整体框架
0. RAII
-
RAII全称是Resource Acquisition is Initialization,即资源获取即初始化。
-
RAII的核心思想是将资源或者状态与对象的生命周期绑定
-
c++可以在构造函数中申请分配资源,在析构函数中释放资源。所以,在RAII的指导下,我们应该使用类来管理资源,将资源和对象的生命周期绑定。智能指针是RAII最好的例子。
1. 线程同步
定义:当有一个线程在对内存进行操作时,其他线程都不可以对这个内存地址进行操作,直到该线程完成操作,其他线程才能对该内存地址进行操作,而其他线程则处于等待状态。
1.1 互斥锁(mutex)
- 互斥锁(互斥量)可保证某一时刻仅有一个线程访问某项共享资源
- 两种状态:已锁定(locked)和未锁定(unlocked)
- 线程在访问共享资源时有如下协议:互斥锁加锁——访问共享资源——互斥锁解锁(锁在屋里的门上,类似进门后锁门,解锁后出门)
#include <pthread.h>// 1.初始化互斥锁(restrict是C语言的修饰符,被修饰的指针,不能由另外的一个指针进行操作)
int pthread_mutex_init(pthread_mutex_t *restrict mutex, const pthread_mutexattr_t *restrict attr);// 2.销毁互斥锁
int pthread_mutex_destroy(pthread_mutex_t *mutex);// 3.互斥锁加锁
int pthread_mutex_lock(pthread_mutex_t *mutex);// 4.互斥锁解锁
int pthread_mutex_unlock(pthread_mutex_t *mutex);// 成功返回0,失败返回errno
1.2 条件变量(condition)
- 用于线程间通信,当某个共享数据达到某个值时,可唤醒等待这个共享数据的线程(生产者-消费者)
- 需要结合互斥锁使用
#include <pthread.h>// 1.初始化条件变量
int pthread_cond_init(pthread_cond_t *restrict cond, const pthread_condattr_t *restrict attr);// 2.销毁条件变量
int pthread_cond_destroy(pthread_cond_t *cond);// 3,等待条件变量,该函数调用时需要传入mutex(加锁的互斥锁),函数执行时,先把调用线程放入条件变量的请求队列,然后将互斥锁mutex解锁,当函数成功返回为0时,互斥锁会再次被锁上. 即函数内部会有一次解锁和加锁操作。(类似已上锁的屋里有个妈妈,当他做好饭后,会通知需要这饭的孩子,妈妈然后会解锁,让孩子进来,当孩子吃完出去后,妈妈又上锁了。这里妈妈是生产的线程,孩子是消费的线程,饭是条件变量)
int pthread_cond_wait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex);
// int pthread_cond_timedwait(pthread_cond_t *restrict cond, pthread_mutex_t *restrict mutex, const struct timespec *restrict abstime); // 线程阻塞,直到指定的时间结束。// 4.唤醒一个或者多个等待的线程
int pthread_cond_signal(pthread_cond_t *cond);
// int pthread_cond_broadcast(pthread_cond_t *cond); // 唤醒所有的等待的线程 // 成功返回0,失败返回errno
1.3 信号量(semaphore)
- 只能取自然数值并且只支持两种操作:等待(P)和信号(V)。若有信号量SV,
- P:若SV值大于0,则SV减一;若SV的值为0,则挂起
- V:若有线程因为等待SV而挂起,则唤醒;若没有,则将SV值加一
#include <semaphore.h>// 1.初始化信号量(pshared:0用在线程间,非0用在进程间;value:信号量中的值)
int sem_init(sem_t *sem, int pshared, unsigned int value);// 2.销毁信号量
int sem_destroy(sem_t *sem);// 3.信号量加锁,调用一次对信号量值-1,若值等于0,则阻塞(相当于P)
int sem_wait(sem_t *sem);// 4.信号量解锁,调用一次对信号量的值+1,唤醒调用sem_post的线程(相当于V)
int sem_post(sem_t *sem);// 成功返回0,失败返回errno
1.4 区别
1.互斥锁与条件变量
互斥锁主要用于线程同步的保证,条件变量可用于线程通信
2.互斥锁和信号量
- 互斥锁有拥有者这一概念,信号量则没有。
- 互斥锁由同一线程加放锁,信号量可以由不同线程进行PV操作。
- 互斥锁保证多个线程对一个共享资源的互斥访问,信号量用于协调多个线程对一系列资源的访问。
3.条件变量和信号量
- 条件变量可以一次唤醒所有等待者,信号量不可以
- 信号量通过互斥锁、条件变量和计数器实现,计数器就是信号量的核心。信号量是有值的,而条件变量没有。
1.5 代码实现
- 新建
lock.h
#ifndef LOCK_H
#define LOCK_H#include <exception>
#include <pthread.h>
#include <semaphore.h>// 线程同步封装成类// 互斥锁
class mutex {
public:mutex() {if (pthread_mutex_init(&m_mutex, NULL) != 0) throw std::exception(); // 始化互斥锁}~mutex() {pthread_mutex_destroy(&m_mutex); // 销毁互斥锁}bool lock() {return pthread_mutex_lock(&m_mutex) == 0; // 互斥锁加锁}bool unlock() {return pthread_mutex_unlock(&m_mutex) == 0; // 互斥锁解锁}pthread_mutex_t* get() {return &m_mutex;}
