前言
1、使用映射类型来定义同一个索引中的多种文档类型
2、可以在映射中使用的不同字段类型
3、使用预定义的字段及其选项
4、上述这些如何帮助数据的索引、更新和删除
内容
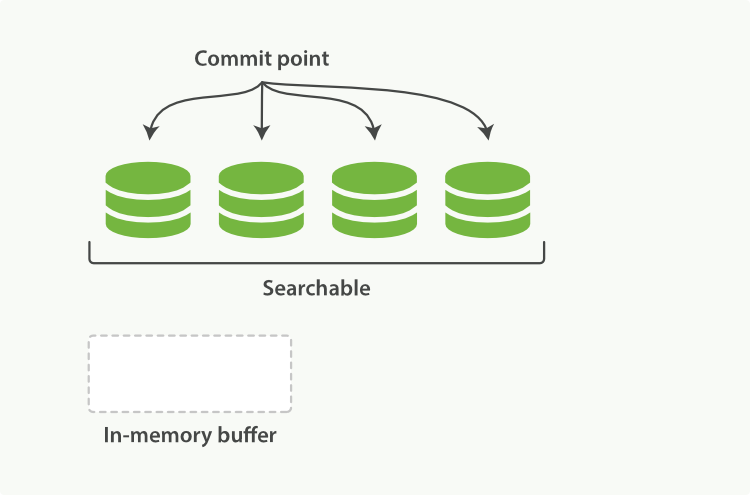
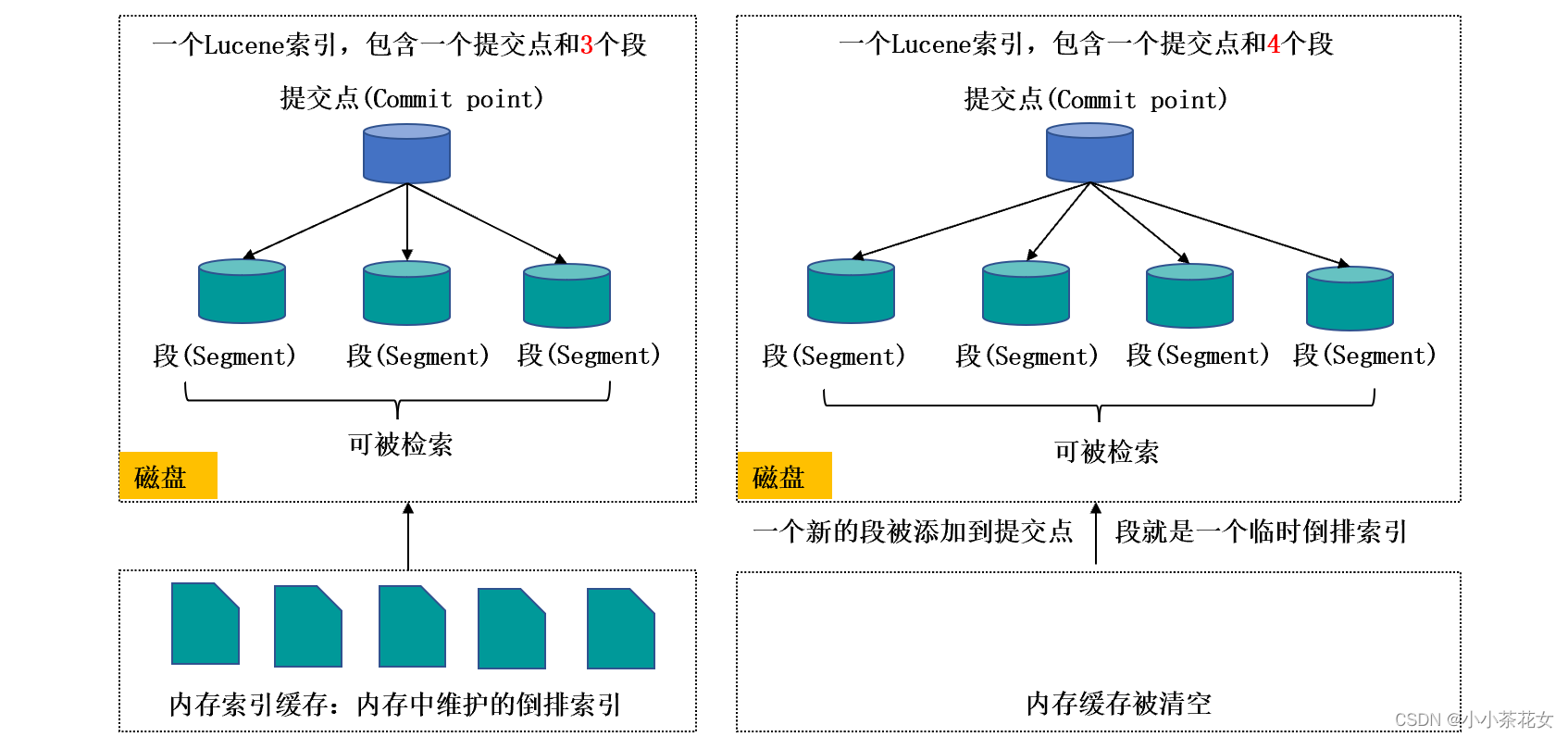
3种类型字段,这些字段是元数据,es会自动管理它们
核心——这些字段包括字符串和数值型
数组和多元字段——这些字段在某个字段中存储相同核心类型的多个值。例如,tags字段可以拥有多个标签
预定义——这些字段包括_ttl和_timestamp
使用映射来定义各种文档
1、获取目前映射,新建类型的时候,如果不知道字段的映射,es会自动创建映射。
curl 'localhost:9200/get-together/group/_mapping?pretty'2、定义新的映射(创建索引之后,可以向某类型中插入任何文档之前顶一个新的映射)
curl -XPUT 'localhost:9200/get-together/_mapping/new-events' -d '{"new-events" : {"properties" : {"host" : {"type" : "string"}}}
}3、扩展现有的映射:如果某个类型的映射目前含有两个来自初始映射的字段,外加定义的一个新字段。随着新字段的加入,初始的映射被扩展了,任何时候都支持这样的操作。es将此称为现有映射和先前提供的映射的合并。
- 并非所有的合并都是奏效的,例如:无法改变现有字段的数据类型,而且通常无法改变一个字段被索引的方式。合并操作失败会抛出:MergeMappingException的异常
解决方式:重新索引类型中的所有数据
(1)将类型里的所有数据移除,移除数据的时候也会移除现有的映射
(2)设置新的映射
(3)再次索引所有的数据
4、映射的同时可以设置许多的分析选项,eg:可以配置分析,生成原始词条的同义词,这样的同义词的查询同样可以匹配。index选项可以设置为:analyzed(默认)、not_analyzed或no。例如,将name字段设置为not_analyzed:
curl -XPUT 'localhost:9200/get-together/_mapping/new-events' -d '{"new-events" : {"properties" : {"name" : {"type" : "string","index" : "not_analyzed"}}}
}'用于定义文档字段的核心类型
1、字符串类型
新增一条文档记录
curl -XPUT 'localhost:9200/get-together/new-events/1' -d '{"name": "Late Night with Elasticsearch","date": "2013-10-25T19:00"
}'搜索单词late
curl 'localhost:9200/get-together/new-events/_search?pretty' -d '{"query": {"query_string": {"query": "late"}}
}'注意:搜索字符串的时候,需要考虑索引过程中的字符串有没有被分析;搜索条件的字符串有没有被分析
2、数值类型
数值类型可以是浮点数,也可以是非浮点数。非小数:byte、short、int或者long。小数:float和double。谨慎选择数值类型,对它们选择将会影响索引的大小,以及能够索引的取值范围。不知道所需要的整型数字取汁范围或者是浮点数字的精度,让es自动检测映射更为安全:为整数值分配long,浮点数值分配double。索引可能变得更大、变得更慢,因为这种类型占据了更多空间,但是,在索引的过程中es不会发生超出范围的错误。
3、日期类型
