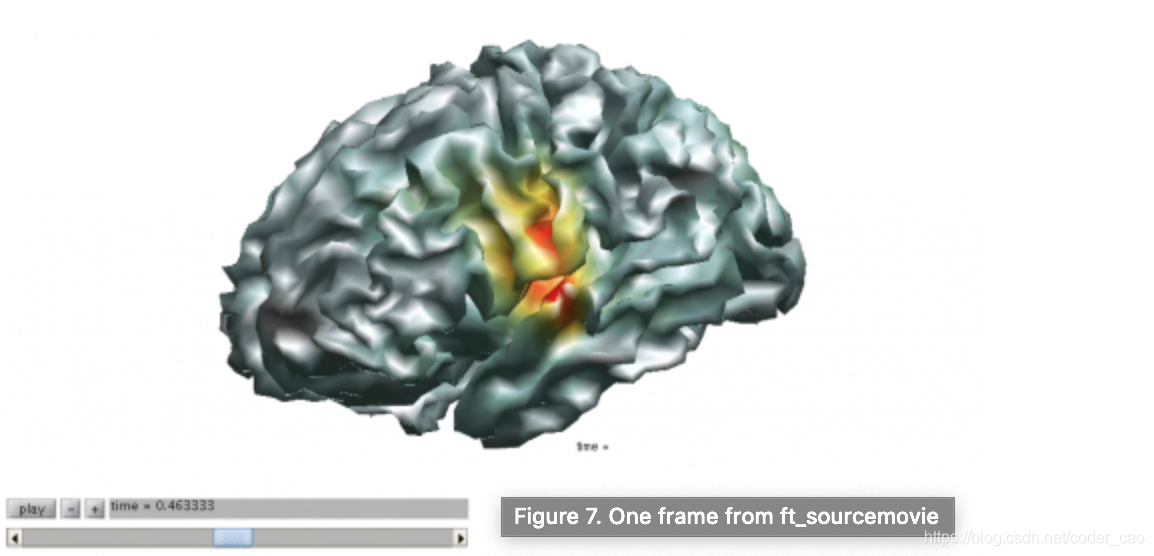
FieldTrip是MEG, EEG, iEEG和NIRS分析的MATLAB软件工具箱。它提供预处理和先进的分析方法,如时频分析,使用偶极子的源重建,分布源和波束形成器和非参数统计测试。
介绍
ft_preprocessing的一种常见用法是完全读取内存中的连续数据。如果数据集相对较小并且计算机具有足够的内存来一次将所有数据保存在内存中,则利用ft_preprocessing是可行的。
背景
使用这种方法,可以将文件中的所有数据读取到内存中,应用过滤器,然后将数据分割为感兴趣的数据段。
过程
采取以下步骤来读取数据、应用过滤器、参考数据(针对EEG数据),可选地在事件或触发器周围选择感兴趣的数据片段,或者将连续的数据切割成合适的等长片段。
使用ft_preprocessing读取EEG通道的数据,应用滤波器并重新参考相连的乳突;
使用ft_preprocessing读取水平和垂直EOG通道的数据,并计算水平和垂直双极EOG偏差。
使用ft_appenddata将EEG和EOG合并为单个数据表示形式
使用ft_definetrial根据触发事件确定感兴趣的数据片段
使用ft_redefinetrial将连续数据分段到试验中
使用ft_redefinetrial将连续数据分段为一秒的片段
本教程中使用的数据集
在本教程中,我们将使用两个数据集,一个带有EEG数据,另一个带有MEG数据。
Irina Siminova在一项研究以图片,视觉显示的文字或听觉呈现的单词表示的刺激的语义处理的研究中,获得了EEG数据集SubjectEEG.zip。采用64通道脑产品脑电放大器,60个头皮电极置于电极帽内,其中一个电极置于右眼下方获取数据。采集后使用重新参考计算信号“EOGv”和“EOGh”。在采集过程中,所有通道均以左乳突为参考,并在耳垂处放置一个电极作为接地。通道1-60对应于位于头部的电极,但位于右侧乳突的通道53除外。通道61、62、63根本不连接到电极。通道64连接到位于左眼下方的电极。因此,我们有62个感兴趣的频道:60个来自头部+ eogh + eogv。
MEG数据集Subject01.zip是Lin Wang在语义一致和不一致句子的语言研究中获取。实验中使用了三种类型的句子:完全一致(FC)、完全不一致(FIC)和初始一致(IC)。三种条件中每一种条件都有87个试验,并添加了一组87个填充句。
将连续的EEG数据读入内存
预处理并将数据读入内存的最简单方法是是只使用数据集作为配置参数调用ft_preprocessing函数。
cfg = [];
cfg.dataset = 'subj2.vhdr';
data_eeg = ft_preprocessing(cfg)>> data_eeg
data_eeg =hdr: [1x1 struct]label: {64x1 cell}trial: {[64x1974550 double]}time: {[1x1974550 double]}
fsample: 500cfg: [1x1 struct]
这将从文件中读取数据作为一个长连续段,而不需要任何额外的过滤。所得数据表示为一项非常长期的试验。要绘制其中一个通道的电位,您可以简单地使用MATLAB plot函数。
chansel = 1;
plot(data_eeg.time{1}, data_eeg.trial{1}(chansel, :))
xlabel('time (s)')
ylabel('channel amplitude (uV)')
legend(data_eeg.label(chansel))
将连续的MEG数据读入内存
如果磁盘上的数据以分段或epoched的格式存储,即文件格式已经反映了实验中的试验,则对ft_preprocessing的调用将返回正在读取的数据并将其分段成原始试验的数据。
cfg = [];
cfg.dataset = 'subj2.vhdr';
data_eeg = ft_preprocessing(cfg)>> data_eeg
data_eeg =hdr: [1x1 struct]label: {64x1 cell}trial: {[64x1974550 double]}time: {[1x1974550 double]}
fsample: 500cfg: [1x1 struct]
该已分割的MEG数据集包含266个试验。以下示例显示了如何在试验的子集中绘制数据。