private:pthread_mutex_t m_mutex;
};// 条件变量
class cond {
public:cond() {if (pthread_cond_init(&m_cond, NULL) != 0) throw std::exception(); // 初始化条件变量}~cond() {pthread_cond_destroy(&m_cond); // 销毁条件变量}bool wait(pthread_mutex_t* mutex) {int ret = 0;ret = pthread_cond_wait(&m_cond, mutex);return ret == 0;}bool timedwait(pthread_mutex_t* mutex, struct timespec t) {int ret = 0;/* 等待条件变量,该函数调用时需要传入mutex(加锁的互斥锁),函数执行时,先把调用线程放入条件变量的请求队列,然后将互斥锁mutex解锁,当函数成功返回为0时,互斥锁会再次被锁上. 即函数内部会有一次解锁和加锁操作 */ret = pthread_cond_timedwait(&m_cond, mutex, &t);return ret == 0;}bool signal() {return pthread_cond_signal(&m_cond); // 唤醒一个或者多个等待的线程}bool broadcast() {return pthread_cond_broadcast(&m_cond); // 唤醒所有的等待的线程}
private:pthread_cond_t m_cond;
};// 信号量
class sem {
public:sem() { if (sem_init(&m_sem, 0, 8) != 0) throw std::exception(); // 初始化信号量(无参构造)}sem(int num) {if (sem_init(&m_sem, 0, num) != 0) throw std::exception(); // 初始化信号量(有参构造,可以传入信号量的值)}~sem() {sem_destroy(&m_sem) != 0; // 销毁信号量}bool wait() {return sem_wait(&m_sem) == 0; // 信号量加锁,调用一次对信号量值-1,若值等于0,则阻塞(相当于P)}bool post() {return sem_post(&m_sem) == 0; // 信号量解锁,调用一次对信号量的值+1,唤醒调用sem_post的线程(相当于V)}
private:sem_t m_sem;
};#endif
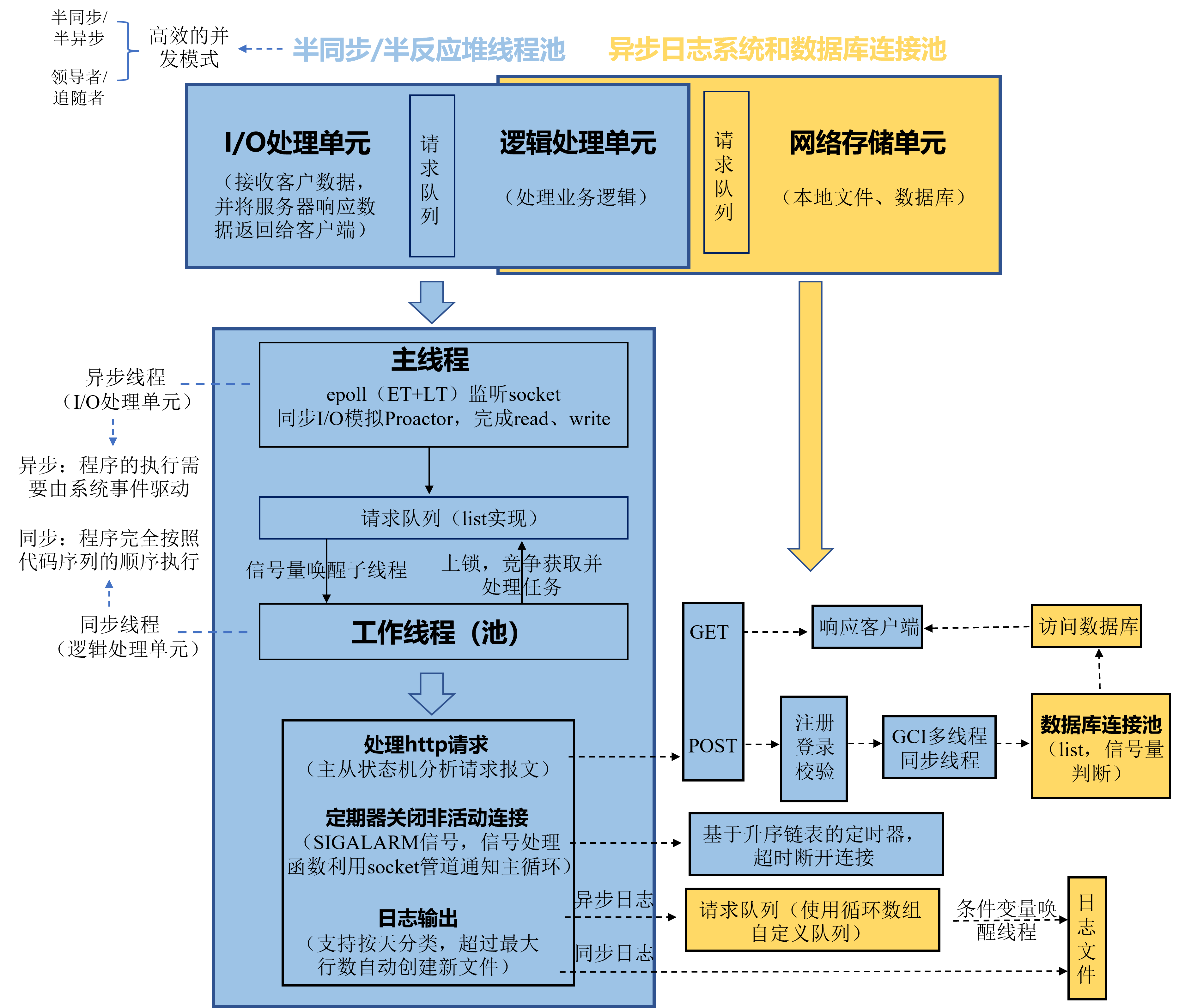
2. 半同步/半反应堆线程池
2.1 服务器编程的基本框架
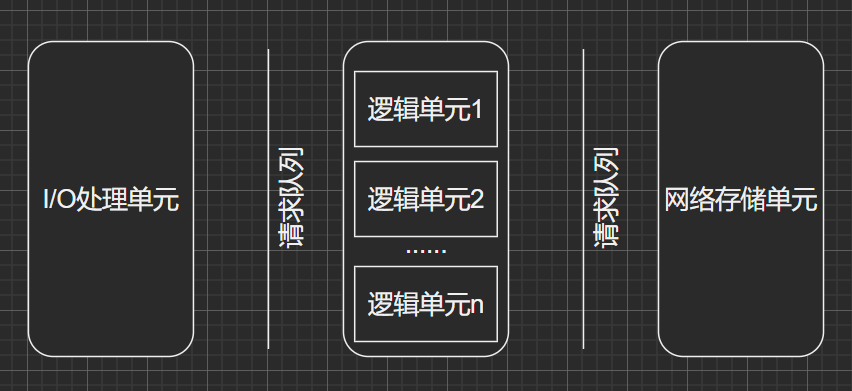
- I/O处理单元:等待并接受新的客户连接,接收客户数据,将服务器响应数据返回给客户端(和客户端打交道)
- 逻辑单元:分析并处理客户数据,然后将结果传递给 I/O 处理单元或者直接发送给客户端(多个逻辑单元对多个客户任务并发处理)
- 网络存储单元:数据库、缓存和文件
- 请求队列:各单元之间的通信方式的抽象,通常被实现为池的一部分
2.2 I/O模型
- 阻塞IO:调用者调用了某个函数,等待这个函数返回,期间什么也不做,不停的去检查这个函数有没有返回,必须等这个函数返回才能进行下一步动作。
- 非阻塞IO:非阻塞等待,每隔一段时间就去检测IO事件是否就绪,没有就绪就可以做其他事。非阻塞I/O执行系统调用总是立即返回,不管事件是否已经发生,若事件没有发生,则返回-1,此时可以根据
errno区分这两种情况,对于accept,recv和send,事件未发生时,errno通常被设置成EAGAIN。 - IO复用:
Linux用select/poll/epoll函数实现IO复用模型,这些函数也会使进程阻塞,但是和阻塞IO所不同的是这些函数可以同时阻塞多个IO操作。而且可以同时对多个读操作、写操作的IO函数进行检测。直到有数据可读或可写时,才真正调用IO操作函数。 - 信号驱动:
Linux用套接口进行信号驱动IO,安装一个信号处理函数,进程继续运行并不阻塞,当IO事件就绪,进程收到SIGIO信号,然后处理IO事件。 - 异步:
Linux中,可以调用 aio_read 函数告诉内核描述字缓冲区指针和缓冲区的大小、文件偏移及通知的方式,然后立即返回,当内核将数据拷贝到缓冲区后,再通知应用程序。
阻塞I/O,非阻塞I/O,I/O复用和信号驱动I/O都是同步I/O,只有使用了特殊的API才是异步IO。
- 同步I/O:内核向应用程序通知的是就绪事件,比如只通知有客户端连接,要求用户代码自行执行I/O操作
- 异步I/O:内核向应用程序通知的是完成事件,比如读取客户端的数据后才通知应用程序,由内核完成I/O操作
2.3 事件处理模式
两种事件处理模式:Reactor和 Proactor(同步I/O模型通常用于实现Reactor模式,异步I/O模型通常用于实现Proactor模式)
- Reactor模式:主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,有的话立即通知工作线程(逻辑单元 ),读写数据、接受新连接及处理客户请求均在工作线程中完成。
- Proactor模式:主线程和内核负责处理读写数据、接受新连接等I/O操作,工作线程仅负责业务逻辑,如处理客户请求。
2.4 同步I/O模拟Proactor模式
由于异步I/O并不成熟,实际中使用较少。所以本项目使用同步I/O模拟proactor模式,工作流程如下(epoll_wait为例):
- 主线程往epoll内核事件表注册socket上的读就绪事件。
- 主线程调用epoll_wait等待socket上有数据可读
- 当socket上有数据可读,epoll_wait通知主线程,主线程从socket循环读取数据,直到没有更多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
- 睡眠在请求队列上某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往epoll内核事件表中注册该socket上的写就绪事件
- 主线程调用epoll_wait等待socket可写。
