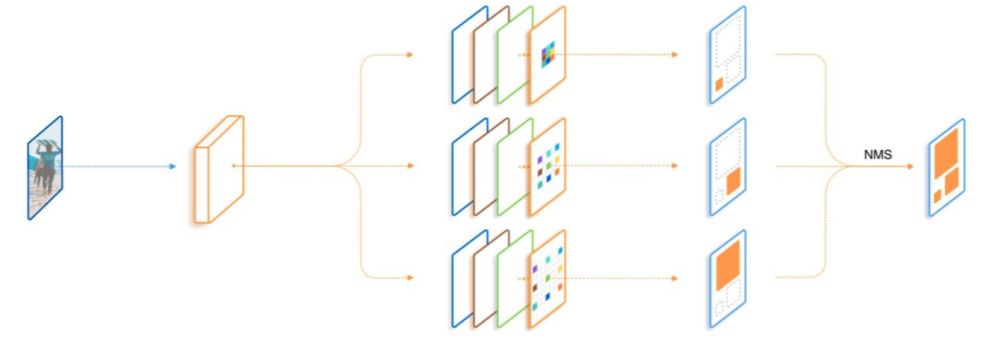
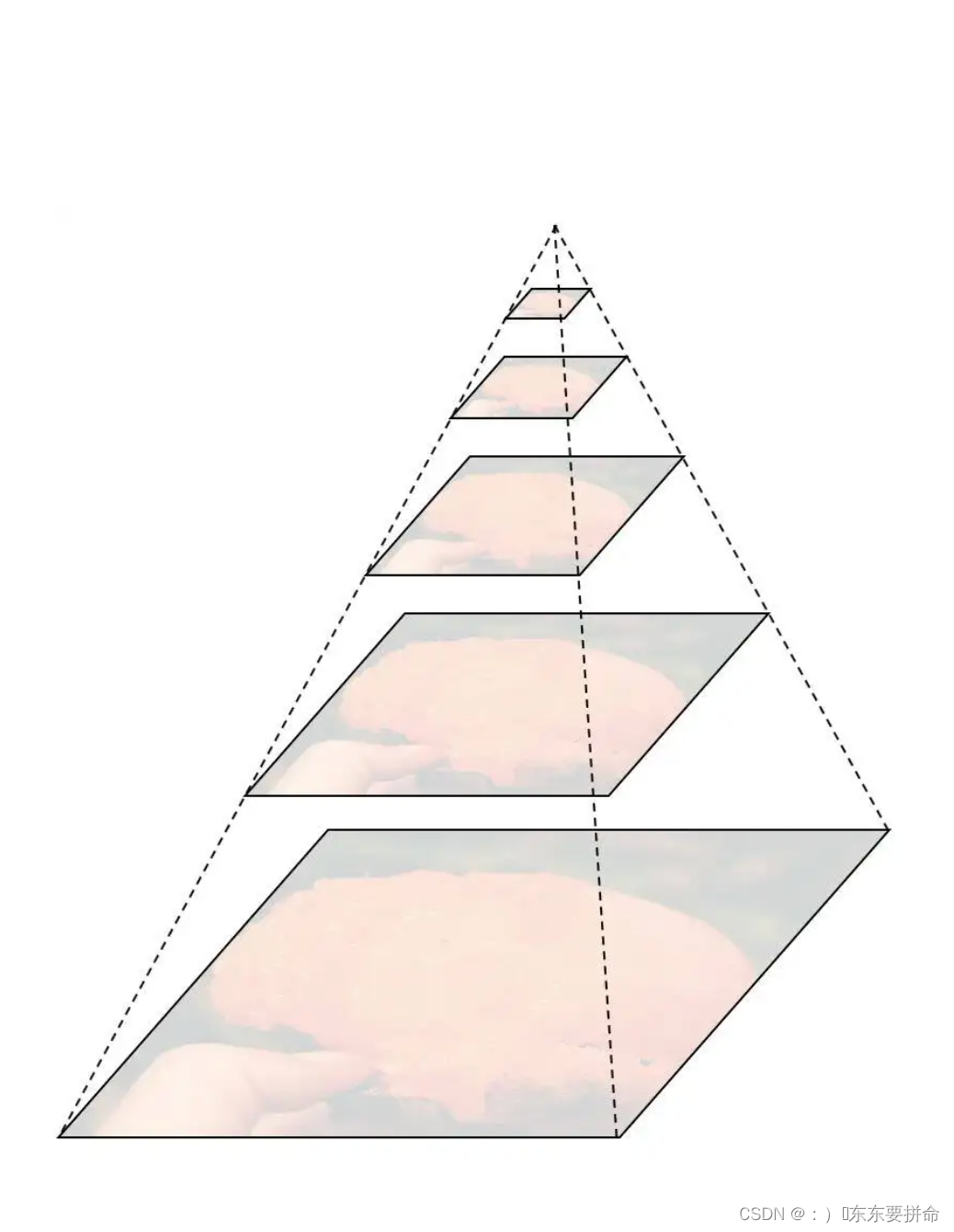
虽然VIT(vision transformer)模型提出后,Transformer在CV领域一路攻城拔寨,不断刷新由自己创下的记录,但VIT文章中所说明的视觉领域transformer很大程度上受transformer模型平方复杂度的限制而在大尺度图像上表现不佳的问题仍制约着视觉领域的发展。为了更好的将transformer与计算机视觉领域任务相结合,主流的方法有两种:(1)在窗口内计算局部注意力(2)池化注意力。后者的研究推动了多尺度视觉transformer(MViT)的发展。这种方法不再像VIT将图像以固定的比例分为一定数量的patch,而是采用高分辨率到低分辨率的多个阶段的特征层次。
在本文中,作者主要做了两个简单的技术改进来提高其性能。
1、创建一个强baseline,以改善两个轴的注意力:(a)使用分解位置距离进行平移不变的位置嵌入,以在Transformer块中注入位置信息。(b)残差池化连接,用于补偿注意力计算中池化的影响
2、采用一个标准的密集预测框架:带特征金字塔的Mask R-CNN(掩模区域卷积神经网络),将其用于目标检测和实例分割。
