相关性研究思路及代码实现(MIC-最大信息系数、Relif-F特征选择算法、pearson、spearman、kendall、卡方检验、fisher精确检验、F检验、简单粗暴的分层聚合)
- 为什么要研究相关性?
- 相关性计算方法选择与代码实现
- 1. 数据预览与清洗
- a. 连续变量
- b. 有序分类变量
- c. 无序分类变量
- d. 二分类变量
- 2. 选择适合的相关性计算方法or验证方法
- a. 业务经验加持下的直观选择。
- b. 通过数学计算得到的相关性
- 常见三大相关系数计算
- Pearson(皮尔森)相关系数
- spearman(斯皮尔曼)相关性系数
- kendall(肯德尔)相关性系数
- 卡方检验
- Fisher精确检验
- F检验(ANOVA, 方差齐性检验)
- MIC-最大信息系数
- 特点
- 计算方法
- 计算步骤
- 代码实现
- Relief 特征选择算法与Relief-F
- 分层聚合统计与数据可视化(简单暴力)
为什么要研究相关性?
工作中经常会有类似相关性验证或探究的过程,出于不同的目的,相关性可以说是做任何数据分析或算法模型的基础。
直观的感觉,我们想知道这几组变量,或者几个因素质检是否存在相关性?是否存在因果关系?或者是某种无法探知到的联系。如果我们能够刻画出这种潜在的规则,便能够方便我们去预测、分类、或者辅助做业务决策。
简而言之,探究相关性可以帮助我们:
-
判断两组变量之间的统计学关联。
注意这里说说的是数学意义上的关联,而非真实意义上的相关性
举个例子:我们想知道收入与消费两组变量之间的相关性,实际上我们是想知道这两者之间是否存在关联。
而我们平时所说的计算pearson相关系数、fisher精确检验等都是从数学定量角度计算而来的”数字“上的”相关性", 结果表明两者具有相关性,并不一定两者现实意义上“相关”这件事说的通。
经常和领导battle举的例子就是,你让我计算公司大楼的高度与我的身高的相关性,兴许统计学上可以计算得到相关,但是它真的是你想要的“找关联”嘛?拿这个结果去汇报会不会被拍死…(最后章节简单说了下如何解决上述问题的思路) -
判断两组变量相关性的强度与方向。
简单说这件事就是告诉我们,如两组变量收入、消费,两者是正向相关还是负向?(方向)关联强度如何,强相关?弱相关?(强度) -
辅助分类、“因果”推断、预测。
这里说的是辅助,一旦确定了两组变量的相关性结论,就可以辅助我们对于某件事件的分类决策、因果关系解释、预测某个变量的未来趋势or数值。
相关性计算方法选择与代码实现
1. 数据预览与清洗
首先我们要搞清楚我们研究的两组或者多组变量是什么数据类型?
a. 连续变量
在一定区间内可以任意取值的变量叫连续变量,其数值是连续不断的,相邻两个数值可作无限分割,即可取无限个数值。如:距离、时间、成绩、体重等。
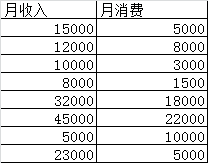
b. 有序分类变量
取值的各类别之间存在着程度上的差别,给人以“半定量”的感觉,因此也称为等级变量 。是根据取值特征而分类的一种定性变量。
如:年龄段、满意度(满意,一般、不满意)、疗效等。
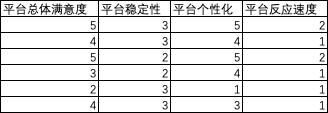
c. 无序分类变量
所分类别或属性之间无程度和顺序的差别。
比如:手机类型(小米、华为、苹果、vivo、三星)
d. 二分类变量
二分类变量即为那些结局只有两种可能性的变量。
比如:(是、否)(死亡、存活)
在明确变量数据类型后,我们才可以“对症下药”,选择合适的相关性计算方法或者分析方法。
除此之外,我们一般尽量不要对变量进行归一化、标准化等scaling的操作,尤其是对于改变变量间分布的操作都不要进行。当然一些对于空值和duplicate的简单清洗还是必须的。
2. 选择适合的相关性计算方法or验证方法
a. 业务经验加持下的直观选择。
之前听一个前辈说过,数学计算只是在验证你的猜想,或者通过量化方式得到一个可能的结果,并不是事务本身应该具有的内在联系。
因此在相关性计算之前,通常我们需要一位业务专家,或者是数据从业人员深入了解业务和行业本身,直观给出一些猜想,那之后你要做的事便是验证此变量的相关性。 例如,收入与高质量活跃用户数有关,血压与血液钠钾比例有关。
b. 通过数学计算得到的相关性
有时候我们可以通过计算多组变量之间的距离、分布、协方差、秩数变化趋势来看多组变量之间的变化关系。