- 当socket上有数据可写,epoll_wait通知主线程。主线程往socket上写入服务器处理客户请求的结果。
2.5 并发编程模式
- 并发模式中的同步和异步
- 同步指的是程序完全按照代码序列的顺序执行
- 异步指的是程序的执行需要由系统事件驱动
- 并发编程方法的实现有多线程和多进程两种,但这里涉及的并发模式指I/O处理单元与逻辑单元的协同完成任务的方法。
- 半同步/半异步模式
- 领导者/追随者模式
- 半同步/半异步模式工作流程
- 同步线程用于处理客户逻辑
- 异步线程用于处理I/O事件
- 异步线程监听到客户请求后,就将其封装成请求对象并插入请求队列中
- 请求队列将通知某个工作在同步模式的工作线程来读取并处理该请求对象
- 半同步/半反应堆工作流程(半同步/半异步的变体,将半异步具体化为某种事件处理模式,以Proactor模式为例(异步线程变为主线程,同步线程变为工作线程))
- 主线程充当异步线程,负责监听所有socket上的事件
- 若有新请求到来,主线程接收之以得到新的连接socket,然后往epoll内核事件表中注册该socket上的读写事件
- 如果连接socket上有读写事件发生,主线程从socket上接收数据,并将数据封装成请求对象插入到请求队列中
- 所有工作线程睡眠在请求队列上,当有任务到来时,通过竞争(如互斥锁)获得任务的接管权
2.6 线程池
-
线程池是由服务器预先创建的一组子线程,线程池中线程数量应该和CPU数量差不多,选择一个已经存在的子线程代价显然要小得多
-
特点:
- 空间换时间,浪费服务器的硬件资源,换取运行效率。
- 池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化,这称为静态资源。
- 当服务器进入正式运行阶段,开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中获取,无需动态分配。
- 当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
2.7 代码实现
-
静态成员
-
静态成员变量:将类成员变量声明为
static,则为静态成员变量- 与一般的成员变量不同,无论建立多少对象,都只有一个静态成员变量的拷贝**,静态成员变量**属于一个类,所有对象共享。
- 静态变量在编译阶段就分配了空间,对象还没创建时就已经分配了空间,放到全局静态区。
- 类内声明,类外初始化(以免类名访问静态成员访问不到,静态成员是单独存储的,并不是对象的组成部分。如果在类的内部进行定义,在建立多个对象时会多次声明和定义该变量的存储位置。在名字空间和作用于相同的情况下会导致重名的问题),而非静态成员类外不能初始化。
- 无论公有,私有,静态成员都可以在类外定义,但私有成员仍有访问权限。
-
静态成员函数:将类成员函数声明为
static,则为静态成员函数。 -
静态成员函数可以直接访问静态成员变量,不能直接访问普通成员变量,但可以通过参数传递的方式访问。(普通成员函数可以访问普通成员变量,也可以访问静态成员变量)
-
静态成员函数没有this指针。非静态数据成员为对象单独维护,但静态成员函数为共享函数,无法区分是哪个对象,因此不能直接访问普通变量成员,也没有this指针。
-
很关键的一点是pthread_create参数中的函数指针指向的函数必须是静态函数,如果处理线程函数为类成员函数时,需要将其设置为静态成员函数。因为pthread_create的函数原型中第三个参数的类型为函数指针,指向的线程处理函数参数类型为
(void*),若线程函数为类成员函数,则this指针会作为默认的参数被传进函数中,从而和线程函数参数(void*)不能匹配,不能通过编译。而静态成员函数就没有这个问题,里面没有this指针。
- 线程池分析
- 线程池的设计模式为半同步/半反应堆,其中反应堆具体为Proactor事件处理模式,即主线程为异步线程,负责监听文件描述符,接收socket新连接,若当前监听的socket发生了读写事件,然后将任务插入到请求队列。工作线程从请求队列中取出任务,完成读写数据的处理。
- 线程池代码
新建threadpool.h
#ifndef THREADPOOL_H
#define THREADPOOL_H
#include <list>
#include <cstdio>#include "lock.h"
#include "sql_connection_pool.h"// 线程池定义为模板类,实现代码复用,其中T是任务类
template <typename T>
class threadpool {
public:threadpool(connection_pool* connPool, int thread_number = 8, int max_requests = 10000); // 构造函数,默认创建8个线程,最大的请求数量是10000~threadpool(); // 析构函数bool append(T* request); // 将任务添加到请求队列private:static void* worker(void* arg); // 线程处理函数void run(); // run执行任务,与worker分开写,因为run中使用了大量的类内成员,与worker不分开写就得写大量的pool->private:int m_thread_number; // 线程数量pthread_t* m_threads; // 线程池数组,大小为m_thread_numberint m_max_requests; // 请求队列最多允许的请求数量std::list<T*> m_workqueue; // 请求队列mutex m_queuelocker; // 队列的互斥锁sem m_queuestate; // 信号量用来判断是否有任务需要处理bool m_stop; // 是否结束线程connection_pool* m_connPoll; // 数据库
};template <typename T>
