Scala 语言学习笔记
概述
Scala 简介:
Scala 是一门基于 JVM 的多范式编程语言,通俗的说:Scala 是一种运行在 JVM 上的函数式的面向对象语言,之所以这样命名是因为它的设计目标是:随着用户的需求一起成长。Scala 可被广泛应用于各种编程任务,从编写小型的脚本到构建巨型系统都能胜任。正因如此,Scala 得以提供一些出众的特性,例如:它集成了面向对象编程和面向函数式编程的各种特性,以及更高层的并发模型。
Scala 语言的特点:
-
兼容性
兼容 Java,可以访问庞大的 Java 类库,例如操作 mysql、redis 等。
-
精简的
Scala 表达能力强,一行代码抵得上多行 Java 代码,开发速度快。
-
高级的
Scala 可以让程序保持短小、清晰,看起来更简洁、优雅。
-
静态类型的
Scala 拥有非常先进的静态类型系统,支持类型推断和模式匹配等。
-
可以开发大数据应用程序
例如 spark 、flink 程序等。
Scala 程序和 Java 程序的对比:
- Java 源代码通过 Javac 编译,编译结果为 Java 字节码、Java 类库
- Scala 源代码通过 scalac 编译,编译结果为 Java 字节码、Java 类库、Scala 类库
使用 Scala 语言创建一个学生类,定义姓名和年龄两个属性,创建一个学生类对象并输出:
//创建学生类
case class Student(var name:String, var age:Int)
//创建学生对象
val s = Student("sjh", 24)
//输出学生对象
print(s)
环境搭建:
-
JDK
-
Scala SDK
下载地址:https://www.scala-lang.org/download/
-
IDEA 在 plugins 中安装 Scala 插件(插件要与 IDEA 版本一致)
下载地址:https://plugins.jetbrains.com/plugin/1347-scala/versions
Scala 解释器:
Scala 解释器就像 Linux 命令一样,执行一条代码马上就可以看到执行结果。
启动解释器:win + R,输入 scala 即可。
打印 hello world:
println("hello world")
退出解释器:
:quit
小案例:
提示用户输入一句话,并把它打印出来:
scala> import java.util.Scanner//导包
import java.util.Scannerscala> println("输入你想说的一句话:")//提示用户
输入你想说的一句话:scala> println("你想说的一句话是:"+ new Scanner(System.in).nextLine())//将用户输入输出
你想说的一句话是:我正在学Scala
基本语法
输出和分号
换行输出:
println(1,2,3)
不换行输出:
print(1,2,3)
注意:可以同时打印多个值,使用逗号隔开。
println("hello scala")//单行分号可以不写
println("hello"); println("scala")//多行代码写在一行中间分号不能省略,最后一条代码的分号可省略。
常量
指程序运行过程中值不能发生改变的量。
-
字面值常量
print(10) //整形常量 print(10.1) //浮点型常量 print("scala") //字符串常量 print('a') //字符常量 print(true, false) //布尔常量 print(null) //空常量 -
自定义常量
变量
格式:
val/var 变量名:变量类型 = 初始值
val 定义的是不可重新赋值的变量,也就是自定义常量。
var 定义的变量可以被重新赋值。
可以使用类型推断来定义变量,代码更简洁:
var name:String = "sjh"
var name = "sjh"
字符串
Scala 提供多种定义字符串的形式
-
使用双引号
var name = "sjh" -
使用插值表达式,有效避免大量字符串拼接
val/var 变量名 = s"{变量/表达式}字符串"实例:定义三个变量,分别保存姓名,年龄,性别,定义一个字符串保存这些信息
scala> val name = "sjh" //定义姓名 name: String = sjhscala> val age = 24 //定义年龄 age: Int = 24scala> val sex = "male" //定义性别 sex: String = malescala> val res = s"name=${name},age=${age},sex=${sex}" //保存信息 res: String = name=sjh,age=24,sex=malescala> print(res) //输出 name=sjh,age=24,sex=male -
使用三引号,可以保存大量文本,例如大段 SQL 语句,三引号中的所有内容都会作为字符串的值
val/var 变量名 = """ 字符串的值 """ -
惰性赋值
在大数据开发中有时会编写非常复杂的 SQL 语句,当一些变量保存的数据较大时,而这些数据又不需要马上加载到 JVM 中,可以使用惰性赋值来提高效率。
lazy val/var 变量名 = 值
标识符
标识符就是给变量、方法、类起名字的,Scala 和 Java 中的标识符非常相似。
命名规则:
- 必须由 大小写英文字母、数字、下划线
_、美元符号$四部分任意组合。 - 数字不能开头。
- 不能和 Scala 关键字重名。
- 最好做到见名知意。
命名规范:
- 变量或方法:小驼峰命名,从第二个单词开始每个单词首字母大写。
- 类或特质:大驼峰命名,每个单词的首字母都大写。
- 包:全部小写,一般是公司域名反写,多级包用
.隔开。
数据类型
Scala 也是一门强类型语言,它里面的数据类型绝大多数与 Java 一样。
| 基础类型 | 类型说明 |
|---|---|
| Byte | 8 位带符号整数 |
| Short | 16 位带符号整数 |
| Int | 32 位带符号整数 |
| Long | 64 位带符号整数 |
| Char | 16 位无符号 Unicode 字符 |
| String | Char 类型的序列,字符串 |
| Float | 32 位单精度浮点数 |
| Double | 64 位单精度浮点数 |
| Boolean | true 或 false |
Scala 和 Java 类型的区别:
- 所有类型都以大写字母开头
- 整形使用 Int 而不是 Integer
- 定义变量可以不写类型,让编译器自动推断
- 默认整形是 Int,默认浮点型是 Double
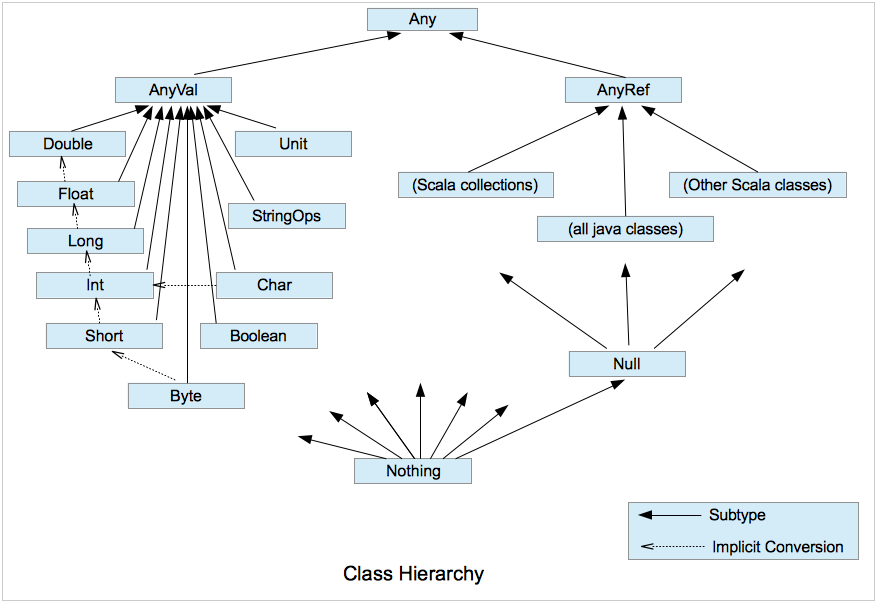
Scala 的类型关系图:
Any 是所有类型的父类,相当于 Java 中的 Object 类。
AnyVal 是所有数值类型的父类,AnyRef 是所有引用类型的父类。
Unit 类似于 Java 中的 void,一般作为返回值。
Null 是所有引用类型的子类,只有一个实例 null。
Nothing 是所有数据类型的子类,不能创建该类型实例,一般结合异常使用。
类型转换
当 Scala 程序在进行运算或赋值时,范围小的数据类型会自动转换为范围大的数据类型值,然后再进行计算。
类型转换分为值类型转换和引用类型转换,值类型转换又分为自动类型转换和强制类型转换。
-
自动类型转换
范围小的数据类型值会自动转换为范围大的数据类型值,自动类型转换从小到大依次为:
Byte -> Short -> Int -> Long -> Float -> Double -
强制类型转换
将范围大的数据类型值通过一定格式转换为范围小的数据类型值(可能会造成精度缺失)。
格式:
val/var 变量名:数据类型 = 具体的值.toXxx例如:
scala> var a:Int = 1 a: Int = 1scala> var b:Short = a.toShort b: Short = 1 -
值类型和 String 类型的相互转换
值类型转 String 格式:
val/var 变量名:String = 值类型 + "" val/var 变量名:String = 值类型.toStringString 类型转值类型格式:
val/var 变量名:值类型 = 字符串值.toXxx//如果转换Char要使用toCharArray
键盘录入
使用步骤:
-
导包
import scala.io.StdIn -
通过
stdIn.readXxx()接收用户键盘录入的数据接收字符串数据:
StdIn.readLine()接收整数数据:
StdIn.readInt()
示例:提示用户输入字符串
scala> import scala.io.StdIn
import scala.io.StdInscala> print("输入一句话:")
输入一句话:
scala> print("输入的是:"+StdIn.readLine())
输入的是:scala
运算符
算数运算符
包括 +(加号)、-(减号)、*(乘号)、/(除号)、%(取余)。
Scala中没有 ++,--这两个运算符。
a % b,底层是 a - a/b * b
Scala 中把字符串和整数数字 n 相乘相当于让字符串重复 n 次。
scala> print("x"*3)
xxx
赋值运算符
- 基本赋值运算符
= - 扩展赋值运算符
+=、-=、*=、/=、%=
关系运算符
包括>、>=、<、<=、==、!=
最终结果一定是 true 或 false。
如果需要比较数据值,使用==或者!=,如果比较引用值需要使用 eq 方法。
scala> val s1 = "a"
s1: String = ascala> val s2 = s1 + ""
s2: String = ascala> print(s1 == s2)
true
scala> print(s1.eq(s2))
false
逻辑运算符
包括 &&、||、!