但是两个变量之间存在相关关系,不一定说明两者之间存在着因果关系。因果关系。而是统计学上的一个概念,是指一个变量变化的同时,另一个因素也会伴随发生变化,但不能确定一个变量变化是不是另一个变量变化的原因。举个例子:通过相关系数计算我们得到近5 年大楼的高度和我的身高具有“相关性”,确实都不变。但是只能证明两者间存在变化上的一定关系,并不是决定性的因果关系。
常见三大相关系数计算
Pearson(皮尔森)相关系数
Pearson相关系数是计算连续型正态分布变量质检的线性相关关系的。
前提要求:
- 各组变量必须是连续变量,而非分类变量等。
- 各组变量一定是随机的,呈现正态分布。
- Pearson只是计算“线性”相关,对于非线性相关并没有较强的解释力。
计算公式:
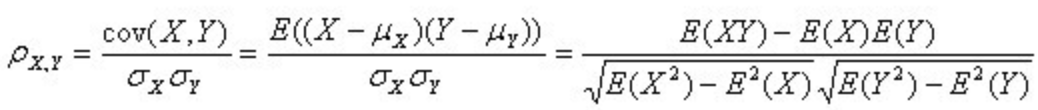
我们可以看到皮尔森系数本质上就是计算两组变量间的协方差,除以两组变量标准差相乘实际上是通过标准化方式剔除了量纲的影响(用皮尔森相关系数的时候不需要事先做标准化等scaler处理)。
此外我们还可以看出,该相关系数无法反映一组变量变化,领一组变量随之变化的幅度,而只是反映随之变化的方向,和随之变化的相似程度。
如果为正,则为正相关,负则为负相关。|0~0.2|为不相关, |0.2~0.4| 为弱相关,|0.40.6|为中等相关,|0.60.8|为强相关,|0.8~1|为极强相关。
显著性检验:
无论是pearson还是后面提到的其他相关性计算方法,都需要考虑到显著性检验。 即便上述相关性系数非常高,但是显著性水平很差,我们也依然不足以说两组变量满足线性相关,有可能是偶发的现象。
显著性水平检验也可以说是一个假设检验,null hypothesis原假设就是两组变量相关性为0,alternative hypothesis备择假设就是相关性不为0。一般p<0.05我们就可以拒绝原假设了,当然主要看我们的阈值。
代码实现与热力图
"""
判断是否为白噪声:
该方法检测是否为正态分布,先检测是否为连续变量
"""def manual_qqnorm(my_array):x = np.arange(-5, 5, 0.1)y = stats.norm.cdf(x, 0, 1)sorted_ = np.sort(my_array)yvals = np.arange(len(sorted_))/float(len(sorted_))x_label = stats.norm.ppf(yvals) #对目标累计分布函数值求标准正太分布累计分布函数的逆plt.scatter(x_label, sorted_)def package_qqnorm(my_array):stats.probplot(my_array, dist="norm", plot=plt)plt.show()
"""
制作相应相关系数热力图
corr的参数设定非常方便,pearson, spearman, kendall等选择对应相关系数
"""
corr = wpj_minmax2.drop(columns=['日期']).corr('pearson')
ax = plt.subplots(figsize=(20, 16))#调整画布大小
ax = sns.heatmap(corr, vmax=.8, square=True, annot=True)#画热力图 annot=True 表示显示系数
# 设置刻度字体大小
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)"""
显著性水平:
结果的第二个元素,就是显著性水平
"""import scipy.stats as stats
correlation, p_value = scipy.stats.pearsonr(x, y)
如下热力图可以方便看到各变量间基于pearson的线性相关系数。(除此之外可以选择其他的spearman,kendall等)。下面我们来简单了解下,其他相关系数的使用场景。
spearman(斯皮尔曼)相关性系数
斯皮尔曼是一种计算秩相关的系数,它比较适用于等级,计算两组变量之间的单调性关系,并且相比pearson具有很好的鲁棒性。特点:
- 如果变量不满足正态分布(不随机),则最好选择spearman而不是pearson.
- 如果不是连续变量,是分类变量等,可以选择spearman.
