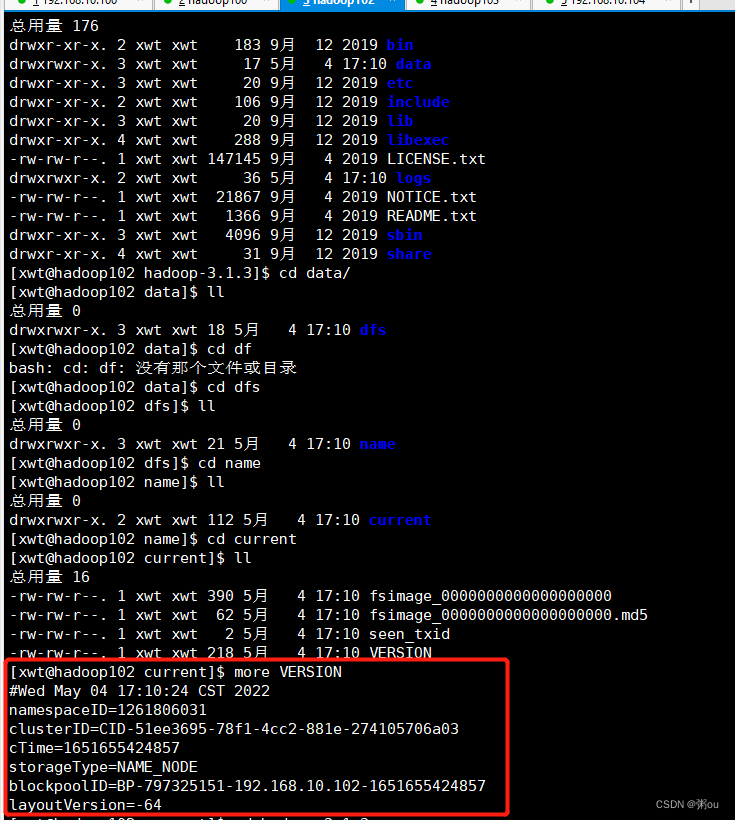
(1)启动HDFS
[xwt@hadoop102 hadoop-3.1.3]$ sbin/start-dfs.sh
(2)在配置了ResourceManager的节点(hadoop103)启动YARN
[xwt@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
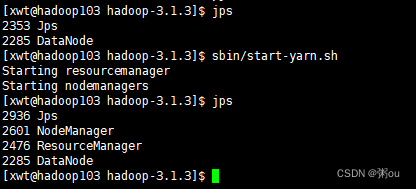
(3)Web端查看HDFS的NameNode
(a)浏览器中输入:http://hadoop102:9870
(b)查看HDFS上存储的数据信息
(4)Web端查看YARN的ResourceManager
(a)浏览器中输入:http://hadoop103:8088
(b)查看YARN上运行的Job信息
查看HDFS文件存储路径
/opt/module/hadoop-3.1.3/data/dfs/data/current/BP-797325151-192.168.10.102-1651655424857/current/finalized集群崩溃情况:①删除当前居群nn,2nn等进程②删除data和logs
③开始格式化
[xwt@hadoop102 hadoop-3.1.3]$ hdfs namenode -format配置历史服务器
查看程序的历史运行情况
1)配置mapred-site.xml
[xwt@hadoop102 hadoop]$ vim mapred-site.xml
#插入
<!-- 历史服务器端地址 -->
<property><name>mapreduce.jobhistory.address</name><value>hadoop102:10020</value>
</property><!-- 历史服务器web端地址 -->
<property><name>mapreduce.jobhistory.webapp.address</name><value>hadoop102:19888</value>
</property>一个是内部运行的端口号,一个是用户查看的端口号
2)分发配置
[xwt@hadoop102 hadoop]$ xsync mapred-site.xml 3)在hadoop102启动历史服务器
[xwt@hadoop102 hadoop]$ mapred --daemon start historyserver
[xwt@hadoop102 hadoop]$ jps
2752 NameNode
2886 DataNode
3211 NodeManager
3692 Jps
3630 JobHistoryServer
配置日志的聚集
日志聚集概念:应用运行完成以后,将程序运行日志信息上传到HDFS系统上
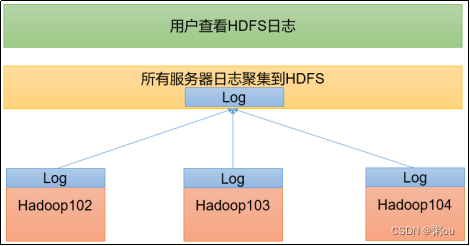
日志聚集功能好处:可以方便的查看到程序运行详情,方便开发调试
1)配置yarn-site.xml
[xwt@hadoop102 hadoop]$ vim yarn-site.xml
#插入
<!-- 开启日志聚集功能 -->
<property><name>yarn.log-aggregation-enable</name><value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property> <name>yarn.log.server.url</name> <value>http://hadoop102:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property><name>yarn.log-aggregation.retain-seconds</name><value>604800</value>
</property>2)分发配置
[xwt@hadoop102 hadoop]$ xsync yarn-site.xml
3)关闭NodeManager 、ResourceManager和HistoryServer
[xwt@hadoop102 hadoop-3.1.3]$ mapred --daemon stop historyserver
[xwt@hadoop102 hadoop-3.1.3]$ sbin/stop-yarn.sh
[xwt@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh 4)启动NodeManager 、ResourceManage和HistoryServer
[xwt@hadoop102 hadoop-3.1.3]$ mapred --daemon start historyserver
[xwt@hadoop102 hadoop-3.1.3]$ sbin//start-yarn.sh [xwt@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh 集群启动/停止方式总结
1)各个模块分开启动/停止(配置ssh是前提)常用
(1)整体启动/停止HDFS
start-dfs.sh/stop-dfs.sh
(2)整体启动/停止YARN
start-yarn.sh/stop-yarn.sh
2)各个服务组件逐一启动/停止
(1)分别启动/停止HDFS组件
hdfs --daemon start/stop namenode/datanode/secondarynamenode
(2)启动/停止YARN
yarn --daemon start/stop resourcemanager/nodemanager
shell不靠后缀区分文件,脚本的话看第一行#!
编写Hadoop集群常用脚本
1)Hadoop集群启停脚本(包含HDFS,Yarn,Historyserver):myhadoop.sh
#这里再~/bin下,编写脚本就在bin下
[xwt@hadoop102 bin]$ vim myhadoop.sh
#输入如下内容
#!/bin/bashif [ $# -lt 1 ] #如果参数小于1
thenecho "No Args Input..."exit ;
ficase $1 in
"start")echo " =================== 启动 hadoop集群 ==================="echo " --------------- 启动 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"echo " --------------- 启动 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"echo " --------------- 启动 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")echo " =================== 关闭 hadoop集群 ==================="echo " --------------- 关闭 historyserver ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"echo " --------------- 关闭 yarn ---------------"ssh hadoop103 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"echo " --------------- 关闭 hdfs ---------------"ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)echo "Input Args Error..."
;;
esac#赋予权限
[xwt@hadoop102 bin]$ chmod 777 myhadoop.sh 2)查看三台服务器Java进程脚本:jpsall
[xwt@hadoop102 bin]$ vim jpsall
#!/bin/bashfor host in hadoop102 hadoop103 hadoop104
doecho =============== $host ===============ssh $host jps
done[xwt@hadoop102 bin]$ chmod 777 jpsall
[xwt@hadoop102 ~]$ xsync bin/