🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
Transformer 是工业化、同质化的后深度学习模型,专为超级计算机上的并行计算而设计。通过同质化,一个 Transformer 模型可以执行广泛的任务而无需微调。Transformers 可以对具有数十亿参数的数十亿原始未标记数据记录执行自我监督学习。
这些特别后深度学习的架构称为基础模型。基础模型变压器代表了始于 2015 年机器对机器自动化的第四次工业革命的缩影这将把一切与一切联系起来。总体而言,人工智能,特别是工业 4.0 ( I4.0 ) 的自然语言处理( NLP )已经远远超出了过去的软件实践。
在不到五年的时间里,人工智能已经成为一种具有无缝 API 的有效云服务。在许多情况下,以前下载图书馆和开发的范式正在成为一种教育活动。
工业 4.0 项目经理可以去 OpenAI 的云平台,注册,获取 API 密钥,几分钟后就可以开始工作了。然后,用户可以输入文本,指定 NLP 任务,并获得 GPT-3 转换器引擎发送的响应。最后,用户可以在没有编程知识的情况下访问 GPT-3 Codex 并创建应用程序。即时工程是从这些模型中出现的一项新技能。
但是,有时 GPT-3 模型可能不适合特定任务。例如,项目经理、顾问或开发人员可能希望使用由 Google AI、Amazon Web Services ( AWS )、Allen Institute for AI 或 Hugging Face 提供的另一个系统。
项目经理应该选择在当地工作吗?还是应该直接在 Google Cloud、Microsoft Azure 或 AWS 上进行实施?开发团队应该选择 Hugging Face、Google Trax、OpenAI 还是 AllenNLP?人工智能专家或数据科学家是否应该使用几乎没有人工智能开发的 API?
答案就是以上所有。您不知道未来的雇主、客户或用户可能想要或指定什么。因此,您必须准备好适应出现的任何需求。这本书没有描述市场上存在的所有产品。然而,本书为读者提供了足够的解决方案来适应工业 4.0 人工智能驱动的 NLP 挑战。
本章首先从高层次解释什么是变压器。然后本章解释了灵活理解实现转换器的所有类型方法的重要性。市场上可用的 API 和自动化的数量模糊了平台、框架、库和语言的定义。
最后,本章介绍了工业 4.0 人工智能专家在嵌入式变压器方面的作用。
在开始探索本书中描述的各种变压器模型实现的旅程之前,我们需要解决这些关键概念。
本章涵盖以下主题:
- 第四次工业革命,工业4.0的出现
- 基础模型的范式变化
- 引入即时工程,一项新技能
- 变压器的背景
- 实施变压器的挑战
- 改变游戏规则的 Transformer 模型 API
- 选择变压器库的难点
- 选择变压器型号的难点
- 工业 4.0 人工智能专家的新角色
- 嵌入式变压器
我们的第一步将是探索变压器的生态系统。
变压器生态系统
