语音识别技术
让机器通过识别和理解过程把语音信号转变为相应的文本或命令的技术。
语音识别本质上是一种模式识别的过程,未知语音的模式与已知语音的参考模式逐一进行比较,最佳匹配的参考模式被作为识别结果。
语音识别的目的就是让机器赋予人的听觉特性,听懂人说什么,并作出相应的动作。目前大多数语音识别技术是基于统计模式的,从语音产生机理来看,语音识别可以分为语音层和语言层两部分。
语音识别技术的主流算法,主要有基于动态时间规整(DTW)算法、基于非参数模型的矢量量化(VQ)方法、基于参数模型的隐马尔可夫模型(HMM)的方法、基于人工神经网络(ANN)和支持向量机等语音识别方法。
语音识别分类:
根据对说话人的依赖程度,分为:
(1)特定人语音识别(SD):只能辨认特定使用者的语音,训练→使用。
(2)非特定人语音识别(SI):可辨认任何人的语音,无须训练。
根据对说话方式的要求,分为:
(1)孤立词识别:每次只能识别单个词汇。
(2)连续语音识别:用者以正常语速说话,即可识别其中的语句。
语音识别系统的模型通常由声学模型和语言模型两部分组成,
分别对应于语音到音节概率的计算和音节到字概率的计算。

基于语音识别芯片的嵌入式产品也越来越多
硬件方面
Sensory公司的RSC系列语音识别芯片
Infineon公司的Unispeech
Unilite语音芯片等,
这些芯片在嵌入式硬件开发中得到了广泛的应用。
软件方面
目前比较成功的语音识别软件有:Nuance、IBM的Viavoice和Microsoft的SAPI以及开源软件HTK。
这些软件都是面向非特定人、大词汇量的连续语音识别系统。
SPHINX
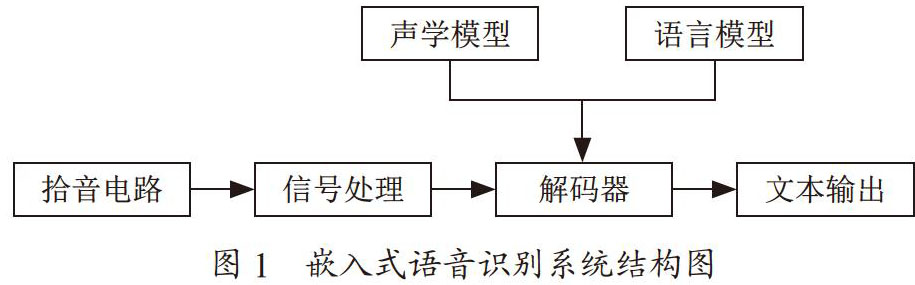
由美国卡内基梅隆大学开发的大词汇量、非特定人、连续英语语音识别系统。一个连续语音识别系统大致可分为四个部分:
特征提取
声学模型训练
语言模型训练
解码器
语音识别系统
一,预处理模块
1 过滤掉不重要的信息以及噪声
2进行端点检测
3进行语音分帧以及预加重
对输入的原始语音信号进行处理,滤除掉其中的不重要的信息以及背景噪声,并进行语音信号的端点检测(找出语音信号的始末)、语音分帧(近似认为在10-30ms内是语音信号是短时平稳的,将语音信号分割为一段一段进行分析)以及预加重(提升高频部分)等处理
二,特征提取:
去除语音信号中对于语音识别无用的冗余信息,保留能够反映语音本质特征的信息,并用一定的形式表示出来。也就是提取出反映语音信号特征的关键特征参数形成特征矢量序列,以便用于后续处理。
目前的较常用的提取特征的方法还是比较多的,不过这些提取方法都是由频谱衍生出来的。
Mel 频率倒谱系数( MFCC) 参数因其良好的 抗噪性和鲁棒性 而应用广泛。
在 sphinx 中也是用 MFCC 特征的。 MFCC 的计算首先用 FFT 将时域信号转化成频域,之后对其对数能量谱用依照 Mel 刻度分布的三角滤波器组进行卷积,最后对各个滤波器的输出构成的向量进行离散余弦变换 DCT ,取前 N 个系数。
FFT (离散傅氏变换的快速算法)
FFT(Fast Fourier Transformation)是离散傅氏变换(DFT)的快速算法。即为快速傅氏变换。它是根据离散傅氏变换的奇、偶、虚、实等特性,对离散傅立叶变换的算法进行改进获得的。
梅尔刻度(melscale)
它是基于彼此等距的听众对音高(pitch)的感性判断的刻度。
