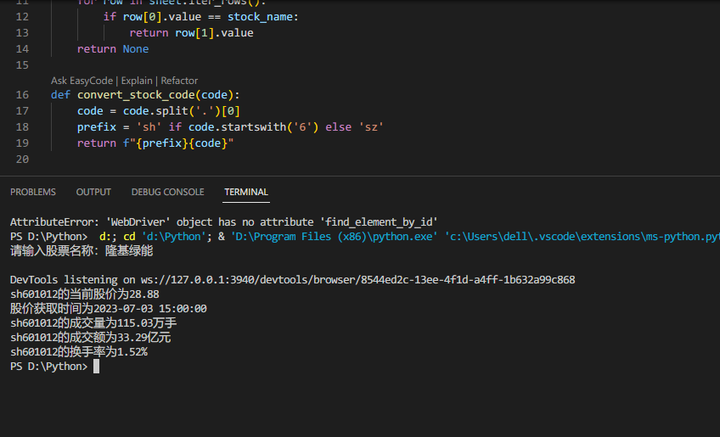
1. 需要给出明确的提示
为了让ChatGPT更好地理解您的意图并提供准确的分析和可视化,您需要给出明确的指示。
您希望创建的数据可视化类型、数据的维度,以及您想应用的任何过滤器或其他细节。
如果需要,您还可以提供必要的标签或注释,以确保ChatGPT准确理解您的意图并提供合适的帮助。
2.将问题进行拆解
当您在一次提示中提出过多问题时,可能会导致混淆和不明确。为了更好地理解您的需求并提供准确的帮助,
建议将提示分解为更小的任务。您可以分别询问关于数据分析和可视化的独立问题。
例如,您可以提出特定的计算或聚合问题,或者为不同的可视化需求提供单独的提示。
通过这种方式,ChatGPT将能够更好地理解您的意图,并为每个任务提供相应的支持和建议。
step 1: 将句子合并
step 2: 将句子翻译成英文
step 3: 将上述英文用json表述
3.提供更多的背景信息
为了让ChatGPT能够更好地理解您的分析需求,
它需要了解您使用的数据源、数据元素之间的关系以及可能涉及的过滤器或聚合操作。
为了提供最佳结果,请尽可能提供更多的上下文信息。
请告知ChatGPT您使用的数据源是什么,
例如数据库、CSV文件或API。描述数据元素之间的关系,
例如它们的字段、键值对或数据结构。如果您打算应用过滤器或聚合操作,
请具体说明您的要求,例如按日期范围过滤、按类别聚合等。
4.忽略自定义的设置
尽管ChatGPT非常智能,但如果您没有根据特定领域的数据进行微调,
它将无法完全理解您的数据分析和可视化需求。通过微调ChatGPT模型,
可以使其更加适应您的具体需求,并帮助您获得更准确、更相关的结果。
微调模型意味着使用特定领域的数据集对ChatGPT进行训练,
使其在该领域的理解能力和表达能力得到提升。这样,ChatGPT就能更好地理解和处理与您的数据分析和可视化任务相关的问题。
5.进行质量控制
这个话题其实在之前的文章里面我有讲到。详情包括例子 请看之前的文章。
ChatGPT 具有一些默认设置,但它们可能不适合您的需求。根据需要自定义 ChatGPT 模型的设置,详细的可以查看api的参数,
例如tempture等,以满足特定的输出格式或样式需求。参数的细微差别将会导致生成的内容全然不同,
甚至,不同的参数可能导致狗屁不通的文章,也可能产出近乎人情的话术。