threadpool<T>::threadpool(connection_pool* connPool, int thread_number, int max_requests) : m_connPoll(connPool), m_thread_number(thread_number), m_max_requests(max_requests), m_threads(NULL), m_stop(false) { // 列表初始化if (thread_number <= 0 || max_requests <= 0) throw std::exception(); // 如果输入参数不满足要求则抛出异常m_threads = new pthread_t[m_thread_number]; // 动态创建线程数组if (!m_threads) throw std::exception(); // 如果创建失败则抛出异常// 创建thread_number个线程并设置线程分离for (int i = 0; i < m_thread_number; ++i) {printf("create the %dth thread\n", i);// 创建线程,如果创建失败则删除数组并抛出异常,第四个参数出入this,因为第三个参数worker是静态成员函数不能访问非静态成员变量if (pthread_create(m_threads + i, NULL, worker, this) != 0) { delete[] m_threads;throw std::exception();}// 设置线程分离,如果分离失败则删除数组并抛出异常if (pthread_detach(m_threads[i])) {delete[] m_threads;throw std::exception();} }
}template <typename T>
threadpool<T>::~threadpool() {delete[] m_threads;m_stop = true;
}template <typename T>
bool threadpool<T>::append(T* request) {m_queuelocker.lock(); // 队列上锁// 如果当前工作队列已满,则队列解锁并退出程序if (m_workqueue.size() > m_max_requests) {m_queuelocker.unlock();return false;}// 将任务添加到当前队列m_workqueue.push_back(request); // 尾插m_queuelocker.unlock(); // 队列解锁m_queuestate.post(); // 队列信号量加1return true; // 退出程序
}template <typename T>
void* threadpool<T>::worker(void* arg) {threadpool* pool = (threadpool*) arg; // 将arg强转为线程池类以便调用成员方法pool->run(); // 运行任务return pool;
}template <typename T>
void threadpool<T>::run() {while (!m_stop) {m_queuestate.wait(); // 信号量减1m_queuelocker.lock(); // 队列加锁// 如果工作队列为空,队列解锁,并循环访问if (m_workqueue.empty()) {m_queuelocker.unlock();continue;}// 工作队列不为空,则从队头取任务并处理T* request = m_workqueue.front();m_workqueue.pop_front();m_queuelocker.unlock();if (!request) continue;// 数据库connectionRAII mysqlcon(&request->mysql, m_connPoll);request->process();}
}#endif
3. I/O多路复用——epoll
epoll使程序能够同时监听多个文件描述符,提高系统性能
3.1 select/poll/epoll对比
- 调用函数
- select和poll都是一个函数,epoll是一组函数
- 文件描述符数量
- select通过线性表描述文件描述符集合,文件描述符有上限,一般是1024,但可以修改源码,重新编译内核,不推荐
- poll是链表描述,突破了文件描述符上限,最大可以打开文件的数目
- epoll通过红黑树描述,最大可以打开文件的数目,可以通过命令ulimit -n number修改,仅对当前终端有效
- 将文件描述符从用户传给内核
- select和poll通过将所有文件描述符拷贝到内核态,每次调用都需要拷贝
- epoll通过epoll_create建立一棵红黑树,通过epoll_ctl将要监听的文件描述符注册到红黑树上
- 内核判断就绪的文件描述符
- select和poll通过遍历文件描述符集合,判断哪个文件描述符上有事件发生
- epoll_create时,内核除了帮我们在epoll文件系统里建了个红黑树用于存储以后epoll_ctl传来的fd外,还会再建立一个list链表,用于存储准备就绪的事件,当epoll_wait调用时,仅仅观察这个list链表里有没有数据即可。epoll是根据每个fd上面的回调函数(中断函数)判断,只有发生了事件的socket才会主动的去调用 callback函数,其他空闲状态socket则不会,若是就绪事件,插入list。
- 应用程序索引就绪文件描述符
- select/poll只返回发生了事件的文件描述符的个数,若知道是哪个发生了事件,同样需要遍历
- epoll返回的发生了事件的个数和结构体数组,结构体包含socket的信息,因此直接处理返回的数组即可
- 工作模式(见3.2)
- select和poll都只能工作在相对低效的LT模式下
- epoll则可以工作在ET高效模式,并且epoll还支持EPOLLONESHOT事件,该事件能进一步减少可读、可写和异常事件被触发的次数。
- 应用场景
- 当所有的fd都是活跃连接,使用epoll,需要建立文件系统,红黑树和链表对于此来说,效率反而不高,不如select和poll
- 当监测的fd数目较小,且各个fd都比较活跃,建议使用select或者poll
- 当监测的fd数目非常大,成千上万,且单位时间只有其中的一部分fd处于就绪状态,这个时候使用epoll能够明显提升性能
3.2 触发模式
-
LT水平触发模式(缺省(即默认)的工作方式)
- epoll_wait检测到文件描述符有事件发生,则将其通知给应用程序,应用程序可以不立即处理该事件。
