CLIP 改进工作串讲(下)
本文为 CLIP 改进工作串讲(下)【论文精读】 的学习笔记。
图像生成
最近一年图像生成领域扩散模型大火,尤其是文本生成图像,DALL-E、imagen 等工作层出不穷,有机会专门再写。这里就只介绍一篇 SIGGRAPH 2022 的最佳论文:CLIPasso。
CLIPasso
Paper:CLIPasso: Semantically-Aware Object Sketching
Code:https://clipasso.github.io/clipasso/
简介
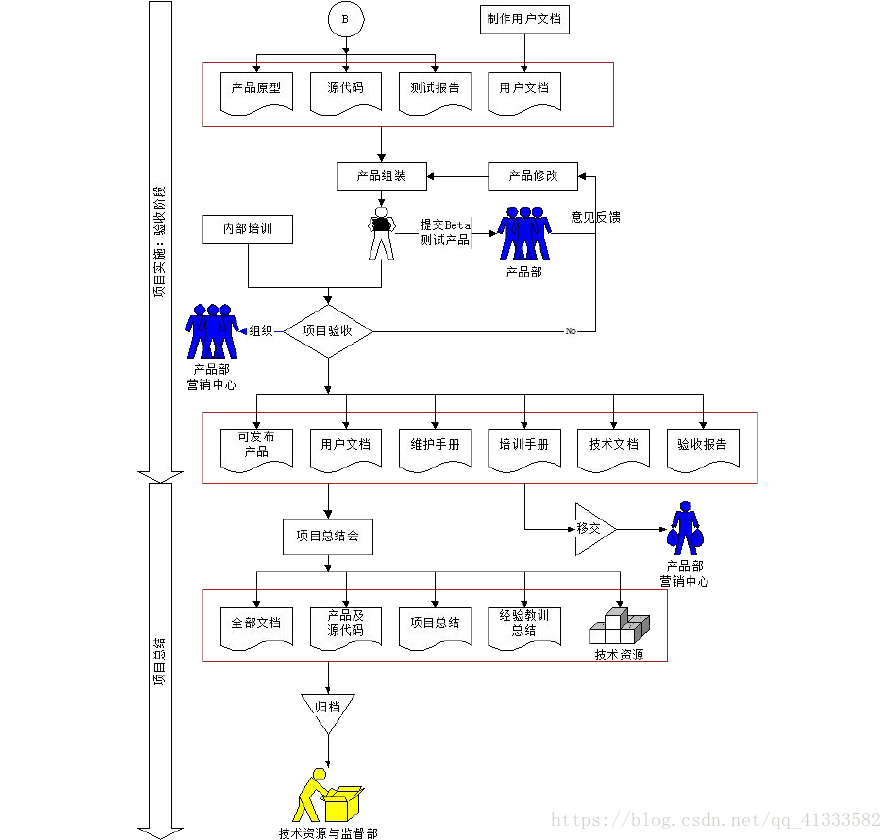
CLIPasso 要做的事情如图 1 所示,要由一张语义清晰的图像生成其对应的抽象简笔画,要求用较少的比划勾勒出原图的轮廓,并且与原图具有相同的语义内容,即原图是头公牛,生成的抽象简笔画也要能看出来是头公牛。