设置日期字段映射的时候,设置日期的format形式。运作过程:通常提供一个表示日期的字符串,es解析这个字符串,将其作为long的数值存入Lucene的索引。搜索文档的时候,提供date的字符串,在后台es会将这个日期字符串解析并按照数值来处理。这样做的原因是字符串相比数值型,数值在存储和处理时更快。
使用format选项来自定日期格式选择:
- 使用预定义的日期格式
- 设置自己定制的格式
curl -XPUT 'localhost:9200/get-together/_mapping/weekly-events' -d '{"weekly-events" : {"properties" : {"next_event" : {"type" : "date","format" : "MMM DD YYYY"}}}
}'curl -XPUT 'localhost:9200/get-together/weekly-events/1' -d '{"name" : "Elasticsearch News","first_occurence" : "2011-04-03","next_event" : "Oct 25 2013"
}'4、布尔类型
boolean类型用于存储文档中的true/false(真/假)。值为true或者false的字段,会被自动映射为boolean,在Lucene的索引中被存储为代表true的T,或者代表false的F,es解析文档中的值,将true和false分别转化为T和F。
数组和多字段
1、数组
如果索引拥有多个值的字段,将这些值放入方括号中。无须手动映射定一个数组,映射会将多个值的字段定义为单个值所属的核心类型。所有核心类型都支持数组,无须修改映射,既可以使用单一值,也可以使用数组。对于Lucene内部而言,两者基本一致,在同一个字的中索引或多或少的词条,完全取决你提供了多少值。
curl -XPUT 'localhost:9200/blog/posts/1' -d '{"tags": ["first", "initial"]
}'curl -XPUT 'localhost:9200/blog/_mapping/posts?pretty'{"blog": {"mappings": {"posts": {"properties": {"tags": {"type": "string"}}}}}
}2、多字段
数组允许使用同一个设置索引多项数据,多字段允许使用不同的设置,对同一项数据索引多次。无须重新索引数据,就能将单字段升级到多字段。多字段也允许在单一字段中拥有多个核心类型的值。
//要搜索analyzed版本的标签字段,就像搜索其他字段一样。如果要搜索not_analyzed版本的字段(仅仅精确匹配原有的标签),就要指定完整的路径:tags.verbatim。
curl -XPUT 'localhost:9200/blog/_mapping/posts' -d '{"posts": {"properties": {"tags": {"type": "string","index": "analyzed","fields": {"verbatim": {"type": "string","index": "not_analyzed"}}}}}
}'使用预定义字段
更新现有文档
删除数据
小结
1、当多个类型种出现同样的字段名称时,两个同名的字段应该有同样的设置。否则es很难辨别你所指的是两个字段中的哪一个。两个字段都是属于同一个Lucene索引。比如:分组和活动文档中,出现了name字段,name字段应该是字符串的,不能一个是字符串一个是数值的。
2、使用类型划分同一索引中的数据。搜索可以在一个、多个或者所有类型中运行

3、为什么不能直接改变一个现有字段的映射?
想象一下以及索引了一个活动,某个字段是字符串,想要通过定义映射的方式,改变现有字段的映射,此时,es不得不改变该字段在现有文档中的索引方式。其实,编辑现存文档意味着删除和再次索引。正确的映射,理想情况下只需要增加,而无须修改。
4、索引过程和搜索过程的区别参考如下链接:
https://blog.csdn.net/wbiblem/article/details/72823779