变压器型号代表了这样的范式变化,他们需要一个新名称来描述它们:基础模型。因此,斯坦福大学创建了基础模型研究中心( CRFM )。在2021 年 8 月,CRFM 发表了一篇由一百多位科学家和专业人士撰写的200 页论文(参见参考文献部分): On the Opportunities and Risks of Foundation Models。
基金会模型不是由学术界创建的,而是由大型科技行业创建的。例如,谷歌发明了变压器模型,这导致了谷歌 BERT。微软与 OpenAI 合作生产 GPT-3。
大型科技公司必须找到更好的模型来应对流入其数据中心的 PB 级数据的指数级增长。因此,变形金刚是出于需要而诞生的。
让我们首先考虑工业 4.0,以了解拥有工业化人工智能模型的必要性。
工业4.0
农业革命导致了引入机械的第一次工业革命。这第二次工业革命催生了电力、电话和飞机。第三次工业革命是数字化的。
第四产业革命或工业 4.0 催生了无限数量的机器对机器连接:机器人、机器人、联网设备、自动驾驶汽车、智能手机、从社交媒体存储中收集数据的机器人等等。
反过来,这些数以百万计的机器和机器人每天都会产生数十亿的数据记录:图像、声音、文字和事件,如图 1.1所示: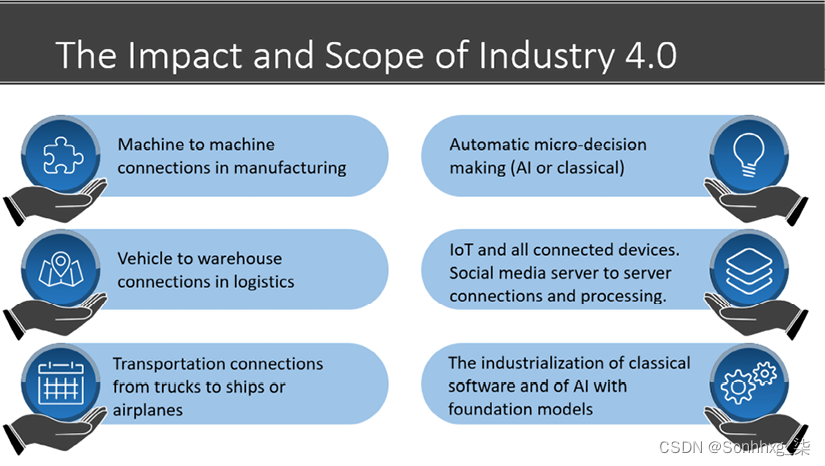
图 1.1:工业 4.0 的范围
工业 4.0 要求智能算法在没有人为干预的情况下大规模处理数据并做出决策,以面对人类历史上看不见的数据量。
大型科技公司需要找到一个单一的人工智能模型,该模型可以执行过去需要几种单独算法的各种任务。
基础模型
变形金刚有两个明显的特征:高度同质化和令人兴奋的涌现特性。同质化使得使用一个模型来执行各种各样的任务成为可能。这些能力是通过在超级计算机上训练十亿参数模型而出现的。
范式变化使基础模型成为后深度学习生态系统,如图 1.2所示: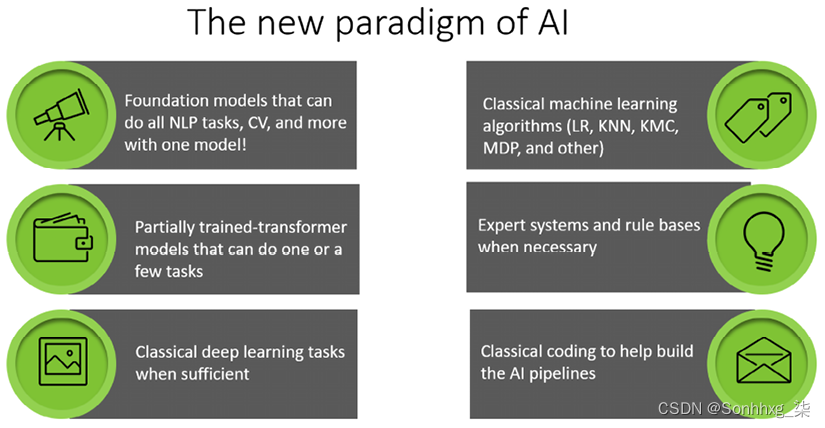
图 1.2:I4.0 人工智能专家的范围
基础模型,虽然采用创新架构设计,建立在人工智能历史之上。结果,人工智能专家的技能范围正在扩大!
目前的 Transformer 模型生态系统不同于人工智能的任何其他进化,可以概括为四个属性:
因此,基础模型是在超级计算机上训练的变压器模型数十亿条数据记录和数十亿个参数。然后,该模型无需进一步微调即可执行广泛的任务。因此,基础模型的规模是独一无二的。这些经过充分训练的模型通常称为引擎。因此,只有 GPT-3、Google BERT 和少数变压器引擎可以作为基础模型。
本书中提到 OpenAI 的 GPT-3 或 Google 的 BERT 模型时,我只会提到基础模型。这是因为 GPT-3 和 Google BERT 在超级计算机上进行了全面训练。虽然在有限的使用范围内有趣且有效,但由于缺乏资源,其他模型无法达到基础模型的同质化水平。
现在让我们探讨一个示例,说明基础模型如何工作并改变了我们开发程序的方式。
编程正在成为 NLP 的一个子领域吗?