最终结果一定是 true 或 false。
位运算符
包括&(按位与)、|(按位或)、^(按位异或)、~(按位取反)、<<(左移一位,相当于乘2)、>>(右移一位,相当于除以2)
位运算符只针对于整形数据,运算符操作的是数据的二进制补码形式。
流程控制
顺序结构
程序按照从上至下、从左至右的顺序依次逐行执行,中间没有任何判断和跳转。
顺序结构是 Scala 中的默认流程结构。
选择结构
if 注意事项:
-
和 Java 一样,如果大括号内只有一行代码可省略大括号
-
条件表达式有返回值
-
没有三元表达式,可以使用
if-else代替scala> println(if(1==1) 1 else 0) 1
块表达式:
使用一对大括号表示一个块表达式,块表达式也是有返回值的,最后一个表达式的值就是返回值
scala> val n = {| println(1)| 1+2| }
1
n: Int = 3
循环结构
for 循环
for(i <- 表达式/数组/集合){//逻辑
}
例如:打印10次 “hello scala”
scala> val n = 1 to 10
n: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)scala> for( i <- n){| println("hello scala")| }
hello scala
hello scala
hello scala
hello scala
hello scala
hello scala
hello scala
hello scala
hello scala
hello scala
**守卫:**for 表达式中的 if 判断语句。
例如输出1 - 10 之间的偶数:
scala> for(i <- 1 to 10 if i % 2 == 0 ) println(i)
2
4
6
8
10
**推导式:**Scala 中的 for 循环也有返回值,可以使用 yield 表达式构建出一个集合。
例如,生成一个10、20…100 的集合:
scala> val set = for(i <- 1 to 10) yield i * 10
set: scala.collection.immutable.IndexedSeq[Int] = Vector(10, 20, 30, 40, 50, 60, 70, 80, 90, 100)
while 循环
格式:
初始化条件
while(判断条件){//循环体//控制条件
}
例如:打印 1-5 的数字
scala> var i = 1
i: Int = 1scala> while(i <= 5){| println(i)| i += 1| }
1
2
3
4
5
do-while 循环
初始化条件
do{//循环体//控制条件
}while(判断条件)
break 和 continue
在 Scala 中,移除了 break 和 continue 关键字
如果要使用,需要 scala.util.controle 包下的 Breaks 类的 breakable 和 break 方法
用法:
-
导包:
import scala.util.control.Breaks._ -
使用 breakable 将 for 表达式包起来
-
for 表达式中需要退出循环的地方,添加
break()方法调用。
例如输出 1-10 的数字,遇到5退出:
scala> breakable{| for( i <- 1 to 10){| if(i == 5) break() else print(i)| }| }
1234
continue 的实现和 break 类似,不同的是需要使用 continue 的地方是用 breakable 将 for 表达式的循环体包起来即可。
例如输出 1-10 不能整除 3 的数字:
scala> for(i <- 1 to 10){| breakable{| if(i % 3 == 0) break() else print(i)| }| }
12457810
案例:打印九九乘法表
for(row <- 1 to 9){for(col <- 1 to row){print(s"${col} x ${row} = ${col * row}\t")}println()
}
或
for(row <- 1 to 9;col <- 1 to row){print(s"${col} x ${row} = ${col * row}\t")if(row == col) println()
}
方法和函数
方法
语法格式:
def 方法名(参数名1:参数类型1, 参数名2:参数类型2...)[: 返回值类型] = {//方法体
}
注意:
- 参数列表的参数类型不能省略
- 返回值类型可以省略,由 Scala 编译器自动推断
- 返回值可以不写 return ,默认就是块表达式的值
示例:定义一个方法用来获取两个整形数字的最大值并返回结果。
def getMax(num1:Int, num2:Int): Int = {return if(num1 >= num2) num1 else num2
}
或
def getMax(num1:Int, num2:Int) = if(num1 >= num2) num1 else num2
返回值的类型推断
当定义递归方法时,不能省略返回值的类型。
示例:定义一个方法求 5 的阶乘。
def f(n:Int):Int = if(n == 1) n else n * f(n - 1)
print(f(5))
惰性方法
当记录方法返回值的变量被声明为 lazy 时,方法的执行将被推迟,直到我们再次使用该值时方法才会执行,像这样的方法就叫做惰性方法。
**注意:**lazy 不能修饰 var 类型的变量。
使用场景:
- 打开数据库连接
- 提升某些特定模块的启动时间
- 确保对象中的某些字段优先初始化
示例:定义一个方法获取两个整数和,使用惰性技术调用该方法,然后打印结果。
scala> def add(num1:Int, num2:Int) = num1 + num2
add: (num1: Int, num2: Int)Intscala> lazy val sum:Int = add(1,2)
sum: Int = <lazy>scala> print(sum)
3
方法参数
-
默认参数
定义方法时可以给参数一个默认值并调用无参方法,例如:
def add(num1:Int = 1, num2:Int = 1) = num1 + num2 print(add())//2 -
带名参数
调用方法时可以指定参数的名称进行调用,例如
def add(num1:Int = 1, num2:Int = 1) = num1 + num2 print(add(num1 = 2))//3 print(add(10))//11 -
变长参数
如果方法的参数是不固定的,可以将该方法的参数定义为变长参数。
格式:
def 方法名(参数名:参数类型*)[: 返回值类型] = {//方法体 }一个方法有且只能有一个变长参数,并且变长参数要放到参数列表的最后面。
例如:定义一个方法计算 n 个数字的和。
def getSum(nums:Int*) = nums.sum print(getSum())//0 print(getSum(1, 2, 3, 4))//10
方法调用方式
-
后缀调用法
与 Java 相同,格式:
对象名.方法名(参数) 例如:Math.abs(-1) -
中缀调用法
格式:
对象名 方法名 参数 例如:Math abs -1在 Scala 中所有的操作符都是方法,操作符是一个方法名是符号的方法。
-
花括号调用法
方法只有一个参数时才能使用花括号调用法。
例如:
scala> Math.abs{| print("求绝对值,结果是:")| -1| } 求绝对值,结果是:res30: Int = 1 -
无括号调用法
如果方法没有参数,可以省略方法后面的括号。
例如:定义一个无参方法打印"hello scala",使用无括号调用法
def say() = print("hello scala") say//hello scala如果方法的返回值类型是 Unit,这样的方法称为过程,过程的
=可以省略不写,花括号不能省略:def say() { print("hello scala") }
函数
Scala 支持函数式编程,Spark/Flink 程序会大量使用函数。
定义
val 函数变量名 = (参数名1:参数类型1, 参数名2:参数类型2...) => 函数体
函数是一个对象
类似于方法,函数也有参数列表和返回值
函数定义不需要使用 def 定义
无需指定返回值类型
示例:定义一个计算两个整数之和的函数。
val getSum = (a:Int, b:Int) => a + b
val sum = getSum(1, 2)//3
方法和函数的区别
方法属于类或者对象,在运行时会加载到 JVM 的方法区。
可以将函数对象赋值给一个变量,在运行时会加载到 JVM 的堆中。
函数是一个对象,继承自 FunctionN,函数对象有apply、curried、toString、tupled这些方法,方法则没有。
结论:在 Scala 中,函数是对象,而方法是属于对象的,可以理解为:方法归属于函数。
可以通过在方法后加上空格和下划线将其转为函数,例如定义一个求和方法并转为函数:
def add(a:Int, b:Int):Int = a + b
val func = add _
func(1, 2)//3
案例:打印nn乘法表
通过方法:
def write(n:Int){for(row <- 1 to n;col <- 1 to row){print(s"${col} x ${row} = ${col * row}\t")if(row == col) println()}
}
通过函数:
val func = (n:Int) => {for(row <- 1 to n;col <- 1 to row){print(s"${col} x ${row} = ${col * row}\t")if(row == col) println()}
}
类和对象
类和对象
创建类和对象可以通过 class 和 new 关键字实现,用 class 创建类,用 new 创建对象。
示例:创建一个 Person 类,然后创建其对象并打印。
- 创建一个 Scala 项目,并创建一个 Object 类(Object 修饰的类是单例对象)。
- 在 object 类中添加 main 方法。
- 创建 Person 类,并在 main 方法中创建 Person 类的对象然后输出结果。
//实体类
class Person {}
----------------------------------------------
//测试类
object ClassDemo {//main方法,作为程序主入口,所有代码执行都从这里开始def main(args: Array[String]): Unit = {//创建 Person 对象val person = new Person()//打印对象println(person)}
}
如果类是空的,没有任何成员,可以省略{}
如果构造器参数为空,可以省略()
//简写类和对象
object ClassDemo {class Persondef main(args: Array[String]): Unit = {val person = new Personprintln(person)}}
成员变量
可以使用 var/val 定义成员变量,对象通过 对象名. 的方式访问成员变量。
示例:定义一个 Person 类,包含一个姓名和年龄字段,创建一个具体对象并打印。
object ClassDemo {class Person{var name = ""var age = 0}def main(args: Array[String]): Unit = {val person = new Personperson.name = "sjh"person.age = 24print(s"姓名:${person.name},年龄:${person.age}")}}
使用下划线初始化成员变量
在定义 var 类型的成员变量时,可以使用 _ 初始化成员变量。
val 类型的成员变量,必须要自己手动初始化。
例如:
class Person{var name:String = _var age:Int = _
}
定义和访问成员方法
在 Scala 的类中,也是使用 def 定义方法。
object ClassDemo {class Person{var name:String = _var age:Int = _def printHello(msg:String): Unit = print(msg)}def main(args: Array[String]): Unit = {val person = new Personprint(person.printHello("hello scala"))}}
访问修饰符
在 Scala 中没有 public 关键字,没有被标记为 private 和 protected 的成员都是公共的。
Scala 中的权限修饰符只有:privat、private[this]、protected、默认。
object ClassDemo {class Person{private var name:String = _private var age:Int = _//获取姓名def getName:String = name//设置姓名def setName(name:String): Unit = this.name = name//获取年龄def getAge:Int = age//设置年龄def setAge(age:Int): Unit = this.age = age}def main(args: Array[String]): Unit = {val person = new Personperson.setName("sjh")person.setAge(24)}}
构造器
主构造器
语法:
class 类名(var/val 参数名:类型 = 默认值,...){//构造代码块
}
示例:
object ClassDemo {class Person(var name:String = "sjh",var age:Int = 24){}def main(args: Array[String]): Unit = {//空参val p1 = new Person("s",2)//全参val p2 = new Person()//指定参数val p3 = new Person(age = 2)}}
辅助构造器
语法:
辅助构造器方法名必须叫 this。
def this(参数名:类型,...){//第一行需要调用主构造器或其他构造器//构造器代码
}
示例:
object ClassDemo {class Customer(var name:String,var address:String){def this(array: Array[String]) = {this(array(0),array(1))}}def main(args: Array[String]): Unit = {//通过辅助构造器创建对象val customer = new Customer(Array("sjh", "xi'an"))}}
单例对象
定义单例对象和定义类很像,就是把 class 换成 object。
格式:
object 单例对象名{}
在 object 中定义的成员变量类似 Java 中的静态变量,在内存中只有一个对象。
单例对象中,可以直接使用 单例对象名.的方式调用成员。
例如:
object ClassDemo {object Dog{val leg_num = 4}def main(args: Array[String]): Unit = {print(Dog.leg_num)}}
单例对象中的方法类似 Java 中的静态方法
object ClassDemo {object Dog{val leg_num = 4def say(): Unit = print("dog")}def main(args: Array[String]): Unit = {Dog.say()}}
main 方法
在 Java 中 main 方法是静态的,Scala 中没有 main 方法,所以必须将其放在一个单例对象中。
-
创建单例对象
object ClassDemo {def main(args: Array[String]): Unit = {print("hello scala")}} -
继承 App 特质
object ClassDemo extends App {print("hello scala") }
伴生对象
在 Java 中有一些类会同时有静态内容和非静态内容,在 Scala 中想要实现类似效果可以使用伴生对象来实现。
一个 class 和 object 具有相同的名字,这个 object 被称为伴生对象,这个 class 被称为半生类。
伴生对象和半生类可以互相访问 private 属性,必须写在一个源文件。
示例:
object ClassDemo {//半生类,里面内容非静态class Person{def eat(): Unit = print("eat " + Person.food)}//伴生对象object Person{private val food = "rice"}def main(args: Array[String]): Unit = {val person = new Personperson.eat()}}
如果某个成员变量权限为 private[this],表示只能在当前类访问,伴生对象也不能直接访问。
apply 方法
可以在创建对象时免去 new 操作,格式:
object 伴生对象名{def apply(参数名:参数类型...) = new 类(...)
