转载请备注来源
联系我:UVE6MjI4MjY3OTAwNA==
文章目录
- 练武
- 好看的维吾尔族小姐姐
- 人生之路
- 汤姆历险记
- 菜鸟黑客-1
- 菜鸟黑客-2
- 通信方式
- mystery of bits
- 消息传递
- 你相信AI吗?
- 擂台
- Guess_RSA
- 雪豹
- 哦?摩斯密码?
- ඞ
- G9的钢琴曲
- BNG
- 听你心跳里的狂
- Brain Games
- Guess!Where?
练武
好看的维吾尔族小姐姐
解压改后缀png,改高,看到娜扎🥺
哦不,是看到一个条形码

镜像翻转后的 datamartix

字符串倒置后unicode转ascii

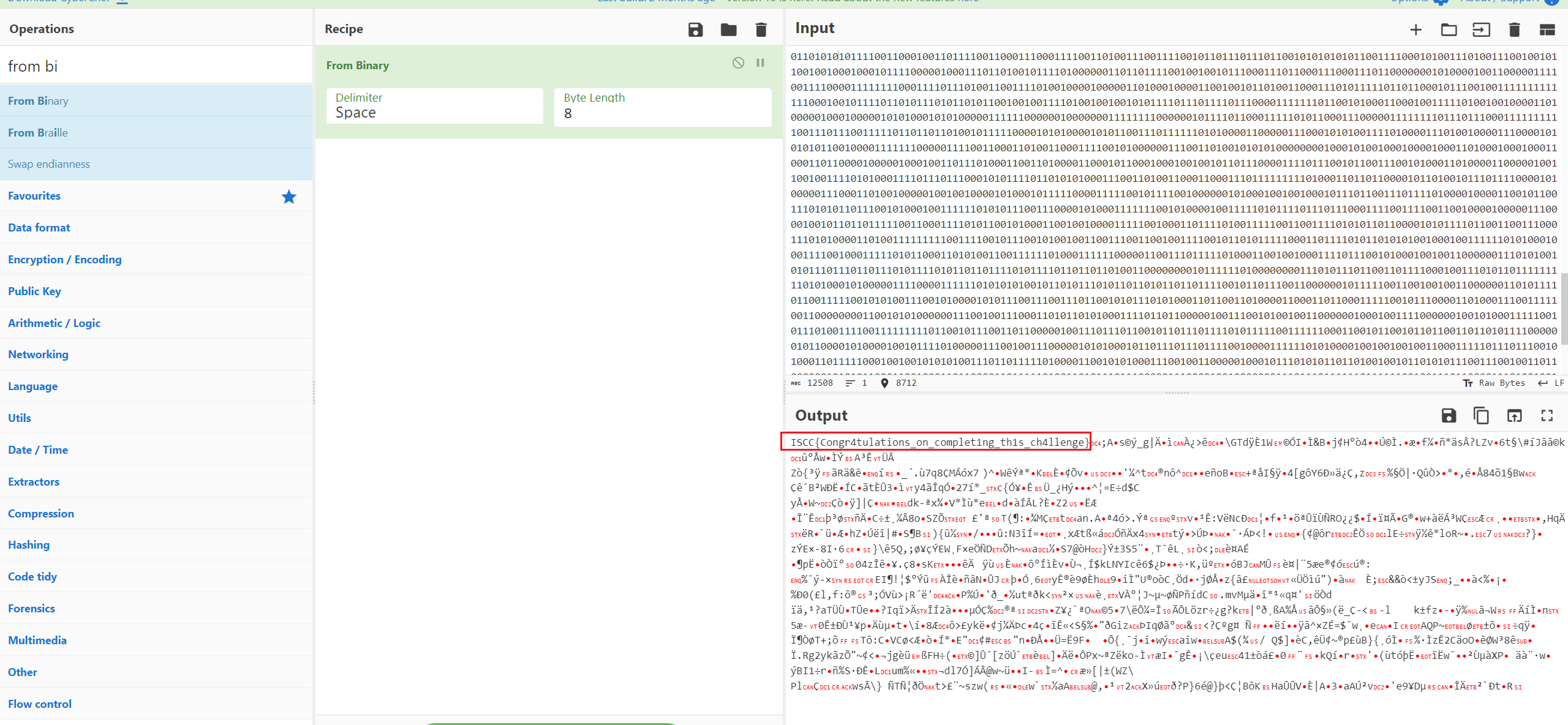
ISCC{you_got_it_welldone!}
人生之路
人生之路充满着迷茫,也许成功的密码就在脚下,也许需要我们行走四方,也许我们旅途的记录会发生整体漂移,也许我们已经记不清走了多少路,分不清旅途的方向(flag以大写字母组成)。
提示1:windows下大图标模式查看,成功的密码就在脚下!
挺抽象的一道题,根据hint压缩包密码就是jpg的名字人生之路.jpeg
得到
rNoWgNoWrN oNgWrNgWoN oNgNrN oNgNrN oWgWoWrWgWrW gNrNkNoN rNoWgNoWrN oNgWrNgWoN grNkoWkrWgoN rNoWgN rNoNgNoWrN rNoNgWrNoNgWrN oNgNrNkWoW gNkNrNgWoN oNgNrNkWoW gNkWrWrkWgoWgrW goWgWkWrWkoWgrWgW rNgoNrN oNgWrNgWoN rNoNgWrNoNgWrN rWgWrWoWgWoW
凯撒14(纯脑洞没理由)
dZaIsZaIdZ aZsIdZsIaZ aZsZdZ aZsZdZ aIsIaIdIsIdI sZdZwZaZ dZaIsZaIdZ aZsIdZsIaZ sdZwaIwdIsaZ dZaIsZ dZaZsZaIdZ dZaZsIdZaZsIdZ aZsZdZwIaI sZwZdZsIaZ aZsZdZwIaI sZwIdIdwIsaIsdI saIsIwIdIwaIsdIsI dZsaZdZ aZsIdZsIaZ dZaZsIdZaZsIdZ dIsIdIaIsIaI
其中wasd对应上左下右,IZ对应12即位移数,如果wasd两个连着,例如wa对应坐上,sd对应右下
以sZwIdIdwIsaIsdI为例:
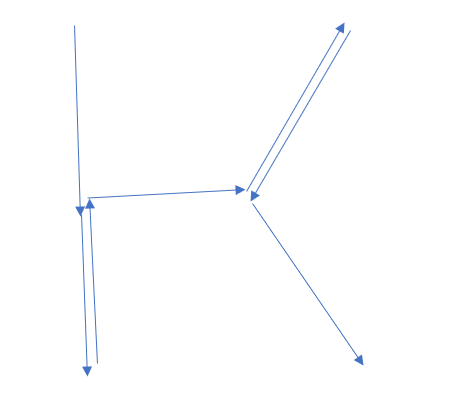
全部画出来就有flag了,整理出来全部的对应关系,有几个字符非常抽象,嫌麻烦可以写个字典跑
A sZwZdZsIaZdZsI
B sZwZdZsZaZdZsZaZ
C aZsZdZ
D sZwZdZsZaZ
E dZaZsIdZaZsIdZ
F dZaZsZaIdZ
G aZsZdZwIaI
H sZwIdZwIsZ
I dZaIsZaIdZ
J dZaIsZaI
K sZwIdIdwIsaIsdI
L sZdZ
M wZsdIwdIsZ
N wZsdZwZ
O sZdZwZaZ
P sZwZdZsIaZ
Q aZwZdZsZsdI
R sZwZdZsIaZdZsI
S aZsIdZsIaZ
T dZaIsZ
U sZdZwZ
V sIsdIdwIwI
W sdZwdZsdZwdZ
X sdZwaIwdIsaZ
Y sdIwdIsaIsI
Z dZsaZdZ
汤姆历险记
文件尾提取一串密文,foremost提取一个压缩包
密文乱序,数量多,也没啥规律,直接字频,结果很规律
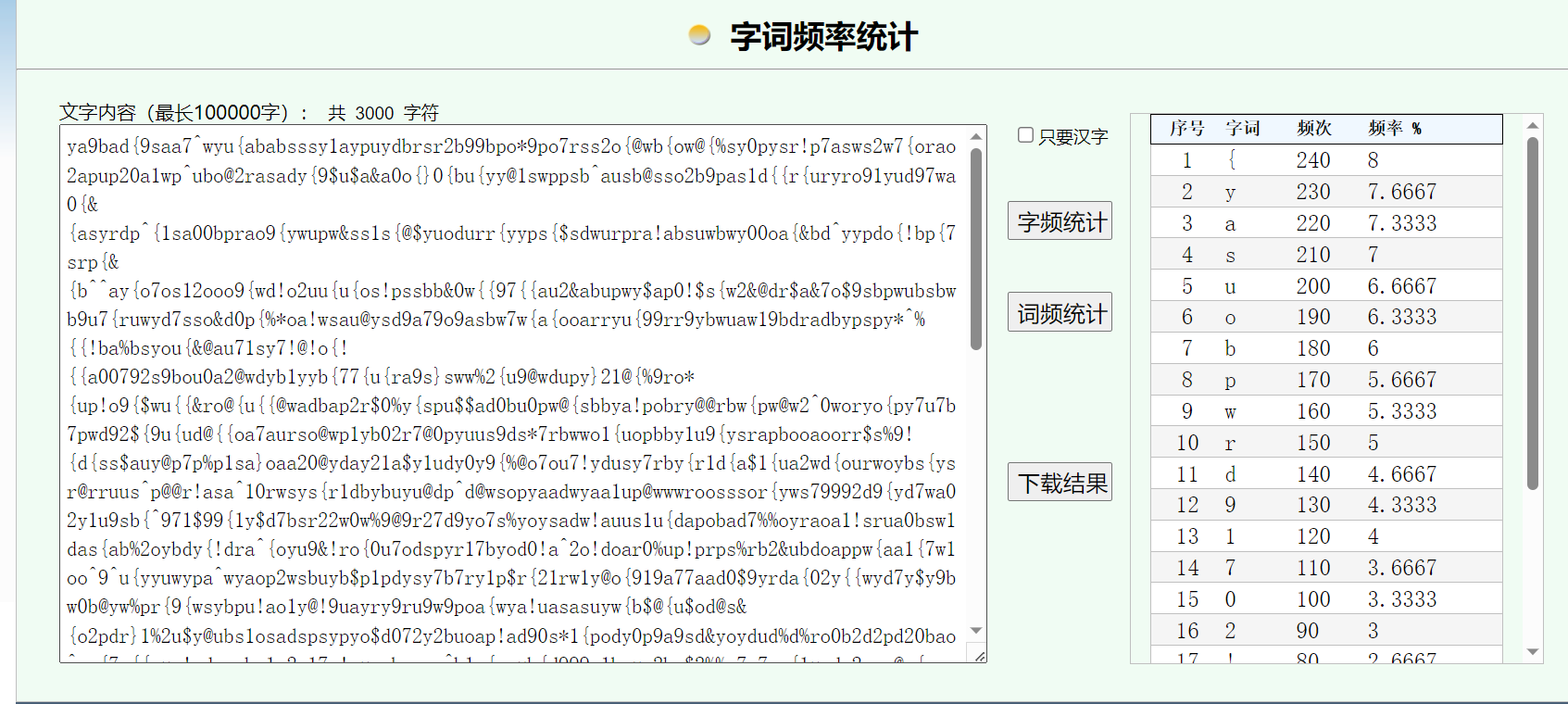
{yasuobpwrd91702!@$%^&*}
压缩包解出来一个word文件
发现行间距不固定,有1有1.5,1倍行距作为.,1.5倍行距作为-,换行作为分割

得到摩斯
.. ..--- ... ----- -.-. ..--- -.-. ...--
解得i2s0c2c3
然后根据一开始所给的字典单表替换即可
path = "dictionary.txt"replaces = {}
key = "ISCC{i2s0c2c3}"
flag = ''
with open(path, "r") as f:lines = f.readlines()for line in lines:after, out = line.strip().split(":")replaces[after] = outfor char in key:if char in replaces:flag += replaces[char]
菜鸟黑客-1
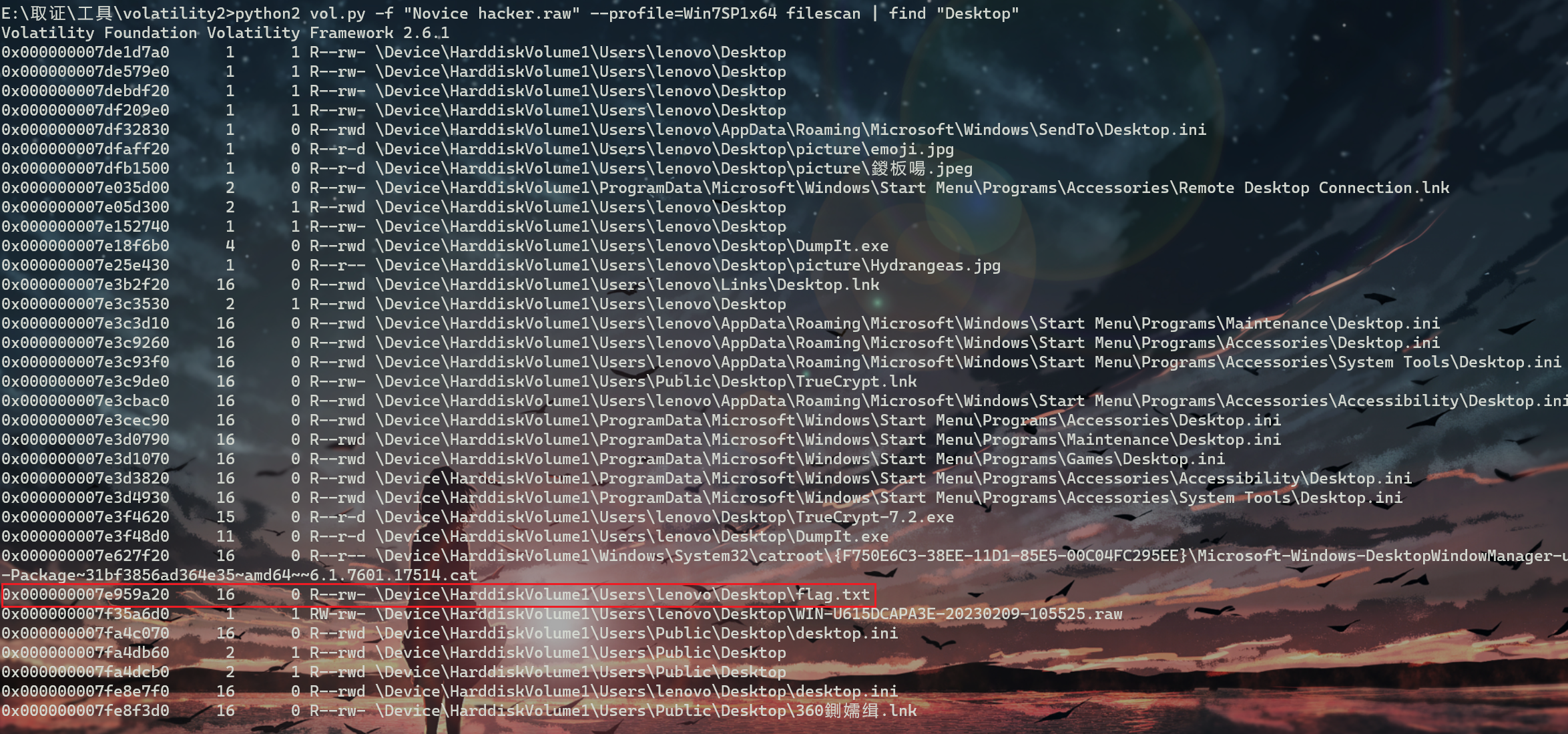
python2 vol.py -f "Novice hacker.raw" --profile=Win7SP1x64 filescan | find "Desktop"
桌面上找到flag.txt,linux下find命令改成grep即可
python2 vol.py -f "Novice hacker.raw" --profile=Win7SP1x64 dumpfiles -Q 0x000000007e959a20 -D ./
vol不知道为啥dump不下来
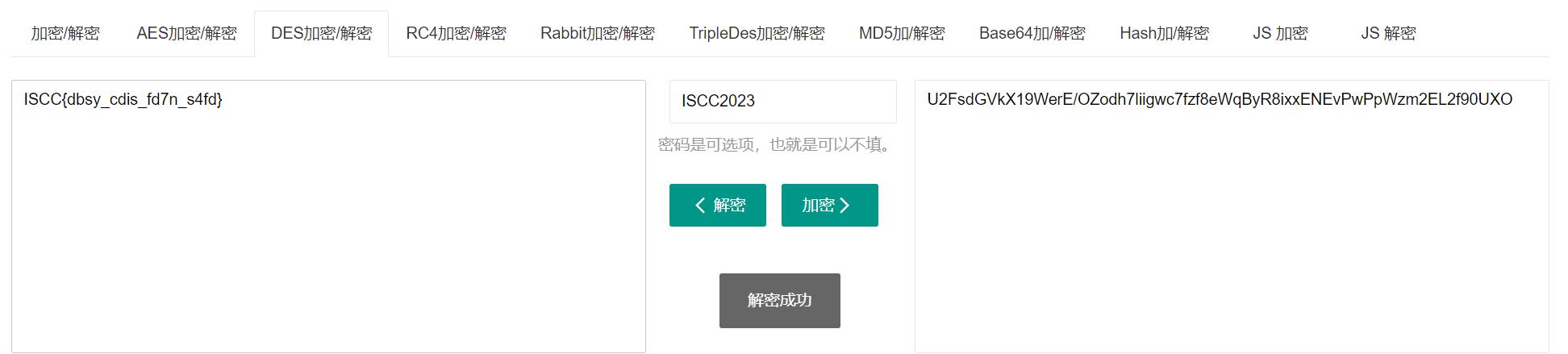
换R-studio一把梭,还是R-studio香。得到DES密文
U2FsdGVkX19WerE/OZodh7liigwc7fzf8eWqByR8ixxENEvPwPpWzm2EL2f90UXO
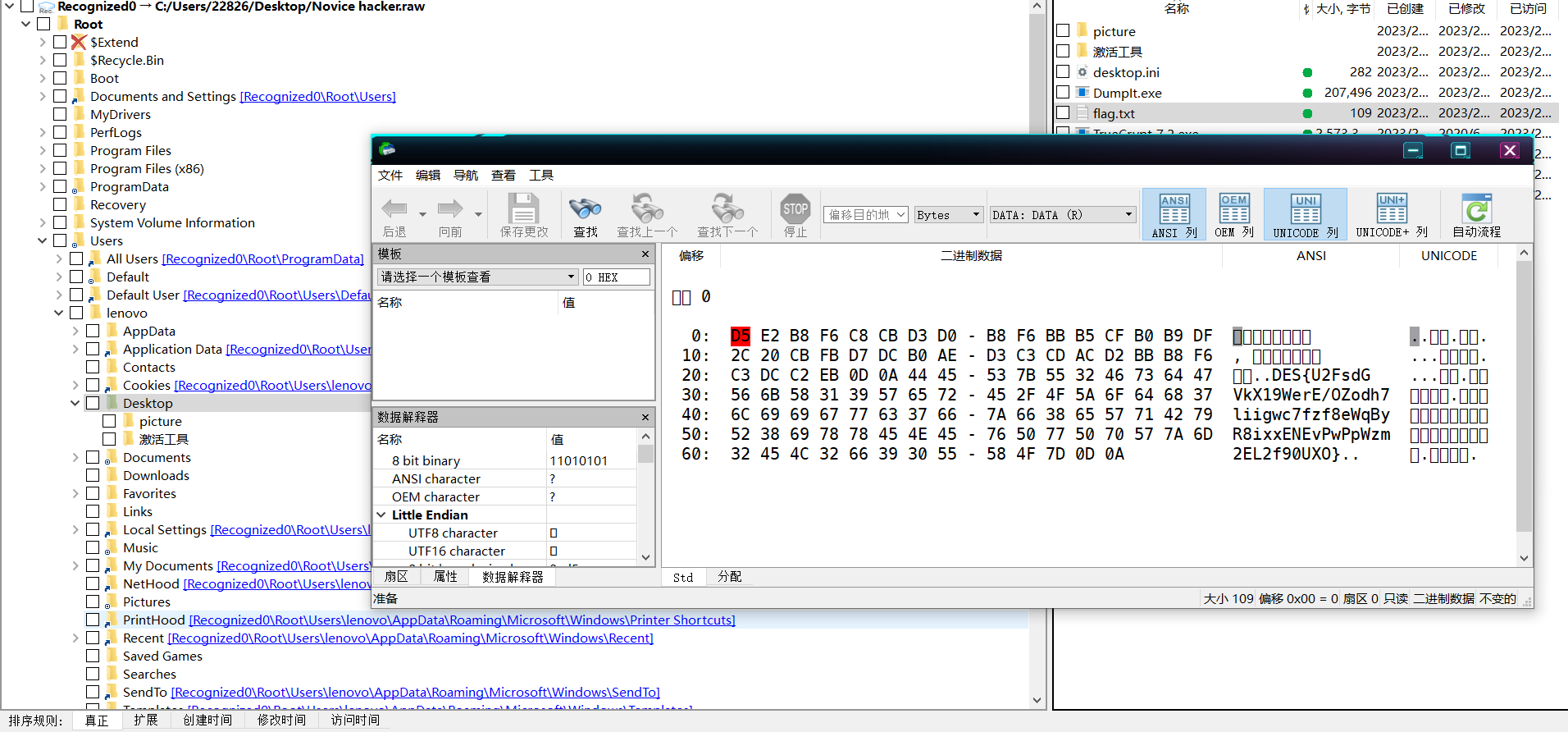
感觉+一点点脑洞,ISCC2023作为key直接解
菜鸟黑客-2
又是抽象的脑洞题
上题在桌面找的时候看到一个emoji.jpg,有点可疑,dump下来