陈等人。(2021) 于 2021 年 8 月在 Codex 上发表了一篇重磅论文,这是一个 GPT-3 模型,可以将自然语言转换为源代码。Codex 接受了 5400 万个公共 GitHub 软件存储库的培训。Codex 可以为源代码生成有趣的自然语言,正如我们将在第 16 章“变压器驱动副驾驶的出现”中看到的那样。
现在编程是从自然语言到源代码语言的翻译任务吗?
编程正在成为 GPT-3 引擎的 NLP 任务吗?
在回答这个问题之前,让我们看一个例子。
请记住,Codex 是一种随机算法,因此元语言很棘手。如果您不小心正确地设计提示,您可能不会生成您期望的内容。
我建立我在试验 Codex 时的一些提示。此示例只是为了说明 Codex 的工作原理,纯粹用于教育目的。
我的提示是:
- “在 Python 中生成 200 个介于 1 和 100 之间的整数的随机分布”
- “使用 matplotlib 绘制数据”
- “创建一个具有 3 个质心的 k-means 聚类模型并拟合模型”
- “打印集群标签”
- “绘制集群”
- “用质心绘制集群”
Codex 自动将我的自然元语言提示翻译成 Python!
法典是一个随机模型,因此如果您再试一次,它可能不会重现完全相同的代码。您必须通过实验来学习元语言,直到您可以像赛车一样驾驶它!
Python程序是自动生成的,可以复制和测试:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets.samples_generator import make_blobs
# generate random data
np.random.seed(0)
X, y = make_blobs(n_samples=200, centers=3, n_features=2, cluster_std=2, random_state=0)
# plot the data
plt.scatter(X[:, 0], X[:, 1], s=50)
plt.show()
# create the k-means model
kmeans = KMeans(n_clusters=3, random_state=0)
# fit the model to the data
kmeans.fit(X)
# print the cluster labels
print(kmeans.labels_)
#plot the clusters
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap='rainbow')
plt.show()
# plot the clusters with centroids
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, cmap='rainbow')
plt.scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1], c='black', s=100, alpha=0.5)
plt.show()你可以复制并粘贴此程序。有用。您还可以尝试 JavaScript,以及其他实验。
GitHub Copilot 现在可与一些 Microsoft 开发工具一起使用,我们将在第 16 章“变压器驱动 Copilot 的出现”中看到。如果您学习即时工程元语言,您将在未来几年减少开发时间。
如果最终用户掌握了元语言,他们就可以创建原型和/或小任务。未来,编码副驾驶将会扩大。
我们将在第 16 章中了解 Codex 在人工智能未来中的位置。
至此,让我们来一睹人工智能专家的美好未来。
人工智能专家的未来
社会不应低估基础模型的影响。即时工程已成为人工智能专家所需的技能。然而,人工智能专家的未来并不仅限于变形金刚。人工智能和数据科学在 I4.0 中重叠。
人工智能专家将参与使用经典人工智能、物联网、边缘计算等的机器对机器算法。人工智能专家还将使用经典算法设计和开发机器人、机器人、服务器和所有类型的连接设备之间的迷人连接。