首先,我们回顾多尺度视觉transformer(MViT),该方案打破了Vit中固定比例尺度的思想,提出了多个尺度构建不同阶段的特征的思想,并通过池化操作大大削减了需要处理的数据量。具体而言,对输入序列X,有池化公式P使得:
![]()
从而获得attention机制中的query、key、value三个部分。此外,Pooling attention可以通过Pooling query Q来降低MViT不同阶段之间的分辨率,并通过Pooling key K和value V来显著降低计算和内存复杂度。
通过像swin-transformer这样,将图像的内容按尺度进行层叠处理,我们解决了patch过多时attention运算量过大的问题。再通过使用pooling层解决单个patch过大导致的计算QKV过于复杂的问题。将transformer应用到vision的计算复杂性从两方面得以下降。
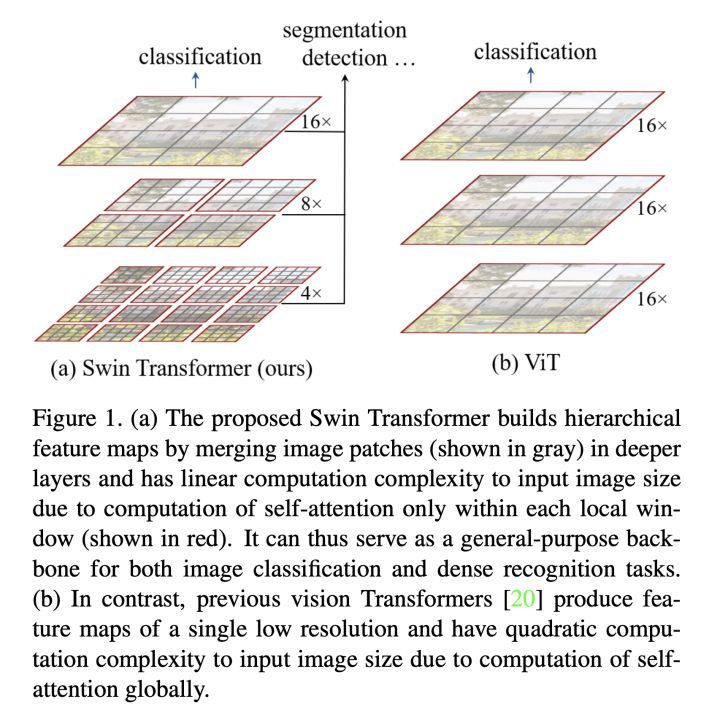
以上是MVIT的部分,而MVITv2主要做了两点改进使得网络训练效果更好,更快的收敛。
1、区别与先前采用的对每个绝对位置做embedding,本文对每条坐标轴进行embedding,使用每个点的坐标轴上的编码之和来表示位置编码。
