随着互联网的不断发展,互联网企业的业务在飞速变化,推动着系统架构也在不断地发生变化。
如今微服务技术越来越成熟,很多企业都采用微服务架构来支撑内部及对外的业务,尤其是在高
并发大流量的电商业务场景下,微服务更是企业首选的架构模式。随着业务发展壮大,用户量暴
涨,单节点处理能力就会成为瓶颈,如果并发量居高不下,服务器很容易因负载过高而导致崩溃
宕机。出于高并发,高可用的考虑,项目就应该演变到分布式架构了。然而分布式环境下我们又
会面临更多的挑战需要去应对。比如:1、分布式系统中接口繁多,重试机制必不可少,接口幂等性问题?2、如果下单、付款分布在不同的服务上,如何保证跨服务事务?3、高并发场景下资源共享问题?4、分库分表后,引发了ID重复问题?那么,我们需要如何解决分布式呢?
文章目录
- 🔥分布式全局唯一ID
- 🔥分布式全局唯一ID解决方案
- 🔥什么是雪花算法SonwFlake
- 🔥雪花算法SonwFlake落地实现
- 🔥雪花算法SonwFlake落地实现之Mybatis Plus
🔥分布式全局唯一ID

何为 ID
日常开发中,我们需要对系统中的各种数据使用 ID 唯一表示,比如用户 ID 对应且仅对应一个人,商品 ID 对应且仅对应一件商品,订单 ID 对应且仅对应一个订单。
为什么需要分布式ID
随着系统数据量越来越大,单数据库压力太大无法维持性能,所以可能就需要变成一主多从这样读写分离,随着继续扩大一主多从也无法支撑了。这时就需要分库分表,这样的话就会出现不同库表之间的数据id不能再依赖数据库自增的id,而需要外部一种方式生成全局统一的唯一id。
分布式ID需要满足什么条件
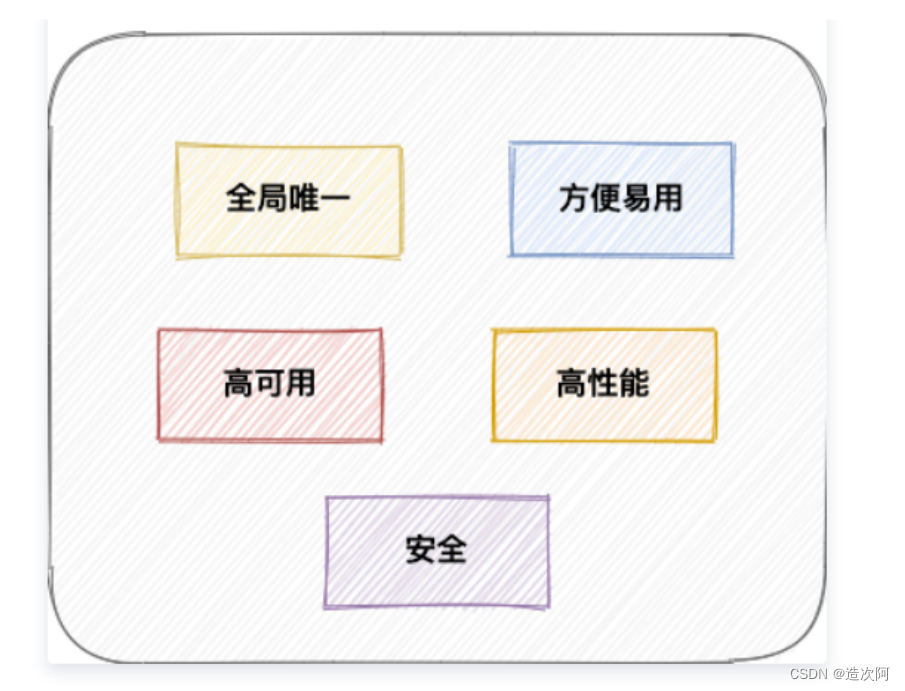
⭐唯一性:全局必须唯一。
⭐高性能:不能在生成id上浪费过多的时间,使其成为功能的性能瓶颈。
⭐高可用:必须保证可用性。
⭐趋势递增:这个不是必须的,但是最好还是满足,因为比如innodb索引就是按照键值排序的,所以有序性可以让维护索引的效率提高。
🔥分布式全局唯一ID解决方案