这个刻度和正常的频率之间的参考点定义是将1000mel的音高指定为100Hz的音调(tone),高于听众阈值的40db以上。在在500HZz以上,由听众来对越来越大的间隔进行判断以产生等间距的音高增量。这样的结果是,500Hz以上的赫兹刻度被划分为四个octaves,以包含梅尔刻度上的两个octaves。Mel的名字来源于单词melody,表示这个刻度是基于pitchcomparisons的
离散余弦变换(DCT for Discrete Cosine Transform)是与傅里叶变换相关的一种变换,它类似于离散傅里叶变换(DFT for Discrete Fourier Transform),但是只使用实数。离散余弦变换相当于一个长度大概是它两倍的离散傅里叶变换。离散傅里叶变换需要进行复数运算,尽管有FFT可以提高运算速度,但在图像编码、特别是在实时处理中非常不便。离散傅里叶变换在实际的图像通信系统中很少使用,但它具有理论的指导意义。根据离散傅里叶变换的性质,实偶函数的傅里叶变换只含实的余弦项,因此构造了一种实数域的变换——离散余弦变换(DCT)。
通过研究发现,DCT除了具有一般的正交变换性质外,其变换阵的基向量很近似于Toeplitz矩阵的特征向量,后者体现了人类的语言、图像信号的相关特性。因此,在对语音、图像信号变换的确定的变换矩阵正交变换中,DCT变换被认为是一种准最佳变换。在近年颁布的一系列视频压缩编码的国际标准建议中,都把 DCT 作为其中的一个基本处理模块。
DCT除了上述介绍的几条特点,即:实数变换、确定的变换矩阵、准最佳变换性能外,二维DCT还是一种可分离的变换,可以用两次一维变换得到二维变换结果。
有两个相关的变换,一个是离散正弦变换(DST for Discrete Sine Transform),它相当于一个长度大概是它两倍的实奇函数的离散傅里叶变换;另一个是改进的离散余弦变换(MDCT for Modified Discrete Cosine Transform),它相当于对交叠的数据进行离散余弦变换。
sphinx 中 MFCC 提取的过程:
1 用快速傅里叶变化将时域信号转化为频域信号
2 将其对数能量谱依照梅尔刻度的三角滤波器组进行卷积
3 对各个滤波器的输出构成的向量进行离线余弦变换,取前n个系数
在 sphinx 中,用帧( frames) 去分割语音波形,每帧大概 10ms ,然后每帧提取可以代表该帧语音的 39 个数字,这 39 个数字也就是该帧语音的 MFCC 特征,用特征向量来表示。
三 声学模型训练
根据训练语音库的特征参数训练出声学模型参数。在识别时可以将待识别的语音的特征参数同声学模型进行匹配,得到识别结果。
目前的主流语音识别系统多采用隐马尔可夫模型HMM进行声学模型建模。
声学模型的建模单元,可以是音素,音节,词等各个层次。
对于小词汇量的语音识别系统,可以直接采用音节进行建模。
对于词 汇量偏大的识别系统 , 一般选取音素,即声母,韵母进行建模 。识别规模越大,识别单元选取的越小。 (关于 HMM ,网上有很多经典的解说,例如《 HMM 学习最佳范例》和《隐马尔科夫模型 (hmm) 简介》等,不了解的可以去看看)
HMM是对语音信号的时间序列结构建立统计模型,将其看作一个数学上的双重随机过程:一个是用具有有限状态数的Markov链来模拟语音信号统计特性变化的隐含(马尔可夫模型的内部状态外界不可见)的随机过程,另一个是与Markov链的每一个状态相关联的外界可见的观测序列(通常就是从各个帧计算而得的声学特征)的随机过程。
人的言语过程实际上就是一个双重随机过程,语音信号本身是一个可观测的时变序列,是由大脑根据语法知识和言语需要(不可观测的状态)发出的音素的参数流(发出的声音)。 HMM 合理地模仿了这一过程,是较为理想的一种语音模型。用 HMM刻画语音信号需作出两个假设 ,一 是内部状态的转移只与上一状态有关 ,另一是 输出值只与当前状态(或当前的状态转移)有关,这两个假设大大降低了模型的复杂度。
