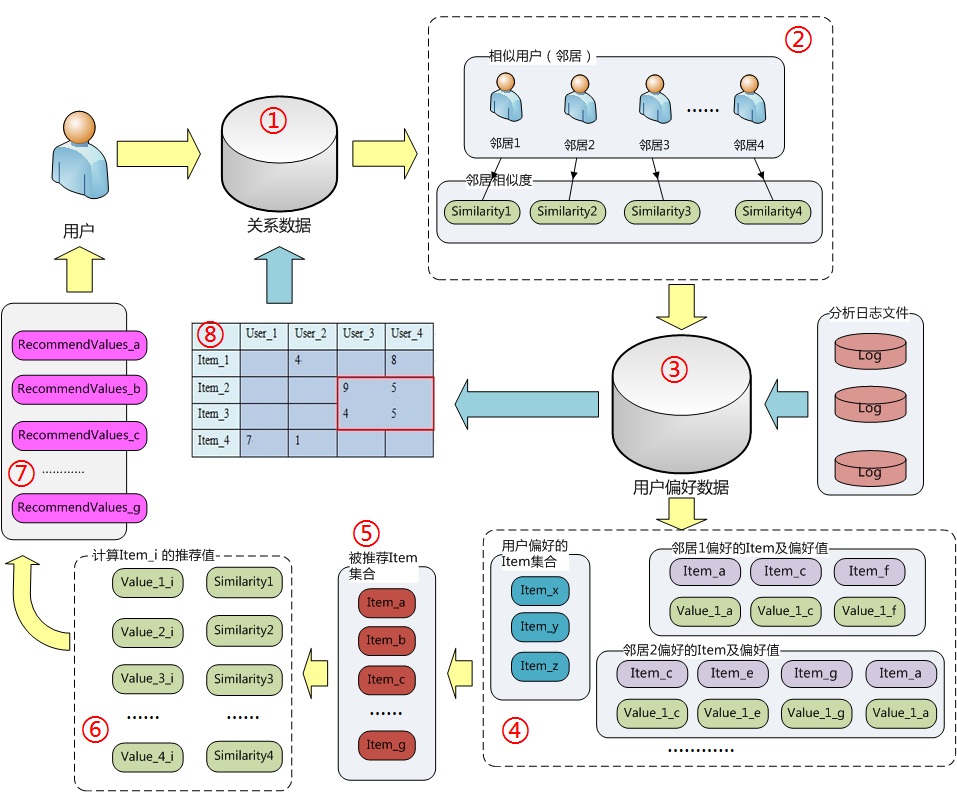
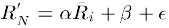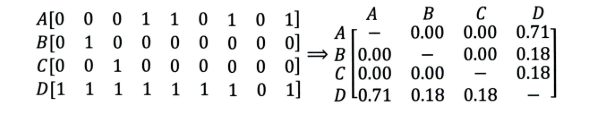协同过滤算法常用于商品推荐或者类似的场合,根据用户之间或商品之间的相似性进行精准推荐
- 协同过滤算法分为:
- 基于用户的协同过滤算法(UserCF算法)(适合社交化应用)
- 基于商品的协同过滤算法(ItemCF算法)(适合电子商务、电影)
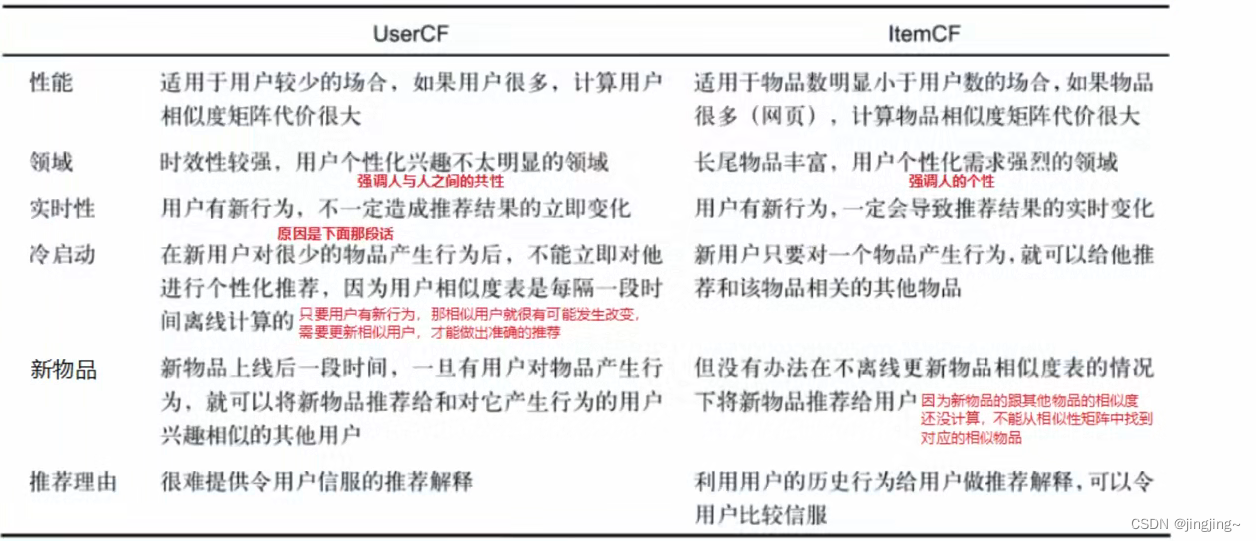
两者不同在于UserCF是通过物品到用户倒排表来计算用户相似矩阵,ItemCF是用过用户到物品倒排表计算机物品相似度,在计算相似度的时候,都没有考虑到评分,只是在最终的推荐时使用预测用户已看过的电影评分。
一篇写的比较好的文章
- 相似度矩阵的计算
① 泊松相关系数
② 余弦相似度
③ 调整余弦相关度
④ Jaccard系数
UserCF:
- 计算用户之间的相似度
看过同一场电影的用户之间关系+1
D, N = {}, {}
# 物品到用户倒排表
for user, items in user_movie.items():N[user] = len(items)for i in items.keys():D.setdefault(i, [])D[i].append(user)
C = {}
# 用户到用户矩阵
for item, user in D.items():for i in user:C.setdefault(i, {})for j in user:if i== j :continueC[i].setdefault(j, 0)C[i][j] += 1W = {}
# 计算用户相似度
for i, related_users in C.items():W.setdefault(i, {})for j, cij in related_users.items():W[i][j] = cij / math.sqrt((N[i]* N[j]))- 预测
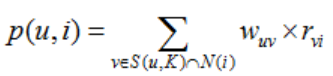
S(u,K)是和用户u兴趣最接近的K个用户的集合;N(i)是喜欢物品i的用户集合;Wuv是用户u和v的相似度;rvi是隐反馈信息,代表用户v对物品i的感兴趣程度,为该电影的打分
rank = {} # 排名# W 用户相似矩阵, N: 喜欢物品的用户集合,for u, wu in sorted(W[user].items(), key=lambda x: x[1], reverse=True)[0:K]:for movie, users in movie_user.items():# 选择K个最高相似度用户# 选出 前K个喜欢,user没有选择的filmif u in users and user not in users:rank.setdefault(movie, 0)score = movie_user[movie][u]rank[movie] += score * wureturn dict(sorted(rank.items(), key=lambda x:x[1], reverse=True)[0:N])