因此,本书不仅限于快速工程,还包括成为“工业 4.0 人工智能专家”或“I4.0 人工智能专家”所需的广泛设计技能。
迅速的工程是人工智能专家必须发展的设计技能的一个子集。因此,在本书中,我将未来的人工智能专家称为“工业 4.0 人工智能专家”。
现在让我们大致了解一下转换器如何优化 NLP 模型。
使用转换器优化 NLP 模型
包括 LSTM 在内的循环神经网络( RNN ) 已将神经网络应用于 NLP 序列几十年的模型。但是,使用循环功能在面对长序列和大量参数时达到极限。因此,最先进的变压器模型现在盛行。
本节简要介绍了导致 Transformer 的 NLP 背景,我们将在第 2 章“ Transformer 模型架构入门”中更详细地描述。然而,首先让我们直观地看一下已经取代 NLP 神经网络的 RNN 层的 Transformer 的注意力头。
Transformer 的核心概念可以粗略地概括为“混合令牌”。NLP 模型首先将单词序列转换为标记。RNN 分析循环函数中的标记。Transformer 不会分析序列中的标记,而是将每个标记与序列中的其他标记关联起来,如图 1.3所示:
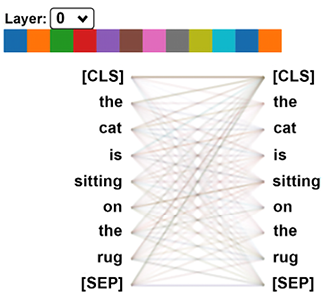
图 1.3:transformer 层的注意力头
我们将浏览一个注意的细节第 2 章中的头。目前,图 1.3的要点是序列中的每个单词(标记)都与序列中的所有其他单词相关。该模型为工业 4.0 NLP 打开了大门。
让我们简要介绍一下变压器的背景。
变压器的背景
在过去的 100 多年里,许多伟大的思想家致力于序列模式和语言造型。结果,机器逐渐学会了如何预测可能的单词序列。引用所有促成这一切的巨头需要一整本书。
在本节中,我将与您分享一些我最喜欢的研究人员,为变形金刚的到来奠定基础。
20 世纪初,安德烈·马尔科夫引入了随机值的概念,并创立了随机过程理论。我们在 AI 中将它们称为马尔可夫决策过程( MDP )、马尔可夫链和马尔可夫过程。在20世纪初,马尔可夫表明我们可以预测下一个元素一个链,一个序列,仅使用该链的最后一个过去元素。他将他的方法应用于包含数千个字母的数据集,使用过去的序列来预测句子的后续字母。请记住,他没有计算机,但证明了今天仍在人工智能中使用的理论。
1948年,克劳德·香农的《通信的数学理论》出版。Claude Shannon 为基于源编码器、发射器和接收器或语义解码器的通信模型奠定了基础。他创造了我们今天所知的信息论。
1950 年,艾伦·图灵发表了他的开创性文章:《计算机与智能》 。艾伦·图灵 (Alan Turing) 的这篇文章基于成功的图灵机上的机器智能,该机在二战期间解密了德国的信息。消息由单词和数字序列组成。
1954 年,Georgetown-IBM 实验使用计算机使用规则系统将俄语句子翻译成英语。规则系统是运行将分析的规则列表的程序语言结构。规则系统仍然存在并且无处不在。然而,在某些情况下,机器智能可以通过自动学习模式来替换数十亿语言组合的规则列表。
1956 年,约翰·麦卡锡(John McCarthy)首次使用“人工智能”一词,当时确定机器可以学习。
1982 年,John Hopfield 引入了一种RNN,称为 Hopfield 网络或“关联”神经网络。John Hopfield 受到 WA Little 的启发,他在 1974 年撰写了《大脑中持久状态的存在》,为数十年来的学习过程奠定了理论基础。RNN 不断发展,LSTM 出现了我们今天所知道的。
RNN 有效地记忆序列的持久状态,如图 1.4所示:
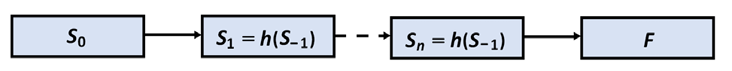
图 1.4:RNN 过程
每个状态S n捕获S n-1的信息。当网络到达终点时,函数F将执行一个动作:转导、建模或任何其他类型的基于序列的任务。
1980 年代,Yann LeCun设计了多功能卷积神经网络(CNN)。他将 CNN 应用于文本序列,它们也应用于序列转导和建模。它们还基于 WA Little 逐层处理信息的持久状态。在 1990 年代,Yann LeCun 总结了几年的工作,产生了 LeNet-5,这导致了我们今天所知道的许多 CNN 模型。然而,CNN 原本高效的架构在处理长而复杂的序列中的长期依赖关系时面临问题。