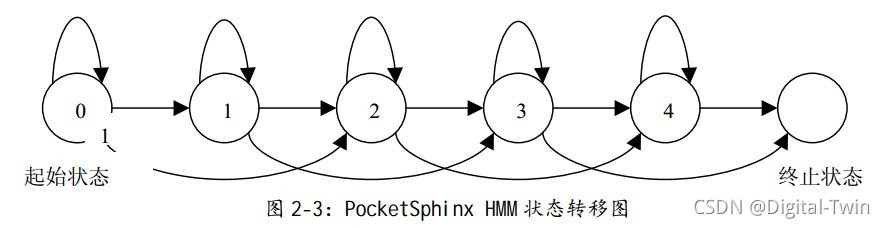
语音识别中使用 HMM 通常是用 从左向右单向、带自环、带跨越的拓扑结构来对识别基元建模 ,
一个音素就是一个三至五状态的 HMM,一个词就是构成词的多个音素的HMM串行起来构成的HMM,而连续语音识别的整个模型就是词和静音组合起来的HMM。
四 语音模型
语言模型 是用来计算 一个句子出现概率的概率模型 。 它主要用于决定哪个词序列的可能性更大,或者在出现了几个词的情况下预测下一个即将出现的词语的内容 。换一个说法说, 语言模型是用来约束单词搜索的。它定义了哪些词能跟在上一个已经识别的词的后面(匹配是一个顺序的处理过程),这样就可以为匹配过程排除一些不可能的单词。
语言建模能够有效的结合汉语语法和语义的知识,描述词之间的内在关系,从而提高识别率,减少搜索范围。
语言模型分为三个层次:字典知识,语法知识,句法知识。
对训练文本数据库进行语法、语义分析,经过基于统计模型训练得到语言模型。语言建模方法主要有基于规则模型和基于统计模型两种方法。统计语言模型是用概率统计的方法来揭示语言单位内在的统计规律,其中N-Gram模型简单有效,被广泛使用。它包含了单词序列的统计。
N-Gram模型基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
Sphinx 中是采用二元语法和三元语法的统计语言概率模型,也就是通过前一个或两个单词来判定当前单词出现的概率 P(w2| w1) , P(w3| w2, w1) 。
五 语音解码和搜索算法:
解码器: 即指语音技术中的识别过程。针对输入的语音信号,根据己经训练好的 HMM 声学模型、语言模型及字典建立一个识别网络, 根据搜索算法在该网络中寻找最佳的一条路径 ,这个路径就是能够 以最大概率输出该语音信号的词串 ,这样就确定这个语音样本所包含的文字了。所以 解码操作即指搜索算法 :是指在解码端通过搜索技术 寻找最优词串 的方法。
连续语音识别中的搜索,就是 寻找一个词模型序列以描述输入语音信号 ,从而得到词解码序列。搜索所依据的是 对公式中的声学模型打分和语言模型打分。在实际使用中,往往要依据经验给语言模型加上一个 高权重 ,并设置一个长词惩罚分数。当今的主流解码技术都是基于 Viterbi搜索算法的,Sphinx也是。
基于动态规划的Viterbi算法在每个时间点上的各个状态,计算解码状态序列对观察序列的后验概率,保留概率最大的路径,并在每个节点记录下相应的状态信息以便最后反向获取词解码序列。Viterbi算法本质上是一种动态规划算法,该算法遍历HMM状态网络并保留每一帧语音在某个状态的最优路径得分。
连续语音识别系统的识别结果是一个词序列。解码实际上是对词表的所有词反复搜索。词表中词的排列方式会影响搜索的速度,而词的排列方式就是字典的表示形式。Sphinx系统中采用音素作为声学训练单元,通常字典就用来记录每个单词由哪些个音素组成,也可以理解为对每个词的发音进行标注。
N-best 搜索和多遍搜索: 为在搜索中利用各种知识源,通常要进行多遍搜索,第一遍使用代价低的知识源(如声学模型、语言模型和音标词典),产生一个候选列表或词候选网格,在此基础上进行使用代价高的知识源(如 4 阶或 5 阶的 N-Gram 、 4 阶或更高的上下文相关模型)的第二遍搜索得到最佳路径。
对于语音识别过程个人的理解:
例如我对电脑说:“帮我打开“我的电脑”!”然后电脑得理解我说了什么,然后再执行打开“我的电脑”的操作,那怎么实现呢?