UUID
Java本身提供了UUID,这是一个唯一的字符串,它可以不依赖其他工具在本地生成。
优点
⭐代码实现简单
⭐本地生成,没有性能问题
⭐全球唯一的,数据迁移容易
缺点
⭐每次生成的ID是无序的,不满足趋势递增
⭐UUID是字符串,而且比较长,占用空间大,查询效率低
⭐ID没有含义,可读性差
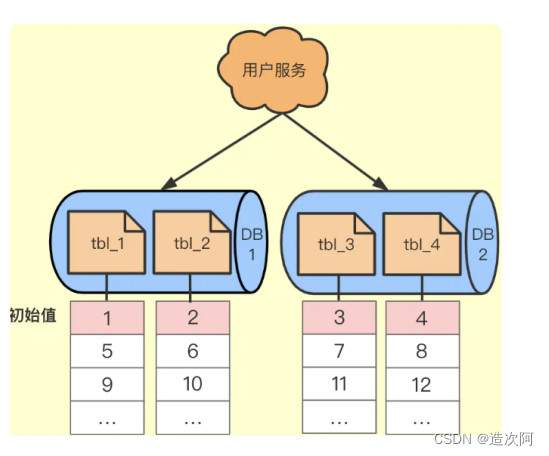
依靠数据库自增字段生成
一个数据库压力大就搞多个数据库,之后搞一个Step步长的概念,每个数据库的自增起始值不同,但是他们的增长Step相同。如下图所示。
优点
⭐返回的分布式ID是趋势递增的id唯一。解决了单点问题,即使一个宕机其他的还可以提供服务。
缺点
⭐单点压力还是很大,因为DB本身写操作就耗时间。最主要的问题还是扩容困难,比如要加一台DB3是很难加进来的,除非停机,将所有DB的id进行修改,同时修改步长。
号段模式
它没有采用新插入记录返回id的方案,而是一个业务类型就是一行数据,用一行数据来维护这个业务的自增id。服务来修改这行数据的max_id,比如当前max_id值是0,那么来给max_id加上1000,如果返回成功,就代表这个服务获得了1-1000这段分布式id,之后将这段缓存在服务内部,用完之后再来表中取。
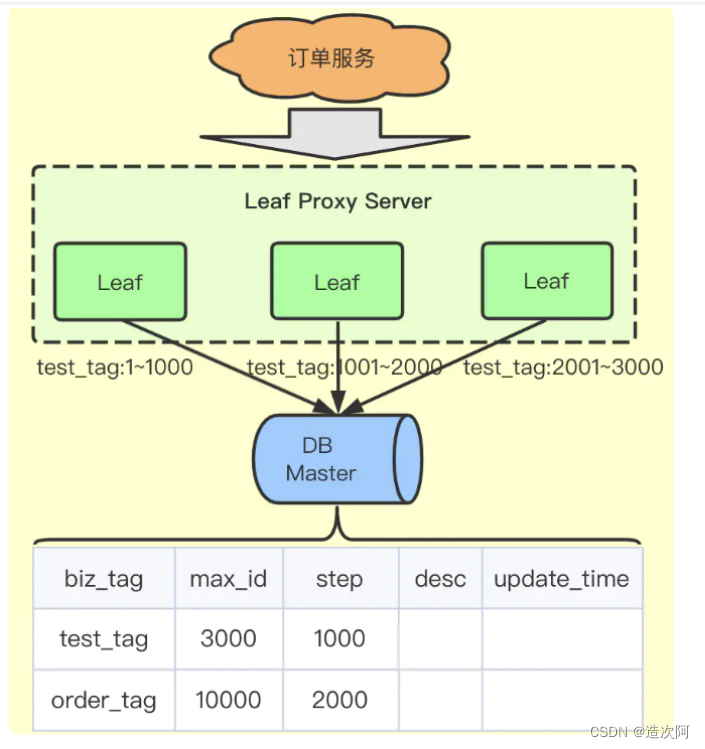
优点
⭐效率很高,db的压力减小,而且一张表可以维护很多业务的分布式id。
缺点
⭐复杂性提高,需要系统为了这个生成方案对号段进行缓存。
Redis自增key方案
通过incr命令让一个key自增,自增后的值作为分布式id。

优点
⭐有序递增,可读性强
⭐性能较高
缺点
⭐占用带宽,依赖Redis
雪花算法(SnowFlake)
SnowFlake生成的是一个Long类型的值,Long类型的数据占用8个字节,也就是64位。SnowFlake将64进行拆分,每个部分具有不同的含义,当然机器码、序列号的位数可以自定义也可以。

优点
⭐本地生成,不依赖中间件。
⭐生成的分布式id足够小,只有8个字节,而且是递增的。
缺点
⭐时钟回拨问题,强烈依赖于服务器的时间,如果时间出现时间回拨就可能出现重复的id。
🔥什么是雪花算法SonwFlake

Snowflake常称为雪花算法,是Twitter开源的分布式ID生成算法,生成后是一个64bit的long型数值,组成部分引入了时间戳,基本保持了自增。
雪花算法作用
⭐生成的所有的id都是随着时间递增
⭐分布式系统内不会产生重复的id
SnowFlake算法优点
⭐高性能高可用:生成时不依赖于数据库,完全在内存中生成
⭐高吞吐:每秒钟能生成数百个的自增ID
⭐ ID自增:存入数据库中,索引效率高
SnowFlake算法的缺点
依赖系统时间,如果系统时间被回调,或者改变,可能会造成ID冲突或者重复
雪花算法组成

