cd sysconfig(目录名) 进目录
ll(listlist) 查看所有的目录
cat 看目录里的内容打开文件
~当前目录的用户主体目录
cd / 根路径
pwd 当前路径
vi 修改文件
敲I 才可以编辑
然后更改BOOTPROTO"STATIC"
IPADDR=IP地址192.168.52.随便写0-255
GATEWAY=网关
NETMAXK=255.255.255.0
DNS1=202.106.0.20
Esc退出编辑
保存:shift+:+wq 按回车
重启:/etc/init.d/network restart
联网:ifconfig回车 ping www.baidu.com回车
连接Xshell:
登录<获取虚拟机的的IP<打开Xshell<新建回话<保存
创建一个新用户hadoop:useradd hadoop -m 命令或程序,参数-m为hadoop的主体目录
su root:切换用户
cd:切换目录
cd ~:切换到主体目录
useradd zhangsan -m
mkdir text:创建目录
touch text:创建文件
增加权限:chmod o+w /home/zhangsan/text/text (o代表用户,W代表写权限,+添加)
rm:删除文件 -r删除目录及文件 -f忽略是否删除的提示
rm test -rf
JDK开发工具包
创建 mkrip opt
cd /
cd home
cd hadoop
mkrip opt
hadoop.apache.org/官网
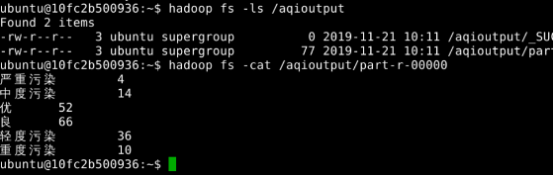
创建一个目录 hadoop fs -mkdir -p /user/hadoop
Hadoop是一个开源、高可靠、可扩展的分布式计算框架来解决:海量数据的储存(HDFS)海量数据分析(Map(打散,设计成自己想要的),Reduce(集成)) 分布式资源调度(Yarn)
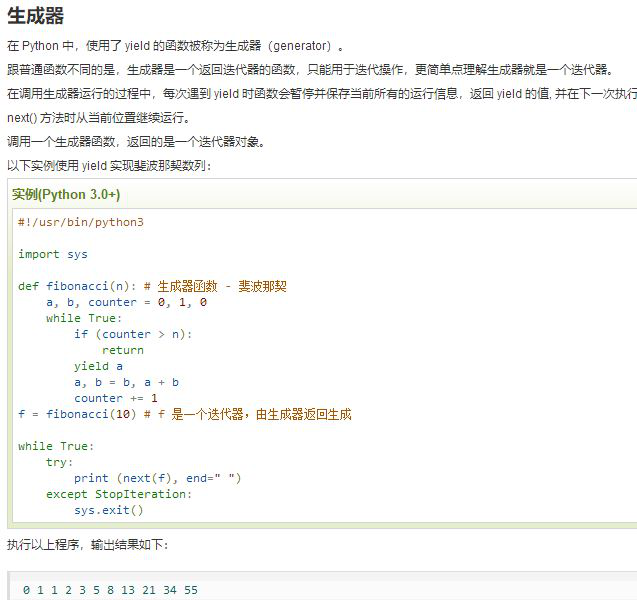
装饰器:


WordCount:
spark使用scala语言进行,scala建立在java之上
scala优点语法特别简洁,可以写在一行不停的写,以分号结束,效率快。但是没有Python函数库分丰富
注释:多行/****/ 单行//
变量:var声明变量
常量:不变的 val声明常量
启动scala : spark-shell
获取文件:var lines=sc.textFile("hdfs://python5:9000/user/hadoop/data.txt")
查看取值:lines.collect()
以空格拆分:lines.map(x=>x.split(" ").collect()
只作了分组lines.map(x=>x.split(" ")).flatMap(x=>for(i <- x) yield(i,1)).groupByKey().map(x=>(x._1,x._2.sum)).collect()
进行了计算lines.map(x=>x.split(" ")).flatMap(x=>for(i <- x) yield(i,1)).reduceByKey((x,y)=>x+y).collect()
数据分析有几种:hadoop里的mapreduce , scala, pyspark :DAG(有向无环图):计算最优路径
SPARK:的核心是RDD(懒操作)
通过文件系统或者并行集合得到RDD
RDD两种计算方式:变换(transformations)map,filter,flatmap,redoucebykey,groupbykey,countbyvalue,transformations是一种懒操作lazy,在worker上运行
操作(actions)count,collect,则优,在driver上运行
RDD两种类型:并行集合(parallelize,map,filter也是并行集合)
转换rdd: Rdd=sc.parallelize([11,22,33])
Rdd.collect()
文件系统数据集
union 并
intersection 交
subtract 差 a.subtract(b) a-b
cartesian 每一个配一遍
countbyvalue: 统计,谁出现了多少次

