时间序列与数据挖掘
一、实验说明
1. 环境登录
无需密码自动登录,系统用户名shiyanlou,密码shiyanlou
2. 环境介绍
本实验环境采用带桌面的Ubuntu Linux环境,实验中会用到:
1. LX终端(LXTerminal): Linux命令行终端,打开后会进入Bash环境,可以使用Linux命令
2. GVim:非常好用的编辑器,最简单的用法可以参考课程Vim编辑器
3. R:在命令行输入‘R’进入交互式环境,下面的代码都是在交互式环境运行
4. 数据:在命令行终端输入以下命令:
# 下载数据 wget http://labfile.oss.aliyuncs.com/courses/360/synthetic_control.tar.gz # 解压数据到当前文件夹 tar zxvf synthetic_control.tar.gz
3. 环境使用
使用R语言交互式环境输入实验所需的代码及文件,使用LX终端(LXTerminal)运行所需命令进行操作。
完成实验后可以点击桌面上方的“实验截图”保存并分享实验结果到微博,向好友展示自己的学习进度。实验楼提供后台系统截图,可以真实有效证明您已经完成了实验。
实验记录页面可以在“我的主页”中查看,其中含有每次实验的截图及笔记,以及每次实验的有效学习时间(指的是在实验桌面内操作的时间,如果没有操作,系统会记录为发呆时间)。这些都是您学习的真实性证明。
二、课程介绍
1. R中的时间序列数据
2. 将时间序列分解为趋势型、季节型以及随机型
3. 在R中构建ARIMA模型,并用其预测未来数据
4. 介绍动态时间规整(DTW),然后使用DTW距离以及欧式距离处理时间序列从而实现层次聚类。
5. 关于时间序列分类的三个例子:一个是使用原始数据,一个是使用经过离散小波变换(DWT)后的数据,另外一个是KNN分类。
三、课程内容
1、R中的时间序列数据
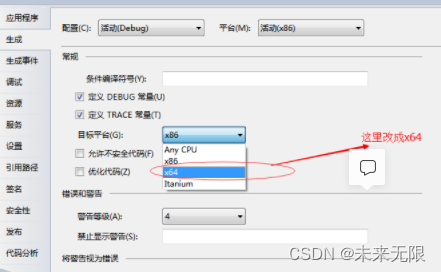
使用ts这个类可以抽取等时间距离的样本,当参数frequency=7的时候说明选取样本的频率单位是周,以此类推,频率为12和4分别生成月度和季度数据。具体实现如下:
# 生成1-30的整数,频率是12也就是月度数据,从2011年3月开始 > a <- ts(1:30, frequency=12, start=c(2011,3)) > print(a) # 转换为字符串型 > str(a) # 输出该时间序列的属性 > attributes(a)
执行结果如下:

2、时间序列分解
时间序列分解就是将时间序列按趋势性、季节性、周期性和不规则性依次分解。其中,趋势部分代表的是长期趋势,季节性指的是时间序列数据呈现季节性波动,周期性指的是指数据呈现周期性波动,不规则部分就是残差。
下面讲解一个关于时间序列分解的例子,使用的数据AirPassengers由Box & Jenkins国际航班从1949年到1960年的乘客数据组成。里面有144个观测值。
> plot(AirPassengers) # 将数据预处理成月度数据 > apts <- ts(AirPassengers, frequency=12) # 使用函数decompose()分解时间序列 > f <- decompose(apts) # 季度数据 > f$figure > plot(f$figure, type="b", xaxt="n", xlab="") # 使用当前的时间区域给月份赋予名称 > monthNames <- months(ISOdate(2011,1:12,1)) # 使用月份名称标记x轴 # side=1表示设置x轴,at指的是范围从10-12,las表示分割的单位刻度为2 > axis(1, at=1:12, labels=monthNames, las=2) > plot(f)
结果如下:

上图中,'observed'标注的表表示原始的时间序列分布图,往下第二个图是显示数据的呈现上升趋势图,第三个季节图显示数据受一定的季节因素影响,最后一个是在移除趋势和季节影响因素后的图。
思考:R里面还有哪些包,哪些函数可以实现时间序列的分解,并试着使用那些函数实现分解,并将分解结果进行对比。
3、时间序列预测
时间序列预测就是基于历史数据预测未来事件。一个典型的例子就是基于股票的历史数据预测它的开盘价。在时间序列预测中有两个比较经典的模型分别是:自回归移动平均模型(ARMA)和差分整合移动平均自回归模型(ARIMA)。
下面使用单变量时间序列数据拟合ARIMA模型,并用该模型预测。
# 参数order由(p,d,q)组成,p=1指的是自回归项数为1,list内容是季节seasonal参数
> fit <- arima(AirPassengers, order=c(1,0,0), list(order=c(2,1,0), period=12))
# 预测未来24个月的数据
> fore <- predict(fit, n.ahead=24)
# 95%的置信水平下的误差范围(U,L)
> U <- fore$pred + 2*fore$se
> L <- fore$pred - 2*fore$se
# col=c(1,2,4,4)表示线的颜色分别为黑色,红色,蓝色,蓝色
# lty=c(1,1,2,2)中的1,2指连接点的先分别为实线和虚线
> ts.plot(AirPassengers, fore$pred, U, L, col=c(1,2,4,4), lty = c(1,1,2,2))
> legend("topleft", c("Actual", "Forecast", "Error Bounds (95% Confidence)"),col=c(1,2,4), lty=c(1,1,2)) 预测结果如下:

4、时间序列聚类
时间序列聚类就是基于密度和距离将时间序列数据聚类,因此同一个类里面的时间序列具有相似性。有很多衡量距离和密度的指标比如欧式距离、曼哈顿距离、最大模、汉明距离、两个向量之间的角度(内积)以及动态时间规划(DTW)距离。
4.1 动态时间规划距离
动态时间规划能够找出两个时间序列的最佳的对应关系,通过包'dtw'可以实现该算法。在包'dtw'中,函数dtw(x,y,...)计算动态时间规划并找出时间序列x与y之间最佳的对应关系。
代码实现:
> library(dtw) # 平均生成100个在0-2*pi范围的序列idx > idx <- seq(0, 2*pi, len=100) > a <- sin(idx) + runif(100)/10 > b <- cos(idx) > align <- dtw(a, b, step=asymmetricP1, keep=T) > dtwPlotTwoWay(align)
a与b这两个序列的最佳对应关系如下图所示:

4.2 合成控制图的时间序列
合成控制图时间序列数据集‘synthetic_control.data’存放于当前工作目录'/home/shiyanlou'下,它包含600个合成控制图数据,每一个合成控制图都是由60个观测值组成的时间序列,那些合成控制图数据被分为6类:
- 1-100:正常型;
- 101-200:周期型;
- 201-300:上升趋;
- 301-400:下降趋势;
- 401-500:上移;
- 401-600:下移。
首先,对数据进行预处理:
> sc <- read.table("synthetic_control.data", header=F, sep="")
# 显示每一类数据的第一个样本观测值
> idx <- c(1,101,201,301,401,501)
> sample1 <- t(sc[idx,]) 合成控制图时间序列样本数据分布如下:

4.3 使用欧式距离层次聚类
首先从上面的合成控制图每一类数据中随机选取10个样本进行处理:
> set.seed(6218) > n <- 10 > s <- sample(1:100, n) > idx <- c(s, 100+s, 200+s, 300+s, 400+s, 500+s) > sample2 <- sc[idx,] > observedLabels <- rep(1:6, each=n) # 使用欧式距离层次聚类 > hc <- hclust(dist(sample2), method="average") > plot(hc, labels=observedLabels, main="") # 将聚类树划分为6类 > rect.hclust(hc, k=6) > memb <- cutree(hc, k=6) > table(observedLabels, memb)
聚类结果与实际分类对比:

图4.1
图4.1中,第1类聚类正确,第2类聚类不是很好,有1个数据被划分到第1类,有2个数据划分到第3类,有1个数据划分到第4类,且上升趋势(第3类)和上移(第5类)并不能很好的被区分,同理,下降趋势(第4类)和下移(第6类)也没有被很好的被识别。
4.4 使用DTW距离实现层次聚类
实现代码如下:
> library(dtw) > distMatrix <- dist(sample2, method="DTW") > hc <- hclust(distMatrix, method="average") > plot(hc, labels=observedLabels, main="") > rect.hclust(hc, k=6) > memb <- cutree(hc, k=6) > table(observedLabels, memb)
聚类结果如下:

图4.2
对比图4.1和4.2可以发现,由后者的聚类效果比较好可看出在测量时间序列的相似性方面,DTW距离比欧式距离要好点。
5、时间序列分类
时间序列分类就是在一个已经标记好类别的时间序列的基础上建立一个分类模型,然后使用这个模系去预测没有被分类的时间序列。从时间序列中提取新的特征有助于提高分类模系的性能。提取特征的方法包括奇异值分解(SVD)、离散傅里叶变化(PFT)、离散小波变化(DWT)和分段聚集逼近(PAA)。
5.1 使用原始数据分类
我们使用包'party'中的函数ctree()来给原始时间序列数据分类。实现代码如下:
# 给原始的数据集加入分类标签classId > classId <- rep(as.character(1:6), each=100) > newSc <- data.frame(cbind(classId, sc)) > library(party) > ct <- ctree(classId ~ ., data=newSc,controls = ctree_control(minsplit=30, minbucket=10, maxdepth=5)) > pClassId <- predict(ct) > table(classId, pClassId) # 计算分类的准确率 > (sum(classId==pClassId)) / nrow(sc) > plot(ct, ip_args=list(pval=FALSE),ep_args=list(digits=0))
输出决策树:

5.2 提取特征分类
接下来,我们使用DWT(离散小波变化)的方法从时间序列中提取特征然后建立一个分类模型。小波变换能处理多样的频率数据,因此具有自适应性。
下面展示一个提取DWT系数的例子。离散小波变换在R中可以通过包'wavelets'实现。包里面的函数dwt()可以计算离散小波的系数,该函数中主要的3个参数X、filter和boundary分别是单变量或多变量的时间序列、使用的小波过滤方式以及分解的水平,函数返回的参数有W和V分别指离散小波系数以及尺度系数。原始时间序列可以通过函数idwt()逆离散小波重新获得。
> library(party)
> library(wavelets)
> wtData <- NULL
# 遍历所有时间序列
> for (i in 1:nrow(sc)) {
+ a <- t(sc[i,])
+ wt <- dwt(X=a, filter="haar", boundary="periodic")
+ wtData <- rbind(wtData, unlist(c(wt@W, wt@V[[wt@level]])))
+ }
> wtData <- as.data.frame(wtData)
> wtSc <- data.frame(cbind(classId, wtData))
# 使用DWT建立一个决策树,control参数是对决策树形状大小的限制
> ct <- ctree(classId ~ ., data=wtSc,controls = ctree_control(minsplit=30, minbucket=10, maxdepth=5))
> pClassId <- predict(ct)
# 将真实分类与聚类后的类别进行对比
> table(classId, pClassId) 
5.3 K-NN分类
K-NN算法也可以用于时间序列的分类。算法流程如下:
- 找出一个新对象的k个最近邻居
- 然后观察该区域内拥有相同属性的数量最多的类代表该区域所属的类
但是,这种直接寻找k个最近邻居的算法时间复杂度为O(n**2),其中n是数据的大小。因此,当处理较大数据的时候就需要一个有效索引的方式。包'RANN'提供一个快速的最近邻搜索算法,能够将算法的时间复杂度缩短为O(n log n)。
下面是在没有索引的情况下实现K-NN算法:
> k <- 20 # 通过在第501个时间序列中添加噪声来创建一个新的数据集 > newTS <- sc[501,] + runif(100)*15 # 使用‘DTW’方法计算新数据集与原始数据集之间的距离 > distances <- dist(newTS, sc, method="DTW") # 给距离升序排列 > s <- sort(as.vector(distances), index.return=TRUE) # s$ix[1:k]是排行在前20的距离,表哥输出k个最近邻居所属的类 > table(classId[s$ix[1:k]])
输出结果如下:

由上图输出表格数据可知,20个邻居中有19个数据都属于第6类,因此将该类时间序列划分到第六类时间序列中。
**思考**:经过学习这么多时间序列分类,请思考以上时间序列分类方法的利与弊。
更多数据挖掘教材请来实验楼学习。
![[学习笔记]黑马程序员-Hadoop入门视频教程](https://img-blog.csdnimg.cn/bde803ec75c74330ad02de50e33f92a0.png)
![[译]用R语言做挖掘数据《五》](https://dn-anything-about-doc.qbox.me/document-uid73259labid1163timestamp1437005313151.png?watermark/1/image/aHR0cDovL3N5bC1zdGF0aWMucWluaXVkbi5jb20vaW1nL3dhdGVybWFyay5wbmc=/dissolve/60/gravity/SouthEast/dx/0/dy/10)