注意:
⭕1位,不用,二进制中的最高位是符号位,1表示负数,0表示正数,由于我们生成的雪花算法都是正整数,所以这里是0 。
⭕41位,这里的时间戳是表示的是从起始时间算起,到生成id时间所经历的时间戳,也就是(当前时间戳-起始时间戳(固定)) 这里一共是41位,范围就是(0~ 2^41-1),这么大的毫秒数转化成时间就是大约69年 。
⭕10位,这里的10位代表工作机器id,一共可以部署在(2^10=1024)台机器上面,10位又可以分为前面五位是数据中心id(0~31),后面五位是机器id(0-31) 。
⭕共12位,序列位,一共可用(0 ~ 2^12-1)共4096个数字。
🔥雪花算法SonwFlake落地实现

Hutool简介
Hutool是一个小而全的Java工具类库,通过静态方法封装,降低相关API的学习成本,提高工作效率,使Java拥有函数式语言般的优雅,让Java语言也可以“甜甜的”。
引入相关依赖
hutool工具包已经提供雪花算法ID生成的工具类。
<!--
https://mvnrepository.com/artifact/cn.hutool/hu
tool-all -->
<dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.13</version>
</dependency>
Snowflake
分布式系统中,有一些需要使用全局唯一ID的场景,有些时候我们希望能使用一种简单一些的ID,并且希望ID能够按照时间有序生成。Twitter的Snowflake 算法就是这种生成器。
//参数1为机器标识
//参数2为数据标识
Snowflake snowflake = IdUtil.getSnowflake(1,
1);
long id = snowflake.nextId();
//简单使用
long id = IdUtil.getSnowflakeNextId();
String id = snowflake.getSnowflakeNextIdStr();
雪花算法SpringBoot引用
config文件
package com.example.demo.config;
import cn.hutool.core.lang.Snowflake;
import cn.hutool.core.net.NetUtil;
import cn.hutool.core.util.IdUtil;
import lombok.extern.slf4j.Slf4j;
import
org.springframework.stereotype.Component;
import javax.annotation.PostConstruct;
@Slf4j
@Component
public class IdGeneratorSnowflake {private long workerId = 0; //第几号机房private long datacenterId = 1; //第几号机器private Snowflake snowflake =
IdUtil.getSnowflake(workerId, datacenterId);@PostConstruct //构造后开始执行,加载初始化工作public void init(){try{//获取本机的ip地址编码workerId =
NetUtil.ipv4ToLong(NetUtil.getLocalhostStr());log.info("当前机器的workerId: " +
workerId);}catch (Exception e){e.printStackTrace();log.warn("当前机器的workerId获取失败 -
---> " + e);workerId =
NetUtil.getLocalhostStr().hashCode();}}/**
分布式全局唯一ID实现_雪花算法SonwFlake落地实现之
Mybatis Plus
初始化工程* 生成id* @return*/public synchronized long snowflakeId(){return snowflake.nextId();}
}
🔥雪花算法SonwFlake落地实现之Mybatis Plus

初始化工程
<dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-bootstarter</artifactId></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>com.baomidou</groupId><artifactId>mybatis-plus-bootstarter</artifactId><version>3.4.2</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connectorjava</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-startertest</artifactId><scope>test</scope><exclusions><exclusion><groupId>org.junit.vintage</groupId><artifactId>junit-vintageengine</artifactId></exclusion></exclusions></dependency></dependencies>
编写相关配置
在 application.yml 配置文件中添加 MySQL 数据库的相关配置:
spring.datasource.driver-classname=com.mysql.cj.jdbc.Driver
spring.datasource.url=jdbc:mysql://192.168.66.1
00:3306/test?serverTimezone=UTC
spring.datasource.username=root
spring.datasource.password=123456
开启MapperScan扫描
在 Spring Boot 启动类中添加 @MapperScan 注解,扫描 Mapper 文件夹:
@SpringBootApplication
@MapperScan("com.itbaizhan.sonwflake.mapper")
public class Application {public static void main(String[] args) {SpringApplication.run(Application.class,
args);}
}
编码
编写实体类 User.java
@Data
public class User {@TableId(type = IdType.ASSIGN_ID)// 雪花算法private Long id;private String name;private Integer age;private String email;
}
编写Mapper
public interface UserMapper extends
BaseMapper<User> {
}
添加测试类
@Testvoid createUser() {User user = new User();user.setName("张三");user.setAge(18);user.setEmail("23472@qq.com");userMapper.insert(user);}