前面的博客里说过最近几个月我从传统语音(语音通信)切到了智能语音(语音识别)。刚开始是学语音识别领域的基础知识,学了后把自己学到的写了PPT给组内同学做了presentation(语音识别传统方法(GMM+HMM+NGRAM)概述)。一段时间后老板就布置了具体任务:在我们公司自己的ARM芯片上基于kaldi搭建一个在线语音识别系统,三个人花三个月左右的时间完成。由于我们都是语音识别领域的小白,要求可以低些,就用传统的GMM-HMM来实现。说实话接到这个任务我们心里是有点没底的,不知道能不能按时完成,毕竟我们对语音识别不熟,对kaldi不熟。既然任务下达了,硬着头皮也要上,并尽最大努力完成。我本能的先在网上用百度/google搜了搜,看有没有一些经验可供参考,好让我们少走弯路。遗憾的是没搜到有价值的东西。没办法,我们只能根据自己以前的经验摸索着前进。最终我们按计划花了不到三个月的时间完成了嵌入式平台上在线语音识别系统的搭建。虽然只是demo,但是为后面真正做商用的产品打下了良好的基础,累积了不少的经验。今天我就把我们怎么做的分享出来,给也想做类似产品的朋友做个参考。
既然作为一个项目来做,就要有计划,分几个阶段完成这个项目。我在学习语音识别基础知识时对kaldi有一个简单的了解(在做语音识别前就已知kaldi的大名,没办法这几年人工智能(AI)太热了。智能语音作为人工智能的主要落地点之一,好多都是基于kaldi来实现的。我是做语音的,自然会关注这个热门领域的动态)。根据对kaldi的简单了解,我把项目分成了三个阶段,第一阶段是学习kaldi,对kaldi有一个更深的认识,同时搞清楚基于kaldi做方案后面有哪些事情要做,计划花一个月左右的时间完成。第二阶段是设计软件架构、写代码、训练模型等,也是花一个月左右的时间完成。第三阶段是调试,提升识别率,还是花一个月左右的时间完成。计划的时间会根据实际情况做微调。
1,第一阶段
第一阶段就是学习kaldi。由于我们是三个人做这个项目,我就把学习任务分成三块:数据准备和MFCC、GMM-HMM模型训练、解码网络创建和解码。在其他两位同学挑好模块后剩下的解码网络创建和解码就有我来学习了。学习过程就是看网上文章、看博客和看kaldi代码、脚本的过程。学完后大家搞清楚了后面有哪些事情要做,同时做了PPT给组内同学讲,让大家共同提高。解码相关的见我前面的文章(基于WFST的语音识别解码器 )。Kaldi中解码有两种类型:offline(多用于模型调试等)和online(多用于在线识别等),其中online也有两种方式,一种是通过PortAudio从MIC采集语音数据做在线语音识别,另一种是通过读音频WAV文件的方式做在线语音识别。我们要做的是在线语音识别,这两个就是很好的参考,尤其是通过PortAudio从MIC采集方式的,很有必要弄明白运行机制。于是我根据网上的博客基于thchs30搭建了PC上的在线识别来调试,基本上搞清楚了代码的运行机制。Kaldi中设定采样率为16kHZ,每帧25ms(其中帧移10ms),每27帧为一组集中做MFCC特征提取和解码,这样处理一组的语音时长是285ms(25+(27-1)*10=285),共4560(16*285=4560)个采样点。每次处理完一组后就从buffer中再取出一组做MFCC和解码,解码后看有没有识别的字出来,有的话就打印出来。
2,第二阶段
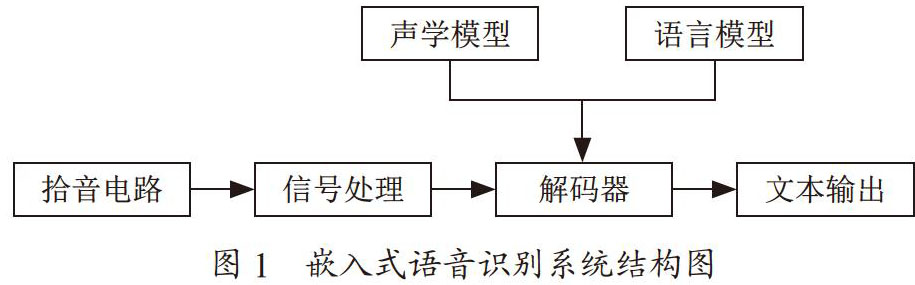
第一阶段主要是学习,第二阶段就要真正干活了。我们在Linux上开发,先制定系统搭建完成后的目标:设备用数据线连在PC上,能在线实时识别英文数字0—9(选识别这些是因为网上有现成的英国人说的音频源,我们可以省去录音频源的工作,好节约时间),即人对着设备说出英文数字0—9后PC屏幕上能实时打印出来,识别率接近GMM-HMM模型下的较好值。大家的任务还是沿袭第一阶段的。学习数据准备和MFCC的同学先数据准备相关的工作,如标注等,好给模型训练的同学用,然后移植kaldi中MFCC相关的代码。学习模型训练的同学先开始模型训练的准备工作,等要准备的数据好了后就开始训练。我负责整个软件架构的设计,同时还要把kaldi中的绝大部分(除了MFCC)移植进我们系统中。通过对kaldi的学习,使我对怎么设计这个在线语音识别的软件架构有了更深的认识。语音识别分两个阶段,即训练阶段和识别阶段。训练阶段就是得到模型给识别阶段用。它相对独立,我们就基于kaldi来训练模型,最终得到final.mdl等文件给识别阶段的软件用(在初始化时读取这些文件得到解码网络)。识别阶段的软件主要分两部分,声音采集和识别(包括特征提取和解码)。这样系统就有两个thread,一个是声音采集thread(audio capture thread),它基于ALSA来做,负责声音的采集和前处理(如噪声抑制),另一个是识别thread(kaldi process thread),负责MFCC和解码。两个thread通过ring buffer交互数据,同时要注意数据的保护。这样系统的软件架构框图如下:
大家对软件架构讨论觉得没什么问题后我就开始写代码搭建软件框架了。在 Linux中创建thread等都是一些套路活。Audio capture thread里先做初始化,包括ALSA的配置以及前处理模块的初始化等。然后就每隔一定时间通过ALSA_LIB的API完成一次音频数据的采集工作,读完数据后就做前处理,处理好后把音频数据放进ring buffer中,同时激活kaldi process thread,让kaldi process thread开始干活。Kaldi thread也是先做一些初始化的工作,然后睡下去等待激活。激活后先从ring buffer里取语音数据,然后做MFCC和decoder。完成后又睡下去等待下次再被激活。搭建软件框架时kaldi相关的代码还没被移植进去,kaldi process thread里仅仅把从ring buffer里拿到的语音数据写进PCM文件,然后用CoolEdit听,声音正常就说明软件框架基本成型了。刚开始时audio capture thread里也没加前处理模块,调试时把从ALSA里获取的数据写进PCM文件听后发现有噪声,就加了噪声抑制(ANS)模块。这个模块用的是webRTC里的。webRTC里的三大前处理模块(AEC/ANS/AGC)几年前我就用过,这次拿过来简单处理一下就用好了,去噪效果也挺好的。ANS一个loop是10ms,而前面说过kaldi里在线识别解码一次处理一组27帧是285ms,我就取两者的最小公倍数570ms作为audio capture thread的loop时间。从ALSA取到语音数据后分57(570/10 = 57)次做噪声抑制,再把抑制后的语音数据写进ring buffer。Kaldi thread激活后还是每次取出285ms语音数据做处理,只不过要取两次(570/285 = 2)。
软件架构搭好后就开始移植kaldi代码了。Kaldi代码量大,不可能也没必要全部移植到我们系统里,只需要移植我们需要的就可以了。怎样才能移植我们需要的代码呢?考虑后我用了如下的方法:先把在线解码相关的代码移植进去,然后开始不停的编译,报什么错提示缺什么就加什么,直到编译通过。这种方法保证了把需要的文件都移植进系统了,但有可能某些文件中的函数没用到,即到文件级还没到函数级。由于时间紧,这个问题就暂时不管了。移植过程更多的是一个体力活,需要小心细致。在移植过程中遇到问题就去网上搜,最后都圆满解决了。Kaldi主要用到了三个开源库:openfst、BLAS、LAPACK。BLAS和LAPACK我用的常规方法,即到官网上下载编译后生成库,然后把库和头文件放到系统的”/usr/lib”和“/use/include”下,让其他代码用。kaldi支持的有BALS库有 ATLAS / CLAPACK / openBLAS / MKL等。在X86的Ubuntu PC上跑kaldi时就用的Intel的MKL,在ARM上就不能用了,需要用其他的几种之一。我评估下来用了openBLAS,主要因为三点:1)它是BSD的;2)它支持多种架构(ARM/X86/MIPS/….),是开源库里性能最好的(各种架构里都嵌了很多的汇编代码),被多家著名公司使用,如IBM/ARM/nvidia/huawei等;3)它有多个编译选项可供选择,比如单线程/多线程选择、设定线程数等。BLAS的早期代码都是用fortran写的,后来用C对其进行了封装,所以系统还要加上对fortran的支持。对openFST,我发现用到的代码并不多,也就没用常规的方法,而是直接把用到的代码移植进系统。我移植好编译没问题后另一个同学把剩下的MFCC以及和ALSA接口(用ALSA接口替代kaldi里的PortAudio接口)相关的也移植进去了。这样移植工作就算结束了。对比了下移植进系统的kaldi代码和kaldi里SRC下的代码,应该是只用了其中一小部分。下图显示了移植进系统的kaldi文件(没列出相关的头文件)。同时负责模型训练的同学也有了一个初步的模型生成的文件,把这些文件放进系统里就可以跑起来了,人说话后PC屏幕上就有词打印出来,不过不正确。这也正常呀,因为还没调试呢!
