- CUDA Visual Profiler
- CUDA编程指导
- shared memory
- Page locked out memory
- C
- CUDA 调用
- CUDA 编程介绍
- CUDA 数据同步
CUDA Visual Profiler
在上180645课程的时候,里面谈到使用CUDA来做矩阵乘法和k均值聚类的加速。在使用n卡的时候,有一个Visual Profiler的东西可以看到GPU的使用信息。
在安装好了CUDA以后,在Ubuntu上登录以后,使用X server。在Ubuntu命令行输入:
ssh -X < your_andrew_id>@ghcXX.ghc.andrew.cmu.edu
然后就登陆了远程服务器,接着呢使用:
computeprof &
如果遇到错误,退出登录再连接就好了。
这样就可以看到了GPU的使用信息了。然后如果是Windows的话,使用Xming或Cygwin。如果是OS X的话,使用XQuartz就可以了。
CUDA编程指导
使用CUDA编程,可以学习CUDA编程指南【1】。接下来我就大概过一遍编程指南。
threadIdx是三维的向量,可以表示为一维、二维、三维的线程索引。如果是二维的话,若尺寸是 (Dx,Dy) ,那么索引的就是 (x+yDx) 。如果是三维的,索引的就是(x,y,z),那么就是( x+yDx+zDxDy )
现在线程块一般是1024个,但是因为有多个线程块。所以总的线程数是每块线程数x线程块数。
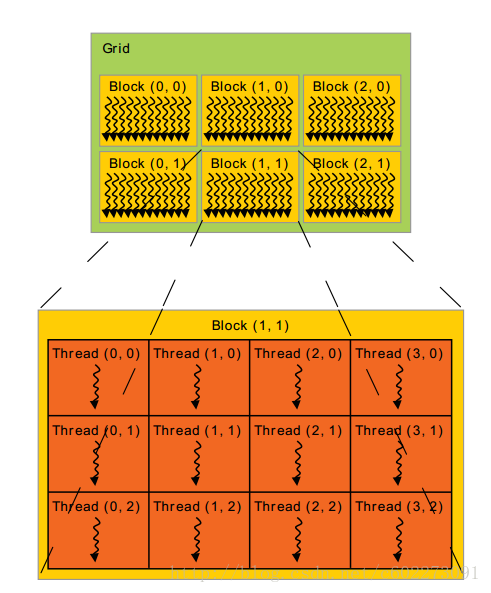
通过调用__syncthreads()函数进行数据同步。
CUDA的每个线程、线程块等等的内存层次:
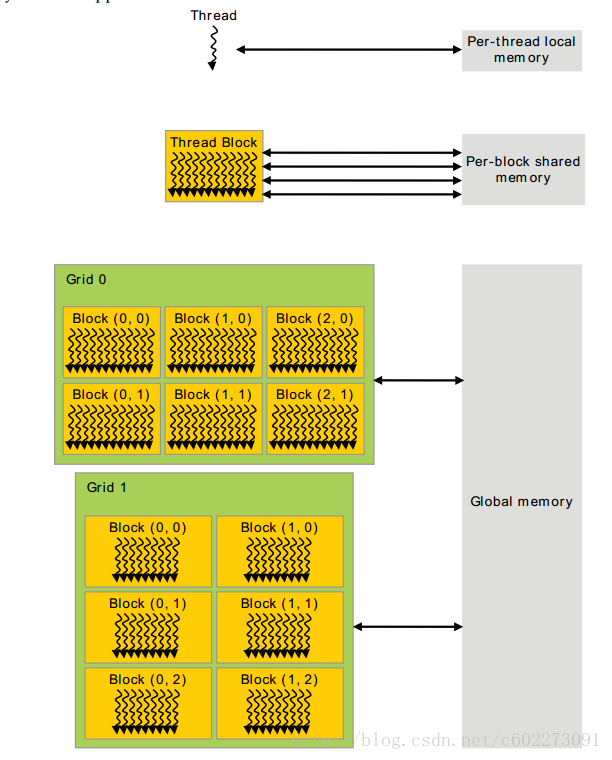
除了全局存储之外,还有两种额外的存储:常量和texture memory(这个玩样儿是啥?)。
CUDADeviceReset()的调用使得所有的配置初始化。
CUDA上的存储操作有cudaMalloc(), cudaFree(). cudaMemcpy()。
举一个例子:
// Device code
__global__ void VecAdd(float* A, float* B, float* C, int N)
{
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < N)
C[i] = A[i] + B[i];
}
// Host code
int main()
{
int N = ...;
size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
// Initialize input vectors
...