- 数据必须至少是序数,一个变量上的分数必须与其他变量单调相关。
计算公式-spearman

我们首先对单组变量排序,相同的数排序/n。公式中的d便是两组变量x与y之间的等级差。
最终我们看到的也是两组变量按照排序等级的单调性,来评价他们之间是否具有一定程度上的相关性。
相关性强度参考pearson, 一般小于|0.3| 我们都姑且认为没有相关性。
代码实现-spearman
"""
制作相应相关系数热力图
corr的参数设定非常方便,pearson, spearman, kendall等选择对应相关系数
"""
corr = wpj_minmax2.drop(columns=['日期']).corr('spearman')
ax = plt.subplots(figsize=(20, 16))#调整画布大小
ax = sns.heatmap(corr, vmax=.8, square=True, annot=True)#画热力图 annot=True 表示显示系数
# 设置刻度字体大小
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)
之前自己手撸了一个spearman, 可以有些调整吧…
def spearman(my_array, names=None):"""param1: 重复变量需要用平均秩数param2: p = 1 - (6*sum(d^2))/n*(n^2-1)"""for sort_name in names:my_array = my_array.sort_values(by=sort_name)my_array.reset_index(inplace=True, drop=True)my_array[sort_name+'p'] = my_array.index+1temp = my_array[my_array[sort_name].duplicated(keep=False)]my_index = list(temp[sort_name+'p'])temp_keep = my_array[~(my_array[sort_name+'p'].isin(my_index))]num_list = list(set(temp[sort_name]))for item in num_list:tempp = temp[temp[sort_name]==item]mean_num = tempp[sort_name+'p'].mean()tempp[sort_name+'p'] = mean_numtemp_keep = temp_keep.append(tempp)temp_keep.reset_index(inplace=True, drop=True)temp_keep['d^2'] = temp_keep[names[0]+'p'] - temp_keep[names[1]+'p']temp_keep['d^2'] = temp_keep['d^2'].apply(lambda x: math.pow(x,2))# 计算相关系数n = len(temp_keep[names[0]])p = 1- ((6*(temp_keep['d^2'].sum()))/(n*(n**2 -1)))return pspearman(df, names=['AAAAA','BBBBB'])"""
显著性水平
"""
import scipy.stats as stats
correlation, p_value = scipy.stats.spearmanr(x, y)
kendall(肯德尔)相关性系数
kendall肯德尔相关系数与spearman比较类似,也是衡量分类变量相关性or相似度的。但是有个前提要求,(xi, yi) 尽量是唯一的值,两组基准数组。kendall 更适合评分、排名一致性的检验。
计算公式-kendall
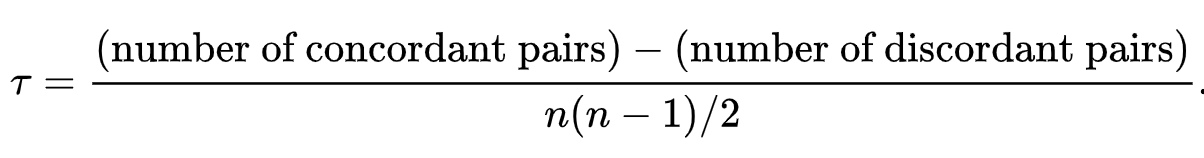
所谓一致对,即为xi < xj 时,有yi < yj, xi > xj 时,有yi > yj。
不一致对则为xi < xj 同时 yi > yj 或者 xi > xj 同时yi > yj.
当xi = xj 时, ji = yj 此时及一致也不一致。
当tau值为1认为一致性是完美的,当tau值为-1认为分歧是完美的,当tau值为0则认为两组变量相互独立。
代码实现-kendall
"""
制作相应相关系数热力图
corr的参数设定非常方便,pearson, spearman, kendall等选择对应相关系数
"""