这个得预先有一个工作,就是电脑得先学会“帮我打开“我的电脑”!”这句语音(实际上是一个波形)所代表的文字就是“帮我打开“我的电脑”!”这句词串。那么如何让它学会呢?
如果以音节(对汉语来说就是一个字的发音)为语音基元的话,那么电脑就是一个字一个字地学习,例如“帮”字、“我”字等等,那么“帮”字怎么学习呢?也就是说电脑接收到一个“帮”字的语音波形,怎么分析理解才知道它代表的是“帮”字呢?首先我们需要建立一个数学模型来表示这个语音。因为语音是连续的不平稳的信号,但是在短的时间内可以认为是平稳的,所以我们需要分割语音信号为一帧一帧,假如大概25ms一帧,然后为了让每一帧平稳过渡,我们就让每帧见存在重叠,假如重叠10ms。这样每帧的语言信号就是平稳的了,再从每帧语音信号中提取反映语音本质特征的信息(去除语音信号中对于语音识别无用的冗余信息,同时达到降维)。那么采用什么特征最能表达每一帧的语音呢?MFCC是用的比较多的一种,这里不介绍了。然后我们就提取每一帧语音的MFCC特征,得到了是一系列的系数,大概四五十个这样,sphinx中是39个数字,组成了特征向量。好,那么我们就通过39个数字来描述每一帧的语音了,那不同的语音帧就会有不同的39个数字的组合,那我们用什么数学模型去描述这39个数字的分布情况呢?这里我们可以用一个混合高斯模型来表示着39个数字的分布,而混合高斯模型就存在着两个参数:均值和方差;那么实际上每一帧的语音就对应着这么一组均值和方差的参数了。
好了,这样“帮”字的语音波形中的一帧就对应了一组均值和方差(HMM模型中的观察序列),那么我们只需要确定“帮”字(HMM模型中的隐含序列)也对应于这一组均值和方差就可以了。那么后者是怎么对应的呢?这就是训练的作用了!我们知道描述一个HMM模型需要三个参数:初始状态概率分布π、隐含状态序列的转移矩阵A(就是某个状态转移到另一个状态的概率观察序列中的这个均值或者方差的概率)和某个隐含状态下输出观察值的概率分布B(也就是某个隐含状态下对应于);而声学模型可以用HMM模型来建模,也就是对于每一个建模的语音单元,我们需要找到一组HMM模型参数(π,A,B)就可以代表这个语音单元了。那么这三个参数怎么确定呢?训练!我们给出一个语音的数据库,指明说这个语音代表这个词,然后让电脑去学习,也就是对数据库进行统计,得到(π,A,B)这三个参数。
好了,一个字(建模单元)的声学模型建立了。那汉语是不是有很多个字啊,那我们就得对每一个建立声学模型了。假设就有几千个模型,然后每个模型就有了三个或者5个HMM状态,那么如果你说的句子有10个字,那我们就得搜索这所有可能的模型去匹配你的语音,那是多么大的搜索空间了,这非常耗时。那我们就需要采用一个比较优的搜索算法了(这里是Viterbi-Beam算法),它每搜索到一个状态点,就保留概率最大的,然后舍弃之前的状态点,这样就裁剪了很多的搜索路径,但因为忽略了之前的路径,所以它就只能得到一个局部的最优解。
那假如出现以下情况呢?例如,It’s a nice day,从语音上可能会被识别为:It sun niced A,或者是It son ice day。从声学模型来看它是无法区别这些结果,因为其不同之处只是在于每个单词的边界划分位置不同造成的。这时候语言模型就该闪亮登场了,从语义上判断那个结果出现的概率最大,即为搜索结果。语言模型N-Gram基于这样一种假设,第n个词的出现只与前面N-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现概率的乘积。这些概率可以通过直接从语料中统计N个词同时出现的次数得到。这样就可以约束搜索,增加识别的准确率了。
