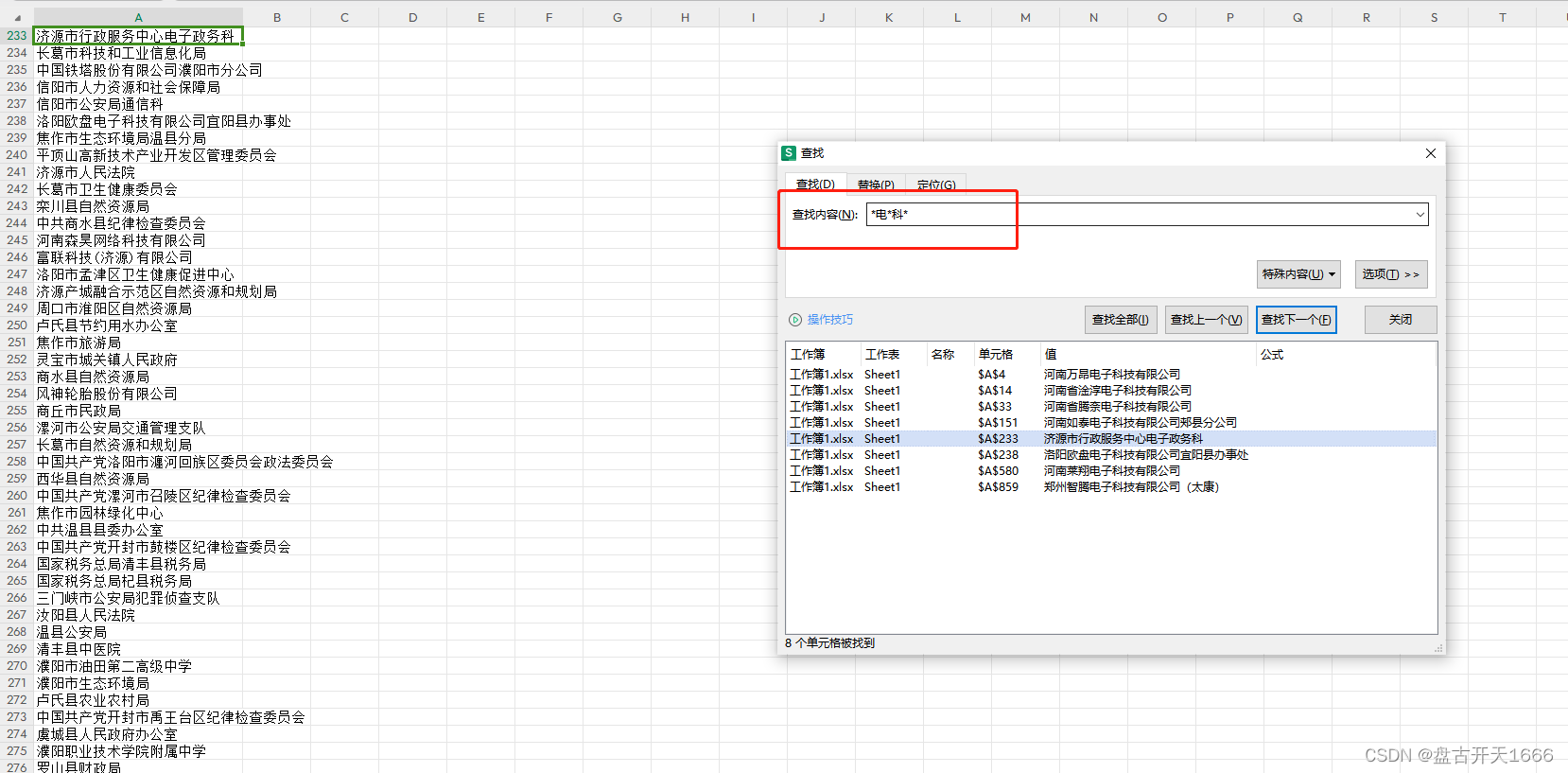
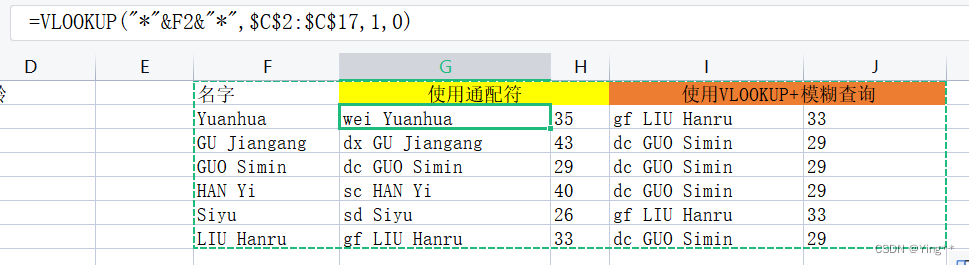
复习题
一、问答题
1.Anaconda的优点有哪些?