corr = wpj_minmax2.drop(columns=['日期']).corr('kendall')
ax = plt.subplots(figsize=(20, 16))#调整画布大小
ax = sns.heatmap(corr, vmax=.8, square=True, annot=True)#画热力图 annot=True 表示显示系数
# 设置刻度字体大小
plt.xticks(fontsize=20)
plt.yticks(fontsize=20)"""
计算方法2
"""
from scipy.stats import kendalltau
import numpy as np
a = [1,2,3,4,5,6]
b = [6,7,8,3,9,2]
Lens = len(a)
count = 0
number = 0
for i in range(Lens-1):for j in range(i+1,Lens):count = count + np.sign(a[i] - a[j]) * np.sign(b[i] - b[j])number += 1Kendallta1 = count/(Lens*(Lens-1)/2)
Kendallta2, p_value = kendalltau(a,b)
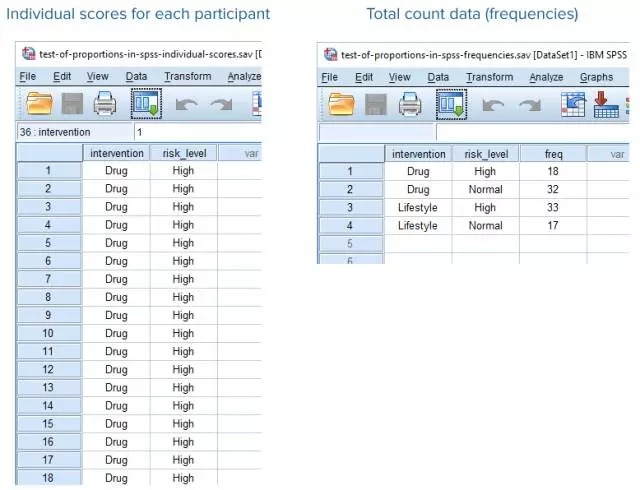
卡方检验
卡方检验是非参数检验,就是我们根本不知道分类变量的分布。
他比较适用于不是连续变量,而是两个二值型离散变量的情况,判断其是否相关。
适合条件:
- 适合离散变量
- 不知道分类变量的分布
- 比较理论频数和实际频数的吻合程度
- 独立性检验的反向检验,如果不独立,那肯定有关联
- 卡方检验受样本量影响很大,两组变量不同的样本量差别很大
- 凡是应用比率进行检验的数据,都可以应用卡方检验
- 只能分析相关的统计学意义,不能反映关联强度
计算思路
其根本思想就是在于比较理论频数和实际频数的吻合程度或拟合优度问题。
四格卡方检验

我们可以看到,
- 实际值:爱吃炸鸡肥胖的频数占比为30.9%,不爱吃炸鸡肥胖频数占比为25%。
- 理论值:肥胖频数占比为28.3%
我们不能单纯从实际值看爱吃炸鸡是否对肥胖有影响,因为有可能存在抽样误差。
为了确定真实原因,我们先假设吃炸鸡对肥胖是没有影响的,即爱吃炸鸡和肥胖不是独立相关的,所以我们可以得出肥胖率理论值是(43+28)/(43+28+96+84)= 28.3%
基于这个假设理论比率,我们得到如下表格:

为了比较理论频数和实际频数的吻合程度或拟合优度,如果吃炸鸡和肥胖真的不是独立相关的,那么四格表里的理论值和实际值差别应该会很小。
卡方检验公式:
实际值与理论值的偏差方差大小与理论值之比。
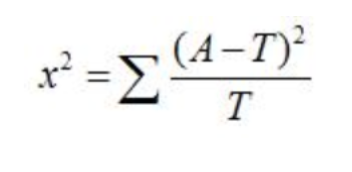
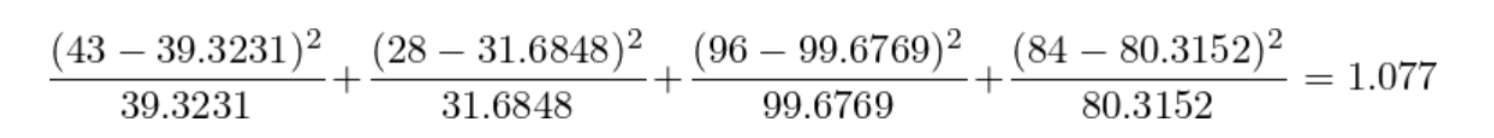
题外话,在自由度大于1、理论数皆大于5时,这种近似很好;当自由度为1时,尤其当1<T<5,而n>40时,应用以下校正公式:

这个0.5叫做连续性修正,简单讲当理论值<5且>1,n>40(or30)的时候,分布类似于泊松分布,而卡方分布又是基于连续性的分布,需要做连续性修正。
连续性修成参考文献:
Confidence Intervals for a Proportion in Finite Population Sampling
建立假设检验:
- 原假设null hypothesis: 实际值与理论值是独立不相关的
- 备择假设alternative hypothesis: 实际值与理论值是独立相关的
我们查询一下chi-square临界表如下图:
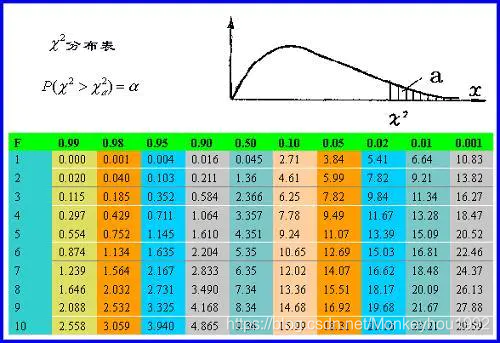
查询临界值就需要知道自由度。我们说,只要一种可能的话,自由度是0,有两种可能,自由度是1。如果抛不是一个硬币,而是一颗台球,上面数字只有一种可能,此时自由度是0。一个药片,吃下去的有三种结果:病治愈,病恶化,病不变,如果吃下去只有治愈这个可能,自由度是0,如果有三种可能,自由度是2。对于本例的表格而言,行和列的自由度都有自己的自由度,分别是行数和列数减一。又考虑到行数和列数的乘积是表中数值的总数,因此全表对应的自由度是行和列自由度的乘积。本例的自由度由此计算出来是1。
df (degree of freedom) = (col - 1)(row - 1) = (2-1)(2-1) = 1
查询可得,95%概率认为吃炸鸡与肥胖不相关的chi-square 是3.84, 因为1.077<3.84, 我们接受原假设,结论:吃炸鸡与肥胖无关!