ItemCF:
- 计算电影之间的相似度
(原理是:用户看过的电影之间有联系,比如一个人看过film1和film2,则film1与film2之间的关系值为1,若又有一个用户也看过film1和film2,则film1和film2关系值+1,以此类推。这样做是根据用户的兴趣偏好来确定电影的关系):
C = {}N = {}for user, items in user_movie.items():# items : {'film6': 4, 'film11': 2, 'film8': 2, 'film14': 2},for i in items.keys():# i :‘film6...N.setdefault(i , 0)N[i] += 1 # 电影打分人数C.setdefault(i, {})for j in items.keys():if i == j : continueC[i].setdefault(j, 0)C[i][j] += 1 # 电影相似度
- 使用余弦相似度计算物品相似度矩阵W
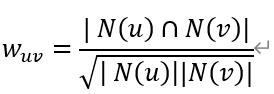
W1 = {}for i, related_items in C.items():W.setdefault(i, {})for j, cij in related_items.items():W[i][j] = cij / (math.sqrt(N[i] * N[j]))
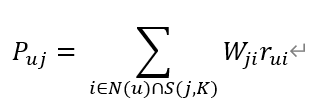
- 预测
rank = {}action_item = user_movie[user]for item, score in action_item.items():for j, Wj in sorted(W[item].items(), key=lambda x: x[1], reverse=True)[0:K]:取前K个相似用户,减少计算量if j in action_item.keys(): # 用户已看过该电影continuerank.setdefault(j, 0)rank[j] += score * Wj # 用户没看过,用看过的电影*物品相似度return dict(sorted(rank.items(), key=lambda x: x[1], reverse=True)[0:N])
- 下面直接在用户-物品上计算相似度。
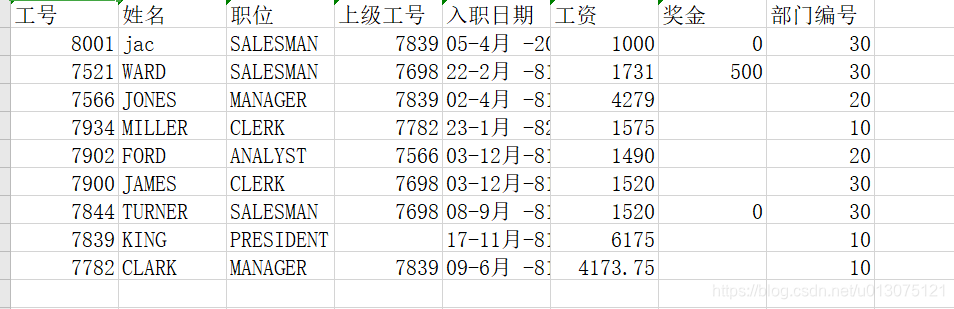
虚拟数据:
10个用户,对14部电影的评分