(1)开源。
(2)安装过程简单。
(3)⾼性能使⽤Python和R语⾔。
(4)免费的社区⽀持。
(5) Conda包管理。
(6) 1,000+开源库
2.爬虫技术是什么?它的设计流程有哪些?
通过递归访问网络资源,抓取网络中信息的数据。
Scrapy是一个用于爬取网页、提取结构化数据的应用的框架,可用于数据挖掘、信息处理或历史归档等的应用系统。
(1)Scrapy Engine:负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等;
(2)Scheduler:它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列和入队,当引擎需要时交还给引擎;
(3)Downloader:负责下载Scrapy Engine发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine,由引擎交给Spider来处理;
(4)Spider:负责处理所有的Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler;
(5)Item Pipeline:负责处理Spider中获取到的Item,并进行后期处理(详细分析、过滤、存储等)的地方;
(6)Downloader Middlewares:一个可以自定义扩展下载功能的组件;
(7)Spider Middlewares:一个可以自定义扩展的操作引擎和Spider中间通信的功能组件。
3.Python提供了大量用于编写网络爬虫程序的标准库和扩展库,请列举5个,并说说它们各自的特点。
(1)urllib库:它提供了urllib.request、urllib.response、urllib.parse和urllib.error四个模块,很好地支持了网页内容读取功能;它结合Python字符串方法和正则表达式,可以完成一些简单地网页内容爬取工作,也是理解和使用其他爬虫库地基础。
(2)Scrapy:它是一个非常好用地Web爬虫框架,非常适合抓取Web站点从网页中提取结构化的数据,并且支持自定义需求。
(3)BeautifulSoup是一个非常优秀的扩展库,可以用来从HTML或XML文件中提取我们感兴趣的数据,并且允许指定使用不同的解析器。
(4)Requests可以使用更简洁的形式来处理HTTP和解析网页内容。
(5)Selenium是一个用于Web应用程序测试的工具,可以用来驱动几乎所有的主流浏览器,完美模拟用户操作,从终端用户的角度测试应用程序。
二、请填写缺失的代码。
1. from bs4 import BeautifulSoup
file = open('samples/./htmlsample01.htm', 'rb')
html = file.read()
bs = BeautifulSoup(html,"html.parser")
# 获取title标签的所有内容
print( ① ) ①bs.title
# 获取head标签的所有内容
print( ② ) ②bs.head
# 获取第一个a标签的所有内容
print( ③ ) ③ bs.a
# 类型
print( ④ ) ④ type(bs.a)
2. from selenium import webdriver #导入库
from selenium.webdriver.common.by import By
browser = webdriver.Chrome() #导入引擎
url = 'https://www.taobao.com' #设置要访问的网站
① ①browser.get(url)
input_1 = ② #调用查找元素函数找到id为q的元素② browser.find_element(By.ID, 'q')
print( ③ ) #打印输出结果 ③ input_1
3. #导入相关的库
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
#绘制条形图
df= pd.DataFrame(np.random.rand(10,4),
① ) ①columns=['a','b','c','d']
② ②df.plot.bar()
③ ③ plt.show()

三、论述题
1.请谈谈抽取Word文档文本信息的案例的算法思路。
(1)切分文件上级目录和文件名。
(2)修改转化后的文件名。
(3)设置保存路径。
(4)加载处理应用,将Word转为txt文本。
(5)本地化保存文本。
四、程序设计题。
1.代码如下,请写出输出结果。
import numpy as np #导入数组
arr2 = np.array([[1,2],[3,4],[5,6]])
print("数组的维数:",arr2.ndim)
print("数组元素总个数:",arr2.size)
print("元素类型:",arr2.dtype)







![[Excel]vlookup的内在逻辑以及模糊检索](https://img-blog.csdnimg.cn/5dc77d29205d48169c5334beb17c3810.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5aSn5bedSVQ=,size_19,color_FFFFFF,t_70,g_se,x_16)