我们可以提到许多其他伟大的名字、论文和模型,这些名字、论文和模型都会让任何 AI 专家感到谦卑。这些年来,人工智能领域的每个人似乎都走在了正确的轨道上。马尔可夫场、RNN 和 CNN 演变成多种其他模型。注意力的概念出现了:按顺序查看其他标记,而不仅仅是最后一个。它被添加到 RNN 和 CNN 模型中。
之后,如果 AI 模型为了分析需要增加计算机能力的更长序列,人工智能开发人员使用更强大的机器并找到了优化梯度的方法。
对序列到序列模型进行了一些研究,但没有达到预期。
似乎没有别的办法可以取得更大的进展。三十年就这样过去了。然后,从 2017 年底开始,工业化的最先进的 Transformer 出现了它的注意力头子层等。RNN 不再是序列建模的先决条件。
在深入了解原始的 Transformer 架构之前,我们将在第 2 章,开始使用 Transformer 模型的架构,让我们从高层次开始,检查我们应该用来学习和实现 Transformer 模型的软件资源的范式变化。
我们应该使用哪些资源?
工业 4.0 AI 模糊了云平台、框架、库、语言和模型之间的界限。变形金刚是新事物,生态系统的范围和数量令人惊叹。Google Cloud 提供即用型转换器模型。
OpenAI 部署了一个几乎不需要编程的“Transformer”API。Hugging Face 提供云库服务,不胜枚举。
本章将对我们将在本书中实施的一些变压器生态系统进行高级分析。
您选择的资源为 NLP 实现转换器至关重要。这是一个项目的生存问题。想象一下现实生活中的采访或演示。想象一下,您正在与您未来的雇主、您的雇主、您的团队或客户交谈。
例如,您从带有拥抱脸的优秀 PowerPoint 开始您的演示文稿。您可能会从经理那里得到不良反应,他可能会说:“对不起,但我们在这种类型的项目中使用 Google Trax,而不是 Hugging Face。请问您可以实施 Google Trax 吗?“如果你不这样做,你的游戏就结束了。
专门研究 Google Trax 可能会出现同样的问题。但是,相反,您可能会得到想要使用 OpenAI 的 GPT-3 引擎和 API 而没有开发的经理的反应。如果您专注于 OpenAI 的 GPT-3 引擎,但没有开发,您可能会遇到更喜欢 Hugging Face 的 AutoML API 的项目经理或客户。可能发生在你身上的最糟糕的事情是经理接受了你的解决方案,但最终,它对那个项目的 NLP 任务根本不起作用。
要记住的关键概念是,如果您只专注于您喜欢的解决方案,您很可能会在某个时候与船一起沉没。
专注于您需要的系统,而不是您喜欢的系统。
本书并非旨在解释市场上存在的每一种变压器解决方案。相反,本书旨在解释足够多的 Transformer 生态系统,让您能够灵活地适应 NLP 项目中面临的任何情况。
在本节中,我们将介绍您将面临的一些挑战。但首先,让我们从 API 开始。
Transformer 4.0 无缝 API 的兴起
我们现在顺利进入工业化人工智能时代。微软、谷歌、亚马逊网络服务( AWS ) 和 IBM 等提供人工智能服务没有开发人员或开发团队希望表现出色。科技巨头拥有价值数百万美元的超级计算机,拥有大量数据集来训练变压器模型和人工智能模型。
大型科技巨头拥有广泛的企业客户,他们已经在使用他们的云服务。因此,将转换器 API 添加到现有云架构所需的工作量比任何其他解决方案都要少。
小公司甚至个人都可以通过 API 访问最强大的变压器模型,而几乎不需要开发投资。实习生可以在几天内实现 API。无需成为工程师或拥有博士学位。对于这样一个简单的实现。
例如,OpenAI 平台现在有一个SaaS(软件即服务)API,用于市场上一些最有效的变压器模型。
OpenAI Transformer 模型非常有效和人性化,目前的政策要求潜在用户填写申请表。一旦请求被接受,用户就可以访问自然语言处理领域!