(整理自百度百科)
音节:
音节是听觉能感受到的最自然的语音单位,有一个或几个音素按一定规律组合而成。
汉语音节:
汉语中一个汉字就是一个音节,每个音节由声母、韵母和声调三个部分组成;汉语普通话中的无调音节(不做音调区分)共有400个音节。拼音是拼读音节的过程,就是按照普通话音节的构成规律,把声母、韵母、声调急速连续拼合并加上声调而成为一个音节。如:q-i-áng→qiáng(强)。
英语音节:
音节是读音的基本单位,任何单词的读音,都是分解为一个个音节朗读。英语中一个元音音素可构成一个音节,一个元音音素和一个或几个辅音音素结合也可以构成一个音节。英语的词有一个音节的,两个音节的,多个音节的。一个音节叫单音节词,两个音节叫双音节词,三个音节以上叫多音节。如:take拿,ta'ble 桌子,po‘ta'to马铃薯,po’pu‘la'tion人口,con’gra‘tu’la'tion祝贺。te‘le’com‘mu‘ni’ca'tion电讯。
元音音素是构成音节的主体,辅音是音节的分界线。每个元音音素都可以构成一个音节,如:bed床,bet 打赌。两个元音音素都可以构成一个音节,如:seat坐位,beat 毒打,beast极好的。两元音音素之间有一个辅音音素时,辅音音素归后一音节,如:stu'dent学生,la'bour 劳动。有两个辅音音素时,一个辅音音素归前一音节,一个归后一音节,如: win'ter冬天 fa'ther 父亲,tea'cher教师。
音素:
音素是根据语音的自然属性划分出来的最小语音单位。从声学性质来看,音素是从音质角度划分出来的最小语音单位。从生理性质来看,一个发音动作形成一个音素。如〔ma〕包含〔m〕〔a〕两个发音动作,是两个音素。相同发音动作发出的音就是同一音素,不同发音动作发出的音就是不同音素。如〔ma-mi〕中,两个〔m〕发音动作相同,是相同音素,〔a〕〔i〕发音动作不同,是不同音素。
汉语音素:
音节只是最自然的语音单位,而音素是最小的语音单位音素。汉语包括10个元音,22个辅音,总共有32个。一个音节,至少有一个音素,至多有四个音素。如“普通话”,由三个音节组成(每个字一个音节),可以分析成“p,u,t,o,ng,h,u,a”八个音素。
英语音素:
记录英语音素的符号叫做音标。英语国际音标共有48个音素,其中元音音素20个,辅音音素28个。英语辅音和元音在语言中的作用,就相当于汉语中的声母和韵母。
语料:
通常,在统计自然语言处理中实际上不可能观测到大规模的语言实例。所以,人们简单地用文本作为替代,并把文本中的上下文关系作为现实世界中语言的上下文关系的替代品。我们把一个文本集合称为语料库(Corpus),当有几个这样的文本集合的时候,我们称之为语料库集合(Corpora)。语料库通常指为语言研究收集的、用电子形式保存的语言材料,由自然出现的书面语或口语的样本汇集而成,用来代表特定的语言或语言变体。
语料库就是把平常我们说话的时候的句子、一些文学作品的语句段落、报刊杂志上出现过的语句段落等等在现实生活中真实出现过的语言材料整理在一起,形成一个语料库,以便做科学研究的时候能够从中取材或者得到数据佐证。
例如我如果想写一篇关于“给力”这个词的普及性的文章,就可以到语料库中查询这个词出现的频率、用法等等。
语音识别发展历史(语音识别技术的研究进展与展望)
机器能够听懂人类的语言的三种 关键技术:
1 自动语音识别 automatic speech recognition
2 自然语言处理 natural language processing
3 语音合成 speech synthesis