- 当下一次调用epoll_wait时,epoll_wait还会再次向应用程序报告此事件,直至被处理
-
ET边缘触发模式
- epoll_wait检测到文件描述符有事件发生,则将其通知给应用程序,应用程序必须立即处理该事件
- 必须要一次性将数据读取完,只支持非阻塞I/O,读取到出现eagain,以避免由于一个文件句柄的阻塞读/阻塞写操作把处理多个文件描述符的任务饿死
-
EPOLLONESHOT
- 背景:一个线程读取某个socket上的数据后开始处理数据,在处理过程中该socket上又有新数据可读,此时另一个线程被唤醒读取,此时出现两个线程处理同一个socket
- 我们期望的是一个socket连接在任一时刻都只被一个线程处理,通过epoll_ctl对该文件描述符注册epolloneshot事件,一个线程处理socket时,其他线程将无法处理,当该线程处理完后,需要通过epoll_ctl重置epolloneshot事件
3.3 epoll-API
#include <sys/epoll.h>
// 1.创建一个指示epoll内核事件表的文件描述符。包括两部分数据,一个是需要检测的文件描述符的信息(红黑树),另一个是就绪列表,存放检测到数据发送改变的文件描述符信息(双向链表)。
int epoll_create(int size); // size没有意义,只要大于0即可,返回值如果失败是-1,成功返回epoll的文件描述符// 2.操作内核事件表监控的文件描述符上的事件,包括注册、修改、删除
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
/* - 参数:- epfd : epoll_create返回的文件描述符- op : 要进行什么操作EPOLL_CTL_ADD: 注册新的fd到epfdEPOLL_CTL_MOD: 修改已经注册的fd的监听事件EPOLL_CTL_DEL: 从epfd删除一个fd- fd : 监控的文件描述符- event : 告诉内核需要监听的事件struct epoll_event {uint32_t events; // Epoll eventsepoll_data_t data; // User data variable};常见的Epoll检测事件:EPOLLIN:表示对应的文件描述符可以读(包括对端SOCKET正常关闭)EPOLLOUT:表示对应的文件描述符可以写EPOLLPRI:表示对应的文件描述符有紧急的数据可读(这里应该表示有带外数据到来)EPOLLERR:表示对应的文件描述符发生错误EPOLLHUP:表示对应的文件描述符被挂断;EPOLLET:将EPOLL设为边缘触发(Edge Triggered)模式,这是相对于水平触发(Level Triggered)而言的EPOLLONESHOT:只监听一次事件,当监听完这次事件之后,如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里typedef union epoll_data {void *ptr;int fd;uint32_t u32;uint64_t u64;} epoll_data_t;
*/// 3.等待所监控文件描述符上有事件的产生,返回就绪的文件描述符个数
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
/*- 参数:- epfd : epoll_create返回的文件描述符- events : 传出参数,用来存内核得到事件的集合- maxevents : 第二个参数结构体数组的大小,这个maxevents的值不能大于创建epoll_create()时的size- timeout : 阻塞时间- 0 : 不阻塞- -1 : 阻塞,直到检测到fd数据发生变化,解除阻塞- > 0 : 阻塞的时长(毫秒)- 返回值:- >0 : 成功,返回有多少文件描述符就绪- 0 : 时间到- -1 : 失败
*/
3.4 代码实现
main.cpp文件中
// 外部函数,定义在了http_conn.cpp中
// 设置文件描述符非阻塞
extern void setnonblocking(int fd);
// 添加文件描述符到epoll
extern int addfd(int epollfd, int fd, bool one_shot);
// 从epoll中删除文件描述符
extern int removefd(int epollfd, int fd);
// 修改文件描述符到epoll
extern int modfd(int epollfd, int fd, int ev);
http_conn.cpp文件中
/*------------文件描述符操作----------*/
// 设置文件描述符非阻塞
void setnonblocking(int fd) {// 获取文件描述符文件状态flagint old_flag = fcntl(fd, F_GETFL); // 添加非阻塞 int new_flag = old_flag | O_NONBLOCK; // 设置文件描述符文件状态flagfcntl(fd, F_SETFL, new_flag);
}// 添加文件描述符到epoll
int addfd(int epollfd, int fd, bool one_shot) {// 事件设置epoll_event event;event.data.fd = fd;#ifdef listenfdLTevent.events = EPOLLIN | EPOLLRDHUP; // 默认是水平触发,EPOLLIN表示对应的文件描述符可以读(包括对端SOCKET正常关闭),EPOLLHUP表示对应的文件描述符被挂断
#endif#ifdef listenfdETevent.events = EPOLLIN | EPOLLET | EPOLLRDHUP;
#endif#ifdef connfdLTevent.events = EPOLLIN | EPOLLRDHUP;
#endif#ifdef connfdETevent.events = EPOLLIN | EPOLLET | EPOLLRDHUP;
#endifif (one_shot) event.events |= EPOLLONESHOT; // 注册epolloneshot事件,一个线程处理socket时,其他线程将无法处理(listenfd不用开启)// 注册内核事件表监控的文件描述符上的事件epoll_ctl(epollfd, EPOLL_CTL_ADD, fd, &event); // 设置文件描述符非阻塞(ET模式只支持非阻塞)setnonblocking(fd);