OpenAI 的 API 的简单性让用户大吃一惊:
- 一键获取API密钥
- 将 OpenAI 导入到笔记本中
- 在提示中输入您希望的任何 NLP 任务
- 您将收到一定数量的令牌(长度)作为完成的响应
就是这样!欢迎来到第四次工业革命和 AI 4.0!
专注于纯代码解决方案的工业 3.0 开发人员将演变为具有跨学科思维的工业 4.0 开发人员。
4.0 开发人员将学习如何设计方法来向Transformer 模型展示预期的内容,而不是像 3.0 开发人员那样直观地告诉它要做什么。我们将在第 7 章“使用 GPT-3 引擎的超人变形金刚的崛起”中通过 GPT-2 和 GPT-3 模型探索这种新方法。
AllenNLP 为变压器提供免费使用的在线教育界面。AllenNLP 还提供了一个可以安装在笔记本中的库。例如,假设我们被要求实施共指分辨率。我们可以从在线运行一个示例开始。
共指解析任务涉及找到一个单词所指的实体,如图 1.5所示的句子:
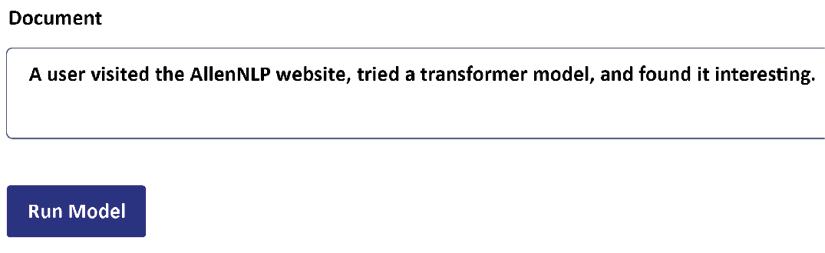
图 1.5:在线运行 NLP 任务
“它”这个词可以指网站或变压器模型。在这种情况下,类 BERT 模型决定将“它”链接到变压器模型。AllenNLP 提供了一个格式化的输出,如图 1.6所示:
图 1.6:AllenNLP 变压器模型的输出
此示例可以在AllenNLP - Demo运行。Transformer 模型不断更新,因此您可能会获得不同的结果。
尽管 API 可以满足许多需求,但它们也有局限性。多用途 API 可能在所有任务中都相当好,但对于特定的 NLP 任务来说还不够好。翻译变压器不是一件容易的事。在在这种情况下,4.0 开发人员、顾问或项目经理必须证明仅 API 无法解决所需的特定 NLP 任务。我们需要搜索一个可靠的库。
选择现成的 API 驱动库
在本书中,我们将探索几个库。例如,谷歌拥有一些世界上最先进的人工智能实验室。在 Google Colab 中只需几行即可安装 Google Trax。你可以选择免费或付费服务。我们可以获取源代码,调整模型,甚至在我们的服务器或谷歌云上训练它们。例如,从现成的 API 到为翻译任务定制转换器模型是一个步骤。
但是,在某些情况下,它可以证明既具有教育意义又有效。我们将在第 6 章“使用 Transformer 进行机器翻译”中探讨 Google 在翻译方面的最新发展并实施 Google Trax 。
我们已经看到,OpenAI 等 API 需要有限的开发人员技能,而 Google Trax 等库则更深入地挖掘代码。这两种方法都表明 AI 4.0 API 将需要在 API 的编辑器方面进行更多开发,但在实现转换器时需要更少的工作量。
除其他算法外,最著名的使用转换器的在线应用程序之一是谷歌翻译。谷歌翻译可以在线使用,也可以通过 API 使用。
让我们尝试使用谷歌翻译在英法翻译中翻译一个需要共指解析的句子: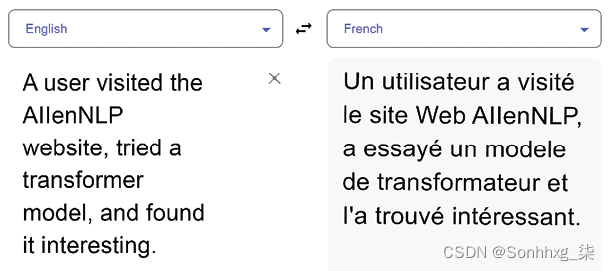
图 1.7:使用谷歌翻译的翻译中的共指解析