}
示例:
object ClassDemo {//半生类class Person(name:String, age:Int){}//伴生对象object Person{def apply(name:String, age:Int): Person = new Person(name, age)}def main(args: Array[String]): Unit = {val person = Person("sjh", 24)}}
案例:定义工具类
import java.text.SimpleDateFormat
import java.util.Dateobject DateUtils {var sdf:SimpleDateFormat = _//日期转字符串def date2String(date:Date, template:String): String = {sdf = new SimpleDateFormat(template)sdf.format(date)}//字符串转日期def string2Date(dateStr:String, template:String): Date = {sdf = new SimpleDateFormat(template)sdf.parse(dateStr)}}
继承和抽象类
继承
语法:
class/object 子类 extends 父类{}
子类重写方法必须使用 override 修饰,可以使用 override 重新一个 val 字段,父类的 var 字段不可重写。
示例:
object ClassDemo {class Person{val name = ""var age = 24def say(): Unit = print("")}class Student extends Person{override val name = "sjh"override def say(): Unit = print("hello")}def main(args: Array[String]): Unit = {val student = new Student()student.say()//hello}}
类型判断
- isInstanceOf 判断对象是否为指定类的对象
- asInstanceOf 将对象转换为指定类型
示例:
object ClassDemo {class Person{}class Student extends Person{def say(): Unit = print("hello")}def main(args: Array[String]): Unit = {val p:Person = new Student()if(p.isInstanceOf[Student]) {val s = p.asInstanceOf[Student]s.say()}}}
isInstanceOf 只能判断对象是否为指定类以及其子类的对象而不能精确判断其类型,如果精确判断可以使用 getClass 和 classOf 来实现。
示例:
object ClassDemo {class Person{}class Student extends Person{}def main(args: Array[String]): Unit = {val p:Person = new Student()print(p.getClass == classOf[Person])//falseprint(p.getClass == classOf[Student])//true}}
抽象类
如果类中有抽象字段或抽象方法,那么该类就必须是抽象类。
抽象字段:没有初始化的变量。
抽象方法:没有方法体。
格式:
abstract class 抽象类名{val/var 抽象字段名:类型def 方法名(参数:参数类型...):返回类型
}
示例:
object ClassDemo {abstract class Shape{val c:Intdef getArea:Double}class Square(x:Int) extends Shape{override val c: Int = xoverride def getArea: Double = c * c}class Circle(r:Int) extends Shape{override val c: Int = roverride def getArea: Double = Math.PI * c * c}def main(args: Array[String]): Unit = {val square = new Square(1)println(square.getArea)//1val circle = new Circle(1)println(circle.getArea)//3.141592653589793}}
匿名内部类
匿名内部类是继承了类的匿名子类对象
语法:
new 类名(){//重写类中所有的抽象内容
}
如果类的主构造器参数列表为空,小括号可以省略。
作用:对象的成员方法仅调用一次、作为方法的参数传递。
示例:
object ClassDemo {abstract class Person{def sayHello()}def show(person: Person): Unit = person.sayHello()def main(args: Array[String]): Unit = {val person:Person = new Person {override def sayHello(): Unit = println("hello")}show(person)}}
案例:动物类
定义抽象动物类,属性包括:姓名,年龄,行为:跑步和吃饭
定义猫类,重写吃饭方法,并定义独有抓老鼠方法。
定义狗类,重写吃饭方法,并定义独有看家方法。
object ClassDemo {abstract class Animal{var name = ""var age = 0def run(): Unit = println("run")def eat()}class Cat extends Animal{override def eat(): Unit = println("eat fish")def catchMouse(): Unit = println("catch mouse")}class Dog extends Animal{override def eat(): Unit = println("eat meat")def catchThief(): Unit = println("catch thief")}def main(args: Array[String]): Unit = {val animal:Animal = new Cat()if(animal.isInstanceOf[Cat]) {val cat = animal.asInstanceOf[Cat]cat.catchMouse()} else if(animal.isInstanceOf[Dog]) {val dog = animal.asInstanceOf[Dog]dog.catchThief()} else {println("not cat or dog")}}}
特质
概述
Scala 中的特质要用关键字 trait 修饰。
特点:
- 特质可以提高代码的复用性。
- 特质可以提高代码的扩展性和可维护性。
- 类与特质是继承关系,类与类只支持单继承,类与特质之间可以单继承也可以多继承。
- Scala 的特质中可以有普通字段、抽象字段、普通方法、抽象方法。
- 如果特质只有抽象内容也叫瘦接口,如果既有抽象内容又有具体内容叫做富接口。
语法:
定义特质
trait 特质名称{}
继承特质
class 类名 extends 特质1 with 特质2{}
示例:类继承单个特质
object ClassDemo {trait Logger{def log(msg:String)}class ConsoleLogger extends Logger{override def log(msg: String): Unit = println(msg)}def main(args: Array[String]): Unit = {val logger = new ConsoleLoggerlogger.log("hello scala")}}
示例:类继承多个特质
object ClassDemo {trait MsgSender{def send(msg:String)}trait MsgReceiver{def receive()}class MsgWorker extends MsgSender with MsgReceiver{override def send(msg: String): Unit = println(s"发送消息:$msg")override def receive(): Unit = println("接收消息")}def main(args: Array[String]): Unit = {val worker = new MsgWorkerworker.send("hello")worker.receive()}}
示例:object 继承 trait
object ClassDemo {trait MsgSender{def send(msg:String)}trait MsgReceiver{def receive()}object MsgWorker extends MsgSender with MsgReceiver{override def send(msg: String): Unit = println(s"发送消息:$msg")override def receive(): Unit = println("接收消息")}def main(args: Array[String]): Unit = {MsgWorker.send("hello scala")MsgWorker.receive()}}
示例:trait 中的成员
object ClassDemo {trait Hero{val name = ""val arms = ""def attack(): Unit = println("发起进攻")def skill()}class Killer extends Hero{override val name = "sjh"override val arms = "gun"override def skill(): Unit = println("kill")}def main(args: Array[String]): Unit = {val killer = new Killerkiller.attack()killer.skill()}}
对象混入 trait
在 Scala 中,类和特质之间无任何继承关系,但通过特定关键字让该类对象具有指定特质中的成员。
语法:
val/var 对象名 = new 类 with 特质
示例:
object ClassDemo {trait Logger{def log(): Unit = println("log..")}class User{}def main(args: Array[String]): Unit = {val user = new User with Loggeruser.log()//log..}}
使用 trait 实现适配器模式
当某个特质中有多个抽象方法,而我们只需要用到某个或某几个方法时不得不将该特质所有抽象方法重写。针对这种情况可以定义一个抽象类继承该特质,重写特质的所有方法,方法体为空。需要使用哪个方法只需要定义类继承抽象类,重写指定方法即可。
object ClassDemo {trait Play{def mid()def top()def adc()def jungle()def support()}abstract class Player extends Play{override def mid(): Unit = {}override def top(): Unit = {}override def adc(): Unit = {}override def jungle(): Unit = {}override def support(): Unit = {}}//新手类class GreenHand extends Player {override def support(): Unit = println("我是辅助")}def main(args: Array[String]): Unit = {val player = new GreenHandplayer.support()}}
使用 trait 实现模板方法模式
在 Scala 中我们可以先定义一个操作中的算法骨架,而将算法的一些步骤延迟到子类中,使得子类可以不改变该结构的情况下重定义该算法的某些特定步骤,这就是模板方法设计模式。
优点:扩展性强、符号开闭原则。
缺点:类的个数增加会导致系统庞大,设计更抽象、增加代码阅读难度。
object ClassDemo {//模板类,计算某个方法的执行时间abstract class Template{def code()def getRuntime: Long = {val startTime = System.currentTimeMillis()code()val endTime = System.currentTimeMillis()endTime - startTime}}class Concrete extends Template{override def code(): Unit = for(_ <- 1 to 10000) println("scala")}def main(args: Array[String]): Unit = {println(s"耗时:${new Concrete().getRuntime} ms")}}
使用 trait 实现责任链模式
多个 trait 中出现了同一方法,且该方法最后都调用了 super.该方法名(),当类继承了这多个 trait 后就可以依次调用多个 trait 中的此同一个方法了,这就形成了一个调用链。
执行顺序:从右至左、先子类后父类。
示例:
object ClassDemo {trait Handler{def handle(data:String): Unit = {println("具体的处理数据...4")println(data)}}trait DataValid extends Handler{override def handle(data: String): Unit = {println("验证数据 3")super.handle(data)}}trait SignValid extends Handler{override def handle(data: String): Unit = {println("验证签名 2")super.handle(data)}}class Payment extends DataValid with SignValid{def pay(data:String): Unit = {println("用户发起支付请求 1")super.handle(data)}}def main(args: Array[String]): Unit = {val payment = new Paymentpayment.pay("发起转账..5")}}
trait 构造机制
每个特质只有一个无参构造器
遇到一个类继承另一个类以及多个trait的情况,创建该类实例时构造器执行顺序:
- 执行父类构造器
- 从左到右依次执行 trait 的构造器
- 如果trait 有父 trait,先执行父 trait
- 如果多个 trait 有相同的父 trait,父 trait 构造器只初始化一次
- 执行子类构造器
示例:
object ClassDemo {trait A{println("A")}trait B extends A{println("B")}trait C extends A{println("C")}class D{println("D")}class E extends D with B with C{println("E")}def main(args: Array[String]): Unit = {new E//DABCE}}
trait 继承 class
trait 可以继承 class,会将所有的成员都继承下来。
示例:
object ClassDemo {class A{def printMsg(): Unit = println("hello scala")}trait B extends Aclass C extends Bdef main(args: Array[String]): Unit = {new C().printMsg()//hello scala}}
案例:程序员
object ClassDemo {abstract class Programmer{val name = ""val age = 0def eat(): Unit = println("eat")def code()}class JavaProgrammer extends Programmer{override def code(): Unit = println("精通 java")}trait BigData{def bigData(): Unit = println("精通大数据")}class PartJavaProgrammer extends JavaProgrammer with BigData{override def code(): Unit = {super.code()bigData()}}def main(args: Array[String]): Unit = {val javaProgrammer = new PartJavaProgrammerjavaProgrammer.code()}}
包
包
包就是文件夹,用 package 修饰,可以区分重名类。
作用域:
子包可以直接访问父包中的内容。
上层访问下层内容时,可以通过导包(import)或者写全包名的形式实现。
如果上下层有相同的类,使用时采用就近原则(优先使用下层)。
包对象:
要定义在父包中,一般用于对包的功能进行补充、增强。
可见性:
通过访问权限修饰符 private、protected、默认来限定访问修饰符。
格式:
访问修饰符[包名]
引入:
Scala 默认引入了 java.lang 包的全部内容,scala 包以及 Predef 包的部分内容。
包的引入不限于Scala 文件的顶不,而是可以编写到任何需要使用的地方。
如果需要导入某个包中的所有类和特质,使用下划线 _ 实现。
如果需要的时某个包的某几个类和特质,可以通过选取器 {}实现。
如果引入的多个包含有相同的类,可以通过重命名或隐藏解决。
重命名格式:
import java.util.{HashSet => JavaSet}
隐藏格式:
import java.util.{HashSet => _,_}//引入util包下除了HashSet的类
样例类
样例类是一种特殊类,一般用于保存数据,在并发编程以及 Flink 等框架中会经常使用。
格式:
case class 样例类名([var/val] 成员变量名1:类型1...)