python2 vol.py -f "Novice hacker.raw" --profile=Win7SP1x64 dumpfiles -Q 0x000000007dfaff20 -D ./
这里又可以dump了,上一题的flag.txt就是不行 不理解为啥
文件尾一个zip,foremost出来,密码还是脑洞ISCC2023,得到
维吉尼亚密码曾多次被发明。该方法最早记录在吉奥万·巴蒂斯塔·贝拉索( Giovan Battista Bellaso)于1553年所著的书《吉奥万·巴蒂斯塔·贝拉索先生的密码》(意大利语:La cifra del. Sig. Giovan Battista Bellaso)中。然而,后来在19世纪时被误传为是法国外交官布莱斯·德·维吉尼亚(Blaise De Vigenère)所创造,因此现在被称为“维吉尼亚密码”。
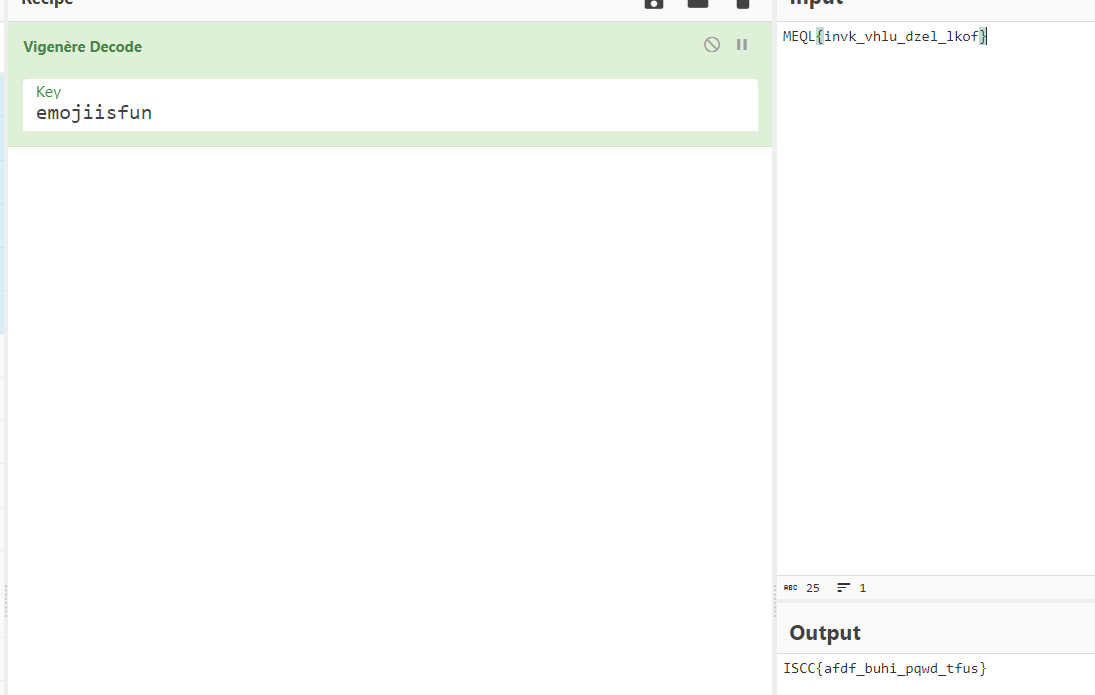
MEQL{invk_vhlu_dzel_lkof}
emoji作为key解维吉尼亚得到ISCC的flag头,但flag错了
看那个emoji.jpg,根据眼睛得到morse,解得key 是emojiisfun,解维吉尼亚得到正确的flag
通信方式
左右声道差分,把0去掉,中间有数据部分拿出来
import scipy.io.wavfile as wavfile
samplerate, data = wavfile.read('telegram2wechat3.wav')
left = []
right = []
for item in data:left.append(item[0])right.append(item[1])
diff = [left - right for left, right in zip(left, right)]
# print(diff)
a=''
for i in diff:if i !=0:a+=str(i)
with open('11.txt','w+') as f:f.writelines(a)
开头七个1,一眼二维码,把2转成0之后01转二维码
脚本来自Bysx20的github
import os
import cv2
import time
import argparse
import itertools
import numpy as npparser = argparse.ArgumentParser()
parser.add_argument('-f', type=str, default=None, required=True,help='输入文件名称')
parser.add_argument('-size', type=int, default=5,help='图片放大倍数(默认5倍)')
args = parser.parse_args()file_path = os.path.join(args.f)if not os.path.exists("./out"):os.mkdir("./out")# read binary txt
with open(file_path, "r") as f:data = f.read().strip()def draw_QR(img, reverse=False):for i, v in enumerate(data[:row*col]):right_bottom_point = (left_top_point[i][0] + size, left_top_point[i][1] + size)if not reverse:cv2.rectangle(img, left_top_point[i], right_bottom_point, color=(255, 255, 255), thickness=-1) if v == "0" else cv2.rectangle(img, left_top_point[i], right_bottom_point, color=(0, 0, 0), thickness=-1)else:cv2.rectangle(img, left_top_point[i], right_bottom_point, color=(0, 0, 0), thickness=-1) if v == "0" else cv2.rectangle(img, left_top_point[i], right_bottom_point, color=(255, 255, 255), thickness=-1)return imgif __name__ == '__main__':# 计算宽高dic = {X: int(len(data) / X) for X in range(1, len(data)) if len(data) % X == 0}size = args.sizefor row, col in dic.items():img1, img2 = np.zeros((row * size, col * size, 1)), np.zeros((row * size, col * size, 1))left_top_point = []for i, j in itertools.product(range(0, row * size, size), range(0, col * size, size)):left_top = (j, i)left_top_point.append(left_top)cv2.imwrite(f"./out/{col}_{row}.png", draw_QR(img1, reverse=False))cv2.imwrite(f"./out/{col}_{row}_reverse.png", draw_QR(img2, reverse=True))print(f"[-] 宽度:{col:6} 高度:{row:6}, 已保存在运行目录out中...")print("[-] 已经遍历完所有情况, 即将自动关闭!")time.sleep(0.5)扫描得到
5337 5337 2448 2448 0001 2448 0001 2161 1721 4574 2496 5337 2606 0668 5337 6671 0008 3296 7741 2583 5337 0260 2977 3320 0001 0668 5337 0604 5337 0260 3945 5337 2606 2161 1721
中文电码转换 - 在线工具栏 (usetoolbar.com)
f12改一下前端长度限制
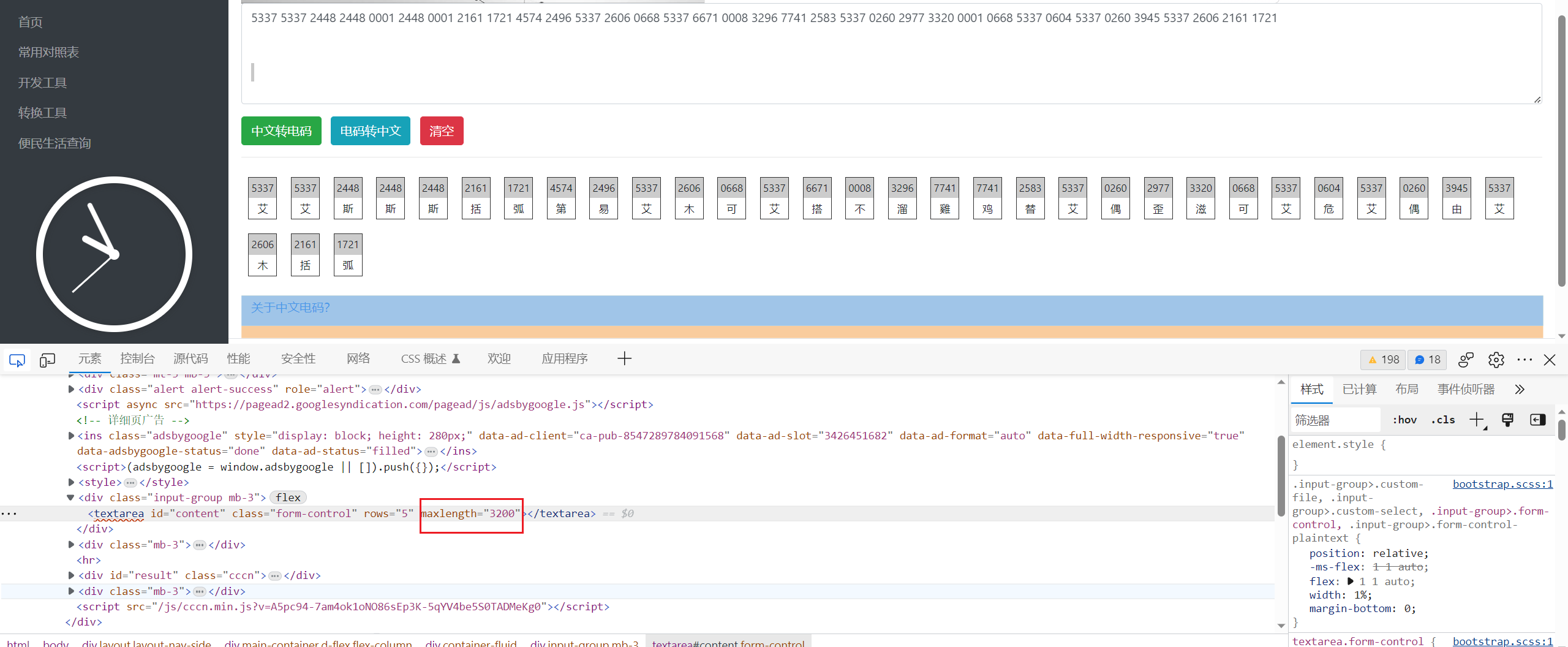
后面就只能靠感觉去读了,我的flag读出来是ISCC{DEMKWGTLYZKVLUM}
总结了个表
A艾一B比C斯一D第E易F艾福G记H艾奇I艾J之艾K科一L艾偶M艾木N恩O偶P匹Q科一由R啊S艾斯T替U由V危W达不溜X艾克斯Y歪Z滋一{}括弧
mystery of bits
png修复一下宽高
stegsolve alpha1通道看到密码
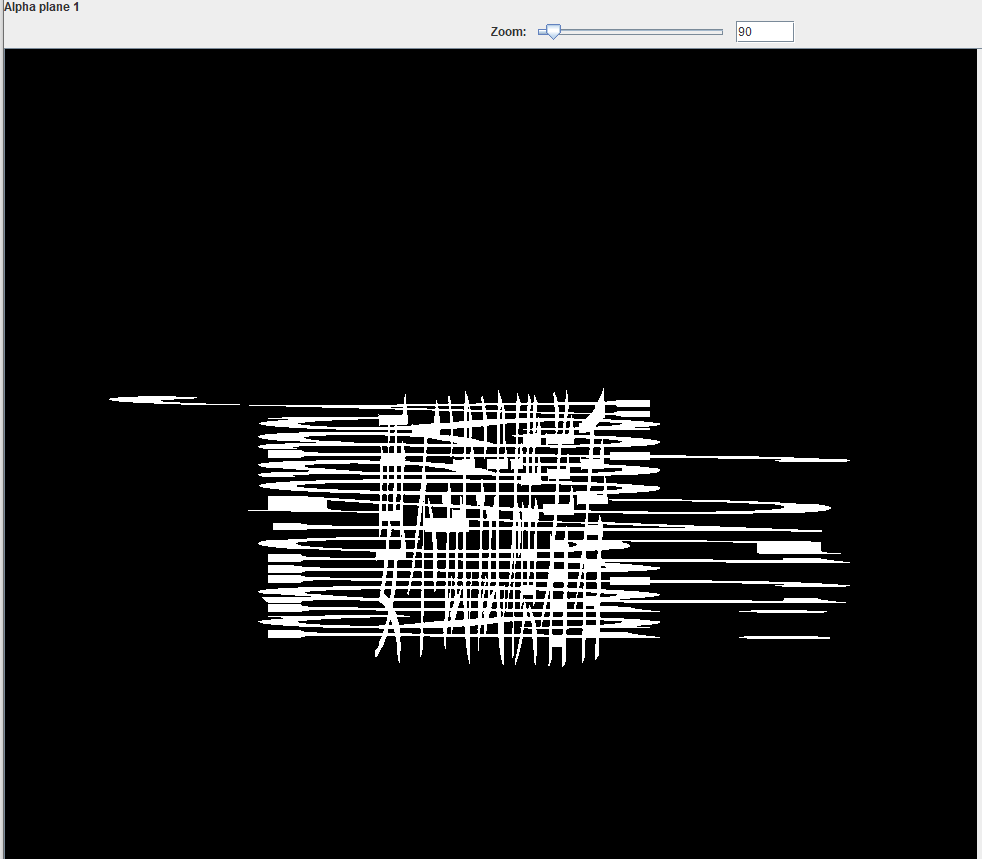
ps调整一下,得到压缩包密码ysafao245hfdisi

解开wav文件尾给了密码

stegpy

转二维码
import os
import cv2
import time
import argparse
import itertools
import numpy as npparser = argparse.ArgumentParser()
parser.add_argument('-f', type=str, default=None, required=True,help='输入文件名称')
parser.add_argument('-size', type=int, default=5,help='图片放大倍数(默认5倍)')
args = parser.parse_args()file_path = os.path.join(args.f)if not os.path.exists("./out"):os.mkdir("./out")# read binary txt
with open(file_path, "r") as f:data = f.read().strip()def draw_QR(img, reverse=False):for i, v in enumerate(data[:row*col]):right_bottom_point = (left_top_point[i][0] + size, left_top_point[i][1] + size)if not reverse:cv2.rectangle(img, left_top_point[i], right_bottom_point, color=(255, 255, 255), thickness=-1) if v == "0" else cv2.rectangle(img, left_top_point[i], right_bottom_point, color=(0, 0, 0), thickness=-1)else:cv2.rectangle(img, left_top_point[i], right_bottom_point, color=(0, 0, 0), thickness=-1) if v == "0" else cv2.rectangle(img, left_top_point[i], right_bottom_point, color=(255, 255, 255), thickness=-1)return imgif __name__ == '__main__':# 计算宽高dic = {X: int(len(data) / X) for X in range(1, len(data)) if len(data) % X == 0}size = args.sizefor row, col in dic.items():img1, img2 = np.zeros((row * size, col * size, 1)), np.zeros((row * size, col * size, 1))left_top_point = []for i, j in itertools.product(range(0, row * size, size), range(0, col * size, size)):left_top = (j, i)left_top_point.append(left_top)cv2.imwrite(f"./out/{col}_{row}.png", draw_QR(img1, reverse=False))cv2.imwrite(f"./out/{col}_{row}_reverse.png", draw_QR(img2, reverse=True))print(f"[-] 宽度:{col:6} 高度:{row:6}, 已保存在运行目录out中...")print("[-] 已经遍历完所有情况, 即将自动关闭!")time.sleep(0.5)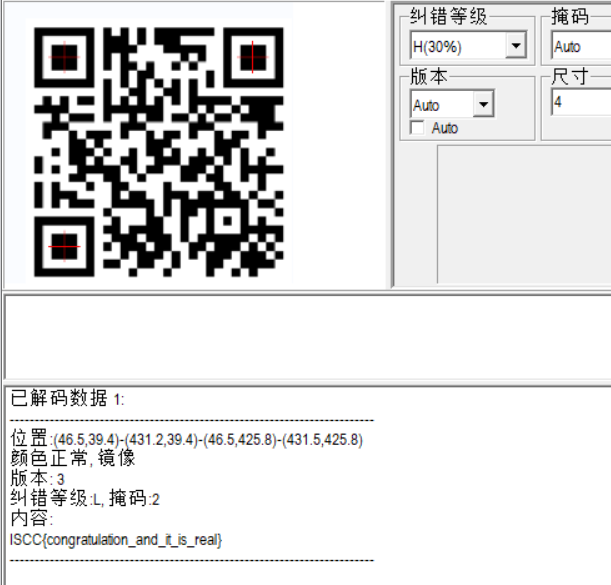
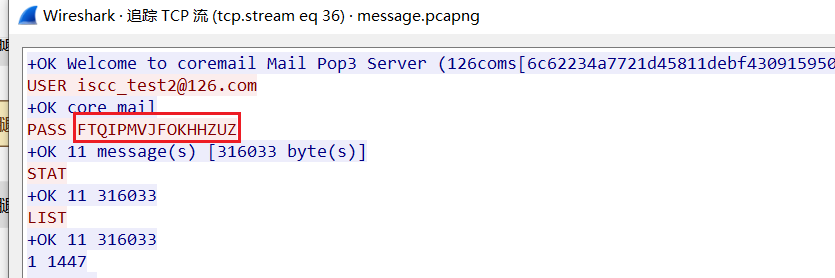
消息传递
发现有smtp邮件传输
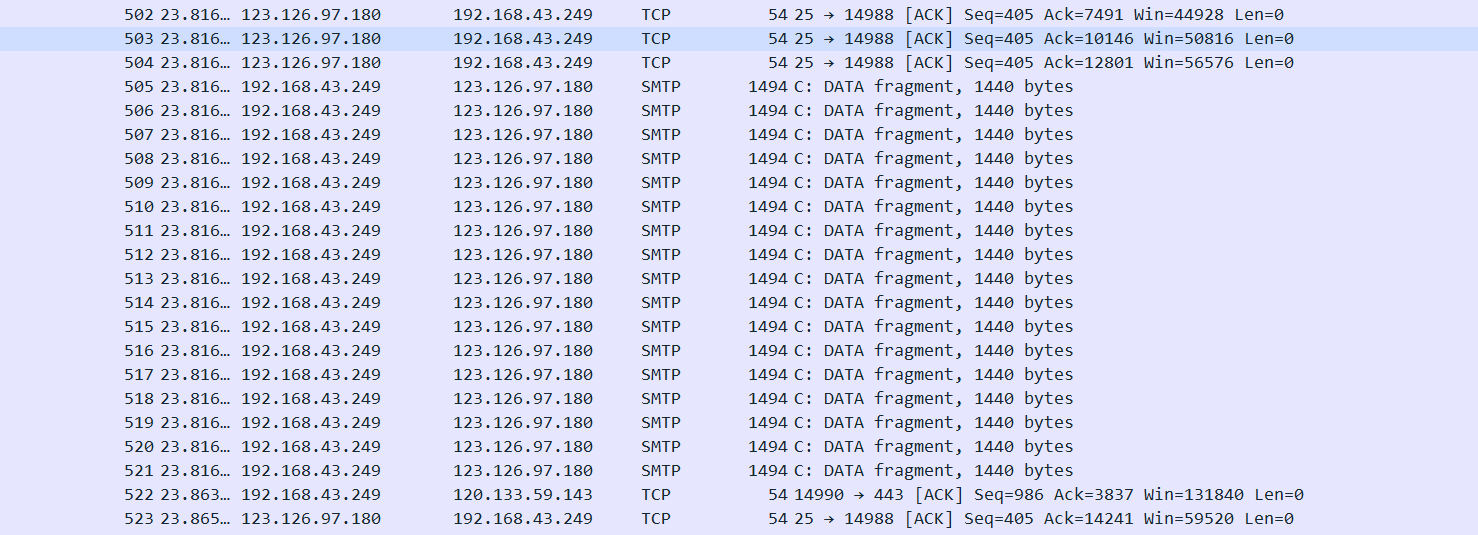
导出imf
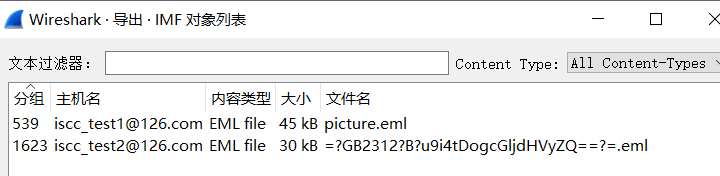
解base64分别可以得到一张png和一个rar
png里两张图 foremost一下,提示两个密码加起来