ex:计算相似度的三种方法:
-
① Jaccard相似度(缺点是没有考虑评分系统):N(u)是用户u的看过的电影集合
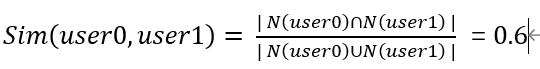
-
② 余弦相似度 (缺点是认为缺失值为0)
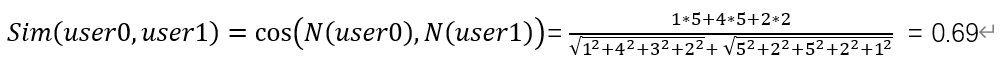
-
③ 皮尔逊相关系数(要求矩阵有序)

-
在预测时使用加权的方法
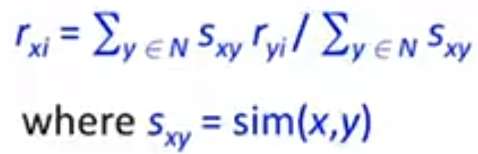
ex:对user0 ->film2的预测:
取N个最相近的用户
p = N1与user0相似度xN1对film2的评分+N2与user0相似度xN2对film2的评分 / N1的相似度+N2的相似度
利用上述表格利用不同方法进行对user0做推荐
UserCF,用user-item倒排表余弦相似度计算相似度