// Allocate vectors in device memory
float* d_A;
cudaMalloc(&d_A, size);
float* d_B;
cudaMalloc(&d_B, size);
float* d_C;
cudaMalloc(&d_C, size);
// Copy vectors from host memory to device memory
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Invoke kernel
int threadsPerBlock = 256;
int blocksPerGrid =
(N + threadsPerBlock - 1) / threadsPerBlock;
VecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// Copy result from device memory to host memory
// h_C contains the result in host memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Free host memory
...
}cudaMallocPitch(), cudaMalloc3D()可以用来分配内存。另外还有cudaMemcpy2D和cudaMemcpy3D来分配2D和3D的内存。P34行有例子。
shared memory
shared 标识,共享的内存比全局的内存更快。这里举了一个矩阵乘法的例子: P35
在P41页有memory blocking存在,更加快。
Page locked out memory
和传统的malloc分配的内存相反的,这种比较固定。
cudaHostAlloc() 和 cudaFreeHost()。
在CUDA里面涉及数据同步和流的东西,这里有显示同步和隐式同步。还有更多数据流的东西,比如数据传过去kernel的时候有的已经在执行啦什么的。还有callback函数。
P57里面有各种API。
CUDA里面的硬件架构上,有SIMD和多线程。
C
一些CUDA的语法,涉及和C有关的东西。类似于API。
在这里,贴上矩阵的CUDA算法,最基本的,然后需要在上面进行加速:
#include <cuda.h>
#include <cuda_runtime.h>
#include "matrix_mul.h"
#define TILE_WIDTH 2namespace cuda
{__global__voidmatrix_mul_kernel(float *sq_matrix_1, float *sq_matrix_2, float *sq_matrix_result, int sq_dimension){int tx = threadIdx.x;int ty = threadIdx.y;float sum = 0.0f;for(int k = 0; k < sq_dimension; k++){sum += sq_matrix_1[ty*sq_dimension + k] * sq_matrix_2[k*sq_dimension + tx];}sq_matrix_result[ty*sq_dimension + tx] = sum;}voidmatrix_multiplication(float *sq_matrix_1, float *sq_matrix_2, float *sq_matrix_result, unsigned int sq_dimension){int size = sq_dimension * sq_dimension * sizeof(float);float *sq_matrix_1_d, *sq_matrix_2_d, *sq_matrix_result_d;/***************************************************1st Part: Allocation of memory on device memory ****************************************************//* copy sq_matrix_1 and sq_matrix_2 to device memory */cudaMalloc((void**) &sq_matrix_1_d, size);cudaMemcpy(sq_matrix_1_d, sq_matrix_1, size, cudaMemcpyHostToDevice);cudaMalloc((void**) &sq_matrix_2_d, size);cudaMemcpy(sq_matrix_2_d, sq_matrix_2, size, cudaMemcpyHostToDevice);/*allocate sq_matrix_result on host */cudaMalloc((void**) &sq_matrix_result_d, size);/***************************************************2nd Part: Inovke kernel ****************************************************/dim3 dimBlock(sq_dimension, sq_dimension);dim3 dimGrid(1,1);matrix_mul_kernel<<<dimGrid, dimBlock, dimBlock.x * dimBlock.x * sizeof(float)>>>(sq_matrix_1_d, sq_matrix_2_d, sq_matrix_result_d, sq_dimension);/***************************************************3rd Part: Transfer result from device to host ****************************************************/cudaMemcpy(sq_matrix_result, sq_matrix_result_d, size, cudaMemcpyDeviceToHost);cudaFree(sq_matrix_1_d);cudaFree(sq_matrix_2_d);cudaFree(sq_matrix_result_d);}