如果不写,变量默认修饰符是val。如果要实现某个成员变量值可以被修改,则需要手动添加var 修饰。
示例:
object ClassDemo {case class Person(val name:String, var age:Int)def main(args: Array[String]): Unit = {val person = new Person(name = "sjh", age = 24)//person.name = "" 不可修改person.age = 0}}
样例类的默认方法
-
apply
可以快速使用类名创建对象,省略 new 关键字。
-
toString
可以在打印时直接打印该对象各个属性值。
-
equals
可以直接使用 == 直接比较属性值。
-
hashCode
同一个对象哈希值一定相同,不同对象哈希值一般不同。
-
copy
可以用来快速创建属性值相同的实例对象,还可以使用带名参数的形式给指定的成员变量赋值。
-
unapply
示例:
object ClassDemo {case class Person(var name:String, var age:Int)def main(args: Array[String]): Unit = {val person = Person(name = "sjh", age = 24)println(person)//Person(sjh,24)val person1 = person.copy(age = 20)println(person1)//Person(sjh,20)}}
样例对象
用 case 修饰的单例对象就叫样例对象,而且它没有主构造器,主要用在:
- 枚举值
- 作为没有任何参数的消息传递
示例:
object ClassDemo {//特质 Sex,表示性别trait Sex//样例对象,表示男,继承 Sex 特质case object Male extends Sex//样例对象,表示女,继承 Sex 特质case object Female extends Sex//定义样例类 Personcase class Person(var name:String, var sex:Sex){}def main(args: Array[String]): Unit = {val p = Person("sjh", Male)}}
案例:计算器
定义样例类 Calculate,并在其中添加四个方法分别用来计算两个整数的加减乘除操作。
object ClassDemo {case class Calculate(a:Int, b:Int){def add(): Int = a + bdef sub(): Int = a - bdef mul(): Int = a * bdef div(): Int = a / b}def main(args: Array[String]): Unit = {val res = Calculate(1, 1)println(s"加法: ${res.add()}")//2println(s"减法: ${res.sub()}")//0println(s"乘法: ${res.mul()}")//1println(s"除法: ${res.div()}")//1}}
数据结构
数组
定长数组
语法:
val/var 变量名 = new Array[元素类型](数组长度)
val/var 变量名 = new Array(元素1, 元素2 ...)
示例:
def main(args: Array[String]): Unit = {val arr = new Array[Int](10)arr(0) = 1println(arr(0))//1println(arr.length)//10
}
变长数组
语法:
val/var 变量名 = ArrayBuffer[元素类型]
val/var 变量名 = ArrayBuffer(元素1, 元素2 ...)
示例:
def main(args: Array[String]): Unit = {val arr = ArrayBuffer[Int]()val arr1 = ArrayBuffer("1", true, 3)println(arr)//ArrayBuffer()println(arr1)//ArrayBuffer(1, true, 3)
}
增删改:
- 使用 += 添加单个元素
- 使用 -= 删除单个元素
- 使用 ++= 追加一个数组
- 使用 --= 移除多个元素
示例:
def main(args: Array[String]): Unit = {val arr = ArrayBuffer("spark", "hadoop", "flink")arr += "flume"arr -= "spark"arr ++= Array("hive", "sqoop")arr --= Array("sqoop", "hadoop")println(arr)//ArrayBuffer(flink, flume, hive)
}
遍历数组
通过索引
for(i <- 0 to arr.length-1)//to包括右println(arr(i))
for(i <- arr.indices)println(arr(i))
for(i <- 0 until(arr.length))//until不包括右println(arr(i))
通过 for 循环
for (elem <- arr)println(elem)
数组常用算法
sum :求和
max:求最大值
min:求最小值
sorted:排序,返回一个新的数组
reverse:反转,返回一个新的数组
示例:
def main(args: Array[String]): Unit = {val arr = Array(4,1,6,5,2,3)println(arr.sum)//21println(arr.max)//6println(arr.min)//1val arr1 = arr.sortedfor (elem <- arr1)print(elem)//123456println()val arr2 = arr1.reversefor (elem <- arr2)print(elem)//654321
}
元组
元组一般用来存储不同类型的数据,并且长度和元素都不可变。
语法:
//通过小括号实现
val/var 元组 = (元素1,元素2...)
//通过箭头(只适用于有2个元素的情况)
val/var 元组 = 元素1 -> 元素2...
示例:
def main(args: Array[String]): Unit = {val tuple = ("sjh", 24)val tuple1 = "sjh" -> 24println(tuple)//(sjh,24)println(tuple1)//(sjh,24)
}
访问元组中元素
通过 元组名._编号 形式访问元组中元素,编号从 1 开始。或者通过 元组名.productIterator 获取迭代器遍历。
示例:
def main(args: Array[String]): Unit = {val tuple = "sjh" -> 24//方法1 通过编号println(tuple._1)//方法2 获取迭代器val iterator = tuple.productIteratorfor (elem <- iterator)println(elem)
}
列表
不可变列表
List 存储的数据有序、可重复,有序是指元素的存入和取出顺序是一致的。列表分为不可变列表和可变列表。
不可变列表指的是列表的元素、长度都不可变。
语法:
val/var 变量名 = List(元素1,元素2...)
val/var 变量名 = Nil
val/var 变量名 = 元素1 :: 元素2 :: Nil
可变列表
语法:
val/var 变量名 = ListBuffer[数据类型]()
val/var 变量名 = ListBuffer(元素1,元素2...)
可变列表常用操作:
| 格式 | 功能 |
|---|---|
| 列表名(索引) | 根据索引获取元素 |
| 列表名(索引) = 值 | 修改元素值 |
| += | 添加单个元素 |
| ++= | 追加列表 |
| -= | 删除某个元素 |
| –= | 删除多个元素 |
| toList | 转为不可变列表 |
| toArray | 转为数组 |
示例:
def main(args: Array[String]): Unit = {val list = ListBuffer(1, 2, 3)println(list(0))list += 4list ++= List(5, 6, 7)list -= 7list --= List(3, 4)val list1 = list.toListval array = list.toArrayprintln(list1)//List(1, 2, 5, 6)for (elem <- array) print(elem)//1256
}
列表常用操作
| 格式 | 功能 |
|---|---|
| distinct | 去重 |
| isEmpty | 判断是否为空 |
| ++ | 拼接两个列表 |
| head | 返回第一个元素 |
| tail | 返回除了第一个元素之外的其他元素 |
| reverse | 反转并返回新列表 |
| take | 获取前缀元素(自定义个数) |
| drop | 获取后缀元素(自定义个数) |
| flatten | 扁平化操作,返回新列表 |
| zip | 拉链操作,合并列表 |
| unzip | 拉开操作,拆分列表 |
| toString | 转换默认字符串 |
| mkString | 转换指定字符串 |
| union | 获取两个列表并集元素,返回新列表 |
| intersect | 获取两个列表交集元素,返回新列表 |
| diff | 获取两个列表差集元素,返回新列表 |
示例:
def main(args: Array[String]): Unit = {val list = List(1, 2, 3, 4)print(list.isEmpty)//falseval list2 = List(4, 5, 6)val list3 = list ++ list2println(list3)//List(1, 2, 3, 4, 4, 5, 6)println(list3.head)//1println(list3.tail)//List(2, 3, 4, 4, 5, 6)//前3个是前缀println(list3.take(3))//List(1, 2, 3)//前3个是前缀,获取后缀println(list3.drop(3))//List(4, 4, 5, 6)
}
示例:扁平化操作
将嵌套列表(每个元素都是列表)的所有具体元素单独放到一个新的列表
def main(args: Array[String]): Unit = {val list1 = List(1, 2)val list2 = List(3, 4)val list = List(list1, list2, List(5))val flatten = list.flattenprintln(list)//List(List(1, 2), List(3, 4), List(5))println(flatten)//List(1, 2, 3, 4, 5)
}
示例:拉链与拉开
拉链:将两个列表组合成一个元素为元组的列表
拉开:将一个包含元组的列表,拆解成包含两个列表的元组
def main(args: Array[String]): Unit = {val names = List("sjh", "a", "bb")val ages = List(24, 1, 10)val list1 = names.zip(ages)println(list1)//List((sjh,24), (a,1), (bb,10))val tuple1 = list1.unzipprintln(tuple1)//(List(sjh, a, bb),List(24, 1, 10))}
示例:转换字符串
mkString 以指定符号分割元素
def main(args: Array[String]): Unit = {val list = List(1, 2, 3, 4)println(list.toString())//List(1, 2, 3, 4)println(list.mkString(":"))//1:2:3:4
}
集
不可变集
特点:唯一、无序
语法:
//创建空的不可变集
val/var 变量名 = Set[类型]()
//指定元素
val/var 变量名 = Set(元素1, 元素2...)