代码实现
import pandas as pd
import numpy as np
from scipy import statschi_squared_stat = ((observed-expected)**2/expected).sum()
print('chi_squared_stat')
print(chi_squared_stat)crit = stats.chi2.ppf(q=0.95,df=5) #95置信水平 df = 自由度
print(crit) #临界值,拒绝域的边界 当卡方值大于临界值,则原假设不成立,备择假设成立
P_value = 1-stats.chi2.cdf(x=chi_squared_stat,df=5)
print('P_value')
print(P_value)
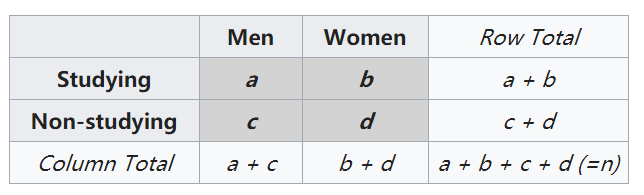
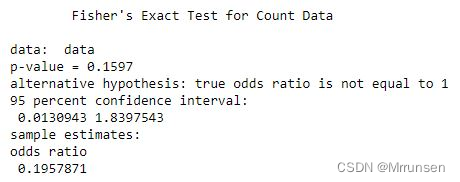
Fisher精确检验
Fisher精确检验可以用于检验任何RC数据之间的关系,但最常用于分析22数据,即两个二分类变量之间的相关性。与卡方检验只能拟合近似分布不同的是,Fisher精确检验可以分析数据的精确分布,更适用于小样本数据。但是该检验与卡方检验一样,只能分析相关的统计学意义,不能反映关联强度。
前提条件:
针对上述卡方检验的2联列表,当理论值<1 , 或者 n < 40, 或做卡方检验后所得的P值接近检验水准a 时,用Fisher exact test(fisher精确检验)。
换言之,fisher精确检验更适合小样本量(不满足大样本假设),适合有偏的分布形式,以及分类变量(尤其是二分类)。
计算思路
article - fisher exact test
fisher是替代卡方检验的一种基于超几何概率分布方法,
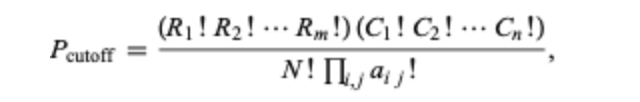
这里的 Ri! 是行总数的阶乘(5!=54321)。 Ci! 是各列总数的阶乘。 N! 是表格总数的阶乘,aij是各个单元值的阶乘。 Πij 是各个单元格值的乘积系数。 这样的公式甚至比卡方检验更需要计算,特别是对于有很多行和列的表格。
举例:

原假设为:性别与学习无关
备择假设为:性别与学习相关
p值越小,越能拒绝原假设,显著性也越高。我们可以这样理解,p值小说明出现了小概率事件,极端情况就是男人都不喜欢学习,女人都很爱学习。那么分子会非常小。
代码实现
"""
一般情况p值<0.05就可以拒绝原假设
"""
scipy.stats.fisher_exact([[a,b],[c,d]])
F检验(ANOVA, 方差齐性检验)
方差分析(ANOVA),又叫F检验,简单来说,就是求得F统计量(组间方差/组内方差),然后查F表,如果大于临界值(一般是0.05显著性水平下)则拒绝原假设,即组间具有显著性的差异。
F统计量 = 组间方差/组内方差
作用: 用来判断特征与label的相关性的,F 检验只能表示线性相关关系。
说白了,就是X的分布是否与Y的分布相似。
计算过程
X, Y为两组相互独立,服从正态分布的序列。
X与Y的期望计算分别为如下:
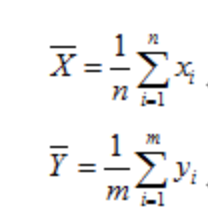
因此我们可以得到两组序列的方差分别为:
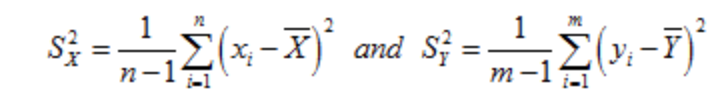
然后F(n-1,m-1)的分布为:
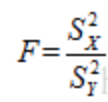
对照F分布表,查找P值。
代码实现:
from scipy.stats import ttest_rel, f
import numpy as np# 模型一10组实验结果
x = [......连续变量]
# 模型二10组实验结果
y = [.......连续变量]print('t检验结果:p值')
print(ttest_rel(x, y))# 计算组内样本方差
var1 = np.var(x, ddof=1)
var2 = np.var(y, ddof=1)
# 计算统计量F
F = var1 / var2
# 计算自由度
df1 = len(x) - 1
df2 = len(y) - 1
# 计算p值
p_value = 1 - 2 * abs(0.5 - f.cdf(F, df1, df2))
print('F检验结果:p值')
MIC-最大信息系数
MIC,即(Maximal Information Coefficient)最大信息系数,属于Maximal Information-based Nonparametric Exploration (MINE) 最大的基于信息的非参数性探索,用于衡量两个变量X和Y之间的关联程度,线性或非线性的强度,常用于机器学习的特征选择。
MIC相较于Mutual Information(MI)互信息而言有更高的准确度,是一种优秀的数据关联性的计算方式。
**互信息(Mutual Information)**是信息论里一种有用的信息度量,它可以看成是一个随机变量中包含的关于另一个随机变量的信息量,或者说是一个随机变量由于已知另一个随机变量而减少的不肯定性。
特点
- 需要很大的数据量,才会准确。
- 公平性:样本量足够大时能为不同类型单噪声程度相似的相关关系给出相近的系数。
- 普适性:不管是什么函数关系,都可以识别。线性和非线性函数关系,对这个系数而言是一样的。
计算方法
MIC基本原理会利用到互信息概念,互信息的概念使用以下方程来说明:
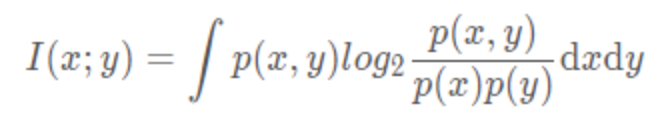
在机器学习中,想把互信息直接用于特征选择存在以下问题:
- 它不属于度量方式,也没有办法归一化,在不同数据及上的结果无法做比较。
- 对于连续变量的计算,通常变量需要先离散化,而互信息的结果对离散化的方式很敏感。