谷歌翻译似乎已经解决了共指问题,但法语中的transformateur这个词的意思是电子设备。转换器一词是法语中的新词(新词)。人工智能专家可能需要有语言和特定项目的语言技能。在这种情况下,不需要进行重大开发。但是,该项目可能需要在请求翻译之前澄清输入。
此示例显示您可能必须与语言学家合作或获得语言技能才能处理输入上下文。此外,使用上下文接口增强输入可能需要大量开发工作。
因此,我们仍然可能不得不亲自动手添加脚本以使用 Google 翻译。或者我们可能必须为特定的翻译需求找到一个转换器模型,例如 BERT、T5 或我们将在本书中探讨的其他模型。
随着解决方案范围的增加,选择模型并非易事。
选择Transformer的型号
大科技企业占据主导地位NLP 市场。仅谷歌、Facebook 和微软每天就运行数十亿个 NLP 例程,从而增强了他们的 AI 模型无与伦比的能力。各大巨头现在提供的变压器型号种类繁多,拥有一流的基础型号。
然而,发现广阔 NLP 市场的小公司也加入了这场游戏。Hugging Face 现在也有免费或付费的服务方式。Hugging Face 要达到通过谷歌研究实验室投入的数十亿美元和微软对 OpenAI 的资助所获得的效率水平将是一项挑战。基础模型的切入点是在 GPT-3 或 Google BERT 等超级计算机上经过全面训练的转换器。
Hugging Face 有不同的方法,并提供范围和数量广泛的变压器任务的模型,其中是一个有趣的哲学。Hugging Face 提供灵活的模型。此外,Hugging Face 提供高级 API 和开发者控制的 API。我们将在本书的几个章节中探讨 Hugging Face 作为一种教育工具和特定任务的可能解决方案。
然而,OpenAI 专注于全球少数最强大的变压器引擎,并且可以在人类水平上执行许多 NLP 任务。我们将在第 7 章“使用 GPT-3 引擎的超人变形金刚崛起”中展示 OpenAI 的 GPT-3 引擎的强大功能。
这些对立且经常相互冲突的策略为我们提供了广泛的可能实现方式。因此,我们必须定义工业 4.0 人工智能专家的角色。
工业 4.0 人工智能专家的角色
工业 4.0 将无处不在的万物连接起来。机器通信直接用其他机器。人工智能驱动的物联网信号无需人工干预即可触发自动决策。NLP 算法发送自动报告、摘要、电子邮件、广告等。
人造的情报专家将不得不适应这个日益自动化任务的新时代,包括变压器模型的实施。人工智能专家将拥有新功能。如果我们从上到下列出 AI 专家必须完成的 Transformer NLP 任务,似乎一些高级任务几乎不需要人工智能专家的开发。人工智能专家可以是人工智能大师,提供设计理念、解释和实现。
对于人工智能专家来说,变压器代表什么的务实定义会因生态系统而异。
让我们看几个例子:
- API:OpenAIAPI 不需要 AI 开发人员。网页设计师可以创建表单,语言学家或主题专家 (SME) 可以准备提示输入文本。人工智能专家的主要角色需要语言技能来展示,而不仅仅是告诉 GPT-3 引擎如何完成任务。例如,显示涉及处理输入的上下文。这个新任务被命名为提示工程。一个快速的工程师在人工智能方面有很大的未来!