常用操作:
- size 获取大小
- 遍历操作和数组一致
+添加元素,生成一个新的 Set++拼接集或列表,生成一个新的 Set-删除一个元素,生成一个新的 Set--删除多个元素,,生成一个新的 Set
可变集
导入包
import scala.collection.mutable.Set
映射
不可变 Map
语法:
//通过箭头
val/var map = Map(k1->v1, k2->v2...)
//通过小括号
val/var map = Map((k1,v1), (k2,v2)...)
可变 Map
导入包
import scala.collection.mutable.Map
基本操作:
- map(key) 获取键对应值,不存在返回None
- map.keys 获取所有键
- map.values 获取所有值
- 遍历 通过普通for实现
- getOrElse 根据键获取值,不存在返回指定默认值
+增加键值对,生成一个新的 Map。如果是可变 Map,直接使用+=或++=。-删除键值对,生成一个新的 Map。如果是可变 Map,直接使用-=或--=。
示例:
def main(args: Array[String]): Unit = {val map = Map("sjh" -> 24, "ax" -> 10)println(map.keys)//Set(ax, sjh)println(map.values)//HashMap(10, 24)for (elem <- map) { println(elem)}//(ax,10) (sjh,24)println(map.getOrElse("sjh", 1))//24map += "abc" -> 10println(map)//Map(abc -> 10, ax -> 10, sjh -> 24)}
迭代器
使用 iterator 从集合获取迭代器,迭代器的两个方法:
hasNext 判断是否有下一个元素
next 返回下一个元素,没有会抛出异常
示例:
def main(args: Array[String]): Unit = {val list = List(1, 2, 3, 4, 5)val iterator = list.iteratorwhile (iterator.hasNext)print(iterator.next())//12345
}
函数式编程
函数式编程指 方法的参数列表可以接收函数对象。
| 函数名 | 功能 |
|---|---|
| foreach | 遍历集合 |
| map | 转换集合 |
| flatmap | 扁平化操作 |
| sorted | 默认排序 |
| sortBy | 按照指定字段排序 |
| sortWith | 自定义排序 |
| groupBy | 按指定条件分组 |
| reduce | 聚合计算 |
| fold | 折叠计算 |
foreach
def main(args: Array[String]): Unit = {val list = List(1, 2, 3, 4, 5)//函数格式 (函数参数列表) => {函数体}list.foreach((x:Int) => {println(x)})//简写格式1 通过类型推断省略参数数据类型list.foreach(x => println(x))//简写格式2 函数参数只在函数体出现一次,且函数体没有涉及复杂使用,可以使用下划线简化list.foreach(println(_))}
map
将一种类型转换为另一种类型,例如将 Int 列表转为 String 列表
def main(args: Array[String]): Unit = {val list = List(1, 2, 3, 4)//将数字转换为对应个数的 *val list2 = list.map((x:Int) => {"*" * x})println(list2)//List(*, **, ***, ****)//根据类型推断简化val list3 = list.map(x => "*" * x)println(list3)//List(*, **, ***, ****)//下划线val list4 = list.map("*" * _)println(list4)//List(*, **, ***, ****)
}
flatMap
可以理解为先进行 map ,再进行 flatten 操作。
def main(args: Array[String]): Unit = {val list = List("hadoop hive spark flink", "kudu hbase storm")val list2 =list.map(_.split(" ")).flattenprintln(list2)//List(hadoop, hive, spark, flink, kudu, hbase, storm)val list3 =list.flatMap(_.split(" "))println(list2)//List(hadoop, hive, spark, flink, kudu, hbase, storm)
}
filter
过滤出符合一定条件的元素,示例,筛选偶数:
def main(args: Array[String]): Unit = {val list = (1 to 6).toListprintln(list.filter(_ % 2 == 0))//List(2, 4, 6)}
排序
def main(args: Array[String]): Unit = {//升序排序val list = List(3, 1, 2, 9, 8)println(list.sorted)//List(1, 2, 3, 8, 9)//指定字段排序val list2 = List("01 hadoop", "02 flume", "03 hive")println(list2.sortBy(_.split(" ")(1)))//List(02 flume, 01 hadoop, 03 hive)//自定义排序实现降序val list3 = List(2, 3, 1, 6, 4, 5)//第一个下划线表示前面的元素,第二个下划线表示后面的元素println(list3.sortWith(_ > _))//List(6, 5, 4, 3, 2, 1)
}
group by
将数据按指定条件进行分组,示例,按照性别分组:
def main(args: Array[String]): Unit = {val list = List("sjh"->"男","ssf"->"女","ka"->"男")//按照元素第二个元素分组//val map = list.groupBy(x => x._2)val map = list.groupBy(_._2)println(map)//Map(男 -> List((sjh,男), (ka,男)), 女 -> List((ssf,女)))//统计不同性别人数val map2 = map.map(x => x._1 -> x._2.length)//不能用下划线简化,因为x在后面出现了2次println(map2)//Map(男 -> 2, 女 -> 1)
}
reduce 和 fold
示例:计算1-10的和,reduce 相当于 reduceLeft,如果想从右到左计算使用 reduceRight
def main(args: Array[String]): Unit = {val list = (1 to 10).toList//x表示聚合操作的结果,y表示下一个元素var i = list.reduce((x, y) => x + y)//简化i = list.reduce(_ + _)println(i)//55
}
fold 和 reduce 很像,只是 fold 多了一个指定初始化值参数
fold 相当于 foldLeft,如果想从右到左计算使用 foldRight
示例:定义一个列表包括1-10,假设初始化值100,计算所有元素和
def main(args: Array[String]): Unit = {val list = (1 to 10).toList//x表示聚合操作的结果,y表示下一个元素val i = list.fold(100)(_ + _)println(i)//155
}
案例:学生成绩单
定义列表,记录学生成绩,格式为:姓名,语文成绩,数学成绩,英语成绩。
获取所有语文成绩在60分以上得同学信息。
获取所有学生的总成绩。
按照总成绩降序排列。
def main(args: Array[String]): Unit = {val list = List(("a", 37, 90 ,100), ("b", 90, 73 ,80), ("c", 60, 90, 76), ("d", 59, 21, 72), ("e", 100, 100, 100))//获取语文成绩60分以上学生信息val list1 = list.filter(_._2 > 60)println(list1)//List((b,90,73,80), (e,100,100,100))//获取所有学生总成绩val list2 = list.map(x => x._1 -> (x._2 + x._3 + x._4))println(list2)//List((a,227), (b,243), (c,226), (d,152), (e,300))//按照总成绩降序排列val list3 = list2.sortWith(_._2 > _._2)println(list3)//List((e,300), (b,243), (a,227), (c,226), (d,152))}
模式匹配、偏函数、异常、提取器
模式匹配
作用:判断固定值、类型查询、快速获取数据
简单模式匹配
格式:
变量 match{case 常量1 => 表达式1case 常量2 => 表达式2case 常量3 => 表达式3case _ => 表达式4 //默认项
}
示例:
def main(args: Array[String]): Unit = {println("输入一个单词")val word = StdIn.readLine()word match {case "hadoop" => println("大数据分布式存储和计算框架")case "zookeeper" => println("大数据分布式协调服务框架")case "spark" => println("大数据分布式内存计算框架")case _ => println("未匹配")}
}
匹配类型
格式:
对象名 match{case 变量名1:类型1 => 表达式1case 变量名2:类型2 => 表达式2case _:类型3 => 表达式3//表达式没用到变量名可以使用下划线代替case _ => 表达式4 //默认项
}
示例:
def main(args: Array[String]): Unit = {val a:Any = "hadoop"a match {case x:String => println(s"${x}是字符串")case x:Int => println(s"${x}是数字")case _ => println("未匹配")}
}
守卫
守卫指在 case 中添加 if 条件判断,这样可以让代码更简洁。
格式:
变量 match{case 变量名 if 条件1 => 表达式1case 变量名 if 条件2 => 表达式2case 变量名 if 条件3=> 表达式3case _ => 表达式4 //默认项
}
示例:
def main(args: Array[String]): Unit = {val a = StdIn.readInt()a match {case x if x > 0 => println("正数")case x if x < 0 => println("负数")case _ => println("是0")}
}
匹配样例类
要匹配的对象必须声明为 Any。
格式:
对象名 match{case 样例类型1(字段1, 字段2..) => 表达式1case 样例类型2(字段1, 字段2..) => 表达式2case 样例类型3(字段1, 字段2..) => 表达式3case _ => 表达式4 //默认项
}
示例:
object ClassDemo {case class Customer(name:String, age:Int)case class Order(id:Int)def main(args: Array[String]): Unit = {val a:Any = Customer("sjh", 20)a match {case Customer => println("是customer")case Order => println("是order")case _ => println("未匹配")}}}
匹配集合
-
匹配数组
def main(args: Array[String]): Unit = {//定义三个数组val arr1 = Array(1, 2, 3)val arr2 = Array(0)val arr3 = Array(0 , 1, 2, 3,4)arr1 match {case Array(1, _, _) => println("长度为3,首元素为1")case Array(0) => println("长度为1,元素0")case Array(0, _*) => println("首元素0,其余任意")} } -
匹配列表
def main(args: Array[String]): Unit = {//定义三个列表val list1 = List(1, 2, 3)val list2 = List(0)val list3 = List(0, 1, 2, 3,4)list3 match {case List(1, _, _) => println("长度为3,首元素为1")case List(0) => println("长度为1,元素0")case List(0, _*) => println("首元素0,其余任意")}//等价于list2 match {case 1 :: _ :: _ ::Nil => println("长度为3,首元素为1")case 0 :: Nil => println("长度为1,元素0")case 0 :: _ => println("首元素0,其余任意")} } -
匹配元组
def main(args: Array[String]): Unit = {//定义三个元组val a = (1, 2, 3)val b = (3, 4, 5)val c = (3, 4)a match {case (1, _, _) => println("长度为3,首元素为1")case (_, _, 5) => println("长度为3,尾元素为5")case _ => println("不匹配")} }
变量声明中的模式匹配
在定义变量时,可以使用模式匹配快速获取数据
生成包含 0-10的数字,使用模式匹配分别获取第2、3、4个元素
生成包含 0-10的列表,使用模式匹配分别获取第1、2个元素
def main(args: Array[String]): Unit = {val arr = (0 to 10).toArrayval Array(_, x, y, z, _*) = arrprintln(x, y, z)//(1,2,3)val list = (0 to 10).toListval List(a, b, _*) = listval c :: d ::tail = listprintln(a, b)//(0,1)println(c, d)//(0,1)
}
匹配 for 表达式
定义变量记录学生姓名和年龄,获取所有年龄为20的学生信息:
def main(args: Array[String]): Unit = {val map = Map("sjh" -> 20, "a" -> 21, "asx" -> 20)//方式一 iffor((k, v) <- map if v == 20)println(k, v)//方式二 固定值for((k, 20) <- map)println(k, 20)}
Option 类型
用来避免空指针异常,具体值使用 Some(x),空值使用 None
示例:定义一个两数相除的方法,使用 Option 类型封装结果
object ClassDemo {def divide(a:Int, b:Int): Option[Int] = {if(b == 0)NoneelseSome(a / b)}def main(args: Array[String]): Unit = {divide(10, 0) match {case None => println("除数不能为 0")case Some(x) => println(s"结果为$x")}}}