ItemCF,使用user-item倒排表使用余弦相似度

UserCF:直接在表格用余弦计算相似度

UserCF直接在表格用皮尔逊相关系数计算相似度

使用MovieLens作为实验数据
UserCF,用item-user计算相似度
可以看出geners大多数相同,效果应该应该还不错

ItemCF,使用user-item倒排表使用余弦相似度
耗时较长,应该是item远远大于user, item相似度矩阵非常大

UserCF直接在表格用皮尔逊相关系数计算相似度

UserCF
# -*- coding: utf-8 -*-
# author: cmzz
# datetime:2020/6/11 22:12
import math
from itertools import islice
import timedef readData():file_user_movie = './ml-latest-small/ratings.csv'file_movie_info = './ml-latest-small/movies.csv'user_movie = {}for line in islice(open(file_user_movie, encoding='utf-8'), 1, None):user, item, score = line.split(',')[0:3]user_movie.setdefault(user, {})user_movie[user][item] = float(score)movies = {}for line in islice(open(file_movie_info, encoding='utf-8'), 1, None):(movieId, movieTitle, genres) = line.split(',')[0:3]movies[movieId] = movieTitle+' '+'genres:{}'.format(genres)return user_movie, movies
def simmialr(user_movie):D, N = {}, {}# 物品到用户倒排表for user, items in user_movie.items():N[user] = len(items)for film, score in items.items():D.setdefault(film, {})D[film][user] = scoreC = {}# 用户到用户矩阵for item, user in D.items():for i in user:C.setdefault(i, {})for j in user:if i== j :continueC[i].setdefault(j, 0)C[i][j] += 1W = {}# 计算用户相似度for i, related_users in C.items():W.setdefault(i, {})for j, cij in related_users.items():W[i][j] = cij / math.sqrt((N[i]* N[j]))return W, Ddef recommend2(user, movie_user, W, K, N):rank = {} # 排名# W 用户相似矩阵, N: 喜欢物品的用户集合,for u, wu in sorted(W[user].items(), key=lambda x: x[1], reverse=True)[0:K]:for movie, users in movie_user.items():# 选择K个最高相似度用户# 选出 前K个喜欢,user没有选择的filmif u in users and user not in users:rank.setdefault(movie, 0)score = movie_user[movie][u]rank[movie] += score * wureturn dict(sorted(rank.items(), key=lambda x:x[1], reverse=True)[0:N])if __name__ == '__main__':user_movie, movies = readData()pre = time.time()UW, movie_user = simmialr(user_movie) # userCFresult = recommend2('1', movie_user, UW, 10, 10)# userCFprint('耗时{}s'.format(time.time()- pre))for film, rating in result.items():print(movies[film])print(rating)print('\n')UserCF,表格使用余弦计算相似度
def simmialr(user_moives):# 余弦计算相关度W={}for user1, items1 in user_moives.items():W.setdefault(user1, {})for user2, items2 in user_moives.items():if user1 == user2: continueW[user1].setdefault(user2, 0)items = items1.keys() & items2.keys() # 取交集if items:for item in items:# 余弦计算公式W[user1][user2] += \(user_moives[user1][item]*user_moives[user2][item]) / \(math.sqrt(sum([x**2 for x in items1.values()])) * math.sqrt(sum([y**2 for y in items2.values()])))return Wdef recommend(uuser, user_movie, W, K, N):rank,sumN = {}, {}action_item = user_movie[uuser].keys()for user, Wj in sorted(W[uuser].items(), key=lambda x: x[1], reverse=True)[0:K]:for item, score in user_movie[user].items():if item in action_item: continuerank.setdefault(item, 0)if item in user_movie[user].keys():sumN.setdefault(item, 0)sumN[item] += Wjrank[item] += score * Wjfor item1, score1 in rank.items():for item2, score2 in sumN.items():if item1 == item2:# 除以该item的相似度总和rank[item1] = score1 / score2return dict(sorted(rank.items(), key=lambda x: x[1], reverse=True)[0:N])ItemCF
# -*- coding: utf-8 -*-
# datetime:2020/6/9 11:48
import math
from itertools import islice
import timedef readData():file_user_movie = './ml-latest-small/ratings.csv'file_movie_info = './ml-latest-small/movies.csv'user_movie = {}for line in islice(open(file_user_movie, encoding='utf-8'), 1, None):user, item, score = line.split(',')[0:3]user_movie.setdefault(user, {})user_movie[user][item] = float(score)movies = {}for line in islice(open(file_movie_info, encoding='utf-8'), 1, None):(movieId, movieTitle, genres) = line.split(',')[0:3]movies[movieId] = movieTitle+' '+'genres:{}'.format(genres)return user_movie, movies