而最大信息系数 MIC 为了克服了这两个问题,它首先寻找一种最优的离散化方式,然后把互信息取值转换成一种度量方式,取值区间在[0,1]。
MIC的计算方式为:
- 给定 i、j,对XY构成的散点图进行 i 列 j 行网格化,并求出最大互信息值。
I(x;y) ≈ I[X;Y] - 对最大互信息值进行归一化。
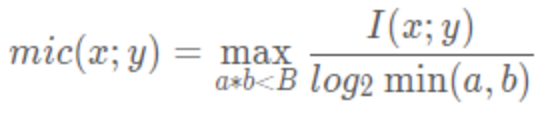
- 选择不同 i、j 尺度下互信息的最大值作为MIC值
用 a,b 表示在 x,y 方向上的划分格子的个数,设置a*b<B,其中 B 的大小为数据量的0.6次方左右,这是一个经验值。
计算步骤
(a). 给定i、j,对X、Y构成的散点图进行i列j行网格化,并求出最大的互信息值,如下图所示:

如上图例子,为假设i=2,j=2,则可能有以下橘色、绿色、蓝色三种网格化方案(其实更多,这里只是随便挑三种方案作说明),分别计算每个网格化方案对应的互信息值,找出使互信息值最大的网格化方案。
那么,给定了某个网格化方案后,计算其对应的互信息值。这里以上图中橘色的网格化方案为例进行说明。
红色网格化方案将所有数据点分为四个区域:左上,右上,左下,右下。每个区域对应的数据点数量为1,4,4,1。
将数据点数归一化得到四个区域的数据点频率,分别为0.1,0.4,0.4,0.1。也就是说,此时,X有两种取值:左和右,Y有两种取值:上和下。P(X=左,Y=上)=0.1,P(X=右,Y=上)=0.4,P(X=左,Y=下)=0.4,P(X=右,Y=下)=0.1。并且,P(X=左)=0.5,P(X=右)=0.5,P(Y=上)=0.5,P(Y=下)=0.5。根据互信息计算公式,得到X和Y在这种分区下的互信息为:

(b). 对最大的互信息值进行归一化
将得到的最大互信息除以log(min(X,Y)),即为归一化,这个与互信息原公式有关。
©. 选择不同尺度下互信息的最大值作为MIC值
上面是在给定i和j的情况下计算M(X,Y,D,i,j)。第三步就是给定很多(i,j)值,计算每一种情况下M(X,Y,D,i,j)的值,将所有M(X,Y,D,i,j)中的最大值作为MIC值。注意的是,这里的(i,j)是有条件的。当然,B(n)这个值可以自己定,这里是别人做实验认为效果最好的值 (B 的大小为数据量的0.6次方左右,这是一个经验值)。
代码实现
在Python中的minepy类库中实现了MIC算法,具体使用如下:
参数:
- alpha:float类型,取值范围为(0 ,1.0 ] 或 > =
4,如果alpha的取值范围在(0,1]之内,那么B的取值范围为(N^αlpha,4)其中n是样本的数目。如果alpha的取值范围是> =
4, alpha直接定义B参数。如果alpha高于样本数 n,则它将被限制为n,因此 B = min(alpha,n) - c:float类型,取值必须大于0,确定每个分区中的列数比列数多了多少。默认值为15,这意味着当尝试在x轴上绘制x网格线时,算法将以最多15x块开始。
- est:估算器,参数为“mic_approx”或者“mic_e”。使用est =”
mic_approx”,将计算原始MINE统计信息;使用est =” mic_e”,将计算等特征矩阵,并且 mic() 和 tic()
方法将分别返回 MIC_e 和 TIC_e 值。
方法:
- compute_score(x, y):计算(equi)特征矩阵(即最大标准化互信息得分)
- mic():返回最大的信息系数(MIC或MIC_e)
- mas():返回最大不对称分数(MAS)
- mev():返回最大边缘值(MEV)
- mcn(eps=0):返回eps> = 0的最小单元数(MCN)
- gmic(p=-1):返回广义最大信息系数(GMIC)
- tic(norm=false):返回总信息系数(TIC或TIC_e)。如果norm == True TIC将在[0,1]中标准化。
代码1:直接计算MIC
import numpy as np
from minepy import MINEx = np.linspace(0, 1, 1000)
y = np.sin(10 * np.pi * x) + x
mine = MINE(alpha=0.6, c=15)
mine.compute_score(x, y)print("Without noise:")
print("MIC", mine.mic())np.random.seed(0)
y += np.random.uniform(-1, 1, x.shape[0]) # add some noise
mine.compute_score(x, y)print("With noise:")
print("MIC", mine.mic())
结果为:
Without noise: MIC 1.0000000000000002
With noise: MIC 0.5057166934173714
代码2:
from __future__ import division
import numpy as np
import matplotlib.pyplot as plt
from minepy import MINE# np.around(a, decimals=0) 对输入数组 a 的元素返回四舍五入后的值
# decimals 保留小数点后 n 位。 默认值为0。
# np.corrcoef()返回皮尔逊相关系数
def mysubplot(x, y, numRows, numCols, plotNum,xlim=(-4, 4), ylim=(-4, 4)):r = np.around(np.corrcoef(x, y)[0, 1], 1)mine = MINE(alpha=0.6, c=15)mine.compute_score(x, y)mic = np.around(mine.mic(), 1)ax = plt.subplot(numRows, numCols, plotNum,xlim=xlim, ylim=ylim)ax.set_title('Pearson r=%.1f\nMIC=%.1f' % (r, mic), fontsize=7)ax.set_frame_on(False)ax.axes.get_xaxis().set_visible(False)ax.axes.get_yaxis().set_visible(False)ax.plot(x, y, ',')ax.set_xticks([])ax.set_yticks([])return ax# np.dot()处理一维数组则得到两数组的内积,处理矩阵则得到矩阵乘积