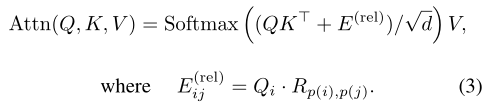
如上式中可见,为i,j处的位置编码,在本文中,它是这样得到的:
![]()
这样的好处是,可以使得位置编码计算复杂度与图像尺度之间呈线性关系,进一步降低计算复杂度。
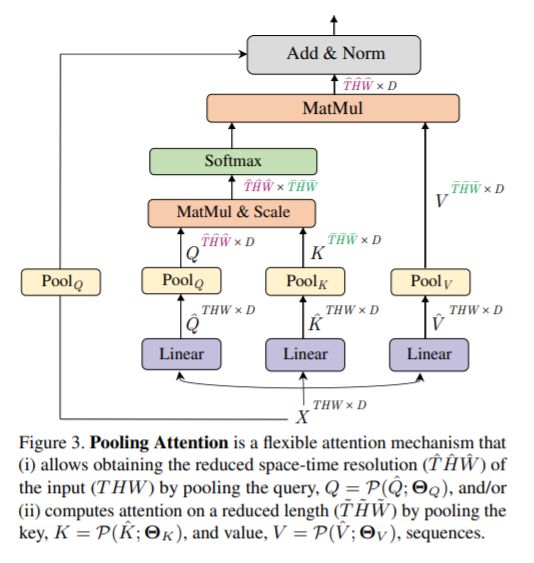
2、池化注意力下的残差链接
pooled attention对于减少注意力块中的计算复杂度和内存需求是非常有效的。MViT在K和V张量上的步长比Q张量的步长大,而Q张量的步长只有在输出序列的分辨率跨阶段变化时才下采样。这促使将残差池化连接添加到Q(pooled后)张量增加信息流动,促进MViT中pooled attention Block的训练和收敛。由此构建额外的残差连接,使得attention的结果表示为
![]()
修改后,网络架构如图:
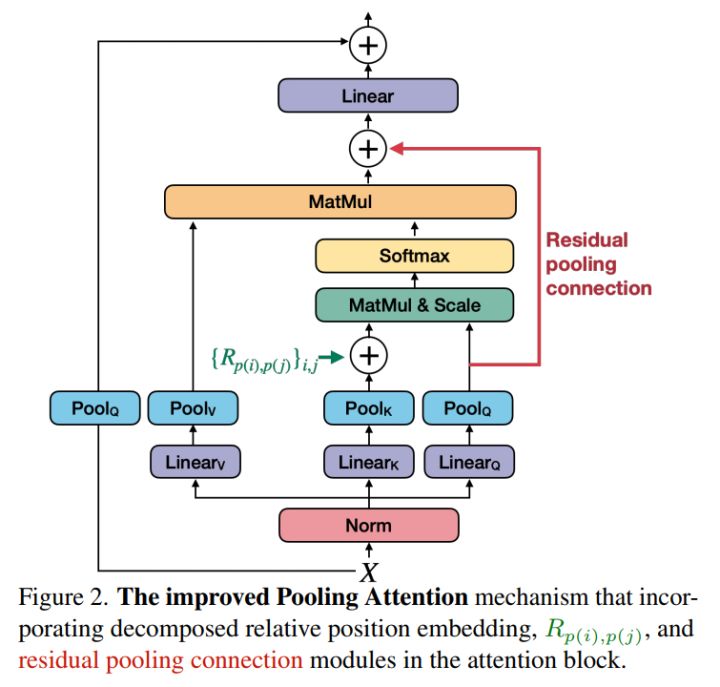
综合以上方法,MViTv2一定程度上解决了transformer应用到视觉领域的复杂度,并给出比较好的测试结果,作者以MViTv2作为特征提起结构,对图像分类、语义分割及视频理解三个重要的领域进行了测试,均得到了较好的效果,这说明池化注意力方法在视觉领域是可行的,并希望能够对计算机视觉领域的后续发展有所帮助。