}// 从epoll中删除文件描述符
void removefd(int epollfd, int fd) {epoll_ctl(epollfd, EPOLL_CTL_DEL, fd, 0); // 删除内核事件表监控的文件描述符上的事件close(fd);
}// 修改文件描述符到epoll,重置socket上的EPOLLPONESHOT事件,以确保下次可读时EPOLLIN事件能被触发
void modfd(int epollfd, int fd, int ev) {epoll_event event;event.data.fd = fd;#ifdef connfdLTevent.events = ev | EPOLLONESHOT | EPOLLRDHUP;
#endif#ifdef connfdETevent.events = ev | EPOLLET | EPOLLONESHOT | EPOLLRDHUP;
#endifepoll_ctl(epollfd, EPOLL_CTL_MOD, fd, &event);
}
4. HTTP
4.1 HTTP报文格式
- 请求报文
HTTP请求报文由请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。请求分为GET和POST两种
- GET
GET /562f25980001b1b106000338.jpg HTTP/1.1
Host:img.mukewang.com
User-Agent:Mozilla/5.0 (Windows NT 10.0; WOW64)
AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36
Accept:image/webp,image/*,*/*;q=0.8
Referer:http://www.imooc.com/
Accept-Encoding:gzip, deflate, sdch
Accept-Language:zh-CN,zh;q=0.8
空行
请求数据为空
- POST
POST / HTTP1.1
Host:www.wrox.com
User-Agent:Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 2.0.50727; .NET CLR 3.0.04506.648; .NET CLR 3.5.21022)
Content-Type:application/x-www-form-urlencoded
Content-Length:40
Connection: Keep-Alive
空行
name=Professional%20Ajax&publisher=Wiley
- 请求行:用来说明请求类型,要访问的资源以及所使用的HTTP版本。
GET说明请求类型为GET,/562f25980001b1b106000338.jpg为要访问的资源,该行的最后一部分说明使用的是HTTP1.1版本。- 请求头部:紧接着请求行(即第一行)之后的部分,用来说明服务器要使用的附加信息。
- HOST,给出请求资源所在服务器的域名。
- User-Agent,HTTP客户端程序的信息,该信息由你发出请求使用的浏览器来定义,并且在每个请求中自动发送等。
- Accept,说明用户代理可处理的媒体类型。
- Accept-Encoding,说明用户代理支持的内容编码。
- Accept-Language,说明用户代理能够处理的自然语言集。
- Content-Type,说明实现主体的媒体类型。
- Content-Length,说明实现主体的大小。
- Connection,连接管理,可以是Keep-Alive或close。
- 空行:请求头部后面的空行是必须的即使第四部分的请求数据为空,也必须有空行。
- 请求数据:也成为主体,可以添加任意的其他数据。
- 响应报文
HTTP响应也由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
HTTP/1.1 200 OK
Date: Fri, 22 May 2009 06:07:21 GMT
Content-Type: text/html; charset=UTF-8
空行
<html><head></head><body><!--body goes here--></body>
</html>
- 状态行:由HTTP协议版本号, 状态码, 状态消息组成。HTTP/1.1表明HTTP版本为1.1版本,状态码为200,状态消息为OK。
- 消息报头:用来说明客户端要使用的一些附加信息。第二行和第三行为消息报头,Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8。
- 空行:消息报头后面的空行是必须的。
- 响应正文:服务器返回给客户端的文本信息。空行后面的html部分为响应正文。
4.2 HTTP状态码
HTTP有5种类型的状态码:
-
1xx:指示信息–表示请求已接收,继续处理。
-
2xx:成功–表示请求正常处理完毕。
- 200 OK:客户端请求被正常处理。
- 206 Partial content:客户端进行了范围请求。
-
3xx:重定向–要完成请求必须进行更进一步的操作。
- 301 Moved Permanently:永久重定向,该资源已被永久移动到新位置,将来任何对该资源的访问都要使用本响应返回的若干个URI之一。
- 302 Found:临时重定向,请求的资源现在临时从不同的URI中获得。
-
4xx:客户端错误–请求有语法错误,服务器无法处理请求。
- 400 Bad Request:请求报文存在语法错误。
- 403 Forbidden:请求被服务器拒绝。
- 404 Not Found:请求不存在,服务器上找不到请求的资源。
-
5xx:服务器端错误–服务器处理请求出错。
- 500 Internal Server Error:服务器在执行请求时出现错误。
4.3 有限状态机
有限状态机是一种抽象的理论模型,它能把有限个变量描述的状态变化过程以可构造可验证的方式呈现出来
STATE_MACHINE()