3,第三阶段
第三阶段就是调试。第二阶段结束后说话就有词出来,但都是错的,需要排查定位问题。在线语音识别系统从大的角度可以分两块:模型和代码实现。首先我们需要定位是模型的问题还是代码实现的问题,先从模型排查。在第一阶段时利用thchs30大致搞清楚了在线解码的机制,是用模型tri1调的,当时识别率很差。现在要关注识别率了,把模型换成了tri2b,识别率有所提高。这说明kaldi里的在线解码的代码是没有问题的,识别率差问题出在模型。况且全球这么多人在用kaldi,如果在线解码有问题应该早就fix了。所以我们决定把我们生成的模型文件放进thchs30里来验证模型是否有问题。为了排除从MIC输入的音频数据有噪声等的干扰,先用读文件的方式验证。把我们的模型文件放进去后发现基本识别不正确,这说明模型是有问题的。负责模型的同学去调查,发现用于训练的音源都是8K采样的,但是在线解码用的都是16K采样的,这是我们自己挖的坑,用重采样程序把8K的全部转成16K的,这个坑也就填好了,但是识别率依旧不好。又发现训练集全是英国人的发音,而测试集是我们中国人的发音,有一定口音的,最好用我们中国人自己的发音作为训练集。于是我们自己又录了用于训练的音源,为了加大训练的数据,又请好多其他人录了音源。训练后得到了新的模型,再放到thchs30里面验证,识别率有六七成了,这说明模型的大方向对了,为了提高识别率,模型还需要继续调试。
接下来就要看代码部分是否有问题了。把新生产的模型放进我们自己的系统,并且用从音频文件都数据的方式(我们的系统既可以从MIC采集数据也可以从音频文件读数据,从音频文件读数据是为了debug)来替代从MIC采集到的数据(这样做是为了排除噪声等因素的干扰)来看代码是否有问题。运行下来发现识别率依旧很差,这说明我们的代码也是有问题的。在第二阶段我已经调试过部分代码,确保了在kaldi process thread里从PCM ring buffer里拿到的音频数据是没有问题的。还有两方面需要调试,一是送进MFCC的PCM数据要是OK的,二是我们的在线解码机制要跟kaldi里的在线解码机制完全一样。一很快就调试好了。二是先再深入研究吃透kaldi里的在线解码机制,改正我们与它不一样的地方,经过两三天调试后识别率跟thchs30里的差不多了,这说明我们的代码经过调试后也有一个好的base了,后面就要开始调性能了。
前面是通过从音频文件中读取数据来做在线识别的,数据相对干净些。现在要从MIC读取音频数据做真正在线识别了,试下来后识别率明显偏低,这说明我们的前处理还没完全做好(前面调试时只加了ANS模块)。我把前处理后的音频数据dump出来用CoolEdit听,的确有时候音质不好,于是我又把webRTC中的AGC模块加上去,再次dump出前处理后的音频数据听,多次听后都感觉音质正常。再来运行加了AGC后的从MIC采集音频数据的在线识别,识别率果然有了明显的提升。前处理能做的都做了,要想再提高识别率,就要靠模型发力了。做模型的同学一边请更多的人录音源来训练,一边尝试各种模型,最终用的是tri4b,有了一个相对不错的识别率。由于我们用的是GMM-HMM,如今主流的语音识别中已不再使用,老板就觉得没有必要再调了,后面肯定会用主流的模型的,但是整个嵌入式上的在线语音识别软件代码尤其软件架构和音频采集还是有用的,后面就要基于这些代码做真正的产品。
对语音识别领域的资深人士来说,这个嵌入式在线语音识别系统还很稚嫩。但通过搭这个系统,让我们对语音识别领域有了多一点的感性认识,也有了一个良好的开端,给老板以信心,并且可以继续做下去。这次工程上的事情偏多,后面希望更深入的做下去,累积更多的语音识别领域的经验。搭这个系统没有任何可供参考的资料,纯粹是根据我们以往的经验摸索着搭出来的。做的产品可能不一样,但很多解决问题的思路都是一样的。如果有朋友也搭过嵌入式上的在线语音识别系统,欢迎探讨,搭出一个更好的在线语音识别系统。











![[培训-DSP快速入门-2]:C54x DSP处理器的架构](https://img-blog.csdnimg.cn/2021071914514657.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0hpV2FuZ1dlbkJpbmc=,size_16,color_FFFFFF,t_70)