偏函数
可以配合集合的函数式编程简化代码。
偏函数是指 被包在花括号内没有 match 的一组 case语句。
示例:
def main(args: Array[String]): Unit = {val pf:PartialFunction[Int, String] = {case 1 => "一"case 2 => "二"case _ => "未匹配"}println(pf(1))//一
}
偏函数可结合 map 函数使用。
定义一个列表包含1-10的数字,将1-3的数字转为[1-3],4-8的数字转为[4-8],其余数字转为(8-*]
def main(args: Array[String]): Unit = {val list = (1 to 10).toListval list1 = list.map {case x if x >= 1 && x <= 3 => "[1-3]"case x if x >= 4 && x <= 8 => "[4-8]"case _ => "(8,*]"}println(list1)//List([1-3], [1-3], [1-3], [4-8], [4-8], [4-8], [4-8], [4-8], (8,*], (8,*])
}
正则表达式
Scala 提供了 Regex 类定义正则表达式
要构造一个 Regex 对象直接使用 String 类的 r 方法即可
建议使用三个双引号表示正则表达式,不需要对其中的反斜杠转义。
格式:
val 正则对象名 = """具体正则表达式""".r
示例:校验邮箱
def main(args: Array[String]): Unit = {val regex = """.+@.+\.com""".rval email = "sad@qq.com"if(regex.findAllMatchIn(email).nonEmpty)println("合法")elseprintln("不合法")
}
示例:过滤出不合法的邮箱
def main(args: Array[String]): Unit = {val regex = """.+@.+\.com""".rval emailList = List("sad@.com", "asda@qq.com", "fuck@,cn")val list = emailList.filter((x) => regex.findAllMatchIn(x).isEmpty)println(list)//List(sad@.com, fuck@,cn)
}
示例:获取邮箱运营商
def main(args: Array[String]): Unit = {//括号可以充当分组角色,用来提取其中内容val regex = """.+@(.+)\.com""".rval emailList = List("sad@.com", "asda@qq.com", "fuck@,cn")val list = emailList.map{case x @ regex(company) => x -> companycase x => x -> "未匹配"}println(list)//List((sad@.com,未匹配), (asda@qq.com,qq), (fuck@,cn,未匹配))
}
异常处理
-
捕获异常
该方式处理完异常,程序会继续执行
-
抛出异常
该方式处理完异常,程序会终止执行
def main(args: Array[String]): Unit = {//捕获异常try{val i = 10 / 0}catch {case _:ArithmeticException => println("算术异常")case _ => println("其他异常")}finally {println("一般用来释放资源")}//抛出异常throw new Exception("发生异常")
}
提取器
一个类如果要支持模式匹配,必须要实现一个提取器。
提取器就是指 unapply 方法。
样例类自动实现了 unapply 方法。
要实现提取器,只需要在该类的伴生对象中实现一个unapply 方法即可。
示例:
object ClassDemo {class Student(var name:String, var age:Int)object Student{//apply 根据给定字段将其封装为 Student 类型对象def apply(name: String, age: Int): Student = new Student(name, age)//unapply 根据传入的学生对象,获取其各个属性值def unapply(s: Student): Option[(String, Int)] = {if(s == null)NoneelseSome(s.name, s.age)}}def main(args: Array[String]): Unit = {val s = Student("sjh", 24)//获取 s 的属性//通过 unapplyprintln(Student.unapply(s))//通过模式匹配 需要实现 unapply方法s match {case Student(name, age) => println(s"$name,$age")case _ => println("未匹配")}}}
案例:随机职业
提示用户录入一个数字(1-5),然后根据数字打印出他的工作。
def main(args: Array[String]): Unit = {println("请输入一个数字,1-5:")val num = StdIn.readInt()num match {case 1 => println("BAT offer")case 2 => println("BAT offer")case 3 => println("BAT offer")case 4 => println("BAT offer")case 5 => println("BAT offer")case _ => println("在家科研,哪都别去")}}
数据的读写
读取数据
在 Source 单例对象中提供了一些获取数据的方法。
按行读取
以行为单位,返回值是一个迭代器类型的对象,通过toArray、toList方法将数据放到数组或列表。
def main(args: Array[String]): Unit = {//创建 Source 对象,关联数据源文件val source = Source.fromFile("./data/1.txt")//在项目中创建一个 data目录和对应文件//以行为单位读取数据val lines:Iterator[String] = source.getLines()//将读取到的数据封装到 List 集合val list:List[String] = lines.toList//打印结果for(data <- list)println(data)//关闭 Sourcesource.close()
}
按字符读取
def main(args: Array[String]): Unit = {//创建 Source 对象,关联数据源文件val source = Source.fromFile("./data/1.txt")//默认使用utf-8//以字符为单位读取数据val buffered:BufferedIterator[Char] = source.buffered//打印结果while(buffered.hasNext)print(buffered.next())//不能使用println//关闭 Sourcesource.close()
}
如果文件内容较少,可以直接把它读取到一个字符串中:
def main(args: Array[String]): Unit = {//创建 Source 对象,关联数据源文件val source = Source.fromFile("./data/1.txt")//将数据读取到字符串val string = source.mkString//打印结果println(string)//关闭 Sourcesource.close()
}
读取词法单元和数字
词法单元指 以特定符号间隔开的字符串
创建一个文本文件
10 2 5
11 2
5 1 3 2
读取所有整数,将结果加1并打印
def main(args: Array[String]): Unit = {//创建 Source 对象,关联数据源文件val source = Source.fromFile("./data/1.txt")//将数据读取到字符串数组 \s 表示空白字符(空格,\t,\r,\n等)val strArr:Array[String] = source.mkString.split("\\s+")val intArr:Array[Int] = strArr.map(_.toInt)//打印结果for (elem <- intArr) {print(elem + " ")}//11 3 6 12 3 6 2 4 3 //关闭 Sourcesource.close()
}
从 URL 或其他源读取
从 URL 地址读取
val source = Source.fromURL("http:www.baidu.com")
从字符串读取
val source = Source.fromString("字符串读取数据")
读取二进制文件
示例:读取图片
def main(args: Array[String]): Unit = {//创建File对象关联文件val file = new File("./data/1.jpg")//创建字节输入流val fis = new FileInputStream(file)val bytes = new Array[Byte](file.length().toInt)//开始读取val len = fis.read(bytes)println(s"读取到的字节数:$len")//关闭字节输入流fis.close()}
写入数据
要使用 Java 的类库
往文件中写入指定内容
def main(args: Array[String]): Unit = {//创建字节输出流val fos = new FileOutputStream("./data/1.txt")//目的地不存在会自动创建//输出fos.write("GetOffer".getBytes())//关闭输出流fos.close()}
序列化和反序列化
要实现序列化必须继承 Serializable 特质(标记接口),如果是样例类可以省略继承
case class Person(name:String, age:Int) [extends Serializable]def main(args: Array[String]): Unit = {val p = Person("sjh", 24)//序列化val outputStream = new ObjectOutputStream(new FileOutputStream("./data/2.txt"))outputStream.writeObject(p)outputStream.close()//反序列化val inputStream = new ObjectInputStream(new FileInputStream("./data/2.txt"))val person = inputStream.readObject().asInstanceOf[Person]//读取出的对象是AnyRef,要转换println(person)inputStream.close()
}
案例:学员成绩表
已知项目 data 文件夹下的 1.txt 记录了学生成绩如下:
张三 37 90 100
李四 90 73 81
王五 60 90 76
赵六 89 21 72
田七 100 100 100
按照学生总成绩进行排名,按照姓名-语文成绩-数学成绩-英语成绩-总成绩的格式,输出到 2.txt
case class Student(var name:String,var chinese:Int, var math:Int, var english:Int){def getSum:Int = chinese + math +english}def main(args: Array[String]): Unit = {//获取数据源文件val source = Source.fromFile("./data/1.txt")//封装到数组val array:Iterator[Array[String]] = source.getLines().map(_.split(" "))//定义可变列表存储学生信息val stuList = ListBuffer[Student]()//遍历数组,将数据封装成 Student 对象,添加到可变列表for(s <- array){stuList += Student(s(0), s(1).toInt, s(2).toInt, s(3).toInt)}//排序val list = stuList.sortBy(_.getSum).reverse.toList//通过字符输出流输出文件val bw = new BufferedWriter(new FileWriter("./data/2.txt"))bw.write("姓名 语文 数学 英语 总分")bw.newLine()for(s <- list){bw.write(s"${s.name} ${s.chinese} ${s.math} ${s.english} ${s.getSum}")bw.newLine()//换行}//关闭资源bw.close()source.close()}
2.txt:
姓名 语文 数学 英语 总分
田七 100 100 100 300
李四 90 73 81 244
张三 37 90 100 227
王五 60 90 76 226
赵六 89 21 72 182
高阶函数
Scala 混合了面向对象和函数式特性,如果一个函数的参数列表可以接收函数对象,那么这个函数就被称为高阶函数。
作为值的函数
可以将函数对象传递给方法 。
需求:将一个整数列表中的每个元素转换为对应个数的*。
def main(args: Array[String]): Unit = {val list = (1 to 5).toListval func = (x:Int) => "*" * xval list1 = list.map(func)println(list1)//List(*, **, ***, ****, *****)
}
匿名函数
没有赋值给变量的函数就是匿名函数
def main(args: Array[String]): Unit = {val list = (1 to 5).toListval list1 = list.map((x:Int) => "*" * x)val list2 = list.map("*" * _)println(list1)//List(*, **, ***, ****, *****)println(list2)//List(*, **, ***, ****, *****)
}
柯里化
柯里化指 将原先接收多个参数的方法转换为多个只有一个参数列表的过程
需求:定义方法完成两个字符串的拼接
object ClassDemo {//普通写法def merge1(str1:String, str2:String): String = str1 + str2//柯里化 f1表示函数def merge2(str1:String, str2:String)(f1:(String, String) => String): String = f1(str1, str2)def main(args: Array[String]): Unit = {println(merge1("abc", "def"))//abcdefprintln(merge2("abc", "def")(_ + _))//abcdef}}
闭包
闭包指 可以访问不在当前作用域范围数据的一个函数。(柯里化就是一个闭包)
通过闭包获取两个整数的和:
def main(args: Array[String]): Unit = {val x = 10val sum = (y:Int) => x + yprintln(sum(10))//20
}
控制抽象
假设函数 A 的参数列表需要接收一个函数 B,而函数B没有输入值也没有返回值,那么函数A称为控制抽象函数。
示例:
object ClassDemo {val func = (f1:() => Unit) => {println("welcome")f1()println("bye")}def main(args: Array[String]): Unit = {func(() => println("shopping.."))}}
结果:
welcome
shopping..