{State cur_State = type_A;while( cur_State != type_C ){Package _pack = getNewPackage();switch( cur_State ){case type_A:process_package_state_A( _pack );cur_State = type_B;break;case type_B:process_package_state_B( _pack );cur_State = type_C;break;} }
}
上述状态机包含三种状态:type_A、type_B 和 type_C,其中 type_A 是状态机的开始状态,type_C 是状态机的结束状态。状态机的当前状态记录在 cur_State 变量中。在一趟循环过程中,状态机先通getNewPackage 方法获得一个新的数据包,然后根据 cur_State 变量的值判断如何处理该数据包。数据包处理完之后,状态机通过给 cur_State 变量传递目标状态值来实现状态转移。那么当状态机进入下一趟循环时,它将执行新的状态对应的逻辑。
- 有限状态机一种逻辑单元内部的一种高效编程方法,在服务器编程中,服务器可以根据不同状态或者消息类型进行相应的处理逻辑,使得程序逻辑清晰易懂。
4.4 HTTP处理流程
4.4.1 整体流程
- 浏览器端发出http连接请求,主线程创建http对象接收请求并将所有数据读入对应buffer,将该对象插入任务队列,工作线程从任务队列中取出一个任务进行处理。
- 工作线程取出任务后,调用process_read函数,通过主、从状态机对请求报文进行解析。
- 解析完之后,跳转do_request函数生成响应正文,通过process_write(生成了状态行、消息报头等响应报文)写入buffer,再通过writev函数返回给浏览器端。
4.4.2 主线程接收数据并存入缓冲区
/*------------读----------*/
// 服务器主线程循环读取客户数据,直到无数据可读或对方关闭连接,如果时ET模式,则需要循环读取,而LT不需要
bool http_conn::read() {// 如果读缓冲区满了,则返回falseif (m_read_idx >= READ_BUFFER_SIZE) return false; // 读取到的字节int bytes_read = 0;#ifdef connfdLTbytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);m_read_idx += bytes_read;if (bytes_read <= 0) return false;printf("读取到了数据:%s\n", m_read_buf);return true;
#endif#ifdef connfdETwhile (true) {bytes_read = recv(m_sockfd, m_read_buf + m_read_idx, READ_BUFFER_SIZE - m_read_idx, 0);if (bytes_read == -1) {if (errno == EAGAIN || errno == EWOULDBLOCK) break; // 没有数据return false;} else if (bytes_read == 0) return false; // 客户端已经断开连接m_read_idx += bytes_read;}printf("读取到了数据:%s\n", m_read_buf);return true;
#endif
}
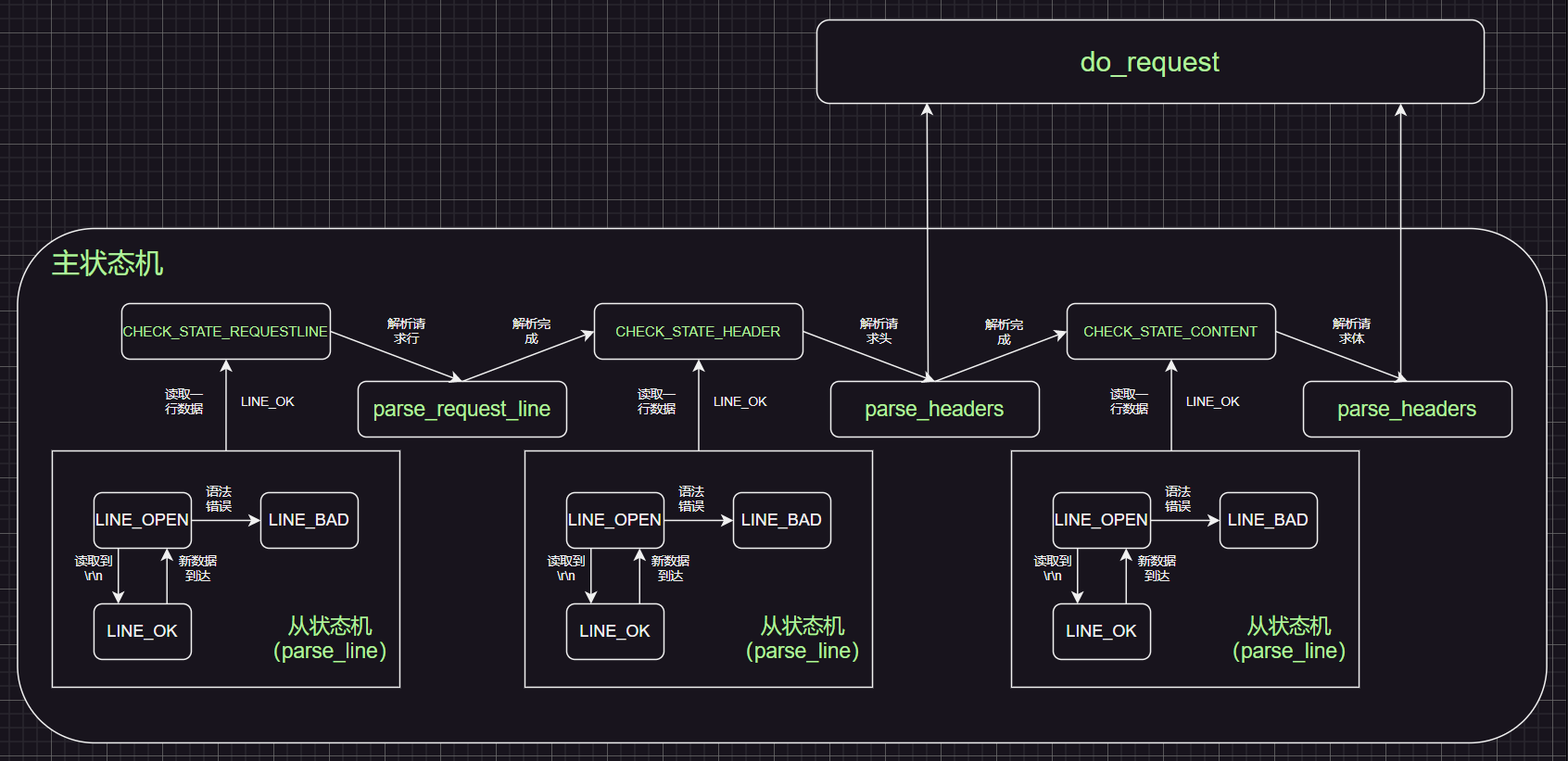
4.4.3 主、从状态机对请求报文进行解析
主状态机负责对该行数据进行解析,从状态机负责读取报文的一行,主状态机内部调用从状态机,从状态机驱动主状态机。
- 主状态机(三种状态,标识解析位置)
- CHECK_STATE_REQUESTLINE,解析请求行
- CHECK_STATE_HEADER,解析请求头
- CHECK_STATE_CONTENT,解析消息体,仅用于解析POST请求
- 从状态机(三种状态,标识解析一行的读取状态)
- LINE_OK,完整读取一行
- LINE_BAD,报文语法有误
- LINE_OPEN,读取的行不完整
4.4.4 主线程发送数据
- writev函数用于在一次函数调用中写多个非连续缓冲区,有时也将这该函数称为聚集写。响应报文分为两种
- 一种是请求文件的存在,通过io向量机制iovec,声明两个iovec,第一个指向m_write_buf(状态行、消息报头、空行等),第二个指向mmap的地址m_file_address(响应正文,此处用了内存映射用来提高文件的访问速度);
- 一种是请求出错,这时候只申请一个iovec,指向m_write_buf
/*------------写----------*/
// 服务器主线程检测写事件,并调用http_conn::write函数将响应报文发送给浏览器端
bool http_conn::write() {int temp = 0; // 发送字节数// 若要发送数据长度为0,表示响应报文为空,一般不会出现这种情况if (bytes_to_send == 0) {modfd(m_epollfd, m_sockfd, EPOLLIN);init();return true;}while (1) {// 将响应报文的状态行、消息头、空行和响应正文发送给浏览器端temp = writev(m_sockfd, m_iv, m_iv_count); // writev函数用于在一次函数调用中写多个非连续缓冲区,称为聚集写if (temp < 0) {if (errno == EAGAIN) {modfd(m_epollfd, m_sockfd, EPOLLOUT);return true;}unmap();return false;}bytes_have_send += temp;bytes_to_send -= temp;// 第一个iovec头部信息的数据已发送完,发送第二个iovec数据if (bytes_have_send >= m_iv[0].iov_len) {// 不再继续发送头部信息m_iv[0].iov_len = 0;m_iv[1].iov_base = m_file_address + bytes_have_send - m_write_idx;m_iv[1].iov_len = bytes_to_send;} else {// 继续发送第一个iovec头部信息数据m_iv[0].iov_base = m_write_buf + bytes_to_send;m_iv[0].iov_len = m_iv[0].iov_len - bytes_have_send;}// 若数据全部发送完毕if (bytes_to_send <= 0) {unmap(); // 取消映射// 重新注册写事件modfd(m_epollfd, m_sockfd, EPOLLIN);if (m_linger) {init();return true;} else return false;}}