def rotation(xy, t):return np.dot(xy, [[np.cos(t), -np.sin(t)],[np.sin(t), np.cos(t)]])def mvnormal(n=1000):cors = [1.0, 0.8, 0.4, 0.0, -0.4, -0.8, -1.0]# enumerate()用于将一个可遍历的数据对象(如列表、字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在for 循环当中。for i, cor in enumerate(cors):cov = [[1, cor], [cor, 1]]xy = np.random.multivariate_normal([0, 0], cov, n)mysubplot(xy[:, 0], xy[:, 1], 3, 7, i + 1)def rotnormal(n=1000):ts = [0, np.pi / 12, np.pi / 6, np.pi / 4, np.pi / 2 - np.pi / 6,np.pi / 2 - np.pi / 12, np.pi / 2]cov = [[1, 1], [1, 1]]# np.random.multivariate_normal方法用于根据实际情况生成一个多元正态分布矩阵xy = np.random.multivariate_normal([0, 0], cov, n)for i, t in enumerate(ts):xy_r = rotation(xy, t)mysubplot(xy_r[:, 0], xy_r[:, 1], 3, 7, i + 8)def others(n=1000):x = np.random.uniform(-1, 1, n)y = 4 * (x ** 2 - 0.5) ** 2 + np.random.uniform(-1, 1, n) / 3mysubplot(x, y, 3, 7, 15, (-1, 1), (-1 / 3, 1 + 1 / 3))y = np.random.uniform(-1, 1, n)xy = np.concatenate((x.reshape(-1, 1), y.reshape(-1, 1)), axis=1)xy = rotation(xy, -np.pi / 8)lim = np.sqrt(2 + np.sqrt(2)) / np.sqrt(2)mysubplot(xy[:, 0], xy[:, 1], 3, 7, 16, (-lim, lim), (-lim, lim))xy = rotation(xy, -np.pi / 8)lim = np.sqrt(2)mysubplot(xy[:, 0], xy[:, 1], 3, 7, 17, (-lim, lim), (-lim, lim))y = 2 * x ** 2 + np.random.uniform(-1, 1, n)mysubplot(x, y, 3, 7, 18, (-1, 1), (-1, 3))y = (x ** 2 + np.random.uniform(0, 0.5, n)) * \np.array([-1, 1])[np.random.random_integers(0, 1, size=n)]mysubplot(x, y, 3, 7, 19, (-1.5, 1.5), (-1.5, 1.5))y = np.cos(x * np.pi) + np.random.uniform(0, 1 / 8, n)x = np.sin(x * np.pi) + np.random.uniform(0, 1 / 8, n)mysubplot(x, y, 3, 7, 20, (-1.5, 1.5), (-1.5, 1.5))xy1 = np.random.multivariate_normal([3, 3], [[1, 0], [0, 1]], int(n / 4))xy2 = np.random.multivariate_normal([-3, 3], [[1, 0], [0, 1]], int(n / 4))xy3 = np.random.multivariate_normal([-3, -3], [[1, 0], [0, 1]], int(n / 4))xy4 = np.random.multivariate_normal([3, -3], [[1, 0], [0, 1]], int(n / 4))# np.concatenate((a1, a2, ...), axis=0)函数。能够一次完成多个数组的拼接xy = np.concatenate((xy1, xy2, xy3, xy4), axis=0)mysubplot(xy[:, 0], xy[:, 1], 3, 7, 21, (-7, 7), (-7, 7))plt.figure(facecolor='white')
mvnormal(n=800)
rotnormal(n=200)
others(n=800)
plt.tight_layout()
# plt.savefig('MIC.png')
plt.show()

从图中我们可以看出
- 在数据线性相关时,皮尔逊系数和 MIC 都有较好的表现。
- 在数据非线性相关时,MIC 表现仍然出色!