# ItemCF
# 使用余弦计算相似度
def cosineItemSimilarity(user_movie):C = {}N = {}for user, items in user_movie.items():for i in items.keys():# i : 电影idN.setdefault(i , 0)N[i] += 1 # 用户对应物品集合C.setdefault(i, {})for j in items.keys():if i == j : continueC[i].setdefault(j, 0)C[i][j] += 1 # 物品对应用户的集合# print(C)W = {}for i, related_items in C.items():W.setdefault(i, {})for j, cij in related_items.items():W[i][j] = cij / (math.sqrt(N[i] * N[j]))return Wdef recommend(user, user_movie, W, K, N):rank = {}action_item = user_movie[user]for item, score in action_item.items():for j, Wj in sorted(W[item].items(), key=lambda x: x[1], reverse=True)[0:K]:if j in action_item.keys(): continuerank.setdefault(j, 0)rank[j] += score * Wjreturn dict(sorted(rank.items(), key=lambda x: x[1], reverse=True)[0:N])# userCF
def simmialr(user_movie):D, N = {}, {}# 物品到用户倒排表for user, items in user_movie.items():N[user] = len(items)for film, score in items.items():D.setdefault(film, {})D[film][user] = scoreC = {}# 用户到用户矩阵for item, user in D.items():for i in user:C.setdefault(i, {})for j in user:if i== j :continueC[i].setdefault(j, 0)C[i][j] += 1W = {}# 计算用户相似度for i, related_users in C.items():W.setdefault(i, {})for j, cij in related_users.items():W[i][j] = cij / math.sqrt((N[i]* N[j]))return W, Ddef recommend2(user, movie_user, W, K, N):rank = {} # 排名# W 用户相似矩阵, N: 喜欢物品的用户集合,for u, wu in sorted(W[user].items(), key=lambda x: x[1], reverse=True)[0:K]:for movie, users in movie_user.items():# 选择K个最高相似度用户# 选出 前K个喜欢,user没有选择的filmif u in users and user not in users:rank.setdefault(movie, 0)score = movie_user[movie][u]rank[movie] += score * wureturn dict(sorted(rank.items(), key=lambda x:x[1], reverse=True)[0:N])if __name__ == '__main__':user_movie, movies = readData()pre = time.time()W = cosineItemSimilarity(user_movie)result = recommend('1', user_movie, W, 10, 10)print('耗时{}s'.format(time.time()- pre))for film, rating in result.items():print(movies[film])print(rating)print('\n')UserCF直接在表格用皮尔逊相关系数计算相似度(代码)
def simmialr(user_movie):#W = {}# 物品到用户倒排表for user1, items1 in user_movie.items():W.setdefault(user1, {})for user2, items2 in user_movie.items():if user1 == user2 : continueW[user1].setdefault(user2, 0)ave1 = sum(items1.values()) / len(items1)ave2 = sum(items2.values()) / len(items2)U = items1.keys() | items2.keys()u1, u2 = [], []for i in U:# print(i)if i in items1.keys():u1.append(items1[i])else:u1.append(ave1)if i in items2.keys():u2.append(items2[i])else:u2.append(ave2)W[user1][user2] = corrcoef(u1, u2)return Wdef multipl(a, b):sumofab = 0.0for i in range(len(a)):temp = a[i] * b[i]sumofab += tempreturn sumofabdef corrcoef(x, y):n = len(x)# 求和sum1 = sum(x)sum2 = sum(y)# 求乘积之和sumofxy = multipl(x, y)# 求平方和sumofx2 = sum([pow(i, 2) for i in x])sumofy2 = sum([pow(j, 2) for j in y])num = sumofxy - (float(sum1) * float(sum2) / n)# 计算皮尔逊相关系数den = math.sqrt((sumofx2 - float(sum1 ** 2) / n) * (sumofy2 - float(sum2 ** 2) / n))if den:return num / denelse:return num / 1def recommend(uuser, user_movie, W, K, N):rank,sumN = {}, {}action_item = user_movie[uuser].keys()for user, Wj in sorted(W[uuser].items(), key=lambda x: x[1], reverse=True)[0:K]:for item, score in user_movie[user].items():if item in action_item: continuerank.setdefault(item, 0)rank[item] += score * Wjreturn dict(sorted(rank.items(), key=lambda x: x[1], reverse=True)[0:N])