两个密码WRWAALIUWOHZAPQW,FTQIPMVJFOKHHZUZ
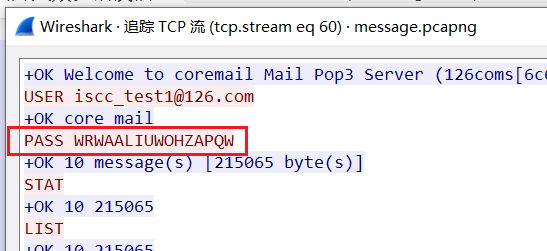
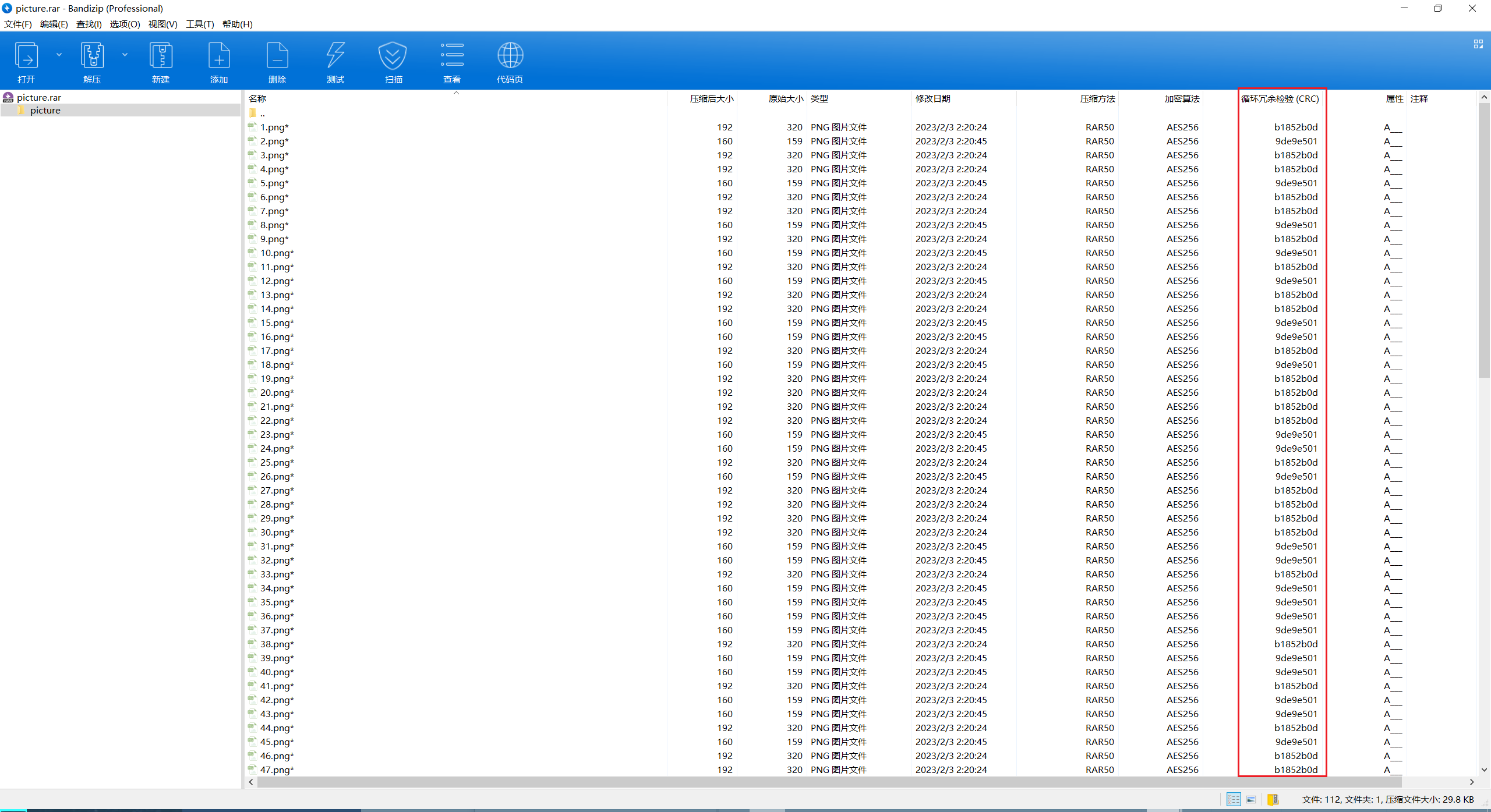
解开得到大量png,两种crc对应01转二进制
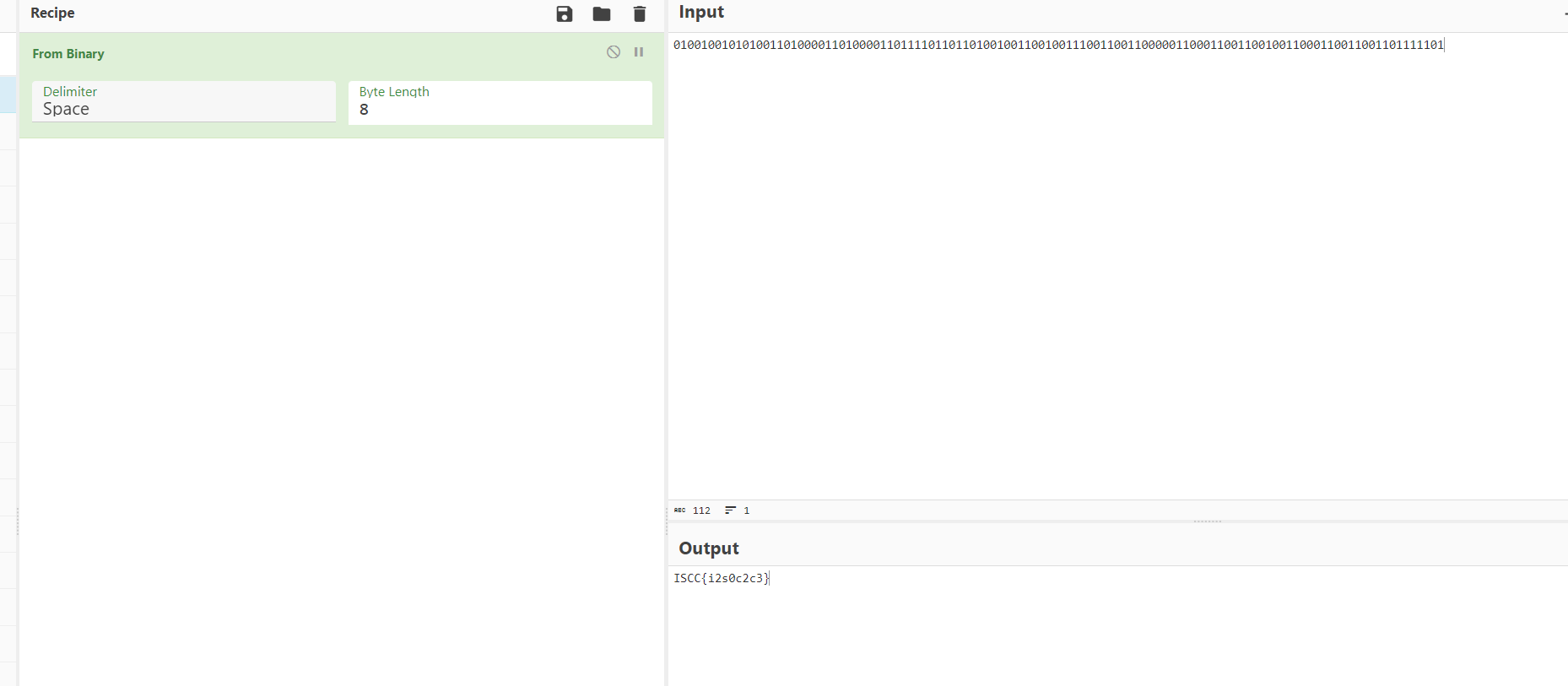
import rarfile
import rewith rarfile.RarFile('picture.rar', 'r') as rar_file:file_list = rar_file.infolist()filenames_crc = [(file_info.filename, file_info.CRC) for file_info in file_list]sorted_filenames_crc = sorted(filenames_crc, key=lambda x: int(re.search(r'\d+', x[0]).group())if re.search(r'\d+', x[0]) else float('inf'))for filename, crc in sorted_filenames_crc:if crc:if hex(crc)=='0xb1852b0d':print(0,end='')else :print(1,end='')得到i2s0c2c3
用回汤姆那道题的单表替换脚本就行
path = "dictionary.txt"replaces = {}
key = "ISCC{i2s0c2c3}"
flag = ''
with open(path, "r") as f:lines = f.readlines()for line in lines:after, out = line.strip().split(":")replaces[after] = outfor char in key:if char in replaces:flag += replaces[char]
你相信AI吗?
手写数字模型,搭不来
非预期解:(不过后来被修了)
直接读取txt文件内容,转成像素填入,得到手写数字的结果
import numpy as np
from PIL import Image# 图像宽度和高度
width, height = 28, 0# 依次读取每个文件,将其转换为图像并保存
for i in range(32):# 读取浮点数数据with open(f'{i}.txt', 'r') as f:data = f.read()data = np.fromstring(data, sep='\n')# 计算图像高度height = len(data) // width# 将浮点数转换为 8 位无符号整数data = np.clip(data, 0, 255)data = data.astype(np.uint8)# 创建图像并保存img = Image.fromarray(data.reshape((height, width)))img.save(f'png/{i}.png')