for trialsel=1:10chansel = 1; % this is the STIM channel that contains the triggerfigureplot(data_meg.time{trialsel}, data_meg.trial{trialsel}(chansel, :))xlabel('time (s)')ylabel('channel amplitude (a.u.)')title(sprintf('trial %d', trialsel));
end
如果要强制将epoched的数据解释为连续数据,则可以使用cfg.continuous选项,如下所示:
cfg = [];
cfg.dataset = 'Subject01.ds';
cfg.continuous = 'yes'; % force it to be continuous
data_meg = ft_preprocessing(cfg);chansel = 2; % this is SCLK01
plot(data_meg.time{1}, data_meg.trial{1}(chansel, :))
xlabel('time (s)')
ylabel(data_meg.label{chansel})
如果放大并仔细查看SCLK01通道,您会发现每3秒会有一次小跳跃。这是由于数据在磁盘上是不连续的,即只有3秒的片段包含每个刺激存储在磁盘上,而在试验之间的数据不存储。因此,MEG频道每3秒也会有一次小跳动,故不应将此特定数据集解释为连续记录。许多其他CTF记录存储在磁盘上,每个数据段的时间为10秒。这些可以解释为连续的,因为长段之间没有间隙。
预处理,过滤和重新参考
在对该脑电图数据进行预处理时,必须考虑参考数据的选择。在采集过程中,EEG放大器的参考通道连接到左乳突。我们想使用相连乳突参考(也称为平均乳突参考)来分析此数据。此外,通过计算在眼睛周围水平和垂直放置的电极的双极偏差,可以方便地检测眼睛的运动和眨眼伪像。
BrainAmp Recorder软件中配置的通道名称与电极帽中位置的标签相对应。这些电极的位置编号为1到60,并且对应的通道名称(如ASCII字符串)为“ 1”,“ 2”,……“ 60”。通道53对应于右乳突。由于左乳突在采集中用作参考,因此在数据文件中未将其表示出来(因为根据定义,该电极处的电压为零)。
cfg = [];
cfg.dataset = 'subj2.vhdr';
cfg.reref = 'yes';
cfg.channel = 'all';
cfg.implicitref = 'M1'; % the implicit (non-recorded) reference channel is added to the data representation
cfg.refchannel = {'M1', '53'}; % the average of these two is used as the new reference, channel '53' corresponds to the right mastoid (M2)
data_eeg = ft_preprocessing(cfg);
为了保持一致性,我们将位于右侧乳突的名称为“53”的通道重命名为“M2”
chanindx = find(strcmp(data_eeg.label, '53'));
data_eeg.label{chanindx} = 'M2';
如果要丢弃不再需要的通道,我们可以进行如下操作
cfg = [];
cfg.channel = [1:61 65]; % keep channels 1 to 61 and the newly inserted M1 channel
data_eeg = ft_preprocessing(cfg, data_eeg);
如果查看数据,我们将看到它包含一个试验。一次试验代表了完整的连续记录,因此大约需要一个小时。
plot(data_eeg.time{1}, data_eeg.trial{1}(1:3,:));
legend(data_eeg.label(1:3));
随后,我们读取水平EOG的数据
cfg = [];
cfg.dataset = 'subj2.vhdr';
cfg.channel = {'51', '60'};
cfg.reref = 'yes';
cfg.refchannel = '51';