方法
生成简笔画的方法肯定不是直接做图到图的生成,这里是使用图形学中的贝塞尔曲线来完成简笔绘画。贝塞尔曲线通过定义平面上的几个点来确定一条曲线,是图形学方向的内容,具体不做展开。
CLIPasso 的模型框架如图 2 所示,中间的 Rasterizer 是图形学方向根据参数绘制贝塞尔曲线的一种方法,本文方法的创新点主要在损失函数和初始化方法两个方面。
损失函数
简介中提到过,生成的简笔画有两个要求:一是要在语义上与输入图像一致,即马还是马、牛还是牛;二是生成的简笔画的几何轮廓也要与原图一致,不能虽然还是马,但是马头的朝向反了,或者是趴着的马。
在 CLIPasso 中,这两个要求分别由两个损失函数几何损失 L g L_g Lg 和语义损失 L s L_s Ls 来保证。
- 语义损失的思路与之前介绍过的 ViLD 的只是蒸馏的思想类似,要让模型提取到的图像特征和 CLIP 图像编码器提取的特征接近,从而在语义上保证原图和简笔画图都是马。这样做的依据是 CLIP 能做到对无论是自然图像、简笔画图等还是其他任何风格的图像,都能准确提取出语义特征,这种能力来自于 CLIP 400M 规模的训练数据。
- 几何损失类似于感知损失,是在约束模型前基层的的特征图。因为在模型的前几层,学习到的还是相对低层的几何纹理信息,而非高层语义信息,因此约束浅层特征可以保证原图和简笔画图的几何轮廓接近。
显著性 (saliency) 图用来对贝塞尔曲线参数进行初始化,作者发现,如果完全随机初始化贝塞尔曲线的参数,会使得模型训练很不稳定。因此他们使用显著性图来辅助贝塞尔曲线参数的初始化,从语义明确的区域采点进行初始化,改善了训练的稳定性。

总结
实验部分就不一一列举了,有兴趣可以去原文查看。CLIPasso 简笔画方法的两个突出优势一是可以适应任意语义类别的输入图像。通过 CLIP 模型的帮助,简笔画的训练不再局限于数据集中固有的几个类别;二是 CLIPasso 可以指定最终出图的比划数。
视频理解
CLIP4clip
Paper:CLIP4Clip: An Empirical Study of CLIP for End to End Video Clip Retrieval
Code:https://github.com/ArrowLuo/CLIP4Clip
简介
CLIP4clip 做的是视频文字检索,这是一篇实验性质的论文,旨在探索 CLIP 模型在视频领域的应用。
方法及实验结果
既然是实验性质的论文,那我们直接来看 CLIP4clip 用哪几种模型结构进行了实验(如图 3 所示)。视频相较于图像无非就是对了一维时间维度,在 CLIP 训练时图像文本对的图像特征和文本特征是一对一的,但是在视频中,图像特征有多个(分别对应不同帧),要与文本特征计算对比损失,需要将这些特征进行融合。这里融合的方式无非就还是视频领域 early/late fusion 那一套 (不熟悉的可参考: 深度学习时代的视频理解综述),即图 3 (b) 中的三种融合方式:
- 直接平均池化(图中 parameter-free type):最简单粗暴的方式就是直接对多帧视频特征直接进行平均池化,这样做的有点是简单直接,并且是无参的。缺点也很明显,直接取平均的方式消解了视频帧之间的时序信息,缺失掉时序信息会使得一组视频帧表达的意思改变甚至反转(
正所谓 “倒放罢了”)。即使如此,直接平均池化的方式依旧是最常用的方式,它简单直接,甚至有时效果更好。 - 时序学习后融合(图中 sequential type):要像考虑到平均池化不能建模的时序信息,一般的想法就是用 Transfomer/LSTM 这种时序建模网络。这是一种 late fusion 的方式,即先各自进行特征处理,再进行特征融合。
- 一起进行学习(图中 tight type):也是用 Transformer 对时序进行建模,与上一种方法的区别是这里是直接将文本特征和图像帧特征一起送到 Transformer 中进行学习,即 early fusion。

原文在五个视频文字检索数据集上都进行了实验,结果类似,这里只看一个 MSR-VTT 的结果。如图 4 所示,在训练数据量较小(左侧 7K)时,平均池化表现最好,当训练数据量增强(右侧 9K),对时序进行建模的方法超过了平均池化的结果。