- 图书馆:Google Trax 库需要有限的开发量才能从现成的模型开始。掌握语言学和 NLP 任务的 AI 专家可以处理数据集和输出。
- 训练和微调:一些拥抱脸功能需要有限的开发量,提供 API 和库。但是,在某些情况下,我们仍然必须弄脏自己的手。在这种情况下,训练、微调模型和找到正确的超参数将需要人工智能专家的专业知识。
- 开发级技能:在某些项目中,标记器和数据集不匹配,如第 9 章,匹配标记器和数据集中所述。在这种情况下,例如,与语言学家合作的人工智能开发人员可以发挥关键作用。因此,计算语言学培训可以在这个级别上派上用场。
最近的NLP AI 的进化可以被称为作为“嵌入式变压器”,它正在扰乱人工智能开发生态系统:
- 例如,GPT-3 转换器目前已嵌入到带有 GitHub Copilot 的多个 Microsoft Azure 应用程序中。正如本章的基础模型部分所介绍的,Codex 是我们将在第 16 章“变压器驱动副驾驶的出现”中研究的另一个示例。
- 嵌入式转换器不能直接访问,但提供自动开发支持,例如自动代码生成。
- 通过辅助文本完成,最终用户可以无缝使用嵌入式转换器。
要直接访问 GPT-3 引擎,您必须首先创建一个 OpenAI 帐户。然后您可以使用 API 或直接在 OpenAI 用户界面中运行示例。
我们将探索这个迷人的新第 16 章中的嵌入式变压器世界。但要充分利用这一章,你应该首先掌握前几章的概念、示例和程序。
工业 4.0 人工智能专家的技能需要灵活性、跨学科知识,尤其是灵活性。本书将为人工智能专家提供各种变压器生态系统,以适应市场的新范式。
在第 2 章深入了解原始 Transformer 的迷人架构之前,是时候总结本章的思想了。
概括
第四次工业革命或工业 4.0 已经迫使人工智能进行深刻的演变。第三次工业革命是数字化的。工业 4.0 建立在数字革命的基础之上,将万物互联,无处不在。自动化流程正在取代包括 NLP 在内的关键领域的人工决策。
RNN 的局限性会减缓快速发展的世界中所需的自动化 NLP 任务的进展。变形金刚填补了这一空白。一家公司需要摘要、翻译和广泛的 NLP 工具来应对工业 4.0 的挑战。
工业 4.0(I4.0)由此催生了人工智能产业化时代。平台、框架、语言和模型概念的演变对工业 4.0 开发人员来说是一个挑战。基础模型通过提供无需进一步训练或微调即可执行广泛任务的同质模型,弥合了第三次工业革命和 I4.0 之间的差距。
例如,AllenNLP 等网站无需安装即可提供教育性 NLP 任务,但它也提供了在定制程序中实现变压器模型的资源。OpenAI 提供了一个 API,只需要几行代码就可以运行一个强大的 GPT-3 引擎。Google Trax 提供了一个端到端的库,Hugging Face 提供了各种转换器模型和实现。我们将在本书中探索这些生态系统。
工业 4.0 是对具有更广泛技能的前 AI 的彻底偏离。例如,项目经理可以通过要求网页设计师通过即时工程为 OpenAI 的 API 创建接口来决定实施转换器。或者,在需要时,项目经理可以要求人工智能专家下载 Google Trax 或 Hugging Face,以开发具有定制变压器模型的成熟项目。
工业 4.0 改变了开发人员的游戏规则,他们的角色将扩大并且需要更多的设计而不是编程。此外,嵌入式转换器将提供辅助代码开发和使用。这些新技能组合是一项挑战,但也开辟了令人兴奋的新视野。
在第 2 章,Transformer 模型的架构入门中,我们将从原始 Transformer 的架构开始。