肉眼ocr之后0-9 ascii单表替换爆破
import itertools
import contextlib
import string
ciphertext = ['51', '59', '75', '95', '56', '46', '669', '74', '22', '92', '28', '72', '77', '682', '47', '02', '77', '633', '92', '43', '56', '633', '688', '59', '22', '633', '685', '57', '683', '56', '96', '96']def has_visible_bytes(input_bytes):return all(chr(byte) in string.printable for byte in input_bytes)with open("out.txt", "wb") as output_file:for permutation in itertools.permutations("0123456789", 10):translation_table = str.maketrans("0123456789", ''.join(permutation))translated_text = [string.translate(translation_table) for string in ciphertext]with contextlib.suppress(Exception):plaintext = bytes([int(character) for character in translated_text])output_file.write(plaintext + b"\n")
擂台
Guess_RSA
公钥解析,得到n,e,用在线网站也行SSL在线工具-公钥解析 (hiencode.com)
from Crypto.PublicKey import RSA# 从公钥里面提取n 和 e
with open('publickey','r') as f:key = RSA.import_key(f.read())
e = key.e
n = key.n
print('e = %d\nn = %d'%(e,n))
#e = 65537
#n = 141290037064947566206529132717181370698234864868642699047557973411457219735533077057541763794458453776854205535054584663279827865601322416203933147042933586981716703290143924844104156938834839095947246954751648421206411462640039984758358072222401824528712347742351563547663982933462992608020341150998418481469
lsb得到一串16进制,去除: 作为dp
381044a04c6c66078e89668fd73cb82c4f10161be4c6f3a12781698d00efba838cdb4b4373bd72ebdca49a6470e59f9fb8413a3b2ac7ac850f176c4d65ef7ab5
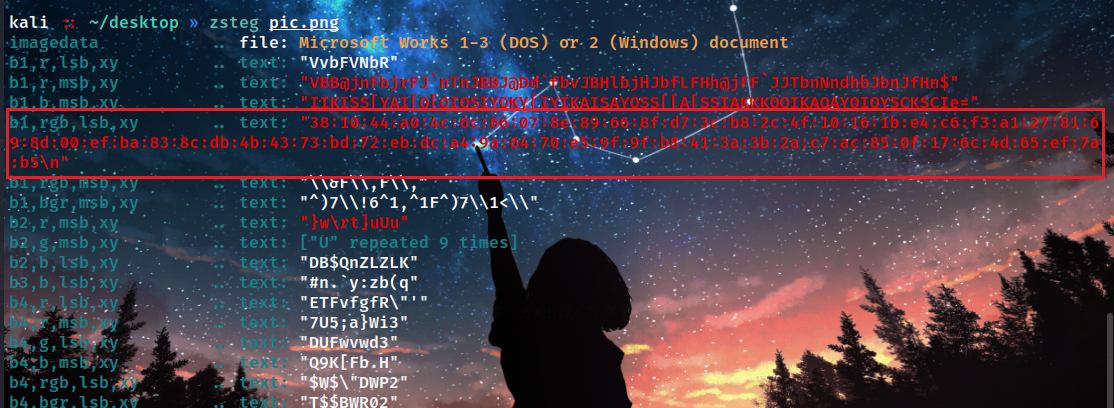
解密脚本
#coding=utf-8
import gmpy2 as gpe = 65537
n = 141290037064947566206529132717181370698234864868642699047557973411457219735533077057541763794458453776854205535054584663279827865601322416203933147042933586981716703290143924844104156938834839095947246954751648421206411462640039984758358072222401824528712347742351563547663982933462992608020341150998418481469
dp = int('381044a04c6c66078e89668fd73cb82c4f10161be4c6f3a12781698d00efba838cdb4b4373bd72ebdca49a6470e59f9fb8413a3b2ac7ac850f176c4d65ef7ab5',16)
c=''
# with open('cryptotext1.txt','rb') as f:
# hex_list = ("{:02X}".format(int(c)) for c in f.read()) # 定义变量接受文件内容
# buflist = list(hex_list)
# for i in buflist:
# c+=i
# with open('cryptotext2.txt','rb') as f:
# hex_list = ("{:02X}".format(int(c)) for c in f.read()) # 定义变量接受文件内容
# buflist = list(hex_list)
# for i in buflist:
# c+=i
with open('cryptotext3.txt','rb') as f:hex_list = ("{:02X}".format(int(c)) for c in f.read()) # 定义变量接受文件内容buflist = list(hex_list)for i in buflist:c+=i
c = int(c,16)
# print(c)
for i in range(1, e): # 在范围(1,e)之间进行遍历if (dp * e - 1) % i == 0:if n % (((dp * e - 1) // i) + 1) == 0: # 存在p,使得n能被p整除p = ((dp * e - 1) // i) + 1q = n // (((dp * e - 1) // i) + 1)phi = (q - 1) * (p - 1) # 欧拉定理d = gp.invert(e, phi) # 求模逆m = pow(c, d, n) # 快速求幂取模运算print (hex(m)[2:])
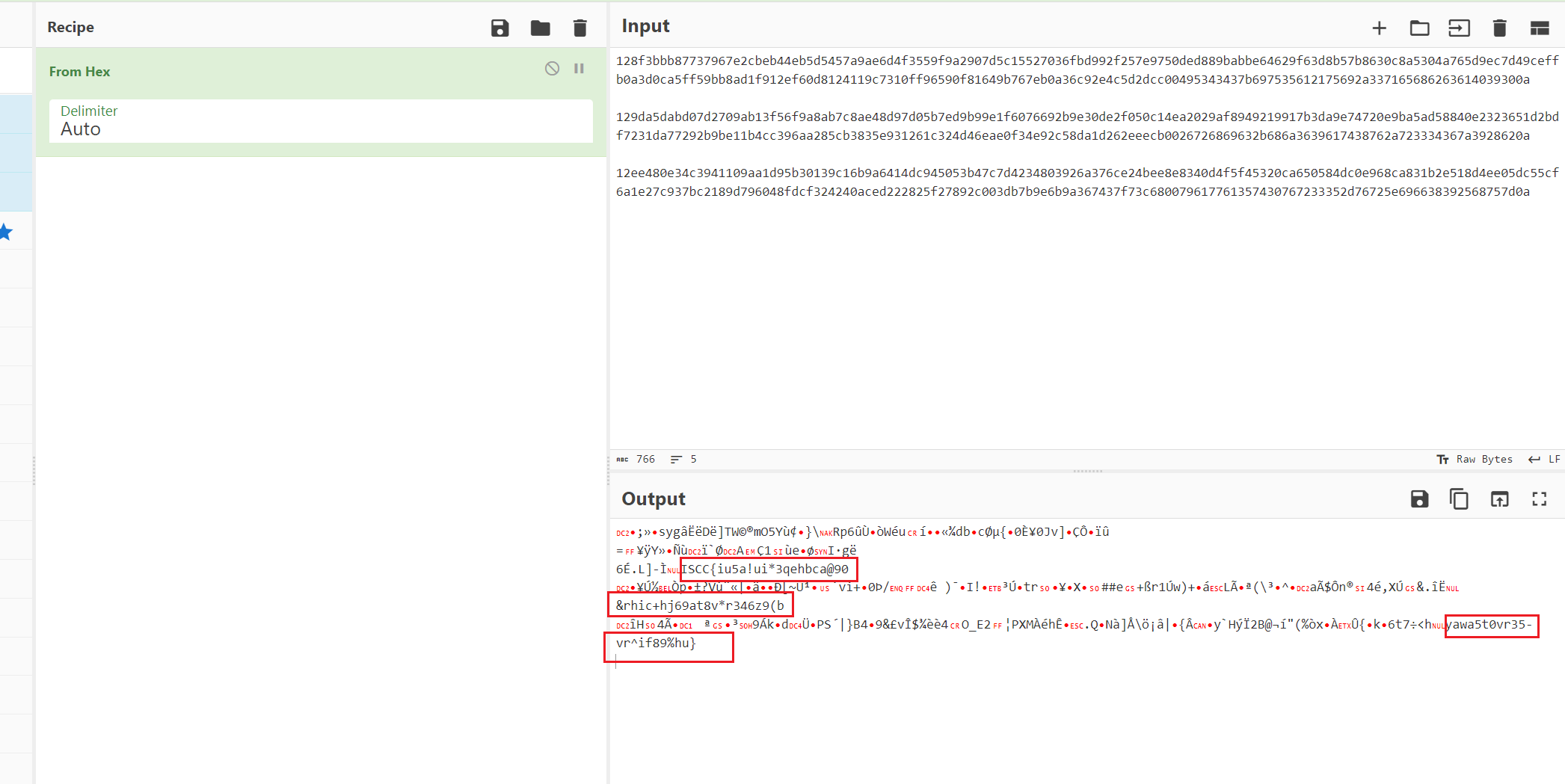
#28f3bbb87737967e2cbeb44eb5d5457a9ae6d4f3559f9a2907d5c15527036fbd992f257e9750ded889babbe64629f63d8b57b8630c8a5304a765d9ec7d49ceffb0a3d0ca5ff59bb8ad1f912ef60d8124119c7310ff96590f81649b767eb0a36c92e4c5d2dcc00495343437b697535612175692a337165686263614039300a
#29da5dabd07d2709ab13f56f9a8ab7c8ae48d97d05b7ed9b99e1f6076692b9e30de2f050c14ea2029af8949219917b3da9e74720e9ba5ad58840e2323651d2bdf7231da77292b9be11b4cc396aa285cb3835e931261c324d46eae0f34e92c58da1d262eeecb0026726869632b686a3639617438762a723334367a3928620a
#2ee480e34c3941109aa1d95b30139c16b9a6414dc945053b47c7d4234803926a376ce24bee8e8340d4f5f45320ca650584dc0e968ca831b2e518d4ee05dc55cf6a1e27c937bc2189d796048fdcf324240aced222825f27892c003db7b9e6b9a367437f73c680079617761357430767233352d76725e696638392568757d0a
不知道是不是自己姿势错误还是题目预期就是如下
找了网上好多脚本去解出来的三段数据转字符都是乱码,其中一个脚本当时报错显示奇数,感觉很奇怪,多次尝试之后发现可能出来的明文都被删除了一位,开头随便加个1成功解析出三段分开的flag
雪豹
套神的套题果然名不虚传,拿了个一血美滋滋 😃
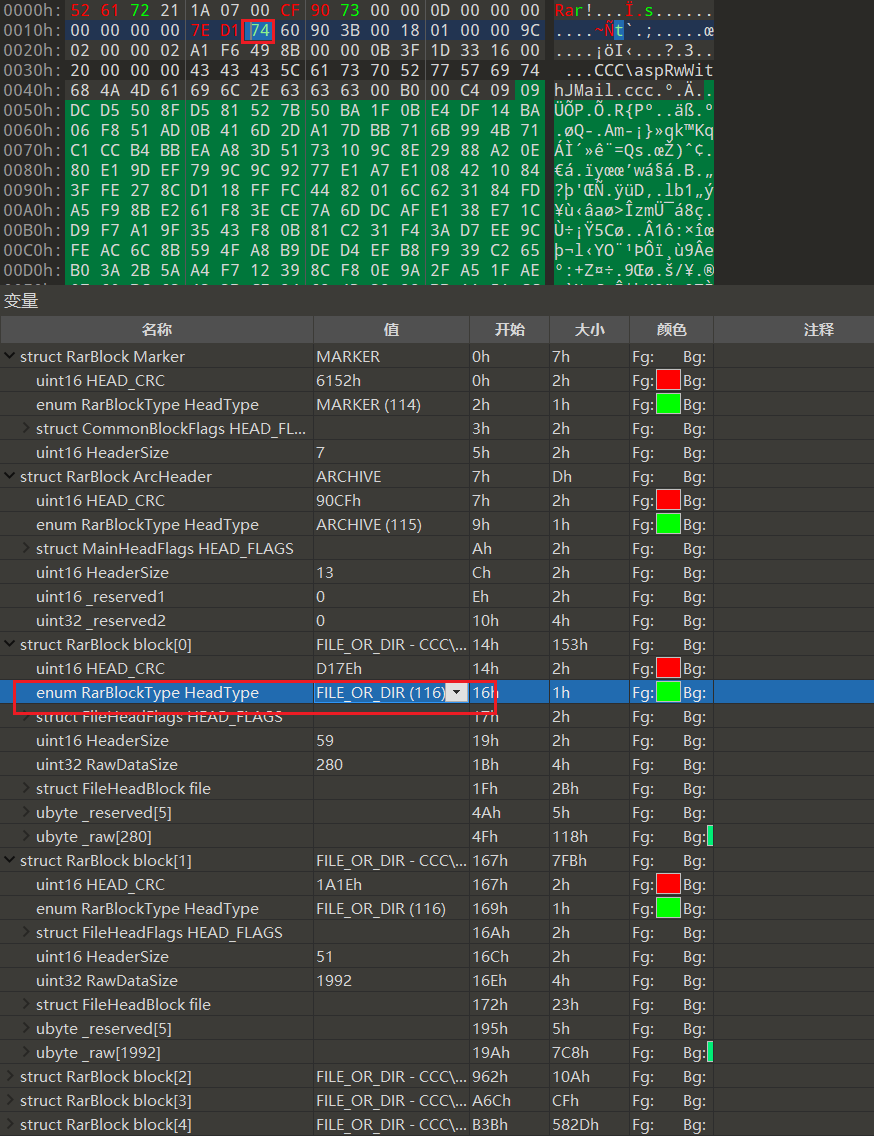
拿到rar打开有密码,没任何密码提示也爆破不出来
随便打开一个正常的rar对比文件结构可以发现,rar的文件头识别为74,即 FILE_OR_DIR (116)
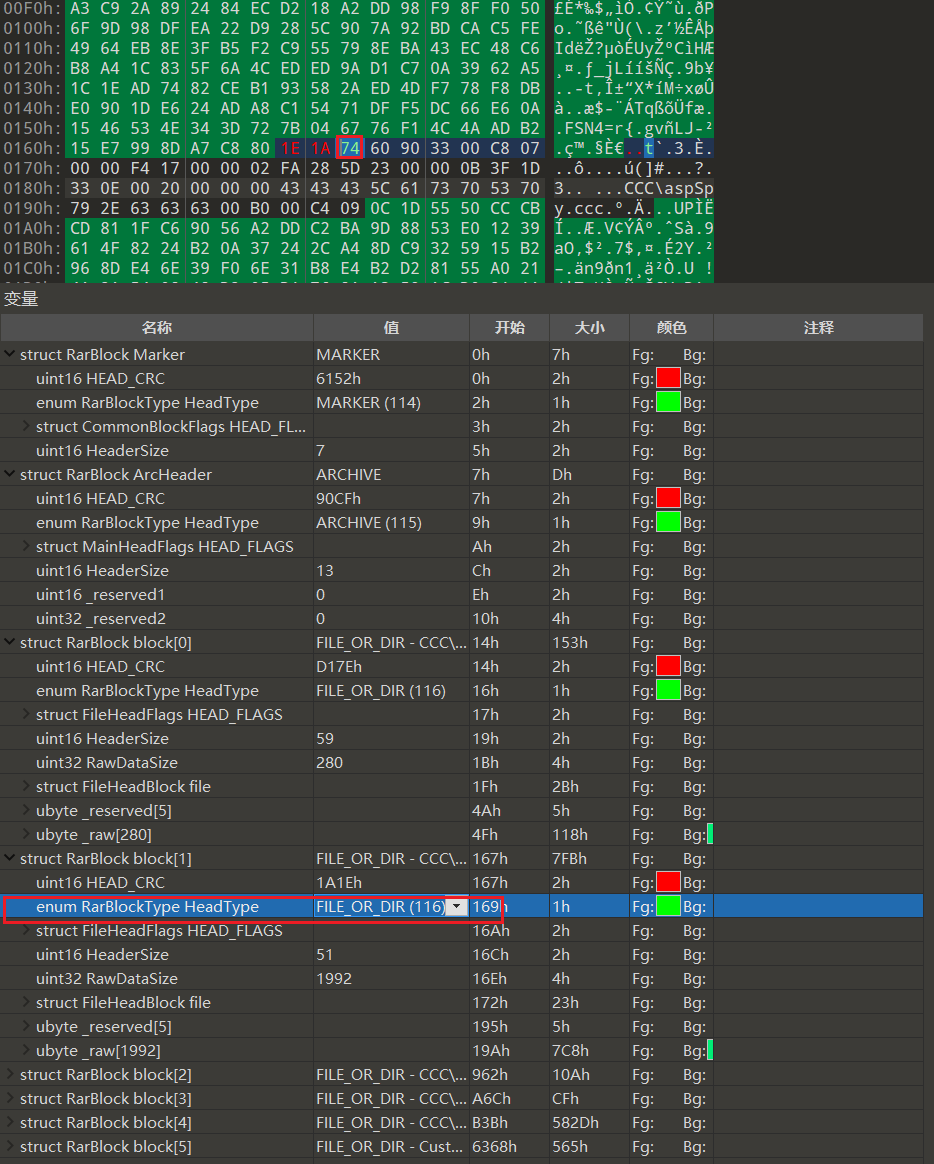
对比会发现题目所给的rar的压缩文件头都被改成了73,全部改回74即可正常识别
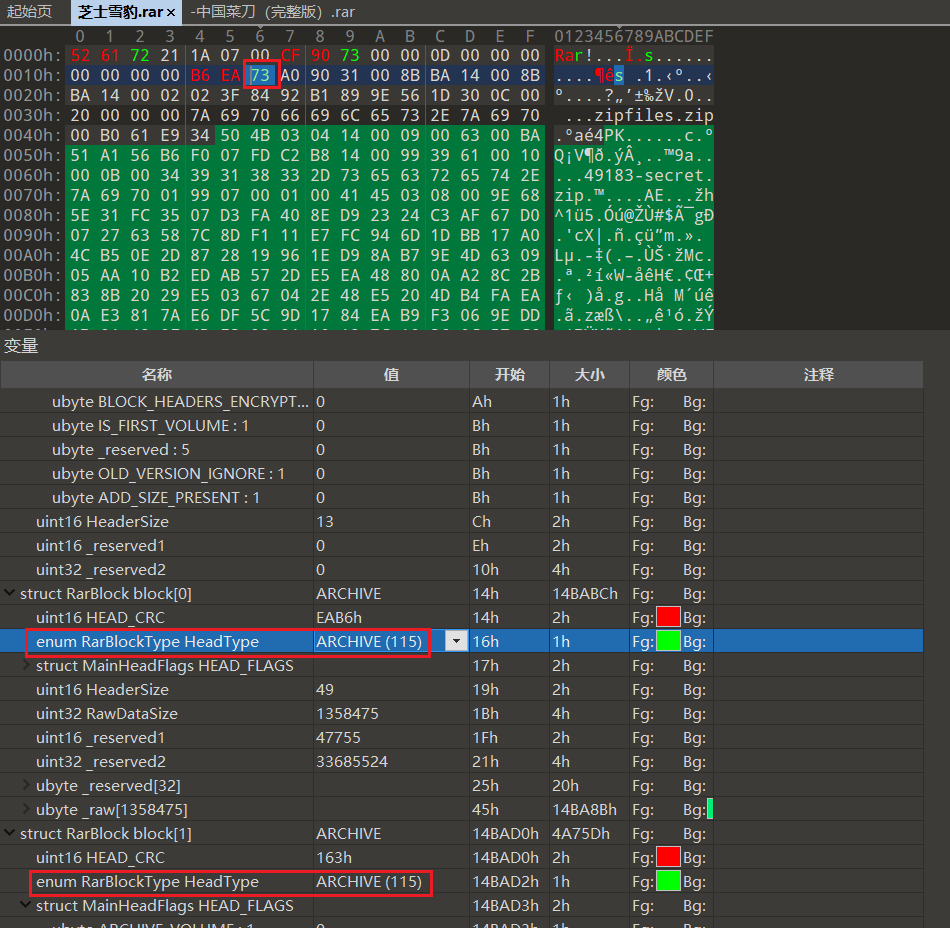
jpg改个高得到zip密码happy_cat
解开之后是一个嵌套49183层的zip
解压脚本,建议放linux里跑,windows可能因为线程并发的原因直接冲突了:
import os
import zipfile
import sys
import time
sys.setrecursionlimit(1000000)#防止python栈溢出
def unzip_file(file_name) :with zipfile.ZipFile(file_name,'r') as zip:comment=zip.commentprint(f"{file_name}:{comment}")zip.extractall()zip.close()#释放内存for file in zip.namelist():if file.endswith('.zip'):os.remove(file_name)unzip_file(file)file_name = '49183-secret.zip'
unzip_file(file_name)
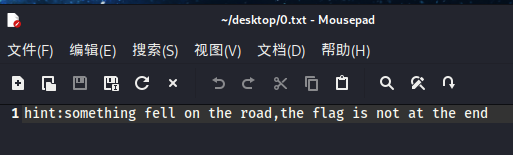
解到最后发现没有flag,提示flag在路上
fuzz后发现压缩包时间不对劲,为10:13:52、10:13:58两种
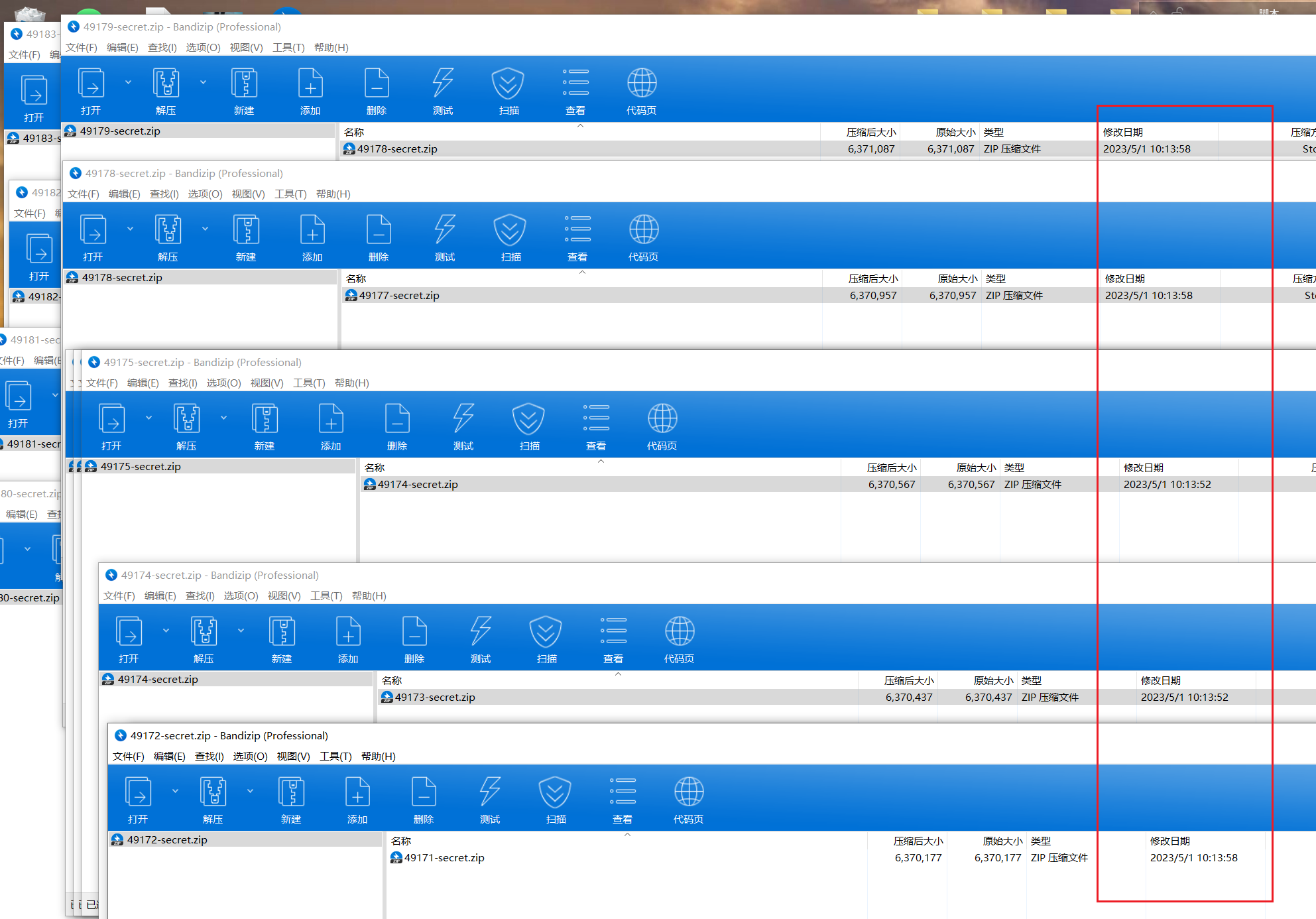
10:13:52为0,10:13:58为1生成二进制
import os
import zipfile
import sys
import time
sys.setrecursionlimit(1000000)#防止python栈溢出
def unzip_file(file_name) :with zipfile.ZipFile(file_name,'r') as zip:zip.extractall()zip.close()#释放内存for file in zip.namelist():if file.endswith('.zip'):file_info = zip.getinfo(zip.namelist()[0])# print(f"{file}:{file_info.date_time}")if file_info.date_time==(2023, 5, 1, 10, 13, 58):print(1,end='')elif file_info.date_time==(2023, 5, 1, 10, 13, 52):print(0,end='')os.remove(file_name)unzip_file(file)file_name = '49183-secret.zip'
print(0,end='')#49183自己为0
unzip_file(file_name)
再解gzip,得到png
根据这个背景图和提示in it,用imagein软件解

得到一串emoji
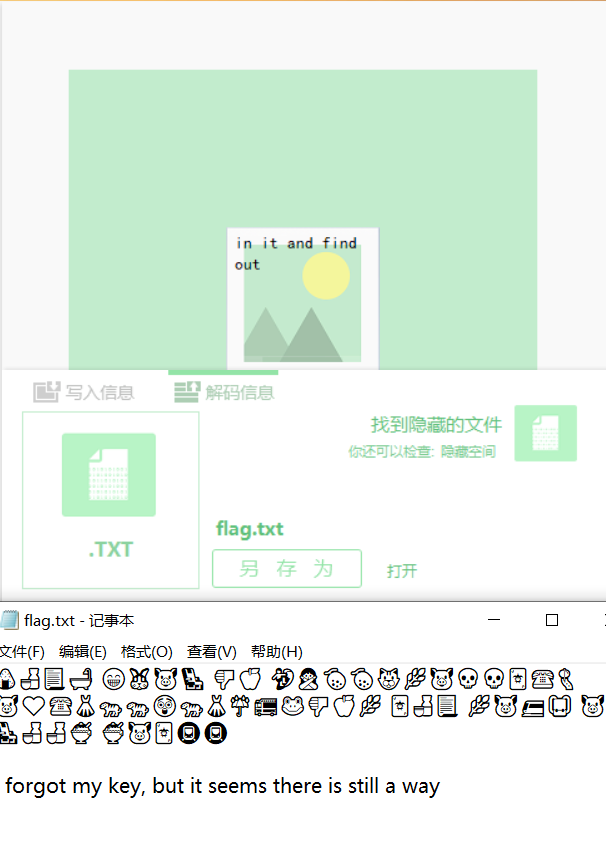
无key emoji,github上有一个这个项目ctf-writeups/hackyeaster2018/challenges/egg17 at master · pavelvodrazka/ctf-writeups · GitHub
解得flag