论文最后给出了共四点 insights:
- 图像特征可以很好地迁移到视频特征
- 要将图像的特征提取器迁移到视频领域,最后做一下 post-pretrain,即在图像数据上 pretrain 之后,再用视频数据 pretrain 一下,毕竟图像数据与视频数据还是有所区别
- 3D patch + late fusion 的方式在视频文字检索领域比较有前途
- CLIP 模型用于视频文字检索对学习率极为敏感
ActionCLIP
Paper:ActionCLIP: A New Paradigm for Video Action Recognition
Code:https://github.com/sallymmx/actionclip
简介
视频领域另一个很重要的任务是动作识别,动作识别是给定一段视频,模型要预测出该段视频内的动作,本质上是一个分类任务。本文借助 CLIP 中对比学习的思想,构建了一个多模态的动作识别模型。本文方法与之前单一模态的动作识别方法的对比如图 5 所示。
在单一模态的动作识别方法中,整个流程与图像分类任务类似,都是先对数据抽取一个特征,然后通过线性层分类器得到预测结果,再与 one-hot 标签计算交叉熵损失即可,动作识别与图像分类流程上唯一的区别就是视频数据比图像数据多了一维时间维,需要对多帧视频特征进行融合。动作识别任务的一个难点是标签很难组织,对于分类来说,标签就是语义清晰的物体类别(如猫、狗、飞机)名词,而在动作分类中,标签动名词组合的短语,如开门(open the door),这时就很容易出现语义模糊性,比如 open 这个词还可以用于 open your mind 等完全不用语义的内容。因此动作识别可能存在的标签类别空间是接近无穷的,如果想要将这些类别一一标注出来几乎是不可能的,即使标注完成,在这么多类的情况下,softmax 可能就没有无法工作了。因此,如何实现文本监督的训练,使得模型能够通过理解文本语义来理解想要分类的动作,实现 zero-shot 的动作识别,是一个需要解决的问题。
针对这个问题,自然就能想到通过 CLIP 中图像文本对这种自监督对比学习的方式。本文的框架(图 5 下方)正是如此。本文的创新点主要有两个,一是如何提取视频特征并与文本特征计算相似度;二是视频与文本对比学习的损失函数。

方法
将图像文本对换成视频文本对进行对比学习,需要解决的问题有两个,一是如何提取视频的特征,二是如何计算视频文本对的对比损失。
先来看第二点,不同于 CLIP 中的图像文本对之间一对一的对比关系,视频文本对中可能出现多个一段文本与多段视频相关,这时在目标相似度矩阵中,就不止有对角线元素是正样本(如图 5 所示)。解决方法也很简单,只要将交叉熵损失换成 KL 散度,约束两个分布的相似度即可。
再来看第一点,如何提取视频特征,并与文本特征计算相似度。本文网络结构图如图 6 所示,乍看之下有些复杂,但实际上还是在 CLIP 多模态相似度计算的框架之下,结构创新主要集中在几个 prompt。prompt 是最近 NLP 领域大火的一个概念,可以理解为通过设计或生成模板来辅助预测,在 CLIP 原论文中,使用 “A photo of {category}.” 来进行 zero-shot 图像分类的方法就是一种 prompt。关于 NLP 中的 prompt 稍详细的简介推荐这篇博客:NLP新宠——浅谈Prompt的前世今生。
本文中,文本特征提取和视频特征提取都有 prompt 的设计,但实际上,只有文本编码器这边的 prompt 与现在常提到的 prompt 概念是一致的,图像编码器这边的 prompt 更多可以认为是一种 adapter 来调整特征尺寸或添加一些信息,或许是为了名称与文本 prompt 对齐,才叫做 prompt 这个名字。
文本prompt
本文中文本 prompt 的是手工设计的 prompt,如图6 (d) 所示,本文通过 prefix/cloze/suffix prompt 三种模板分别在句子前/句子中/句子添加动作类别信息,作为文本编码器的输入。
视觉prompt
本文图像编码器这边的三个 prompt 与 prompt 的原义关系不大,且认为是 ViT 中的几个网络结构即可。
- pre-network prompt:图6 © 中展示的是 pre-network prompt,实际上就是将视频帧的时间和空间上的图像块加上位置编码,将时序信息和位置信息添加到输入中;
- in-network prompt:图6 (d) 展示的是 in-network prompt,实际上是一种时序上的 shift 操作。shift 是一种常用的技术,它在特征图上做一些移动,在保持保持零额外开销的情况下增强模型的建模能力,在视频领域的 TSM、视觉 Transformer 中的 swin 都有相关的应用。
- post-network prompt:图6 (e) 展示的是 post-network prompt,这一部分就与上面介绍的 CLIP4clip 一模一样了(连名字、简写都一样),就是三种将多帧图像特征融合为视频特征的三种方式。