}5. 定时器处理非活动连接
5.1 基本概念
- 非活动:浏览器与服务器端建立连接后,长时间不交换数据,一直占用服务器端的文件描述符,导致连接资源的浪费。
- 定时事件:固定一段时间之后触发某段代码,由该段代码处理一个事件(如从内核事件表删除事件,并关闭文件描述符,释放连接资源)。
- 定时器:利用结构体或其他形式,将多种定时事件进行封装起来(本项目只涉及一种定时事件,即定期检测非活跃连接,这里将该定时事件与连接资源封装为一个结构体定时器)。
- 定时器容器:使用某种容器类数据结构,将上述多个定时器组合起来,便于对定时事件统一管理(本项目中使用升序链表将所有定时器串联组织起来)。
5.2 实现方法
- 流程:本项目利用
alarm函数周期性地触发SIGALRM信号,信号处理函数利用管道通知主循环,主循环接收到该信号后对升序链表上所有定时器进行处理,若该段时间内没有交换数据,则将该连接关闭,释放所占用的资源。 - 运行机制:Linux下的信号采用的异步处理机制,信号处理函数和当前进程是两条不同的执行路线。具体的,当进程收到信号时,操作系统会中断进程当前的正常流程,转而进入信号处理函数执行操作,完成后再返回中断的地方继续执行。
- 统一事件源:将信号事件与其他事件一样被处理。信号处理函数使用管道将信号传递给主循环,信号处理函数往管道的写端写入信号值,主循环则从管道的读端读出信号值,使用I/O复用系统调用来监听管道读端的可读事件,这样信号事件与其他文件描述符都可以通过epoll来监测,从而实现统一处理。
- 注意事项:一般的信号处理函数需要处理该信号对应的逻辑,当该逻辑比较复杂时,信号处理函数执行时间过长,会导致信号屏蔽太久。为了避免这种现象的发生,信号处理函数仅仅发送信号通知程序主循环,将信号对应的处理逻辑放在程序主循环中,由主循环执行信号对应的逻辑代码。
6. 日志系统
6.1 基本概念
-
日志:由服务器自动创建,并记录运行状态,错误信息,访问数据的文件。
-
同步日志:日志写入函数与工作线程串行执行,由于涉及到I/O操作,当单条日志比较大的时候,同步模式会阻塞整个处理流程,服务器所能处理的并发能力将有所下降,尤其是在峰值的时候,写日志可能成为系统的瓶颈。
-
异步日志:将所写的日志内容先存入阻塞队列,写线程从阻塞队列中取出内容,写入日志。
-
生产者-消费者模型,并发编程中的经典模型。以多线程为例,为了实现线程间数据同步,生产者线程与消费者线程共享一个缓冲区,其中生产者线程往缓冲区中push消息,消费者线程从缓冲区中pop消息。
-
阻塞队列:将生产者-消费者模型进行封装,使用循环数组实现队列,作为两者共享的缓冲区。
-
单例模式:保证一个类只创建一个实例,同时提供全局访问的方法。
6.2 实现方法
- 功能:本项目中,使用单例模式创建日志系统,对服务器运行状态、错误信息和访问数据进行记录,该系统可以实现按天分类,超行分类功能,可以根据实际情况分别使用同步和异步写入两种方式。
- 单例模式实现思路:私有化构造函数,以防止外界创建单例类的对象;使用类的私有静态指针变量指向类的唯一实例,并用一个公有的静态方法获取该实例。单例模式有两种实现方法,分别是懒汉模式(不用的时候不去初始化,所以在第一次被使用时才进行初始化)和饿汉模式(即迫不及待,在程序运行时立即初始化)。本项目使用的是懒汉模式。
- 异步写入方式:将生产者-消费者模型封装为阻塞队列,创建一个写线程,工作线程将要写的内容push进队列,写线程从队列中取出内容,写入日志文件。
7. 数据库连接池
7.1 基本概念
- 什么是数据库连接池?
- 池是一组资源的集合,这组资源在服务器启动之初就被完全创建好并初始化(池是资源的容器,本质上是对资源的复用)。连接池中的资源为一组数据库连接,由程序动态地对池中的连接进行使用,释放。
- 当系统开始处理客户请求的时候,如果它需要相关的资源,可以直接从池中获取,无需动态分配;当服务器处理完一个客户连接后,可以把相关的资源放回池中,无需执行系统调用释放资源。
- 数据库访问的一般流程是什么?
- 当系统需要访问数据库时,先系统创建数据库连接,完成数据库操作,然后系统断开数据库连接。
- 为什么要创建连接池?
- 从一般流程中可以看出,若系统需要频繁访问数据库,则需要频繁创建和断开数据库连接,而创建数据库连接是一个很耗时的操作,也容易对数据库造成安全隐患。
- 在程序初始化的时候,集中创建多个数据库连接,并把他们集中管理,供程序使用,可以保证较快的数据库读写速度,更加安全可靠。
7.2 方法
- 使用局部静态变量懒汉模式创建连接池。将数据库连接的获取与释放通过RAII机制封装,避免手动释放。
8. 压力测试
Webbench 是 Linux 上一款知名的、优秀的 web 性能压力测试工具。它是由Lionbridge公司开发。
测试处在相同硬件上,不同服务的性能以及不同硬件上同一个服务的运行状况。
展示服务器的两项内容:每秒钟响应请求数和每秒钟传输数据量。
基本原理:Webbench 首先 fork 出多个子进程,每个子进程都循环做 web 访问测试。子进程把访问的结果通过pipe 告诉父进程,父进程做最终的统计结果。
测试示例
webbench -c 1000 -t 30 http://192.168.110.129:10000/index.html
参数:-c 表示客户端数-t 表示时间
9. 测试方法
- 编译
g++ *.cpp -lmysqlclient -lpthread
- 运行
./a.out 10000
- 压力测试(在另一个终端,进入webbench-1.5文件夹)
// 先make
make
// 再测试
./webbench -c 10000 -t 5 http://192.168.154.128:10000/0
源码已上传至github
https://github.com/chaoproz/myWebServer