bye
案例:计算器
定义一个方法,用来完成两个 Int 类型数字的计算
具体计算封装到函数中
使用柯里化完成操作
object ClassDemo {//普通写法def add(a:Int, b:Int): Int = a + bdef sub(a:Int, b:Int): Int = a - bdef mul(a:Int, b:Int): Int = a * bdef div(a:Int, b:Int): Int = a / b//柯里化def calculate(a:Int, b:Int)(func:(Int,Int) => Int): Int = func(a, b)def main(args: Array[String]): Unit = {println(calculate(1, 1)(_ + _))//2println(calculate(1, 1)(_ - _))//0println(calculate(1, 1)(_ * _))//1println(calculate(1, 1)(_ / _))//1}}
隐式转换和隐式参数
隐式转换
隐式转换指用 implicit 关键字 声明的带有 单个参数 的方法。该方法是被自动调用的,用来实现自动将某种类型的数据转换为另一种类型的数据。
示例:手动导入
通过隐式转换,让 File 类的对象具有 read 功能。
执行流程:file对象没有read方法 -> 有隐式转换 -> 将File转为RichFile对象
object ClassDemo {class RichFile(file: File){//定义 read 方法def read(): String = Source.fromFile(file).mkString}object Implicit{implicit def file2RichFile(file: File): RichFile = new RichFile(file)}def main(args: Array[String]): Unit = {//手动导入import Implicit.file2RichFileval file = new File("./data/1.txt")file.read()}}
自动调用隐式转换:
- 当对象调用类中不存在的方法或成员时
- 当方法参数类型与目标类型不一致时
如果在当前作用域存在隐式转换方法,会自动导入隐式转换
object ClassDemo {class RichFile(file: File){//定义 read 方法def read(): String = Source.fromFile(file).mkString}def main(args: Array[String]): Unit = {//自动导入implicit def file2RichFile(file: File): RichFile = new RichFile(file)val file = new File("./data/1.txt")file.read()}}
隐式参数
隐式参数指用 implicit 关键字 修饰的变量。调用方法时可以不给定初始值,因为编译器会自动查找缺省值。
使用步骤:
- 在方法后添加一个参数列表,参数使用 implicit 修饰
- 在 object 中定义 implicit 修饰的隐式值
- 调用该方法,可以不传入 implicit 修饰的参数值
和隐式转换一样,可以手动导入,如果作用域内定义了隐式值可以自动导入。
定义一个show方法,实现将传入的值,使用指定前缀分隔符和后缀分隔符包装起来。
例如 show(“a”)("<<",">>") // <<a>>
object ClassDemo {//name表示姓名,第一个String表示前缀信息,第二个String表示后缀信息def show(name:String)(implicit delimit:(String, String)): String = delimit._1 + name +delimit._2//定义单例对象,用来给隐式参数默认值object Implicit{implicit val delimit_default: (String, String) = ("<<" ,">>")}def main(args: Array[String]): Unit = {//手动导入import Implicit.delimit_default//调用showprintln(show("abc"))//<<abc>>println(show("abc")("<-", "->"))//<-abc->}}
自动导入
object ClassDemo {//name表示姓名,第一个String表示前缀信息,第二个String表示后缀信息def show(name:String)(implicit delimit:(String, String)): String = delimit._1 + name +delimit._2def main(args: Array[String]): Unit = {//自动导入implicit val delimit_default: (String, String) = ("<<" ,">>")//调用showprintln(show("abc"))//<<abc>>println(show("abc")("<-", "->"))//<-abc->}}
案例:获取列表元素平均值
通过隐式转换,获取列表中所有元素的平均值。
object ClassDemo {class RichList(list: List[Int]){def avg(): Option[Int] = {if(list.isEmpty)NoneelseSome(list.sum / list.size)}}def main(args: Array[String]): Unit = {//自动导入implicit def list2RichList(list: List[Int]): RichList = new RichList(list)//调用val list = (1 to 10).toListprintln(list.avg())//Some(5)}}
递归
递归就是方法自己调用自己
示例:求阶乘
object ClassDemo {def f(n: Int): Int = if(n == 1) n else n * f(n - 1)def main(args: Array[String]): Unit = {println(f(5))}}
内存图解
Scala 中,内存分为五部分
-
栈
所有代码的执行、存储局部变量。
按照 FILO 的顺序执行,方法执行完毕后立马被回收。
-
堆
存储所有new 出来的对象。
在不确定的时间被垃圾收集器回收。
-
方法区
存储字节码文件,方法等数据。
程序执行完毕后,由操作系统回收资源。
-
本地方法区
和本地方法相关。
-
寄存器
和 CPU 相关。
斐波那契数列
已知数列1,1,2,3,5,8,13,求第12个数字。
object ClassDemo {def f(n: Int): Int = {if(n == 1 || n == 2)1elsef(n - 1) + f(n - 2)}def main(args: Array[String]): Unit = {println(f(12))//144}}
案例:打印目录文件
定义 printFile 方法,该方法打印该文件夹下所有文件路径。
object ClassDemo {def printFile(dir: File): Unit = {if(!dir.isDirectory)println("路径不合法")else {//获取该目录下所有文件及文件夹val files:Array[File] = dir.listFiles()for(listFile <- files){if(listFile.isDirectory)printFile(listFile)elseprintln(listFile)}}}def main(args: Array[String]): Unit = {printFile(new File("d:/"))}}
泛型
泛型
泛型的意思是 泛指某种具体的数据类型,在 Scala 中泛型用 [数据类型] 表示。
-
泛型方法
示例,定义一个泛型方法,获取任意数据类型的中间元素
def getMiddleElement[T](array: Array[T]): T = {array(array.length / 2)} -
泛型类
示例,定义一个 Pair 泛型类,包含两个字段且字段类型不固定
class Pair[T](var a:T, var b:T) -
泛型特质
trait Logger[T]{val a:Tdef show(b:T) }object ConsoleLogger extends Logger[String]{override val a: String = "sjh"override def show(b: String): Unit = println(b) }
上下界
上界
使用 T <: 类型名 表示给类型添加一个上界,表示该类型必须是 T 或 T 的子类。
object ClassDemo {class Personclass Student extends Persondef demo[T <: Person](array: Array[T]): Unit = println(array)def main(args: Array[String]): Unit = {demo(Array(new Person))demo(Array(new Student))demo(Array("a"))//报错}}
下界
使用 T >: 类型名 表示给类型添加一个下界,表示该类型必须是 T 或 T 的父类。
如果泛型既有上界又有下界,下界写在前面,[T >: A <: B]
协变、逆变、非变
协变:类 A 和 类 B 之间是父子类关系,Pair[A] 和 Pari[B] 之间也有父子关系。
class Pair[+T]{}
逆变:类 A 和 类 B 之间是父子类关系,但 Pair[A] 和 Pari[B] 之间是子父关系。
class Pair[-T]{}
非变:类 A 和 类 B 之间是父子类关系,Pair[A] 和 Pari[B] 之间没有任何关系。
class Pair[T]{} //默认类型是非变的
示例:
object ClassDemo {class Superclass Sub extends Superclass Temp1[T]class Temp2[+T]class Temp3[-T]def main(args: Array[String]): Unit = {//测试非变val t1:Temp1[Sub] = new Temp1[Sub]//val t2:Temp1[Super] = t1 报错//测试协变val t3:Temp2[Sub] = new Temp2[Sub]val t4:Temp2[Super] = t3//测试逆变val t5:Temp3[Super] = new Temp3[Super]val t6:Temp3[Sub] = t5}}
集合
分类:
-
可变集合 线程不安全
集合本身可以动态变化,且可变集合提供了改变集合内元素而都方法。
scala.collection.mutable //需要手动导包 -
不可变集合 线程安全
默认类库,集合内的元素一旦初始化完成就不可再进行更改,任何对集合的改变都将生成一个新的集合。
scala.collection.immutable //不需要手动导包
- Set 无序、唯一
- HashSet
- SortedSet
- TreeSet
- BitSet
- ListSet
- Seq 序列、有序、可重复、元素有索引
- IndexedSeq 索引序列,随机访问效率高
- NumericRange Range的加强
- Range 有序整数序列,类似等差数列
- Vector 通用不可变的数据结构,获取元素时间长,随机更新快于数组或列表
- String 字符串
- LinearSeq 线性序列,主要操作首尾元素
- List 列表
- Queue 队列
- Stack 栈 不可变栈已经弃用
- Stream 流
- IndexedSeq 索引序列,随机访问效率高
- Map
- HashMap
- SortedMap
- TreeMap
- ListMap
可变集合比不可变集合更丰富,例如在 Seq 中,增加了 Buffer 集合,例如 ArrayBuffer 和 ListBuffer。
Traverable
Traverable 是一个特质,它的子特质 immutable.Traverable 和 mutable.Traverable 分别是不可变集合和可变集合的父特质。
格式:
创建空的Traverable 对象。
val t = Traverable.empty[Int]
val t = Traverable[Int]()
val t = Nil
创建带参数的Traverable 对象。
val t = List(1, 2, 3).toTraverable
val t = Traverable(1, 2, 3)//默认生成List
转置:
使用 transpose 方法。