} // namespace cudaCUDA 调用
核函数是GPU每个thread上运行的程序。必须通过gloabl函数类型限定符定义。形式如下:
__global__ void kernel(param list){ }
核函数只能在主机端调用,调用时必须申明执行参数。调用形式如下:
Kernel<<<Dg,Db, Ns, S>>>(param list);
<<<>>>运算符内是核函数的执行参数,告诉编译器运行时如何启动核函数,用于说明内核函数中的线程数量,以及线程是如何组织的。
<<<>>>运算符对kernel函数完整的执行配置参数形式是<< < Dg, Db, Ns, S>>> 【2】
- 参数Dg用于定义整个grid的维度和尺寸,即一个grid有多少个block。为dim3类型。Dim3 Dg(Dg.x, Dg.y, 1)表示grid中每行有Dg.x个block,每列有Dg.y个block,第三维恒为1(目前一个核函数只有一个grid)。整个grid中共有Dg.x*Dg.y个block,其中Dg.x和Dg.y最大值为65535。
- 参数Db用于定义一个block的维度和尺寸,即一个block有多少个thread。为dim3类型。Dim3 Db(Db.x, Db.y, Db.z)表示整个block中每行有Db.x个thread,每列有Db.y个thread,高度为Db.z。Db.x和Db.y最大值为512,Db.z最大值为62。 一个block中共有Db.x*Db.y*Db.z个thread。计算能力为1.0,1.1的硬件该乘积的最大值为768,计算能力为1.2,1.3的硬件支持的最大值为1024。
- 参数Ns是一个可选参数,用于设置每个block除了静态分配的shared Memory以外,最多能动态分配的shared memory大小,单位为byte。不需要动态分配时该值为0或省略不写。
- 参数S是一个cudaStream_t类型的可选参数,初始值为零,表示该核函数处在哪个流之中。
CUDA 编程介绍
比如举个计算一个数字每个数字平方和的CUDA实现。
#include <stdio.h> __global__ void square(float * d_out, float * d_in)
{ int idx = threadIdx.x; float f = d_in[idx]; d_out[idx] = f * f;
} int main(int argc, char ** argv)
{ const int ARRAY_SIZE = 64; const int ARRAY_BYTES = ARRAY_SIZE * sizeof(float); // generate the input array on the host float h_in[ARRAY_SIZE]; for (int i = 0; i < ARRAY_SIZE; i++){ h_in[i] = float(i); } float h_out[ARRAY_SIZE]; // declare GPU memory pointers float *d_in; float *d_out; // allocate GPU memory cudaMalloc((void**) &d_in, ARRAY_BYTES); cudaMalloc((void**) &d_out, ARRAY_BYTES); // transfer the array to the GPU cudaMemcpy(d_in, h_in, ARRAY_BYTES, cudaMemcpyHostToDevice); // launch the kernel square<<<1, ARRAY_SIZE>>>(d_out, d_in); // copy back the result array to the CPU cudaMemcpy(h_out, d_out, ARRAY_BYTES, cudaMemcpyDeviceToHost); // print out the resulting array for (int i =0; i < ARRAY_SIZE; i++) { printf("%f", h_out[i]); printf(((i % 4) != 3) ? "\t" : "\n"); } cudaFree(d_in); cudaFree(d_out); return 0;
} CUDA 数据同步
原本有问题的代码:
__global__ void shift(){ int idx = threadIdx.x; __shared__ int array[128]; array[idx] = threadIdx.x; if (idx < 127) { array[idx] = array[idx + 1]; }
} 设置barrier:
__global__ void shift(){int idx = threadIdx.x;__shared__ int array[128];array[idx] = threadIdx.x;__syncthreads();//执行至此,数组中的每一个元素都被正确的赋值if (idx < 127) {int temp = array[idx + 1];__syncthreads();//将一行代码拆分成两行来设置一个barrier,这种技巧非常实用,执行至此,每一个线程都正确的取值array[idx] = temp;__syncthreads();//确保后续使用array的正确性}}参考资料:
【1】CUDA 编程指南:http://docs.nvidia.com/cuda/pdf/CUDA_C_Programming_Guide.pdf
【2】CUDA 调用说明:http://blog.csdn.net/augusdi/article/details/12204121
【3】CUDA 核函数的参数解析:http://blog.csdn.net/a925907195/article/details/39500915