YOLOv5介绍
YOLOv5为兼顾速度与性能的目标检测算法。笔者将在近期更新一系列YOLOv5的代码导读博客。YOLOv5为2021.1.5日发布的4.0版本。
YOLOv5开源项目github网址
本博客导读的代码为utils文件夹下的google_utils.py文件,更新日期为2021.1.14.
google_utils.py
该文件负责从github/googleleaps/google drive等网站下下载所需要的的一些文件。
相关导入模块及说明如下所示。
#谷歌云对应的链接
# Google utils: https://cloud.google.com/storage/docs/reference/librariesimport os #与操作系统交互的模块
import platform #提供获取操作系统相关信息的模块
import subprocess #子进程定义及操作的模块
import time #获取系统时间的模块
from pathlib import Path #使字符串路径易于操作的模块import requests #通过urllib3实现自动发送HTTP/1.1请求的第三方模块
import torch #pytorch模块
gsutil_getsize 函数用于返回网站链接对应文件的大小
def gsutil_getsize(url=''):# gs://bucket/file size https://cloud.google.com/storage/docs/gsutil/commands/du#创建一个子进程在命令行执行 gsutil du url命令s = subprocess.check_output(f'gsutil du {url}', shell=True).decode('utf-8')return eval(s.split(' ')[0]) if len(s) else 0 # 返回文件的byte大小
attempt_download 函数实现 从几个云平台下载预训练模型
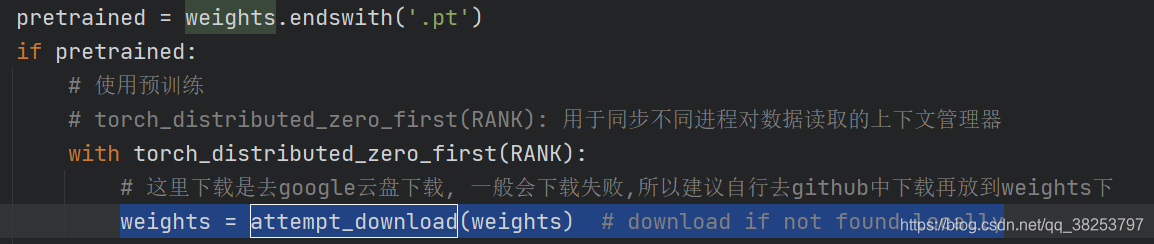
def attempt_download(file, repo='ultralytics/yolov5'):#如果对应的文件不存在 则尝试下载# .strip()删除字符串前后的空格 /n /t等 .replace()将'替换为空格 .lower()将字符串全部转换为小写 Path()将str转换为Path对象file = Path(str(file).strip().replace("'", '').lower())if not file.exists(): #如果这个文件路径 不存在文件try:# 利用github api 获取最新版本相关信息 这里response是一个大字典response = requests.get(f'https://api.github.com/repos/{repo}/releases/latest').json()# response['assets']为包含多个字典的列表 其中记录了每一个asset相关的信息assets = [x['name'] for x in response['assets']] # release assets, i.e. ['yolov5s.pt', 'yolov5m.pt', ...]tag = response['tag_name'] # 当前版本信息i.e. 'v4.0'except: # 退而求其次的计划 利用git命令强行补齐信息assets = ['yolov5.pt', 'yolov5.pt', 'yolov5l.pt', 'yolov5x.pt']tag = subprocess.check_output('git tag', shell=True).decode('utf-8').split('\n')[-2]name = file.name #返回路径最后的文件名称或路径名称if name in assets:# msg 为定义无法下载文件的错误信息msg = f'{file} missing, try downloading from https://github.com/{repo}/releases/'redundant = False # second download optiontry: # 尝试从Github上下载文件 url为文件的精确链接url = f'https://github.com/{repo}/releases/download/{tag}/{name}'print(f'Downloading {url} to {file}...')torch.hub.download_url_to_file(url, file)assert file.exists() and file.stat().st_size > 1E6 # 检查文件是否已经完成下载except Exception as e: # 尝试从googleleaps(云服务器)上下载模型print(f'Download error: {e}')assert redundant, 'No secondary mirror'url = f'https://storage.googleapis.com/{repo}/ckpt/{name}'print(f'Downloading {url} to {file}...')os.system(f'curl -L {url} -o {file}') # torch.hub.download_url_to_file(url, weights)finally:if not file.exists() or file.stat().st_size < 1E6: # 检查文件是否存在 或大小小于10的6次方位file.unlink(missing_ok=True) # 移除部分下载的文件print(f'ERROR: Download failure: {msg}')#打印错误信息print('')return
gdrive_download 函数用于从google drive上下载压缩文件
def gdrive_download(id='16TiPfZj7htmTyhntwcZyEEAejOUxuT6m', file='tmp.zip'):# 从Google Drive上下载文件 from yolov5.utils.google_utils import *; gdrive_download()t = time.time()file = Path(file)cookie = Path('cookie') # gdrive cookieprint(f'Downloading https://drive.google.com/uc?export=download&id={id} as {file}... ', end='')file.unlink(missing_ok=True) # 移除已经存在的文件cookie.unlink(missing_ok=True) # 移除已经存在的cookie# Attempt file downloadout = "NUL" if platform.system() == "Windows" else "/dev/null"#用cmd命令 从google drive上下载文件os.system(f'curl -c ./cookie -s -L "drive.google.com/uc?export=download&id={id}" > {out}')if os.path.exists('cookie'): # 如果文件较大 则需令牌才能够下载s = f'curl -Lb ./cookie "drive.google.com/uc?export=download&confirm={get_token()}&id={id}" -o {file}'else: # 如果文件较小s = f'curl -s -L -o {file} "drive.google.com/uc?export=download&id={id}"'r = os.system(s) # 执行命令并获得返回 如果cmd命令执行成功 则os.system()命令会返回0cookie.unlink(missing_ok=True) # 再次移除已经存在的cookie# 下载错误检查if r != 0:file.unlink(missing_ok=True) #移除部分下载的文件print('Download error ') # raise Exception('Download error')return r# 如果是压缩文件则解压 .suffix方法为获取Path对象的后缀if file.suffix == '.zip':print('unzipping... ', end='')os.system(f'unzip -q {file}') # cmd执行解压命令file.unlink() # 移除zip文件print(f'Done ({time.time() - t:.1f}s)') # 打印下载解压过程所需要的时间return r
get_token 函数用于从cookie文件中获取令牌
def get_token(cookie="./cookie"): #这里是从cookie中获取令牌(token)with open(cookie) as f:for line in f:if "download" in line:return line.split()[-1]return ""
attempt_download 函数中,用github api 获得的response 变量结构如下:

由此可见response是一个字典,其中的assets键对应的值为嵌套列表,其中包含每一个asset对应的详细信息。asset中主要包含官方的预训练模型。