哦?摩斯密码?
4716个文件夹,每个文件夹下三个二维码
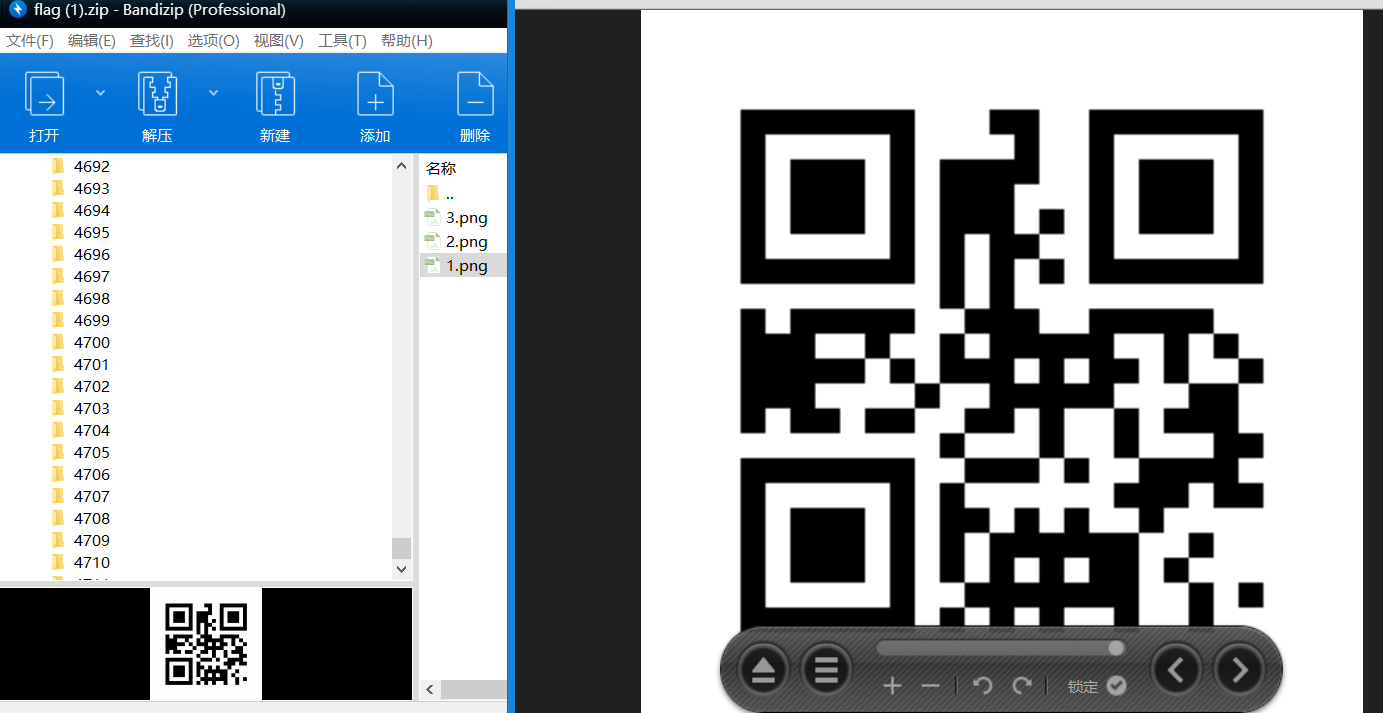
二维码的扫描结果都是摩斯
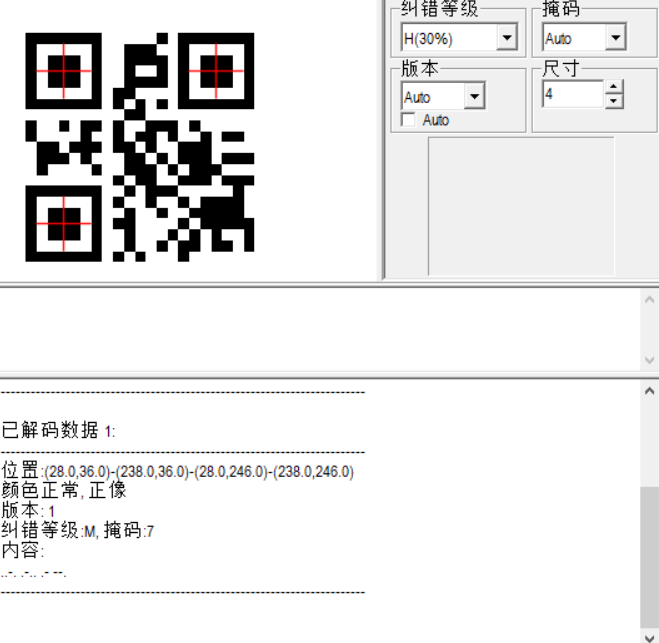
遍历读取,扫描二维码,解摩斯
import os
import cv2
from pyzbar import pyzbardef decode_qr_code(image_path):image = cv2.imread(image_path)qr_codes = pyzbar.decode(image)if qr_codes:return qr_codes[0].data.decode('utf-8')else:return Nonedef decode_morse_code(morse_code):MORSE_CODE_DICT = {'.-': 'A', '-...': 'B', '-.-.': 'C', '-..': 'D', '.': 'E','..-.': 'F', '--.': 'G', '....': 'H', '..': 'I', '.---': 'J','-.-': 'K', '.-..': 'L', '--': 'M', '-.': 'N', '---': 'O','.--.': 'P', '--.-': 'Q', '.-.': 'R', '...': 'S', '-': 'T','..-': 'U', '...-': 'V', '.--': 'W', '-..-': 'X', '-.--': 'Y','--..': 'Z', '.----': '1', '..---': '2', '...--': '3', '....-': '4','.....': '5', '-....': '6', '--...': '7', '---..': '8', '----.': '9','-----': '0', '--..--': ',', '.-.-.-': '.', '..--..': '?', '-..-.': '/','-....-': '-', '-.--.': '(', '-.--.-': ')', '.-...': '&', '---...': ':','-.-.-.': ';', '-...-': '=', '.-.-.': '+', '-....-': '-', '..--.-': '_','.-..-.': '"', '...-..-': '$', '.--.-.': '@', '...---...': 'SOS'}words = morse_code.strip().split(' / ')decoded_message = []for word in words:characters = word.split(' ')decoded_word = ''.join([MORSE_CODE_DICT.get(char, '') for char in characters])decoded_message.append(decoded_word)return ' '.join(decoded_message)a=''
for folder_name in range(4716):folder_dir = str(folder_name)if os.path.isdir(folder_dir):for i in range(1,4):image_path = os.path.join(folder_dir, f"{i}.png")if os.path.isfile(image_path):result = decode_qr_code(image_path)morse_result=decode_morse_code(result)a+=morse_result# print(f"{image_path} : {morse_result}")
print(a)结果字频统计一下,提示TH1SN0FLAG
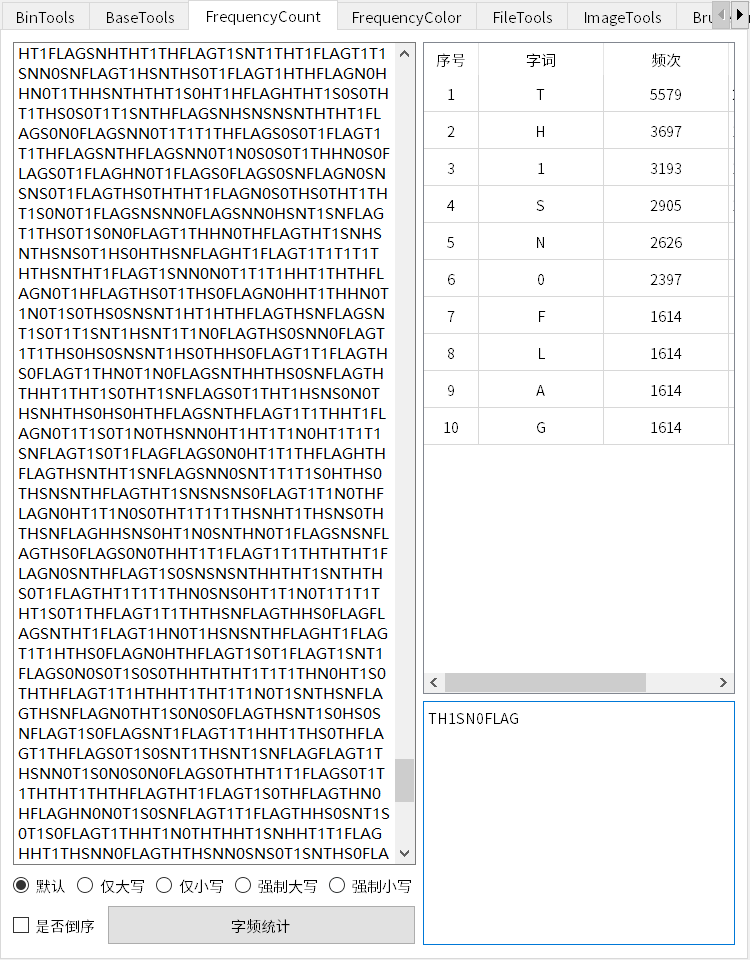
由于只有FLAG字段是单独作为一个二维码的
在尝试将所有FLAG和对应的图片打印出来时发现呈现了一定的规律性
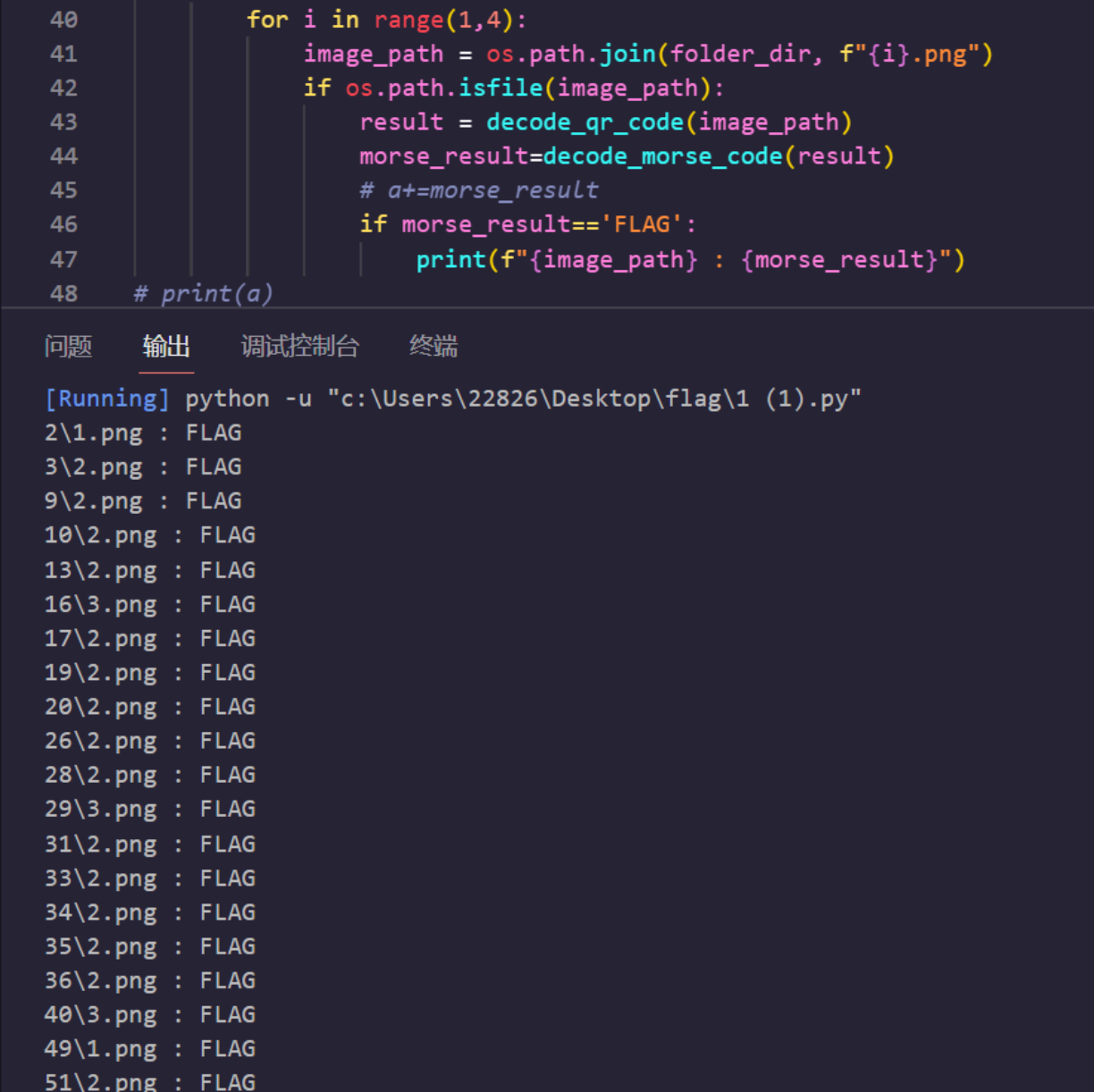
再结合题目名又强调摩斯,以1为.2为-3为分割转摩斯
import os
import cv2
from pyzbar import pyzbardef decode_qr_code(image_path):image = cv2.imread(image_path)qr_codes = pyzbar.decode(image)if qr_codes:return qr_codes[0].data.decode('utf-8')else:return Nonedef decode_morse_code(morse_code):MORSE_CODE_DICT = {'.-': 'A', '-...': 'B', '-.-.': 'C', '-..': 'D', '.': 'E','..-.': 'F', '--.': 'G', '....': 'H', '..': 'I', '.---': 'J','-.-': 'K', '.-..': 'L', '--': 'M', '-.': 'N', '---': 'O','.--.': 'P', '--.-': 'Q', '.-.': 'R', '...': 'S', '-': 'T','..-': 'U', '...-': 'V', '.--': 'W', '-..-': 'X', '-.--': 'Y','--..': 'Z', '.----': '1', '..---': '2', '...--': '3', '....-': '4','.....': '5', '-....': '6', '--...': '7', '---..': '8', '----.': '9','-----': '0', '--..--': ',', '.-.-.-': '.', '..--..': '?', '-..-.': '/','-....-': '-', '-.--.': '(', '-.--.-': ')', '.-...': '&', '---...': ':','-.-.-.': ';', '-...-': '=', '.-.-.': '+', '-....-': '-', '..--.-': '_','.-..-.': '"', '...-..-': '$', '.--.-.': '@', '...---...': 'SOS'}words = morse_code.strip().split(' / ')decoded_message = []for word in words:characters = word.split(' ')decoded_word = ''.join([MORSE_CODE_DICT.get(char, '') for char in characters])decoded_message.append(decoded_word)return ' '.join(decoded_message)a=''
dic={1:'.',2:'-',3:' '}
for folder_name in range(4716):folder_dir = str(folder_name)if os.path.isdir(folder_dir):for i in range(1,4):image_path = os.path.join(folder_dir, f"{i}.png")if os.path.isfile(image_path):result = decode_qr_code(image_path)morse_result=decode_morse_code(result)if morse_result=='FLAG':a+=dic[i]
print(a)
lists=a.split(' ')
for i in lists:print(decode_morse_code(i),end='')
7位二进制得到NyqgE0TddlwxLpK/g6514s2I6hQt1xNxdmmKYriUGiI=
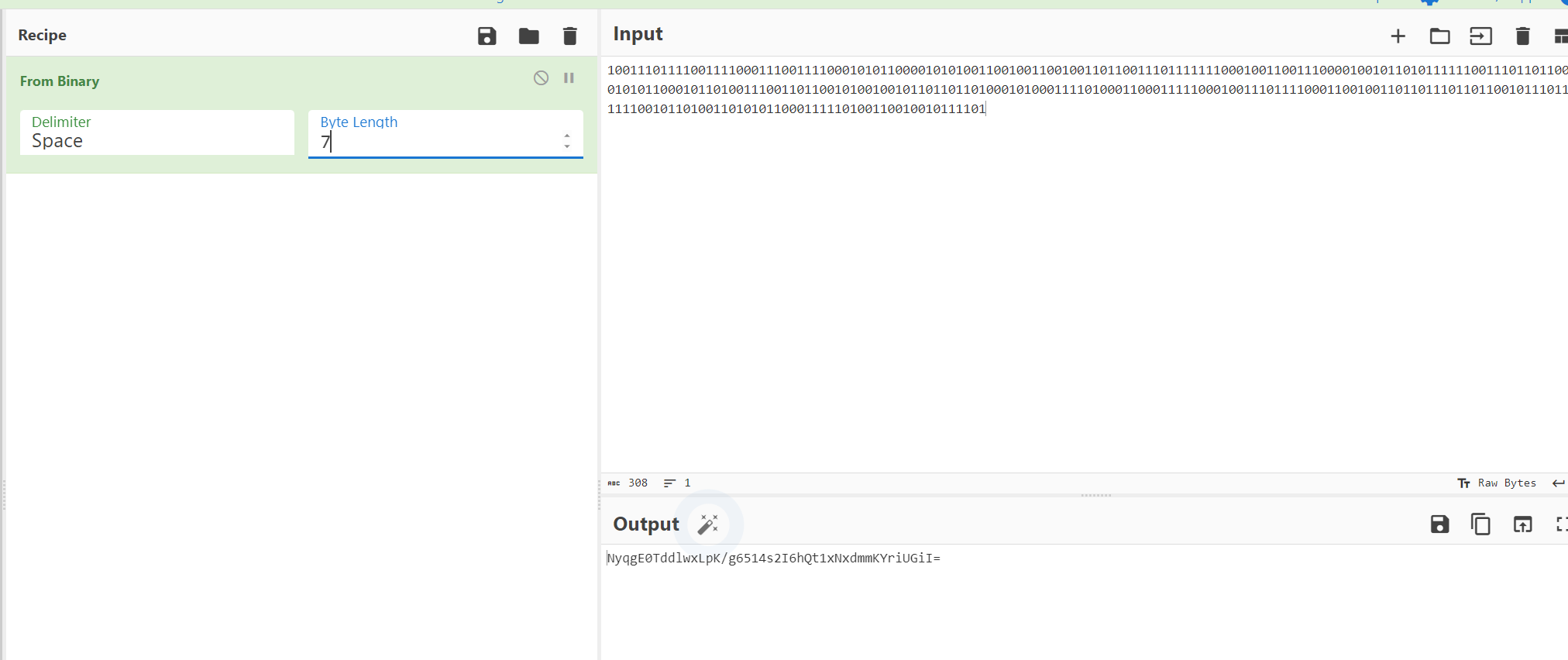
之前字频结果小写作为key解AES得到flag在线AES加密解密、AES在线加密解密、AES encryption and decryption–查错网 (chacuo.net)
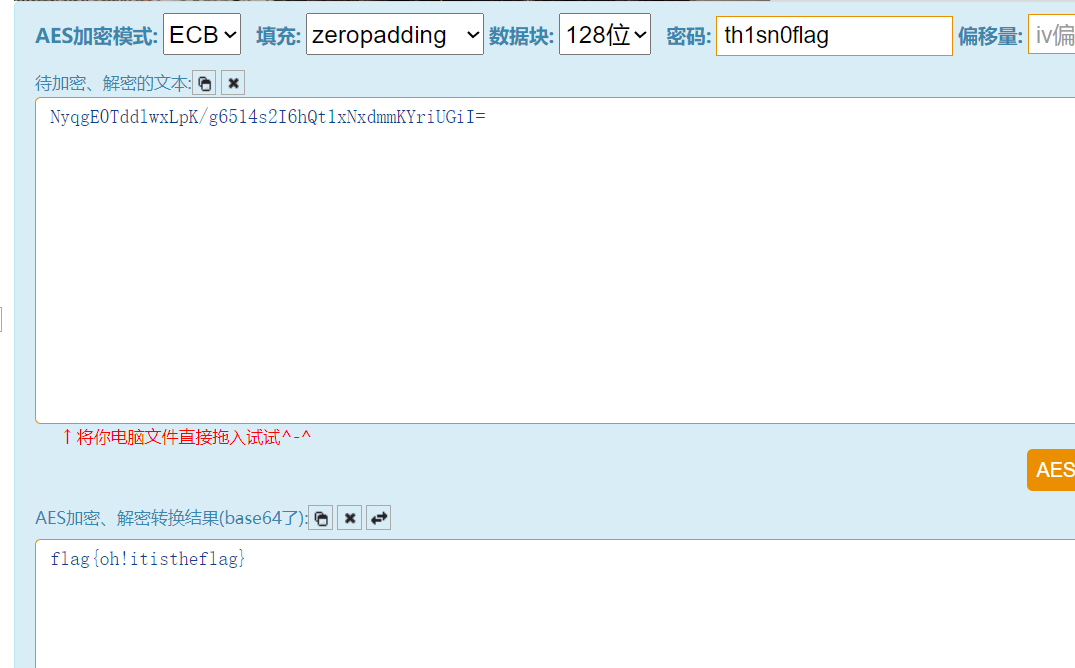
ඞ
又是套神出的题,不过相对来说没那么套,还是挺有意思的
给了个内存,volatility桌面上找到一个solve.zip,一个hint.txt
python2 vol.py -f "C:\Users\22826\Desktop\1.raw" --profile=Win7SP1x64 filescan | find "Desktop"
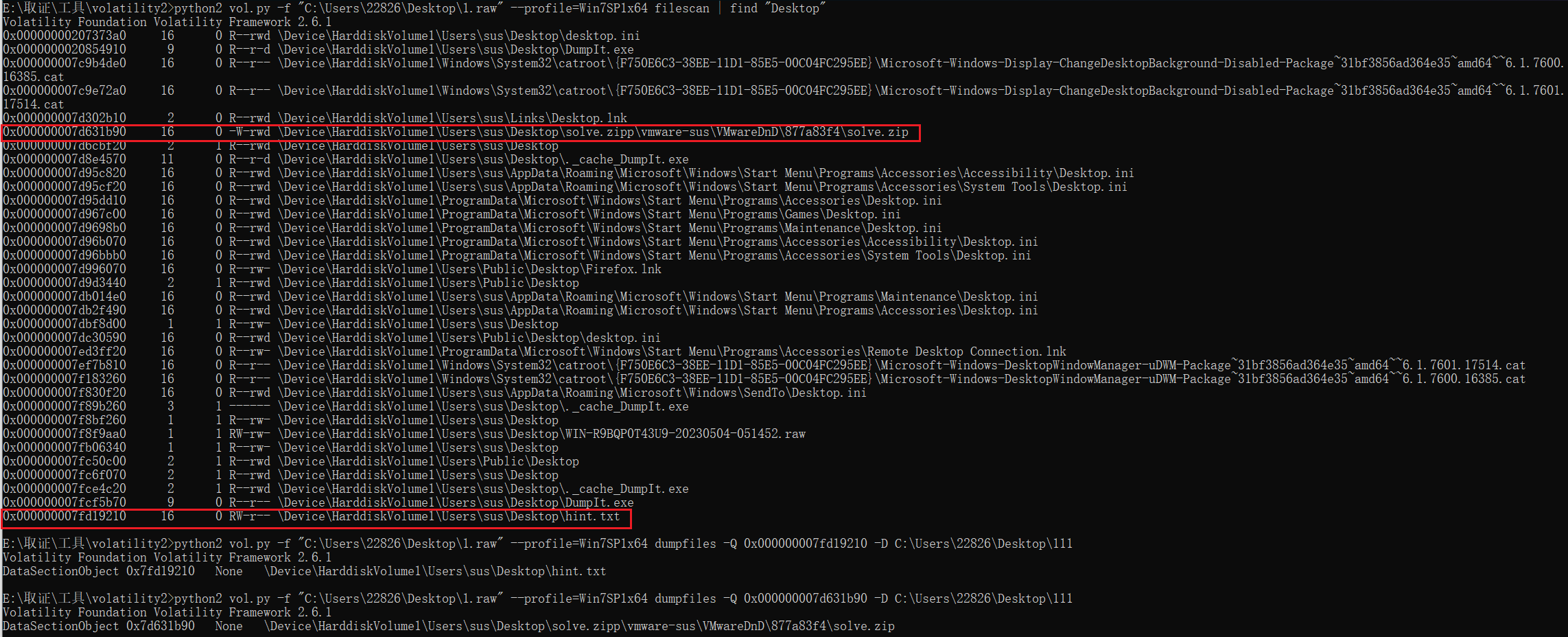
提示四个玩家一场游戏

