首先打开淘宝页面,搜索手机:
https://uland.taobao.com/sem/tbsearch?refpid=mm_26632258_3504122_32538762&clk1=04511dd93dde330d86022e9ce3a3dc46&keyword=手机&page=0

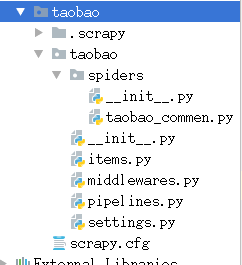
# 新建scrapy项目
scrapy startproject taobao
# 进入项目目录:
cd taobao
# 创建爬虫
scrapy genspider taobao_comment taobao.com
打开终端,运行docker:
sudo service docker start
运行splash容器:
sudo docker run -p 8050:8050 scrapinghub/splash
 在浏览器输入:http://localhost:8050
在浏览器输入:http://localhost:8050
得到下面的页面:
 再来配置爬虫文件:
再来配置爬虫文件:
# settings.py# 添加SPIDER_MIDDLEWARES
SPIDER_MIDDLEWARES = {'scrapy_splash.SplashDeduplicateArgsMiddleware': 100,
}
# DOWNLOADER_MIDDLEWARES 中添加Splash middleware:
DOWNLOADER_MIDDLEWARES = {'scrapy_splash.SplashCookiesMiddleware': 723,'scrapy_splash.SplashMiddleware': 725,'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,'taobao.middlewares.TaobaoDownloaderMiddleware': 543,}
# 将最后几行的注释解开:
HTTPCACHE_ENABLED = True
HTTPCACHE_EXPIRATION_SECS = 0
HTTPCACHE_DIR = 'httpcache'
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
SPLASH_URL = 'http://localhost:8050/' #自己安装的docker里的splash位置
DUPEFILTER_CLASS = "scrapy_splash.SplashAwareDupeFilter" # 添加DUPEFILTER_CLASS去重# 将robots协议改为False:
ROBOTSTXT_OBEY = False
# taobao_comment.pyimport scrapyfrom scrapy_splash import SplashRequestclass TaobaoCommenSpider(scrapy.Spider):name = 'taobao_comment'allowed_domains = ['taobao.com']def start_requests(self):script = """function main(splash, args)splash:set_user_agent("Mozilla/5.0 Chrome/69.0.3497.100 Safari/537.36")splash:go(args.url)splash:wait(5)return {html=splash:html()}end"""url = "https://uland.taobao.com/sem/tbsearch?refpid=mm_26632258_3504122_32538762&clk1=04511dd93dde330d86022e9ce3a3dc46&keyword=%E6%89%8B%E6%9C%BA&page=0"yield SplashRequest(url,self.parse,endpoint="execute",args={'lua_source': script, 'url': url})def parse(self, response):with open('taobao.html', 'w+') as f:f.write(response.text)
执行爬虫:scrapy crawl taobao_comment
发现目录中出现taobao.html,右键单击,在浏览器中运行:


到此一个scrapy-splash的简单网页抓取就完成了。