消融实验
实验部分着重看几个消融实验。
如图 7 所示,该消融实验意图探究预训练对于动作分类任务是否有用。整体的结论肯定是有用的,无论是 NLP,还是 CV,预训练基本上已经是基本操作。这里想提的一个点是,观察表格结果发现,文本特征提取器的预训练初始化似乎没有那么重要,至少远没有图像的预训练初始化重要。这也印证了近年来多模态领域研究的一个趋势:大家都把研究的重心放在视觉这边的特征提取,视觉-语言联合模型的初始化也都是用 ViT 的预训练权重初始化。

图 8 所示的消融实验意图验证本文网络结构部分的设计,即文本 prompt 和视觉 prompt 有没有用。可以看到,文本 prompt 提升十分有限。在视觉 prompt 中,in-network prompt 即 shift 模块,不仅没提升,甚至还降了接近三个点;而 post-network prompt 还是有比较明显的提升。与视频文本检索领域的 CLIP4clip 的观察有所不同的是,动作识别领域的 ActionCLIP 平均池化的融合方式与时序建模融合方式有了较大的差距。这是因为视频文本检索领域的数据集都太小,微调训练体现不出时序建模的作用,而在动作识别领域,当有了充分的数据来进行微调之后,时序建模还是很有用的。

其他方向
多模态 CLIP-ViL
Paper:How Much Can CLIP Benefit Vision-and-Language Tasks?
Code:https://github.com/clip-vil/CLIP-ViL
本文也算是一篇实验性质的论文,作者将 CLIP 的预训练参数用来初始化 ViL 模型,然后再各种视觉-文本多模态任务上进行微调,测试结果。
语音 AudioCLIP
Paper:AudioCLIP: Extending CLIP to Image, Text and Audio
Code:https://github.com/AndreyGuzhov/AudioCLIP
视频数据本身就是一种丰富的多模态数据,其中既有图像帧,也有语音和文本标注。本文结构图如图 8 所示,将图像、文本、语音三种模态特征分别提取特征,然后两两进行跨模态的对比学习。

3D PointCLIP
Paper:PointCLIP: Point Cloud Understanding by CLIP
Code:https://github.com/ZrrSkywalker/PointCLIP
3D 想要利用 2D 图像数据训练 CLIP 模型,关键就是要将 2D 与 3D 联系起来。本文(流程图如图 9 所示)通过现将 3D 点云投射为多张 2D 的深度图实现了这种联系。

DepthCLIP
Paper:Can Language Understand Depth?
Code:https://github.com/Adonis-galaxy/DepthCLIP
本文试图探究 CLIP 模型能否理解图像的深度。在之前的一些应用和改进工作中,都是在利用 CLIP 出色的语义识别能力,由于是通过对比学习的方式在大量的图像文本对上进行训练,因此语义识别能力是 CLIP 模型最强的地方。而对于 “深度” 这种抽象的概念,对比学习的方式很难建模。
本文的流程图如图 10 所示,作者直接将深度估计这个回归问题通过指定深度区间转化为分类问题,然后构造 prompt,去预测每个像素的深度。这里就与 LSeg 有点像了,都是一个像素级的分类问题。

总结
CLIP 在目标任务相关工作按照改动程度由小到大来分大概有以下三种:
- 直接用 CLIP 模型的预训练特征,与目标任务的特征进行融合(点乘、拼接等),还是按照目标任务进行训练。只是借用 CLIP 提取的比较好的特征。
- 将 CLIP 作为教师模型来进行知识蒸馏(浅/深层特征蒸馏),协助训练目标任务。
- 借鉴 CLIP 多模态对比学习的思想,定义目标任务的正负样本对,从而实现 zero-shot 的推理。
Ref
- NLP新宠——浅谈Prompt的前世今生