solve.zip密码是伪装者的名字
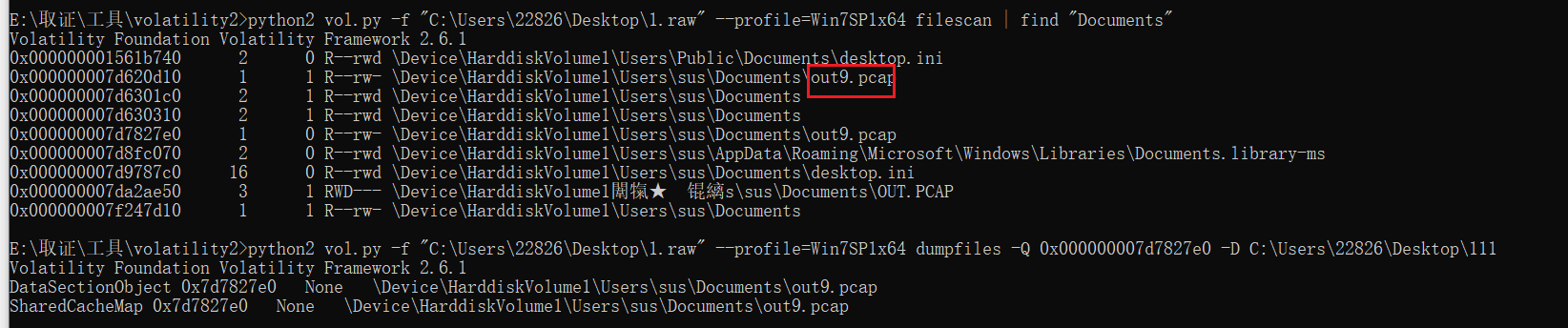
不是很懂什么意思,继续找,Documents目录下可以找到个out9.pcap,导出来
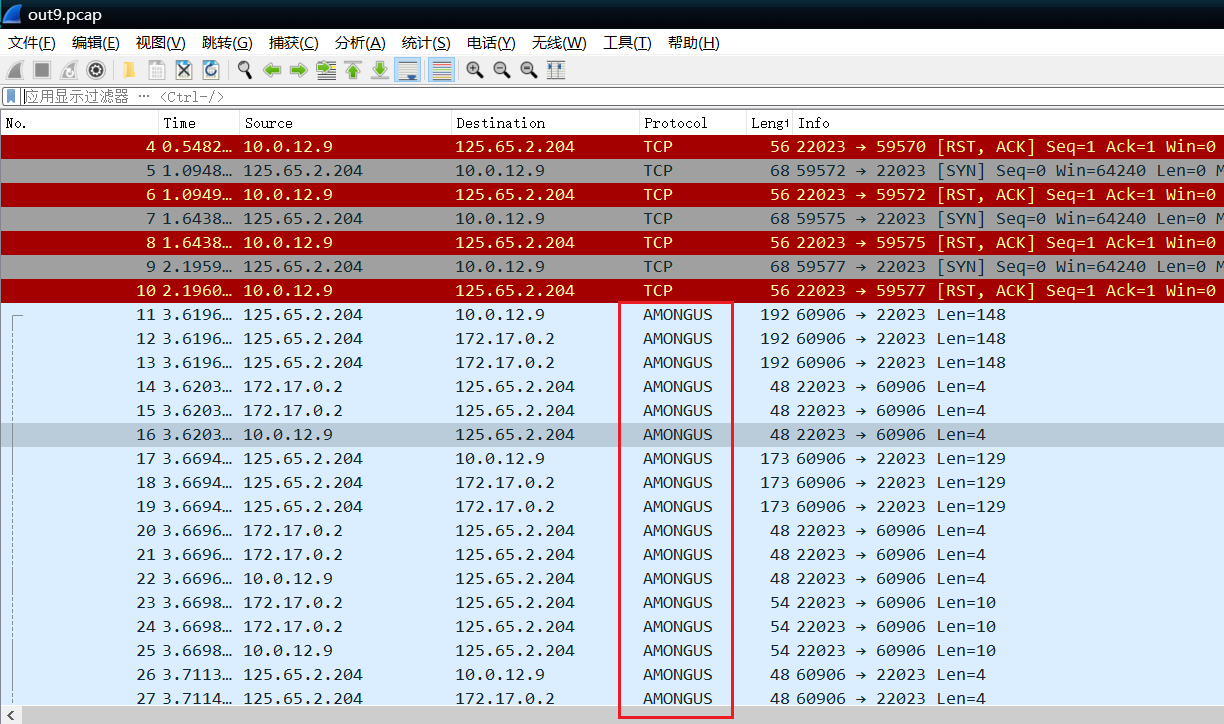
搜一下among us发现是一款太空狼人杀的游戏
结合之前的hint,大概就能猜到这个是游戏过程抓下来的流量,至于要找的伪装者的名字应该就是指游戏中的对应身份的名字
题目还给了游戏的配置文件,逆一下plugins下的dll文件,搜一下发现能搜到伪装者
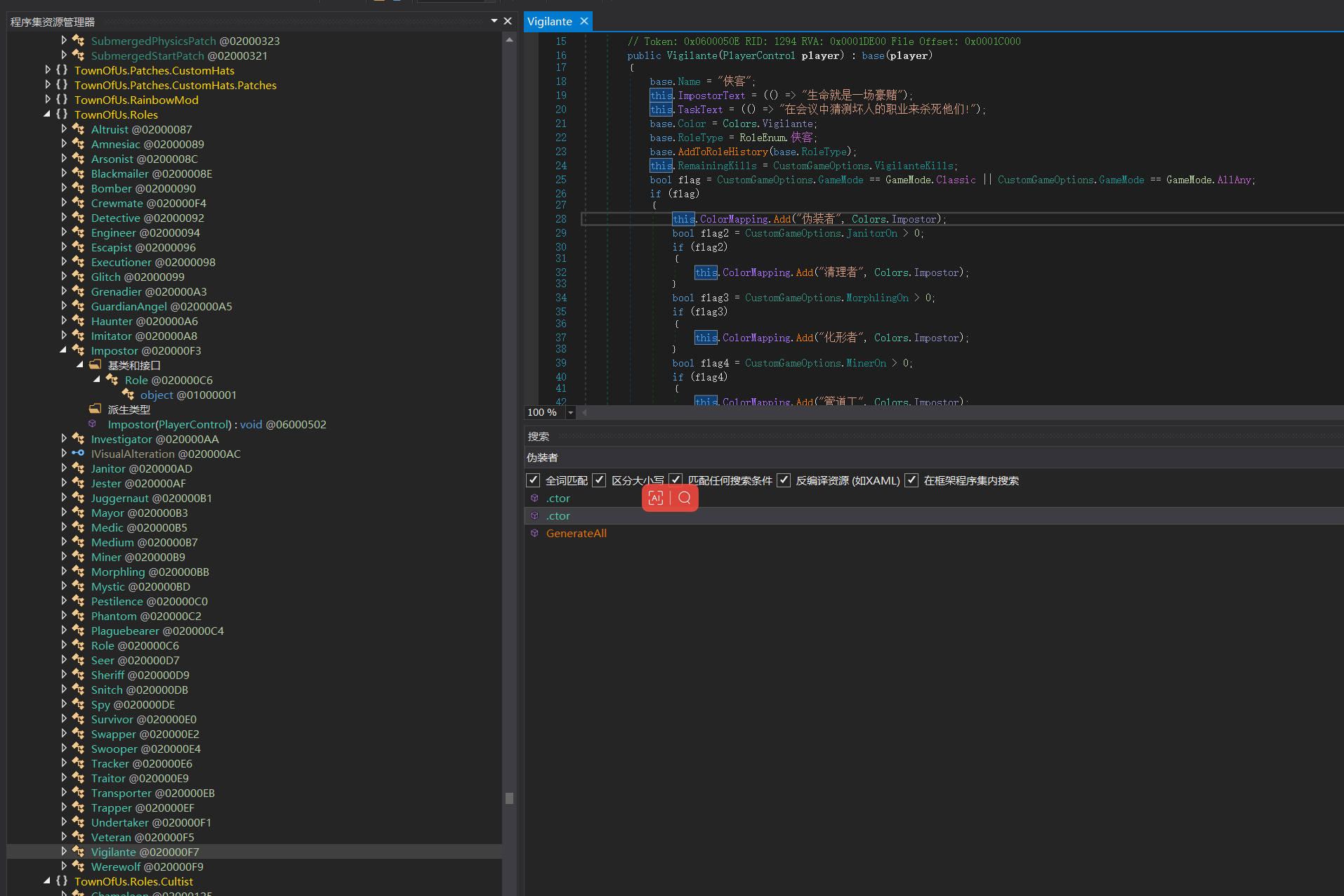
同级下有个Impostor的类,翻译过来就是伪装者,是伪装者的类定义,伪装者名字的定义就是password
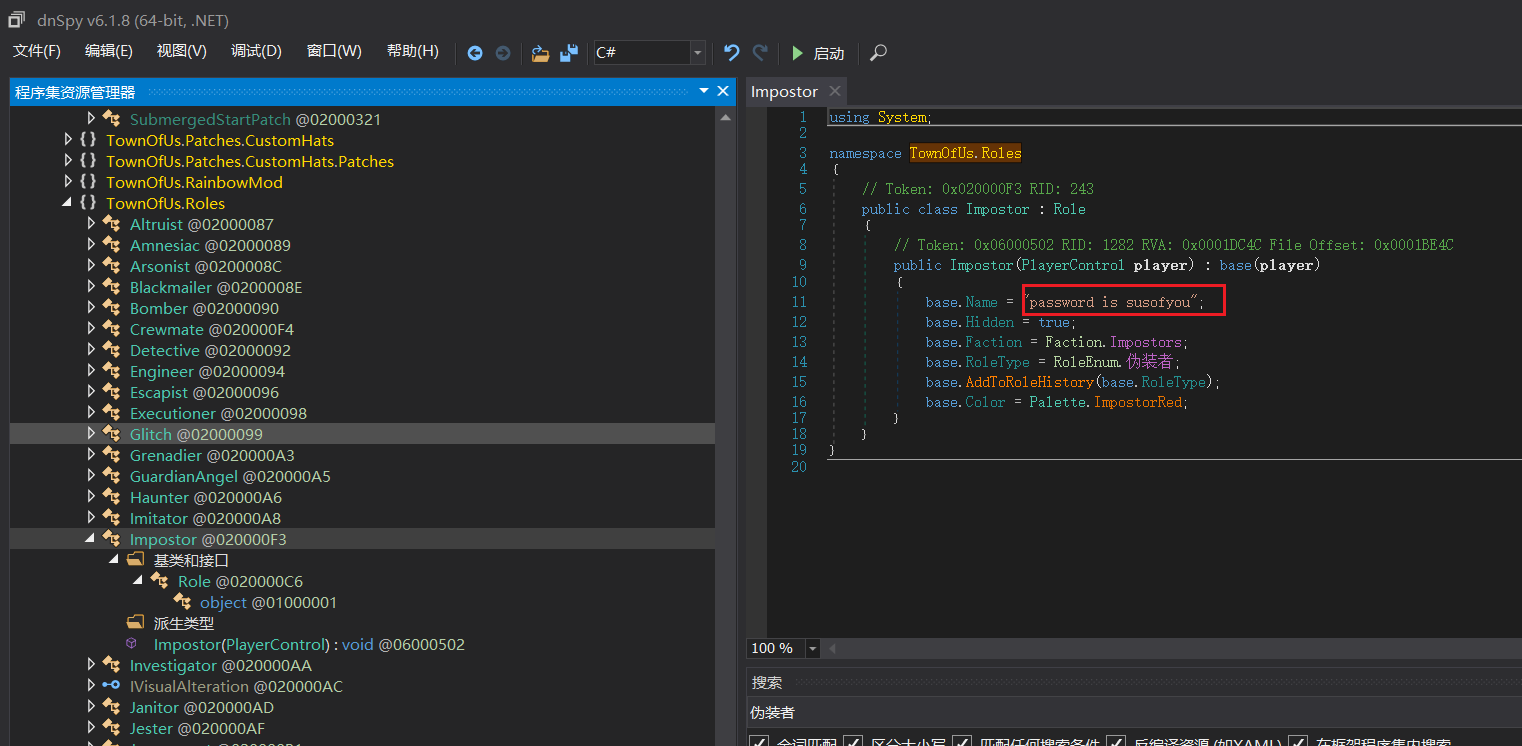
更简单粗暴的做法可能是ida直接字符串搜password?