Relief 特征选择算法与Relief-F
Relief算法最早由Kira提出,最初局限于两类数据的分类问题。Relief算法是一种特征权重算法(Feature weighting algorithms),根据各个特征和类别的相关性赋予特征不同的权重,权重小于某个阈值的特征将被移除。Relief算法中特征和类别的相关性是基于特征对近距离样本的区分能力。算法从训练集D中随机选择一个样本R,然后从和R同类的样本中寻找最近邻样本H,称为Near Hit,从和R不同类的样本中寻找最近邻样本M,称为NearMiss,然后根据以下规则更新每个特征的权重:如果R和Near Hit在某个特征上的距离小于R和Near Miss上的距离,则说明该特征对区分同类和不同类的最近邻是有益的,则增加该特征的权重;反之,如果R和Near Hit在某个特征的距离大于R和Near Miss上的距离,说明该特征对区分同类和不同类的最近邻起负面作用,则降低该特征的权重。以上过程重复m次,最后得到各特征的平均权重。特征的权重越大,表示该特征的分类能力越强,反之,表示该特征分类能力越弱。Relief算法的运行时间随着样本的抽样次数m和原始特征个数N的增加线性增加,因而运行效率非常高。
Relief 借用了 “假设间隔”(hypothesis margin) 的思想,我们知道在分类问题中,常常会采用决策面的思想来进行分类,“假设间隔”就是指在保持样本分类不变的情况下,决策面能够移动的最大距离,可以表示为:
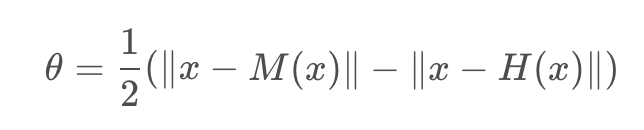
关于relief与relief-F特征选择算法,可以参考:
https://blog.csdn.net/coffee_cream/article/details/61420732
总的来说,就是鉴别最佳分类效果来看相关性的方法。说到这个,我更”欣赏“下述方法(主要是野鸡太菜555555)。
分层聚合统计与数据可视化(简单暴力)
上面说了很多“花里胡哨"的相关性计算方法,下面介绍的是一个非常简单,非常实际,非常立竿见影的方法。
这也是我工作中被上的一课吧。
我试图用各种相关性检验方法去验证业务中某两组或多组变量的相关性,但是leader对我说了一句话:”有些数据,你简单的摆在眼前,一眼就能看出是相关的,何必再多此一举去验证呢?“
基于这个思路,其实要做的,就是分层聚合你所有的特征,并给出明显的收益效果。
举个例子:

我们想证明,用户的哪些特征与转化具有相关性。
的确我们可以选择跑上述所有提到的相关性计算方式。但是还有一种更直接简单的方法,就是分层聚合。
比如,我们就想看「累计访问天数,转化」的相关性。
我们先得到大盘转化率9.88%
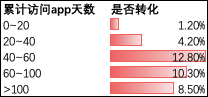
转化率 = 去重转化用户数/去重存量活跃用户数
我们做简单的case when分层,不难看出,40~60天的转化率最高。
那么是不是证明,累计访问app天数与转化率存在某种程度的关联,这种关联也可以被刻画成40~60天最高?
(注意数据量一定要足够大,否则小样本需要做假设检验的)

性别也与转化率有一定关系,女性更高。高于平均水平。那么我们app的转化有很多是女性贡献的!
当然这里也可以用我们上述提到的卡方检验去做相关性分析,没有问题。但是,何必呢…
最后,我们先得到提升转化的所有特征的策略变更or筛选方式,
那么我们可以直接把那些导致转化高于平均水平的特征分层列出即可,甚至可以分成A/B/C类用户划分。