data_eogh = ft_preprocessing(cfg);
在数据的这种表示形式中,结果通道51参考了自身,这意味着它包含零值。可以通过以下方式检查
figure
plot(data_eogh.time{1}, data_eogh.trial{1}(1,:));
hold on
plot(data_eogh.time{1}, data_eogh.trial{1}(2,:),'g');
legend({'51' '60'});
为方便起见,我们将通道60重命名为EOGH,并再次使用ft_preprocessing函数选择水平EOG通道并丢弃虚拟通道。
data_eogh.label{2} = 'EOGH';cfg = [];
cfg.channel = 'EOGH';% nothing will be done, only the selection of the interesting channel
data_eogh = ft_preprocessing(cfg, data_eogh);
使用通道50和64之间的差异作为双极EOG,以类似方式完成垂直EOG的处理
cfg = [];
cfg.dataset = 'subj2.vhdr';
cfg.channel = {'50', '64'};
cfg.reref = 'yes';
cfg.refchannel = '50'
data_eogv = ft_preprocessing(cfg);data_eogv.label{2} = 'EOGV';cfg = [];
cfg.channel = 'EOGV';
% nothing will be done, only the selection of the interesting channel
data_eogv = ft_preprocessing(cfg, data_eogv);
现在,我们已经将EEG数据重新参考到乳突以及水平和垂直双极EOG,我们可以使用以下方法将三个原始数据结构组合为单个表示形式:
cfg = [];
data_all = ft_appenddata(cfg, data_eeg, data_eogh, data_eogv);
在上面的示例中,我们并没有将过滤器应用于数据。当然我们可以在初始预处理/读取过程中将过滤器应用于数据。之后也可以通过调用ft_preprocessing函数并将数据作为第二个输入参数来应用过滤器。如果要将不同的预处理选项(例如,EEG通道的过滤器,EMG通道的校正,重新参考)应用于不同的通道,则应使用每种通道类型的所需选项调用ft_preprocessing,随后添加不同的渠道类型的数据到一个原始数据结构。
将连续数据分割为试验
通过特定于读取和通道的预处理,您可以根据触发代码识别感兴趣的数据片段,并将连续数据分割为试验。让我们首先看看数据se中出现的不同触发代码
cfg = [];
cfg.dataset = 'subj2.vhdr';
cfg.trialdef.eventtype = '?';
dummy = ft_definetrial(cfg);
这将在屏幕上显示事件类型和值。
evaluating trialfunction 'trialfun_general'
the following events were found in the datafile
event type: 'New Segment' with event values:
event type: 'Response' with event values: 'R 8'
event type: 'Stimulus' with event values: 'S 1' 'S 12' 'S 13' 'S 21' 'S 27' 'S111''S112' 'S113' 'S121' 'S122' 'S123' 'S131' 'S132' 'S133' 'S141' 'S142' 'S143''S151' 'S152' 'S153' 'S161' 'S162' 'S163' 'S171' 'S172' 'S173' 'S181' 'S182''S183' 'S211' 'S212' 'S213' 'S221' 'S222' 'S223' 'S231' 'S232' 'S233' 'S241''S242' 'S243'
no trials have been defined yet, see FT_DEFINETRIAL for further help