解开solve.py提示我们需要找到四个变量,房间名称,游戏名称,获胜方式,完成任务数量
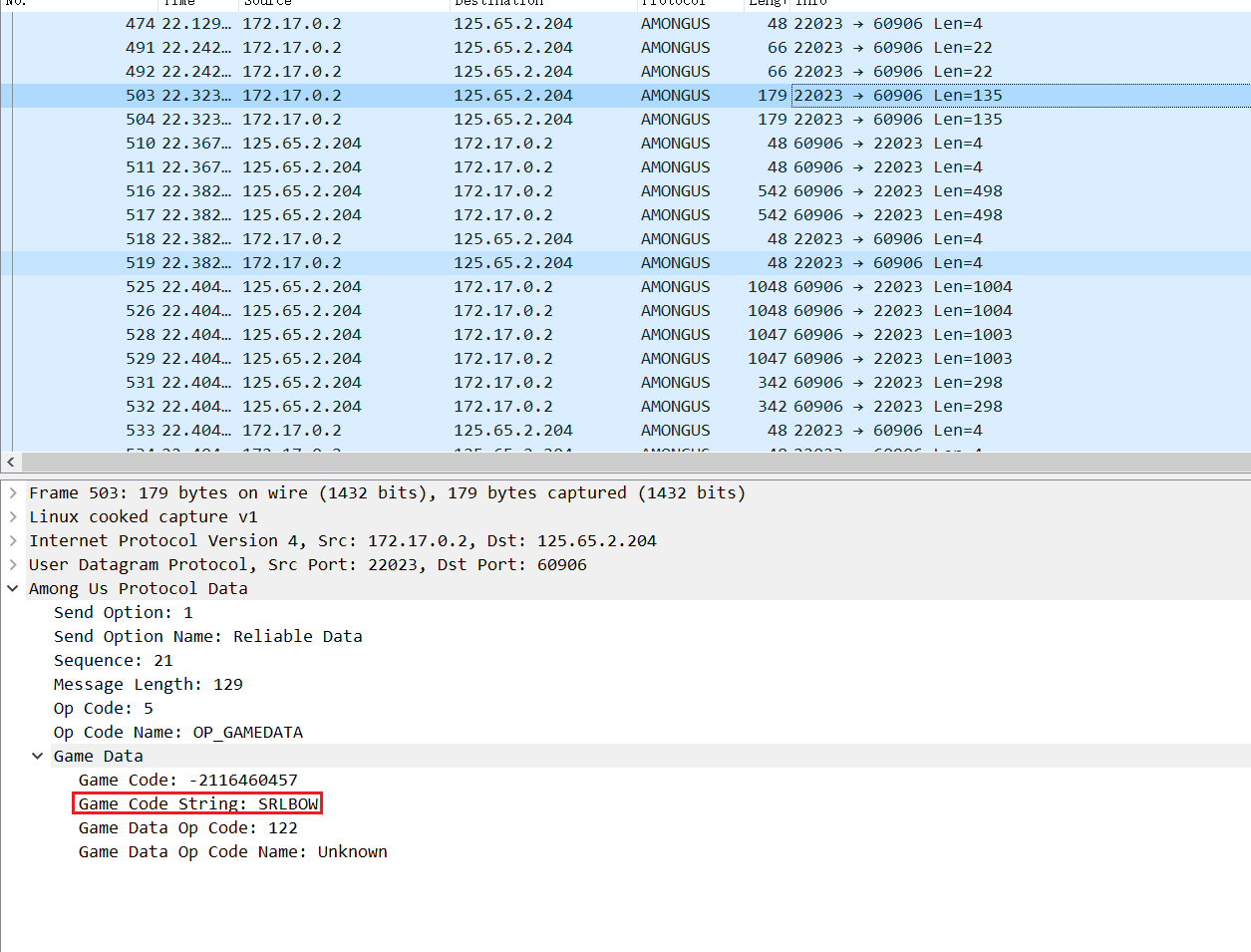
github上关于amongus流量的解析roobscoob/among-us-protocol: A writeup of the network protocol used in Among Us, a game by Innersloth. (github.com)
lua插件cybershard/wireshark-amongus (github.com)
加入lua插件解析之后可以马上得到code是SRLBOW
voted ISCC
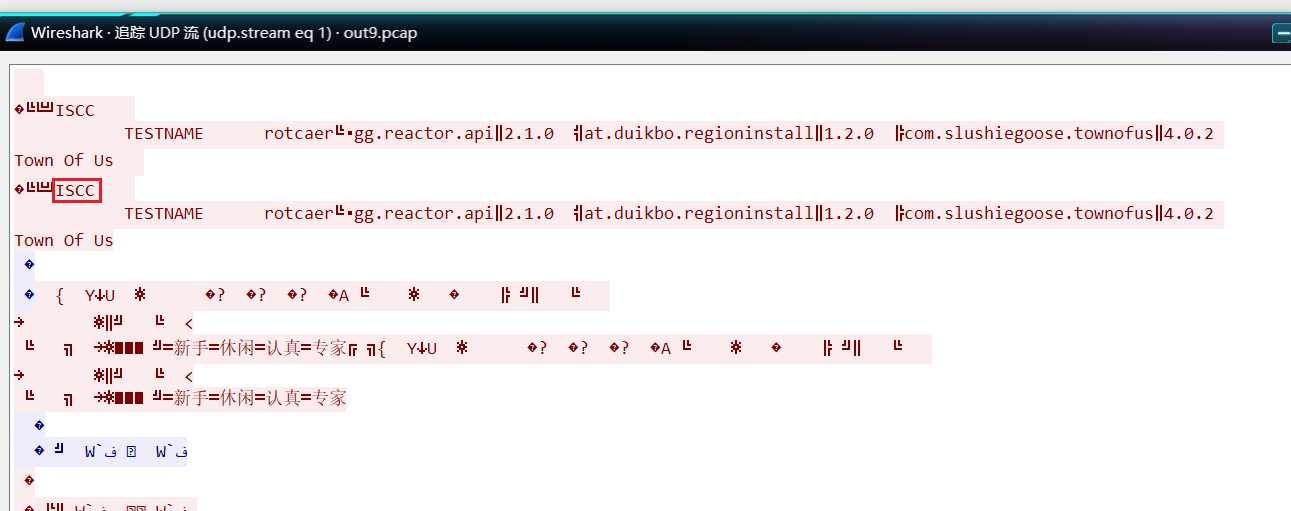
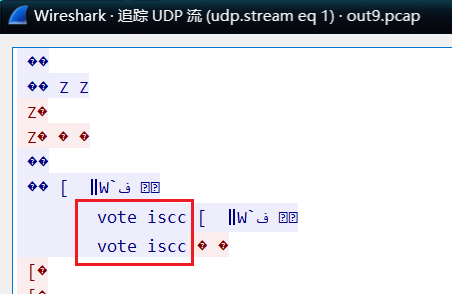
howtowin crew_vote
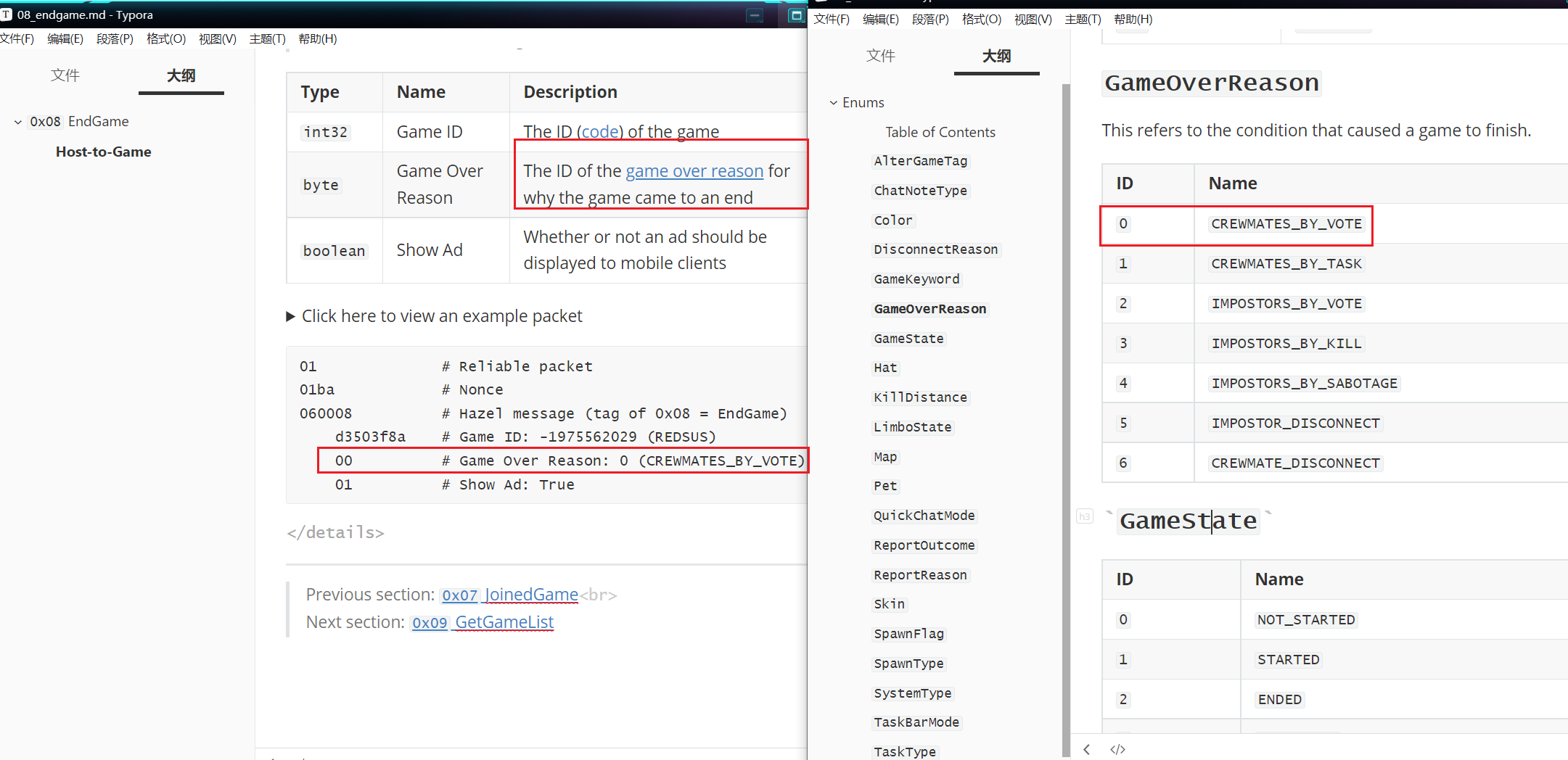
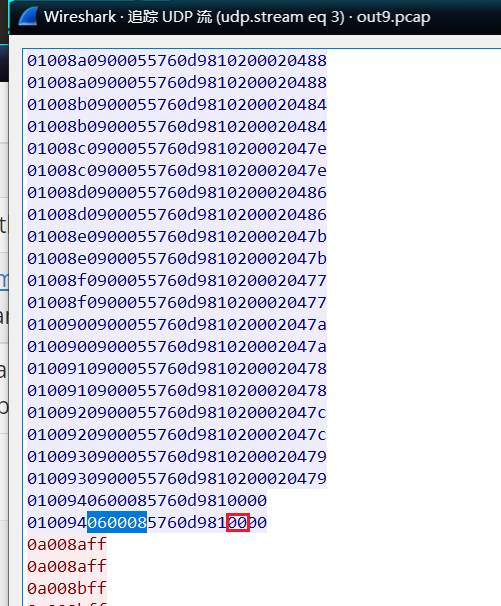
最后一个tasks_num 2
完成第一个任务
完成第二个任务
import hashlib#analyze the .pcap answer the questioncode = 'SRLBOW' #join the game's Game code(eg:ABCD)voted = 'ISCC'#who was voted in this game(the game's name)(eg:dingzhen)howtowin = 'crew_vote'#how win this game?choose:(crew_vote/crew_task/imp_vote/imp_task/imp_disconnect/crew_disconnect)(eg:imp_task)tasks_num = '2'#how many tasks were done?(eg:5)flag = hashlib.md5((code+voted+howtowin+tasks_num).encode()).hexdigest()#eg:md5('ABCDdingzhenimp_task5') = ca90ed3a8c98ef30af3b44643de8512e
print(f'your flag is ISCC{{{flag}}}')#eg:your flag is ISCC{ca90ed3a8c98ef30af3b44643de8512e}
#ISCC{016f115d998e20b5754f42175ac96da4}
G9的钢琴曲
开头密码题exp:解得keyISCC_Y0u_R3alLy_KnOw_CoPPersm1th
from Crypto.Util.number import *
# from libnum import *out =[(2172252055704676687457456207934570002654428519127702486311980109116704284191676330440328812486703915927053358543917713596131304154696440247623888101060090049, 2108637380559167544966298857366809660819309447678518955440217990535095703498823529603132157555536540927898101378853427638496799467186376541583898176373756917, 1103840869050032098984210850630584416814272073121760519116633450832540460407682739594980752914408375293588645043889636184344774987897378026909963273402766561), (2000124088829445641229622245114189828522912764366697463519930724825924163986998694550757186794149331654420524788899548639866463311104678617705042675360057243, 1665549488322348612920659576773850703765765307223600084262385091708189142517147893842872604879786471376822691498663100028754092239272226011616462859779271025, 990627294315894701092445987317798430568264256978762186489740206376279178571289900941886873570710241025125621594301020499270029956301204583788447662869037315), (1303516450844607175859180241406482278674954250245197644105258810912430306740632927947088058701010631209652921073238771523431247167608544636294883977018097199, 1119758042346732592435539174564881640374540951155805649314246375263320107846465196580695284748429608544175058830657524095385658523219250943378976577225782230, 598915905620934628053505443816290720352232457144997188593150390072666051798491983452700635551081569466232682512362475354896855707688259553722701065491789402), (2463333340881549805545364706970314608937871808508385657282029236077808399479795853056347857164089991597487727014937851894809199639758978587612411591527423763, 673590616457425981268507673967667728811152404125286063856277932080928372715113304373395326309595915550999528364692493169822993967220858400311382215177833045, 208198360150172881237486434064181246031019081636219908755237161625039285165750040108367852136975511290424988781713799103150982065579123496034803730006273360)]# clean data
ns = [o[0] for o in out]
rs = [o[1] for o in out]
cs = [o[2] for o in out]
# calculate T_i for each polynomial
calcT = lambda idx : crt([0 if i != idx else 1 for i in range(4)], ns)# calculate Ts
T = [calcT(i) for i in range(len(ns))]
# print(T)
#下面就是calcT函数的意义
# print(crt([1,0,0,0],ns))
# print(crt([0,1,0,0],ns))
# print(crt([0,0,1,0],ns))
# print(crt([0,0,0,1],ns))# construct the final polynomial
f = 0
P.<x> = PolynomialRing(Zmod(prod(ns)))# use pad to add known bits
pad = bytes_to_long(b'ISCC' + b'\x00' * 59)
m = x + pad# construct g(x)
for i in range(4):f += T[i] * (m^4 + 3*m^2 + rs[i]*m - cs[i])
root = f.small_roots(X=2^472, epsilon=0.03)[0]
m = m(root)
print(long_to_bytes(int(m)))
#ISCC_Y0u_R3alLy_KnOw_CoPPersm1th
那个hint.txt不知道啥用,music.rar一眼cloakify,可能hint.txt提示cloakify?不过不知道他怎么藏的
用他自带的desserts密码库解
python2 decloakify.py music.rar .\ciphers\desserts > 1.wav
得到的-+一眼二进制
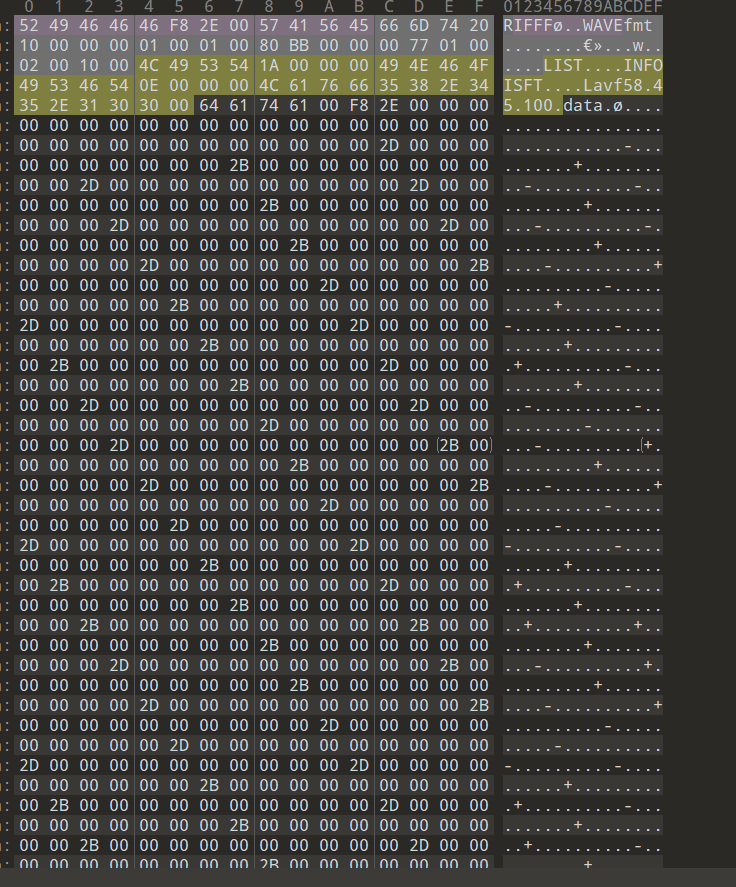
with open('1.wav','rb') as f:hex_list = ("{:02X}".format(int(c)) for c in f.read()) # 定义变量接受文件内容buflist = list(hex_list) # 用列表保存信息,方便后续操作for i in buflist:if i =='2D':print(0,end='')elif i == '2B':print(1,end='')
BNG
不好说
通过给出的例子以及题目描述可以得知bng的结构与png和jpg都相关
通过对比可以得知文件头与png相似,组成部分是BNG和宽高位深度数据,以及每一块之前都有4字节来提示这个块的大小
颜色块很明显是bzip压缩得来的,解压后可以发现与jpg的颜色块很相似,因此得知这里使用了范式huffman压缩算法来压缩颜色数据
同时,每个大块是以四个字节的00来分割的,并在最后的颜色块与结尾块之间留了一位隐写位
前置的范式huffman编码解码(来源:https://www.cnblogs.com/kentle/p/14725589.html):
from tqdm import tqdm
from typing import Dict, List, Tupledef int_to_bytes(n: int) -> bytes:"""返回整数对应的二进制比特串 例如 50 -> b'\x50'"""return bytes([n])class Node:"""Node结点,用于构建二叉数"""def __init__(self, value, weight, lchild, rchild):self.value = valueself.weight = weightself.lchild = lchildself.rchild = rchildclass Huffman:"""Huffman编码"""@staticmethoddef bytes_fre(bytes_str: bytes):"""统计目标文本的字符频数, 返回频数字典例如b'\x4F\x56\x4F' -> {b'\x4F':2, b'\x56':1}"""fre_dic = [0 for _ in range(256)]for item in bytes_str:fre_dic[item] += 1return {int_to_bytes(x): fre_dic[x] for x in range(256) if fre_dic[x] != 0}@staticmethoddef build(fre_dic: Dict[bytes, int]) -> Dict[bytes, str]:"""通过字典构建Huffman编码,返回对应的编码字典例如 {b'\x4F':1, b'\x56':1} -> {b'\x4F':'0', b'\x56':'1'}"""def dlr(current: Node, huffman_code: str, _huffman_dic: Dict[bytes, str]):"""递归遍历二叉树求对应的Huffman编码"""if current is None:returnelse:if current.lchild is None and current.rchild is None:_huffman_dic[current.value] = huffman_codeelse:dlr(current.lchild, huffman_code + '0', _huffman_dic)dlr(current.rchild, huffman_code + '1', _huffman_dic)if not fre_dic:return {}elif len(fre_dic) == 1:return {value: '0' for value in fre_dic.keys()}# 初始化森林, 权重weight小的在后node_lst = [Node(value, weight, None, None)for value, weight in fre_dic.items()]node_lst.sort(key=lambda item: item.weight, reverse=True)# 构建Huffman树while len(node_lst) > 1:# 合并最后两棵树node_2 = node_lst.pop()node_1 = node_lst.pop()node_add = Node(None, node_1.weight +node_2.weight, node_1, node_2)node_lst.append(node_add)# 调整森林index = len(node_lst) - 1while index and node_lst[index - 1].weight <= node_add.weight:node_lst[index] = node_lst[index - 1]index = index - 1node_lst[index] = node_add# 获取Huffman编码huffman_dic = {key: '' for key in fre_dic.keys()}dlr(node_lst[0], '', huffman_dic)return huffman_dic@classmethoddef to_canonical(cls, huffman_dic: Dict[bytes, str]) -> Dict[bytes, str]:"""将Huffman编码转换成范氏Huffman编码"""code_lst = [(value, len(code)) for value, code in huffman_dic.items()]code_lst.sort(key=lambda item: (item[1], item[0]), reverse=False)value_lst, length_lst = [], []for value, length in code_lst:value_lst.append(value)length_lst.append(length)return cls.rebuild(value_lst, length_lst)@staticmethoddef rebuild(char_lst: List[bytes], length_lst: List[int]) -> Dict[bytes, str]:"""以范氏Huffman的形式恢复字典"""huffman_dic = {value: '' for value in char_lst}current_code = 0for i in range(len(char_lst)):if i == 0:current_code = 0else:current_code = (current_code + 1) << (length_lst[i] - length_lst[i - 1])huffman_dic[char_lst[i]] = bin(current_code)[2::].rjust(length_lst[i], '0')return huffman_dic@staticmethoddef decode(str_bytes: bytes, huffman_dic: Dict[bytes, str], padding: int, visualize: bool = False):"""Huffman解码输入待编码文本, Huffman字典huffman_dic, 末端填充位padding返回编码后的文本"""if not huffman_dic: # 空字典,直接返回return b''elif len(huffman_dic) == 1: # 字典长度为1,添加冗余结点,使之后续能够正常构建码树huffman_dic[b'OVO'] = 'OVO'# 初始化森林, 短码在前,长码在后, 长度相等的码字典序小的在前node_lst = [Node(value, weight, None, None)for value, weight in huffman_dic.items()]node_lst.sort(key=lambda _item: (len(_item.weight), _item.weight), reverse=False)# 构建Huffman树while len(node_lst) > 1:# 合并最后两棵树node_2 = node_lst.pop()node_1 = node_lst.pop()node_add = Node(None, node_1.weight[:-1:], node_1, node_2)node_lst.append(node_add)# 调整森林node_lst.sort(key=lambda _item: (len(_item.weight), _item.weight), reverse=False)# 解密文本read_buffer, buffer_size = [], 0# 生成字符->二进制列表的映射dic = [list(map(int, bin(item)[2::].rjust(8, '0')))for item in range(256)]# 将str_bytes转化为二进制列表for item in str_bytes:read_buffer.extend(dic[item])buffer_size = buffer_size + 8read_buffer = read_buffer[0: buffer_size - padding:]buffer_size = buffer_size - paddingwrite_buffer = bytearray([])current = node_lst[0]for pos in tqdm(range(0, buffer_size, 8), unit='byte', disable=not visualize):for item in read_buffer[pos:pos + 8]:# 根据二进制数移动currentif item:current = current.rchildelse:current = current.lchild# 到达叶结点,打印字符并重置currentif current.lchild is None and current.rchild is None:write_buffer.extend(current.value)current = node_lst[0]return bytes(write_buffer)@staticmethoddef encode(str_bytes: bytes, huffman_dic: Dict[bytes, str], visualize: bool = False) -> Tuple[bytes, int]:"""Huffman编码输入待编码文本, Huffman字典huffman_dic返回末端填充位数padding和编码后的文本"""bin_buffer = ''padding = 0# 生成整数->bytes的字典dic = [int_to_bytes(item) for item in range(256)]# 将bytes字符串转化成bytes列表read_buffer = [dic[item] for item in str_bytes]write_buffer = bytearray([])# 循环读入数据,同时编码输出for item in tqdm(read_buffer, unit='byte', disable=not visualize):bin_buffer = bin_buffer + huffman_dic[item]while len(bin_buffer) >= 8:write_buffer.append(int(bin_buffer[:8:], 2))bin_buffer = bin_buffer[8::]# 将缓冲区内的数据填充后输出if bin_buffer:padding = 8 - len(bin_buffer)bin_buffer = bin_buffer.ljust(8, '0')write_buffer.append(int(bin_buffer, 2))return bytes(write_buffer), paddingclass OVO:VERBOSE = 0b10 # -v 显示进度@classmethoddef decode_as_huffman(cls, str_bytes: bytes, mode: int):"""以huffman编码解码输入byte串,返回解码后的byte串"""padding = str_bytes[0]max_length = str_bytes[1]length = list(str_bytes[2:2 + max_length:])char_num = sum(length)# 如果length全零,那么表示256个字符全在同一层if char_num == 0 and max_length != 0:char_num = 256length[max_length - 1] = 256# 计算出还原huffman码表所需的信息char_lst, length_lst = [], []for pos in range(2 + max_length, 2 + max_length + char_num):char_lst.append(int_to_bytes(str_bytes[pos]))for i in range(max_length):length_lst.extend([i + 1] * length[i])# 重构码表code_dic = Huffman.rebuild(char_lst, length_lst)# huffman解码str_bytes = str_bytes[2 + max_length + char_num::]write_buffer = Huffman.decode(str_bytes, code_dic, padding, bool(mode & cls.VERBOSE))return write_buffer@classmethoddef encode_as_huffman(cls, str_bytes: bytes, mode: int):"""以huffman编码的形式编码文件输入bytes串,返回编码后的比特串"""fre_dic = Huffman.bytes_fre(str_bytes)code_dic = Huffman.build(fre_dic)code_dic = Huffman.to_canonical(code_dic)max_length = 0for code in code_dic.values():max_length = max(max_length, len(code))length_lst = [0 for _ in range(max_length + 1)]for code in code_dic.values():length_lst[len(code)] += 1# 要是256个字符全部位于同一层,使用全零标记if length_lst[max_length] == 256:length_lst[max_length] = 0length_lst.pop(0) # 码长为0的字符并不存在,故删去# 将码表信息转化成bytes类型code_bytes = b''.join(code_dic.keys())length_bytes = b''.join(map(int_to_bytes, length_lst))# huffman编码temp_buffer, padding = Huffman.encode(str_bytes, code_dic, bool(mode & cls.VERBOSE))# 合并结果code_data = int_to_bytes(max_length) + length_bytes + code_byteswrite_buffer = int_to_bytes(padding) + code_data + temp_bufferreturn write_buffer@classmethoddef decode(cls, fp_in, mode: int = 0):fp_out = cls.decode_as_huffman(fp_in, mode)return fp_out@classmethoddef encode(cls, fp_in, mode: int = 0):fp_out = cls.encode_as_huffman(fp_in, mode)return fp_outbng2png转换器(包含隐写位读取)
from OVO import OVO
from PIL import Image
import bz2def bng2png(bngfile, pngfile):data = open(bngfile, 'rb').read()width, height = int.from_bytes(data[8:12], 'big'), int.from_bytes(data[12:16], 'big')pngimg = Image.new('RGB', (width, height))collen = int.from_bytes(data[21:25], 'big')col = OVO.decode(bz2.decompress(data[25:25+collen]), False)for y in range(height):for x in range(width):pngimg.putpixel((x, y), (col[0], col[1], col[2]))col = col[3:]pngimg.save(pngfile)def getsecret(bngfile):data = open(bngfile, 'rb').read()collen = int.from_bytes(data[21:25], 'big')secret = data[25+collen:25+collen+1].decode()return secretsecret = ''
for i in range(471):bngfile = 'bngs/' + str(i) + '.bng'pngfile = 'decimg/' + str(i) + '.png'bng2png(bngfile, pngfile)secret += getsecret(bngfile)
print(secret)转换结果