转置操作时,需要每个集合的元素个数相同。
def main(args: Array[String]): Unit = {val t1 = Traversable(Traversable(1, 4, 7), Traversable(2, 5, 8), Traversable(3, 6, 9))println(t1)//List(List(1, 4, 7), List(2, 5, 8), List(3, 6, 9))val transpose = t1.transposeprintln(transpose)//List(List(1, 2, 3), List(4, 5, 6), List(7, 8, 9))
}
拼接:
++ 可以拼接数据,但是会创建大量临时集合,可以通过 concat 方法实现。
def main(args: Array[String]): Unit = {val t1 = Traversable(1, 2, 3)val t2 = Traversable(4, 5, 6)val traversable = Traversable.concat(t1, t2)println(traversable)//List(1, 2, 3, 4, 5, 6)
}
筛选:
利用 collect 方法实现偏函数结合集合使用,从集合中筛选指定数据。
def main(args: Array[String]): Unit = {val t1 = (1 to 10).toListdef filter:PartialFunction[Int, Int] = {case x if x % 2 == 0 => x}//val t2 = t1.collect(filter)val t2 = t1.collect({case x if x % 2 == 0 => x})println(t2)//List(2, 4, 6, 8, 10)
}
scan 方法
def scan[B](z:B)(op: (B, B) => B)
[B] 表示返回值的数据类型,(z:B)表示初始化值,(op: (B, B) => B)表示具体的函数运算。
示例:定义 traversable 集合,存储1-5,假设初始值为1,分别获取每个元素的阶乘值。
def main(args: Array[String]): Unit = {val t1 = 1 to 5//val seq = t1.scan(1)((a, b) => a * b)val seq = t1.scan(1)(_ * _)println(seq)//Vector(1, 1, 2, 6, 24, 120)
}
获取集合指定元素
head/last : 获取第一个/最后一个元素,不存在抛出异常
headOption/lastOption : 获取获取第一个/最后一个元素,返回值是 Option
find: 查找符号条件的第一个元素
slice :截取集合中的一部分元素,左闭右开
def main(args: Array[String]): Unit = {val t1 = 1 to 5println(t1.head)//1println(t1.last)//5println(t1.headOption)//Some(1)println(t1.lastOption)//Some(5)println(t1.find(_ % 2 == 0))//Some(2)println(t1.slice(0, 2))//Vector(1, 2)
}
判断元素是否合法
forall 如果集合中所有元素都满足条件返回 true
exist 如果集合中有一个元素满足条件返回 true
def main(args: Array[String]): Unit = {val t1 = 1 to 5println(t1.forall(_ % 2 == 0))//falseprintln(t1.exists(_ % 2 == 0))//true
}
聚合函数
count 统计集合中满足条件的元素个数
sum 获取集合元素和
product 获取集合中所有元素成绩
max 获取集合中所有元素最大值
min 获取集合中所有元素最小值
集合类型转换
- toList
- toSet
- toArray
- toSeq
填充元素
fill 快速生成指定数量的元素
iterator 根据指定条件,生成指定个数的元素
range 生成某个区间内的指定间隔的所有数据,不传间隔参数默认 1
def main(args: Array[String]): Unit = {val t1 = Traversable.fill(5)("a")println(t1)//List(a, a, a, a, a)val t2 = Traversable.fill(2, 2, 2)("a")println(t2)//List(List(List(a, a), List(a, a)), List(List(a, a), List(a, a)))val t3 = Traversable.iterate(1, 5)(_ * 10)println(t3)//List(1, 10, 100, 1000, 10000)val t4 = Traversable.range(1, 100, 7)println(t4)//List(1, 8, 15, 22, 29, 36, 43, 50, 57, 64, 71, 78, 85, 92, 99)
}
案例:随机学生序列
定义一个 Traversable 集合,包含 5 个学生信息,学生姓名年龄随机生成。
按照学生年龄降序排列并打印。
object ClassDemo {case class Student(name:String, age:Int)def main(args: Array[String]): Unit = {val names: List[String] = List("aa" ,"bb", "cc", "dd", "ee")val r:Random = new Random()val students = Traversable.fill(5)(Student(names(r.nextInt(names.size)), r.nextInt(10) + 20))val list = students.toListval list1 = list.sortWith(_.age < _.age)println(list1)//List(Student(ee,22), Student(bb,23), Student(ee,23), Student(ee,24), Student(aa,26))}}
Iterable
Iterable 表示一个可以迭代的集合,它继承了 Travsersable 特质,同时也是其他集合的父特质。它定义了获取迭代器的方法,这是一个抽象方法。
遍历集合示例:
def main(args: Array[String]): Unit = {val list = List(1, 2, 3, 4, 5)//方式一 主动迭代val iterator = list.iteratorwhile (iterator.hasNext)print(iterator.next() + " ")//方式二 被动迭代list.foreach(x => print(x + " "))
}
分组遍历示例:
def main(args: Array[String]): Unit = {val i = (1 to 5).toIterableval iterator = i.grouped(2)while (iterator.hasNext)print(iterator.next() +" ")//Vector(1, 2) Vector(3, 4) Vector(5)
}
按照索引生成元组:
def main(args: Array[String]): Unit = {val i = Iterable("A", "B", "C", "D", "E")val tuples = i.zipWithIndex.map(x => x._2 -> x._1)println(tuples)//List((0,A), (1,B), (2,C), (3,D), (4,E))
}
判断集合是否相同:
def main(args: Array[String]): Unit = {val i1 = Iterable("A", "B", "C")val i2 = Iterable("A", "C", "B")val i3 = Iterable("A", "B", "C")println(i1.sameElements(i2))//falseprintln(i1.sameElements(i3))//true
}
Seq
Seq 特质代表 按照一定顺序排列的元素序列,序列是一种特别的可迭代集合,它的特点是有序、可重复、有索引
创建 Seq 集合:
def main(args: Array[String]): Unit = {val seq = (1 to 5).toSeqprintln(seq)//Range(1, 2, 3, 4, 5)
}
获取长度及元素:
通过 length 或 size 方法获取长度,通过索引直接获取元素。
def main(args: Array[String]): Unit = {val seq = (1 to 5).toSeqprintln(seq.length)//5println(seq.size)//5println(seq(0))//1
}
获取指定元素的索引值
- indexOf 获取指定元素在列表中第一次出现的位置
- lastIndexOf 获取指定元素在列表中最后一次出现的位置
- indexWhere 获取满足条件的元素,在集合中第一次出现的索引
- lastIndexWhere 获取满足条件的元素,在集合中最后一次出现的索引
- indexOfSlice 获取指定的子序列在集合中第一次出现的位置
找不到返回 -1。
判断是否包含指定数据:
startsWith 是否以指定子序列开头
endsWith 是否以指定子序列结尾
contains 判断是否包含某个指定数据
containsSlice 判断是否包含某个指定子序列
修改指定的元素:
updated 修改指定索引位置的元素为指定的值。
patch 修改指定区间的元素为指定的值。
def main(args: Array[String]): Unit = {val seq = (1 to 5).toSeqval seq1 = seq.updated(0, 5)println(seq1)//Vector(5, 2, 3, 4, 5)//参数1 起始索引 参数2 替换后的元素 参数3 替换几个val seq2 = seq.patch(1, Seq(1, 2), 3)println(seq2)//Vector(1, 1, 2, 4, 5)
}
Stack
top 获取栈顶元素
push 入栈
pop 出栈
clear 清除所有元素
mutable.Stack 有一个独有方法 pushAll,把多个元素压入栈中。
ArrayStack 有独有方法为:dup,复制栈顶元素。preseving,执行表达式,执行完毕后恢复栈。
操作示例:
def main(args: Array[String]): Unit = {//从右往左入栈val s = mutable.Stack(1, 2, 3, 4, 5)println(s.top)//1println(s.push(6))//Stack(6, 1, 2, 3, 4, 5)println(s.pushAll(Seq(7, 8, 9)))//Stack(9, 8, 7, 6, 1, 2, 3, 4, 5)println(s.pop())//9println(s.clear())//()
}
定义可变栈存储1-5,通过dup方法复制栈顶元素,通过preseving 方法先清空元素再恢复。
def main(args: Array[String]): Unit = {//从右往左入栈val s = mutable.ArrayStack(1, 2, 3, 4, 5)//复制栈顶元素s.dup()println(s)//ArrayStack(1, 1, 2, 3, 4, 5)s.preserving({//该方法执行后,栈中数据会恢复s.clear()})println(s)//ArrayStack(1, 1, 2, 3, 4, 5)
}
Queue
表示队列,特点是 FIFO,常用的队列是 mutable.Queue,内部以 MutableList 实现。
enqueue 入队
dequeue 出队
dequeueAll 移除所有满足条件的元素
dequeueFirst 移除第一个满足条件的元素
案例:统计字符个数
提示用户录入字符串并接受,统计每个字符出现的次数并打印。
def main(args: Array[String]): Unit = {println("请输入一个字符串:")val str = StdIn.readLine()val map = mutable.Map[Char, Int]()for(c <- str.toCharArray){if(!map.contains(c))map += c -> 1elsemap += c -> (map.getOrElse(c, 1) + 1)}map.foreach(println(_))
}