found 1570 events
created 0 trials
触发代码S111,S121,S131,S141分别对应于所呈现的4种不同动物的图片。触发代码S151,S161,S171,S181对应于4种不同工具的显示图片。我们可以选择以下动物和工具类别的数据
cfg = [];
cfg.dataset = 'subj2.vhdr';
cfg.trialdef.eventtype = 'Stimulus';
cfg.trialdef.eventvalue = {'S111', 'S121', 'S131', 'S141'};
cfg_vis_animal = ft_definetrial(cfg);cfg.trialdef.eventvalue = {'S151', 'S161', 'S171', 'S181'};
cfg_vis_tool = ft_definetrial(cfg);
ft_definetrial产生的输出配置包含作为Nx3矩阵的试验定义,包含每个试验的开始样本,结束样本和每次试验的偏移量。原则上,我们现在可以使用此配置从磁盘上的原始数据文件中读取这些段,但是由于我们已经在内存中拥有完整的连续数据所以我们将使用ft_redefinetrial从连续数据段中删除这些片段。
data_vis_animal = ft_redefinetrial(cfg_vis_animal, data_all);
data_vis_tool = ft_redefinetrial(cfg_vis_tool, data_all);
随后,我们可以使用ft_rejectvisual进行伪影检测,以删除带有伪影的试验,并使用ft_timelockanalysis对试验进行平均以获取ERP,或者使用ft_freqanalysis获得两种情况下数据的平均时频表示。如果将ft_timelockanalysis或ft_frequencyanalysis与cfg.keeptrials ='yes'选项一起使用,则可以随后使用ft_timelockstatistics或ft_freqstatistics对这些刺激中的动物工具对比进行统计比较。
将连续数据分割成一秒的片段
对于没有触发器的连续数据处理,可以方便地将数据切割成等长度的片段。这可以在从磁盘读取数据的同时完成,也可以在完整的连续数据在内存中完成。
以下示例显示了如何一次性读取和分段数据。
cfg = [];
cfg.dataset = 'subj2.vhdr';
cfg.trialfun = 'ft_trialfun_general';
cfg.trialdef.triallength = 1; % duration in seconds
cfg.trialdef.ntrials = inf; % number of trials, inf results in as many as possible
cfg = ft_definetrial(cfg);% read the data from disk and segment it into 1-second pieces
data_segmented = ft_preprocessing(cfg);
以下示例显示了如何首先将数据作为单个连续段读取,然后将其切成第二个片段。
% read it from disk as a single continuous segment
cfg = [];
cfg.dataset = 'subj2.vhdr';
data_cont = ft_preprocessing(cfg);% segment it into 1-second pieces
cfg = [];
cfg.length = 1;
data_segmented = ft_redefinetrial(cfg, data_cont);
参考:
http://www.fieldtriptoolbox.org/tutorial/continuous/
文章来源于网络,仅用于学术分享,不用于商业行为,若有侵权及疑问,请后台留言!
如需转载请扫下面微信二维码码,备注"转载"
更多阅读
大脑分区与功能简介汇总
第2期 | 国内脑机接口领域专家教授汇总
精彩长文 | 脑机接口技术的现状与未来!
TensorFlow处理运动想象分类任务
ICA处理脑电资料汇总
收藏 | 脑电EEG基础与处理汇总
脑机接口BCI学习交流QQ群:903290195