wget 可以下载网页 wget 网页地址 去统计网页有多少
打开jupyter:
Jupyter-notbook --ip python5
import os
import sys
spark_home = os.environ.get('SPARK_HOME',None)
if not spark_home:
raise ValueError('SPARK_HOME enviroment variable is not set')
sys.path.insert(0,os.path.join(spark_home,'python'))
sys.path.insert(0,os.path.join(spark_home,'python/lib/py4j-0.10.4-src.zip'))
exec(open(os.path.join(spark_home,'python/pyspark/shell.py')).read())
SPARK CORE的任务就是对这些数据进行分布式计算 简写sc
yarn代表整个集群,通用资源管理系统,主要成员RM[resourcemanager](资源管理,控制整个集群,分配给NodeManager每个节点),里container(相当于容器)
AM[applicationmaster](作业调度/监控,管理在YARN运行的应用程序的每个实例,AM是应用程序的主宰者,负责协调来自RM的资源)
Reduce():并行汇总所有RDD元素
Rdd=sc.parallelize([1,2,3,4],2),2是默认几个分区
Rdd.reduce(lambda x,y:x+y)
结果:分区为:[(1,2),(3,4)]
初步计算:[3,7]
最终计算:10,x是汇总,y是每个元素
Aggregate:有三个参数,第一个参数是给第二个第三个初始化

Join:内连接
rdd1=sc.parallelize([('a',1),('a',2),('a',3)])
rdd2=sc.parallelize([('b',3),('b',4),('a',5)])
rdd3=rdd1.join(rdd2)
print(rdd3.collect())
结果为:[('a', (1, 5)), ('a', (2, 5)), ('a', (3, 5))]
leftOuterJoin:左链接
rdd4=rdd1.leftOuterJoin(rdd2)
print(rdd4.collect())
结果为:[('a', (1, 5)), ('a', (1, 6)), ('a', (2, 5)), ('a', (2, 6)), ('a', (3, 5)), ('a', (3, 6))]
rightOuterJoin:右链接
rdd5=rdd1.rightOuterJoin(rdd2)
print(rdd5.collect())
结果为:[('b', (None, 3)), ('b', (None, 4)), ('a', (1, 5)), ('a', (1, 6)), ('a', (2, 5)), ('a', (2, 6)), ('a', (3, 5)), ('a', (3, 6))]
Cogroup:全连接
SubtractByKey:减链接

combineByKey:Rdd(k,v)变成了rdd(k,c)只是类型变了
x = sc.parallelize([("a", 1), ("b", 1), ("a", 2)])
def to_list(a):
return [a]
def append(a, b):
a.append(b)
return a
def extend(a, b):
a.extend(b)
return a
sorted(x.combineByKey(to_list, append, extend).collect())
结果:[('a', [1, 2]), ('b', [1])]
练习题:
#区,姓名,钱
#r1,aa,12
#r2,ss,22
#r3,ww,33
#r1,qq,32
#r2,tt,55
#r3,cc,77
#统计王者荣耀共赚多少钱?
Rdd=sc.textfile(“/user/hadoop/wangzhe.csv”)
Print(rdd.collect)
Rdd1=rdd.map(lambda x:x.split(‘,’)).map(lambad x:int(x[2]))
Print(rdd1.collect())
Rdd1.reduce(lambad x,y:x+y)
#分别统计每个区赚了多少
Rdd2=rdd.map(lambda x:x.split(‘,’)).map(lambad x:(x[1],int(x[2])))
Rdd2.redoucebykey(lambad x,y:x+y).collect()
#分别统计每个区每个人花了多少钱
Rdd3=rdd.map(lambda x:x.split(‘,’)).map(lambad x:(x[0],x[1]),int(x[2])))
Rdd3.redoucebykey(lambad x,y:x+y).collect()
#按照钱进行排序
rdd4=rdd3.redoucebykey(lambad x,y:x+y)
Rdd4.map(lambad X:(x[1],x[0])).sortbykey(ture).collect()
#先按照姓名正序排序,如果姓名相同则按照区进行倒序排序
Rdd4.sort(key=lambad x:x[0][0],x[0][1])这是一种二维数组
Rdd4=rdd3.map(lambad x:(x[0][1],(x[0][0],x[1]))).sortbykey(false)
Print(rdd4.collect())
Rdd4=rdd4.map(lambad x:(x[1][0],(x[0],x[1][1]))).sortbakey(ture)
Print(rdd4.collect())
Rdd4=rdd4.map(lambad x:(x[0],x[1][0],x[1][1]))
Print(rdd4.collect())
第二种方法
Rs=rdd3.collect()
Print(“----------------------------------”)
Class CompareValue(object):
Def __init__(self,obj):
Self.obj=obj
Def __lt__(self,other): #__lt__(self,other)比较小于的
If self.obj>other.obj:
Return self.obj>other.obj
Rs=sorted(rs,key=lambad x:(x[0][0],CompareValue(x[0][1]))),reverse=False)