以及可以得到隐写位置的数据
Vm1wR2EwNUhTWGxVYms1cFRUSjRWbFl3WkRSWFJteHpZVVZPYWxadGVIcFdNbmgzWVRBeFZrNVdaRnBXVmxwUVdWVmFTbVF3TVZWWGJHUlRUVEJLVVZkV1dsWmtNbEY1Vkd0c1ZHSkdXazlaYlhSTFpVWmFSMWR0Um1waVZscFlWako0VjFWdFJqWmlTRUpYWWtkb1JGcFhlR0ZTVmtaelZHMXNhR1ZzV2toV1JscHZVakZhYzFwRmJGSmlSVXBoVm1wT1QwMHhVbGRYYkU1clVsUkdWMVJzWkRSV01WcEhWMnh3VjJFeGNGUldha1pyWkVaS2RWTnNhR2xpUlhCWFYxY3dNVkV5UmtkaVJtUlhWMGRvVUZscmFFTlRWbkJKWWpOa1VWVlVNRGs9解7次base64后:my secret password:75ce46be8882436396c25c9b1f76b37e
ocr(ddddocr)
import ddddocr
res = ''
ocr = ddddocr.DdddOcr()
for i in range(471):with open('images/{}.png'.format(i), 'rb') as f:img_bytes = f.read()tmp = ocr.classification(img_bytes).replace('o', '0')res += tmp
print(res)ocr的结果解hex后保存为压缩包,使用隐写位里面隐写的密码即可解开
听你心跳里的狂
自己出的题没想到被非预期了(
贴个预期解吧
不过折磨到一些人感觉非常不错)
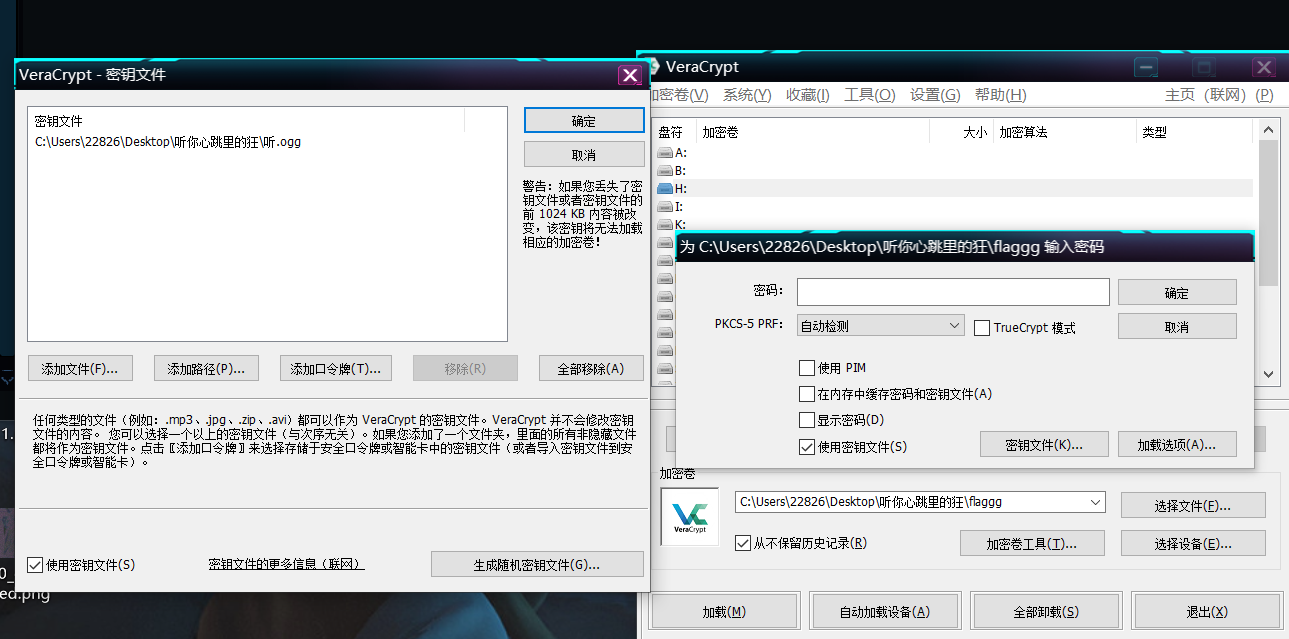
首先拿到一个ogg音频文件和一个flaggg文件,flaggg文件16进制数据是个乱码,但根据其长度恰好为10mb,猜测是VC容器,将ogg音频文件作为密钥文件成功挂载
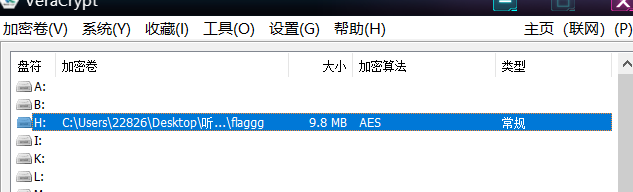
在挂载的磁盘里得到一个压缩文件,在结尾处可以找到一串字符
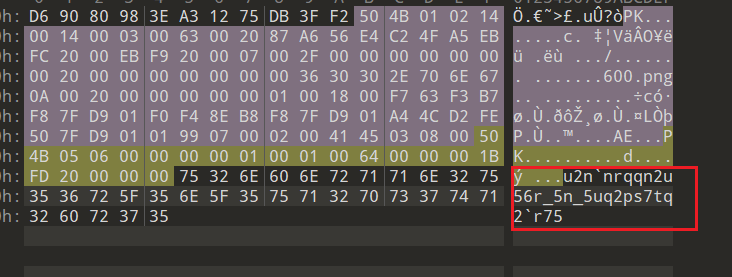
解rot13+rot47可以得到一串md5值
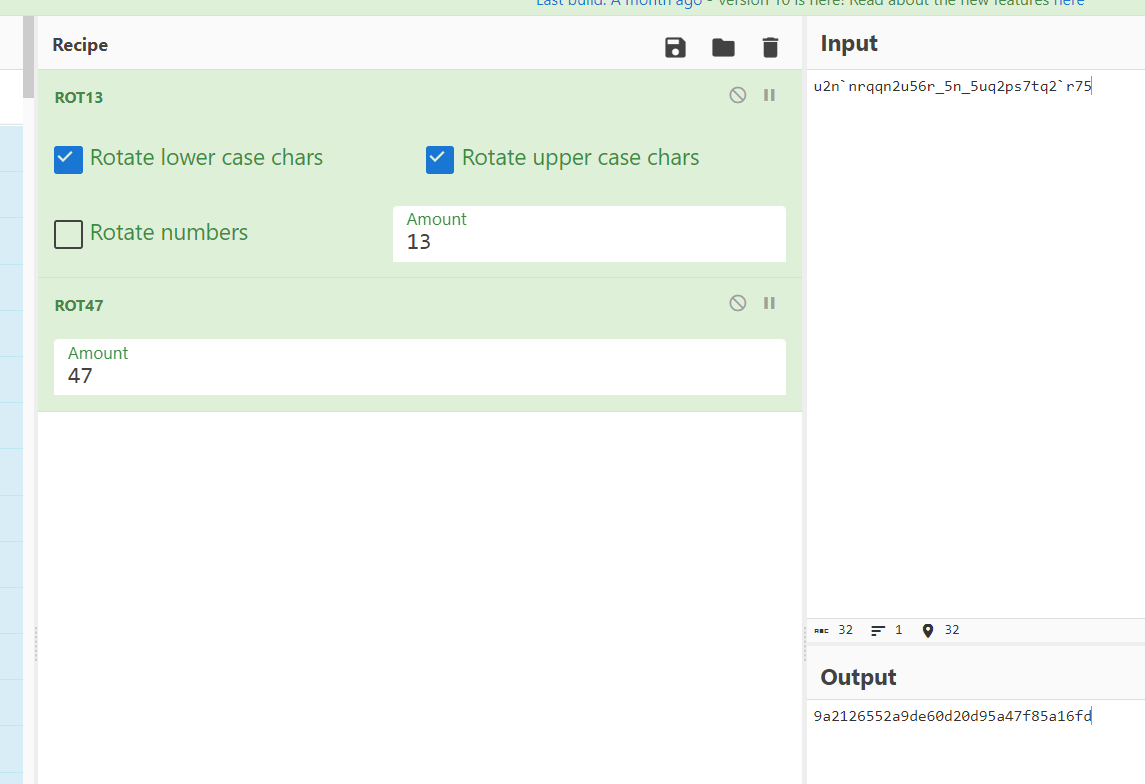
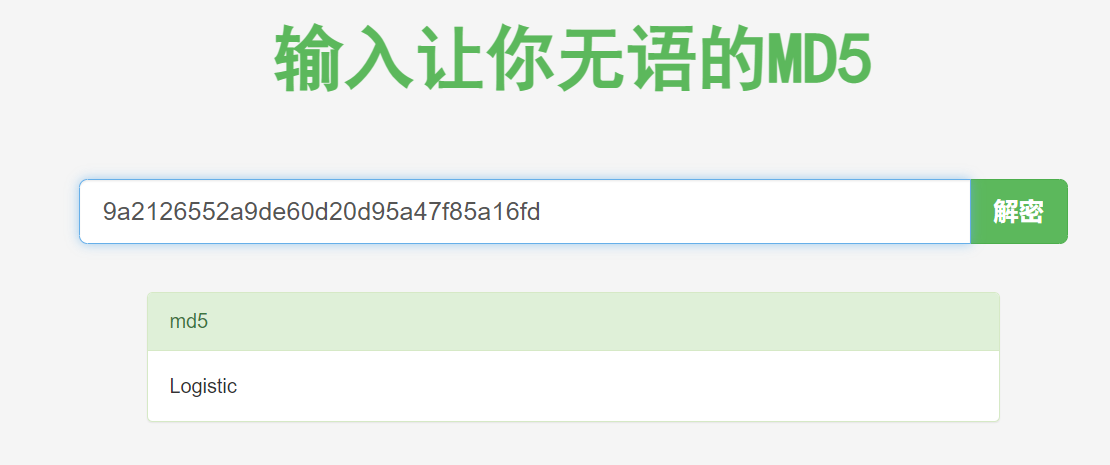
放入somd5或者cmd5里可以解得压缩包密码Logistic
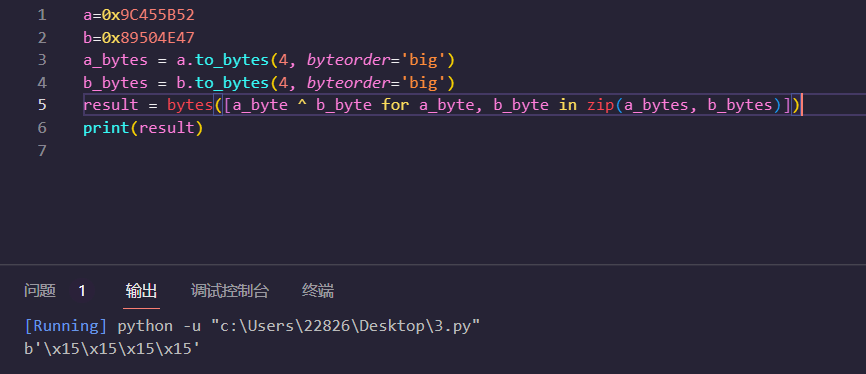
解得png文件,但无法直接打开,16进制也为乱码,根据文件后缀提示为png,将文件头与png文件头逐字节异或发现得到都是0x15,将整个文件与0x15异或得到原png文件
根据压缩包密码Logistic,可以知道图片是由Logistic加密算法加密,根据图片名知道需要迭代混沌600次,不知道r和x0参数,爆破一下即可
这里有点小问题,本来为了降低难度图片名给的是
迭代次数_参数1_参数2.png,结果主办方上的不是最终附件导致图片名是600.png,只有迭代次数,不过问题不大小小爆破一下就好了
最终解密脚本:
import matplotlib.pyplot as plt
from PIL import Image
import numpy as npdef logic_decrypt(im, x0, r):xsize, ysize = im.sizeim = np.array(im).flatten()#返回一个一维数组num = len(im)#print(num)for i in range(600):#迭代600次,达到充分混沌状态x0 = r * x0 * (1-x0)#系统方程形式E = np.zeros(num)#产生一维混沌加密序列E[0] = x0for i in range(0,num-1):E[i+1] = r * E[i]* (1-E[i])E = np.round(E*255).astype(np.uint8)#归一化序列im = np.bitwise_xor(E,im)#异或操作加密im = im.reshape(ysize,xsize,-1)#转化为二维混沌加密序列im = np.squeeze(im)im = Image.fromarray(im)im.save(f"png/{x0}_{r}.png")return im
lists = np.arange(0, 10.1, 0.1).tolist()
x0_list = [round(num, 1) for num in lists]
r_list = [round(num, 1) for num in lists]
im = Image.open("600.png")
for x0 in x0_list:for r in r_list:im_de = logic_decrypt(im, x0, r)
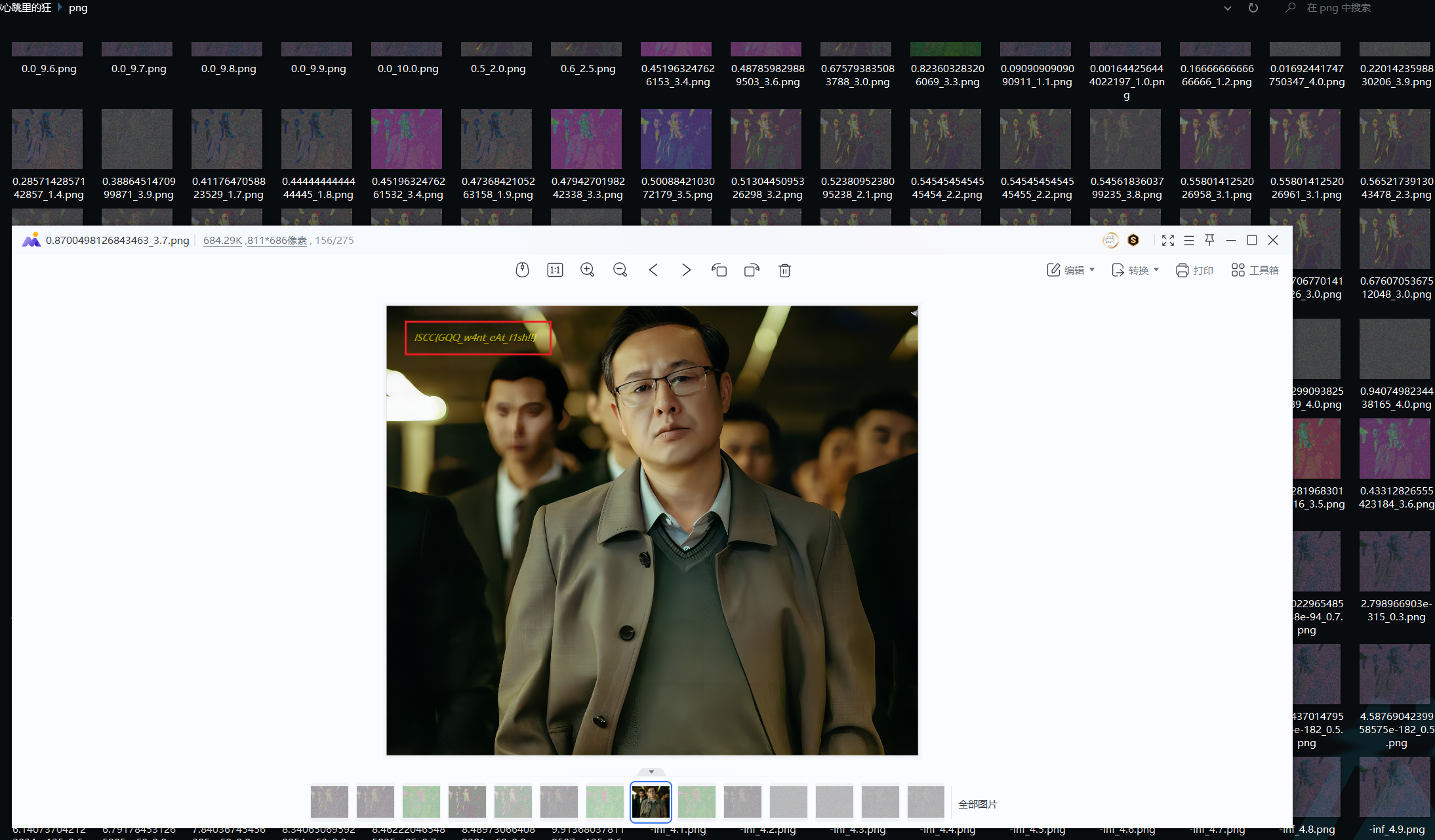
左上角得到flag
非预期之xor后硬看)
Brain Games
压缩包注释aaencode,把?改回成表情,解得密码Peace_And_Love
看底下数字键盘可以猜到是数字键盘密码,中间6个弹孔对应6位长度和顺序,顺序是依照子弹裂痕,后发的裂痕会在碰到前发的裂痕后停止,得到顺序是570831

cloacked-pixel得到
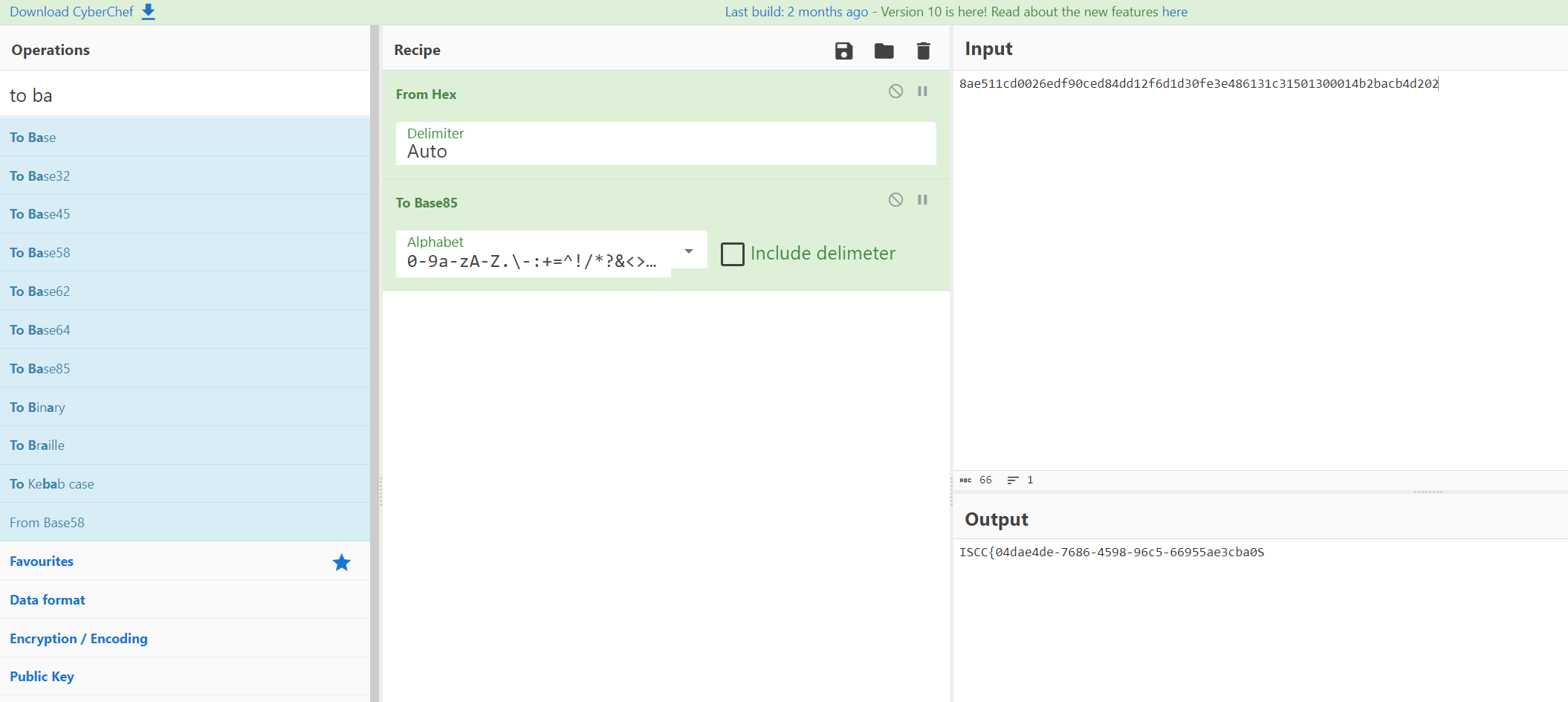
8ae511cd0026edf90ced84dd12f6d1d30fe3e486131c31501300014b2bacb4d202
然后就又是抽象的时刻了,fromhex tobase85,最后一个S改成}就好了
Guess!Where?
密码半脑洞,长度64密文也很规整,直接解base64解不了,凯撒3-base64-base32-base16
I_love_iscc!!!
后面又是大大的脑洞
通过按时间顺序排序,发现01文件夹内多插入了ISC23五个文件夹
将其内容输出,发现两个一组刚好可以对应26个字母,将其转换一下

后面结尾的flag也在提示这几部分对应的是flag,去掉flag之后前面的字符刚好可以连成一句话,再结合ISCC应该有两个C,C文件夹应该被读取两次

最终脚本:
得到flagilikeiscchowaboutyou
import osdef read_files_in_directory(directory):for root, dirs, files in os.walk(directory):for file in files:file_path = os.path.join(root, file)with open(file_path, 'r',encoding='utf-8') as f:content = f.read()# print(f"{file_path}:{content}")content_lists = [content[i:i+2] for i in range(0, len(content), 2)]print(file_path,':',end='')for i in content_lists:print(chr(int(i)+96),end='')print()# 获取当前目录
current_directory = os.getcwd()
dirlists=['I','S','C','C','2','3']
# dirlists=['I']
for i in dirlists:read_files_in_directory(os.path.join(current_directory, i))






![构建docker镜像时,报错:ERROR: unexpected status code [manifests latest]: 403 Forbidden](https://img-blog.csdnimg.cn/4013a5cc513447329e1104f90f310762.png)