首先先一目了然看一下其目录结构(这些个源码可以在github上下载到,只要在GitHub搜索mace即可):

介绍
MACE(Mobile AI Compute Engine)是一个针对移动异构计算平台优化的深度学习推理框架。MACE提供工具和文档,帮助用户将深度学习模型部署到移动电话、平板电脑、个人电脑和物联网设备上。
架构
下图显示了整个体系结构
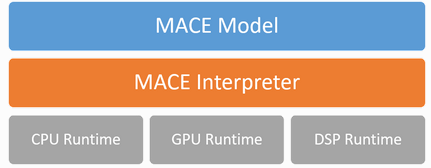
MACE模型
MACE定义了与Caffe2类似的自定义模型格式。MACE模型能够转换TensorFlow、Caffe或ONNX的导出模型。
MACE解释器
Mace解释器主要对NN图进行解析,并对图中的张量进行管理。
运行时
CPU/GPU/DSP运行时对应于不同设备的操作。
工作流程
下图显示了MACE的基本工作流程。

- 配置模型部署文件
模型部署配置文件(.yml)描述了模型和库的信息,MACE将基于该文件构建库。
- 生成库
建立MACE动态或静态库。
- 转换模型
将TensorFlow、Caffe或ONNX模型转换为MACE模型。
- 部署
将MACE库集成到应用程序中,并使用MACE API运行。
- 运行(CLI)
MACE提供了MACE_run命令行工具,可用于运行模型,并根据最初的TensorFlow或Caffe结果验证模型的正确性。
- 基准
MACE提供了基准测试工具来获取模型的操作级分析结果。
浏览一下源码
docker文件夹是几个与docker安装相关的文件。docs文件夹是一些文档,与代码关系不大。third_party和tools文件夹是需要用到的一些第三方模块和代码构建、测试所用到的相关脚本。其中tools/converter.py是构建代码的顶层脚本。
mace/public/mace.h
enum DeviceType { CPU = 0, GPU = 2, HEXAGON = 3, HTA = 4, APU = 5 };enum class DataFormat {NONE = 0, NHWC = 1, NCHW = 2,HWOI = 100, OIHW = 101, HWIO = 102, OHWI = 103,AUTO = 1000,
};enum GPUPerfHint {PERF_DEFAULT = 0,PERF_LOW = 1,PERF_NORMAL = 2,PERF_HIGH = 3
};enum GPUPriorityHint {PRIORITY_DEFAULT = 0,PRIORITY_LOW = 1,PRIORITY_NORMAL = 2,PRIORITY_HIGH = 3
};mace.h文件中定义了三个主要类:RunMetadata、MaceTensor 和 MaceEngine.
RunMetadata:定义了一个public类型的变量 op_stats,类型为vector <OperatorStats>
MaceTensor: 定义了 MACE 输入输出 tensor,有几个不同形式的构造函数
MaceEngine: 作为 MACE 框架引擎,根据构造函数传入的DeviceType执行相应的功能代码// MACE input/output tensor
class MACE_API MaceTensor {friend class MaceEngine;public:// shape - the shape of the tensor, with size n, if shape is unknown// in advance, it should be specified large enough to hold tensor of all// possible size.// data - the buffer of the tensor, must not be null with size equals// shape[0] * shape[1] * ... * shape[n-1].// If you want to pass a buffer which is unsuitable to use the default// shared_ptr deleter (for example, the buffer is not dynamically// allocated by C++, e.g. a C buffer), you can set customized deleter// of shared_ptr and manage the life cycle of the buffer by yourself.// For example, std::shared_ptr<float>(raw_buffer, [](float *){});MaceTensor(const std::vector<int64_t> &shape,std::shared_ptr<void> data,const DataFormat format = DataFormat::NHWC);MaceTensor();MaceTensor(const MaceTensor &other);MaceTensor(const MaceTensor &&other);MaceTensor &operator=(const MaceTensor &other);MaceTensor &operator=(const MaceTensor &&other);~MaceTensor();// shape will be updated to the actual output shape after running.const std::vector<int64_t> &shape() const;const std::shared_ptr<float> data() const;std::shared_ptr<float> data();template <typename T>const std::shared_ptr<T> data() const {return std::static_pointer_cast<T>(raw_data());}template <typename T>std::shared_ptr<T> data() {return std::static_pointer_cast<T>(raw_mutable_data());}DataFormat data_format() const;private:std::shared_ptr<void> raw_data() const;std::shared_ptr<void> raw_mutable_data();private:class Impl;std::unique_ptr<Impl> impl_;
};class MACE_API MaceEngine {public:explicit MaceEngine(const MaceEngineConfig &config);~MaceEngine();MaceStatus Init(const NetDef *net_def,const std::vector<std::string> &input_nodes,const std::vector<std::string> &output_nodes,const unsigned char *model_data);MaceStatus Init(const NetDef *net_def,const std::vector<std::string> &input_nodes,const std::vector<std::string> &output_nodes,const std::string &model_data_file);MaceStatus Run(const std::map<std::string, MaceTensor> &inputs,std::map<std::string, MaceTensor> *outputs);MaceStatus Run(const std::map<std::string, MaceTensor> &inputs,std::map<std::string, MaceTensor> *outputs,RunMetadata *run_metadata);private:class Impl;std::unique_ptr<Impl> impl_;MaceEngine(const MaceEngine &) = delete;MaceEngine &operator=(const MaceEngine &) = delete;
};