环境
python:3+
ffmpeg:用于处理视频和语音
gradio:UI界面和读取语音
概述
我们的目的是做一个语音智能助手

下面我们开始
准备工作
下载Visual Studio Code
Visual Studio Code
因为需要写python代码,用Visual Studio Code比较方便。
安装python
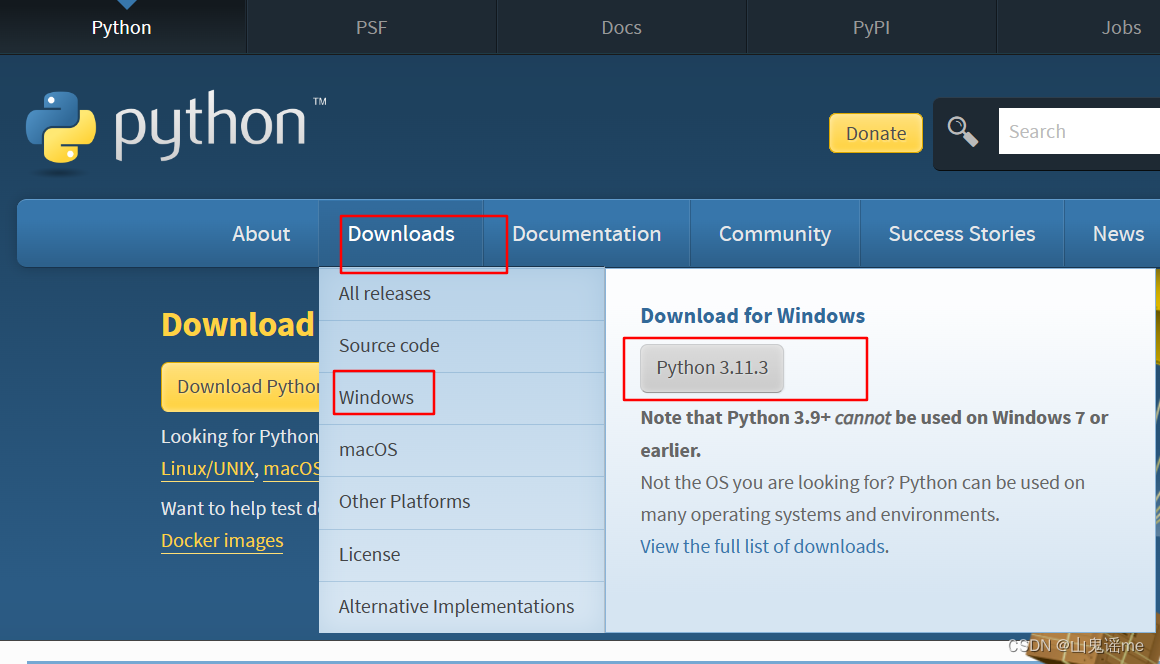
python官网
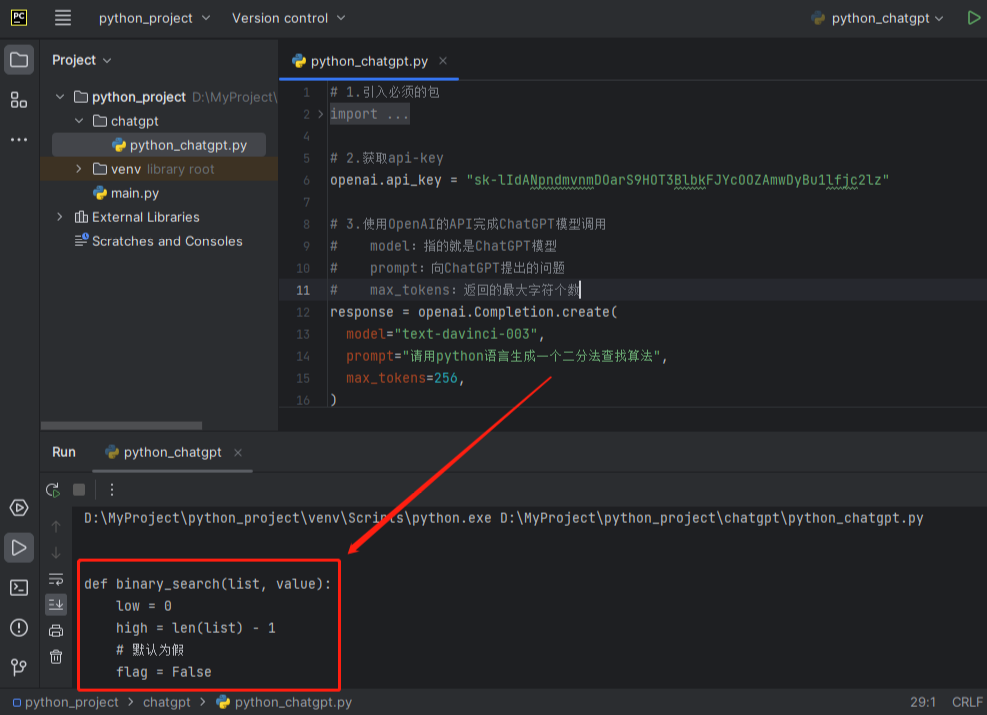
执行下载好的exe文件,可以建议选择自定义安装,这样可以修改安装路径,只要别安装到C盘就行。
记得勾选添加到环境变量
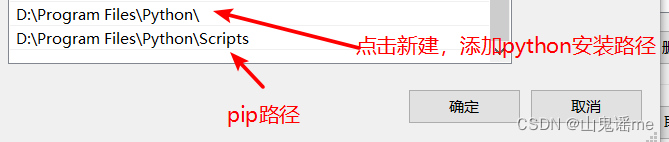
添加环境变量
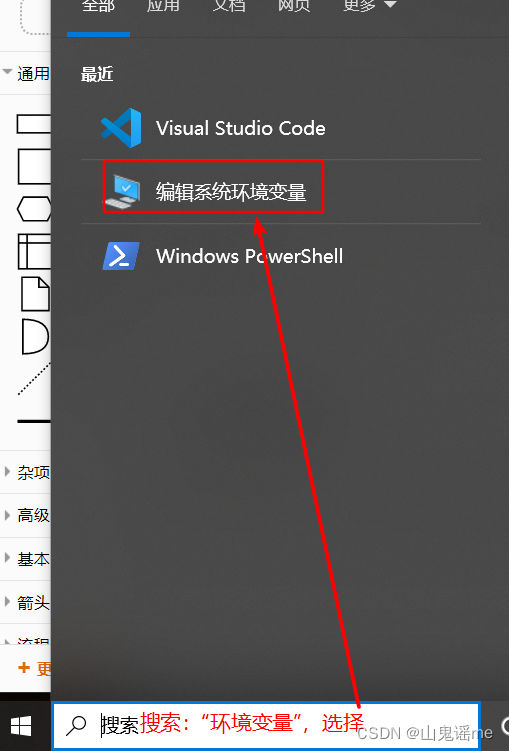
假设在安装时候,忘记了勾选添加到环境变量,那么我们可以自己配置
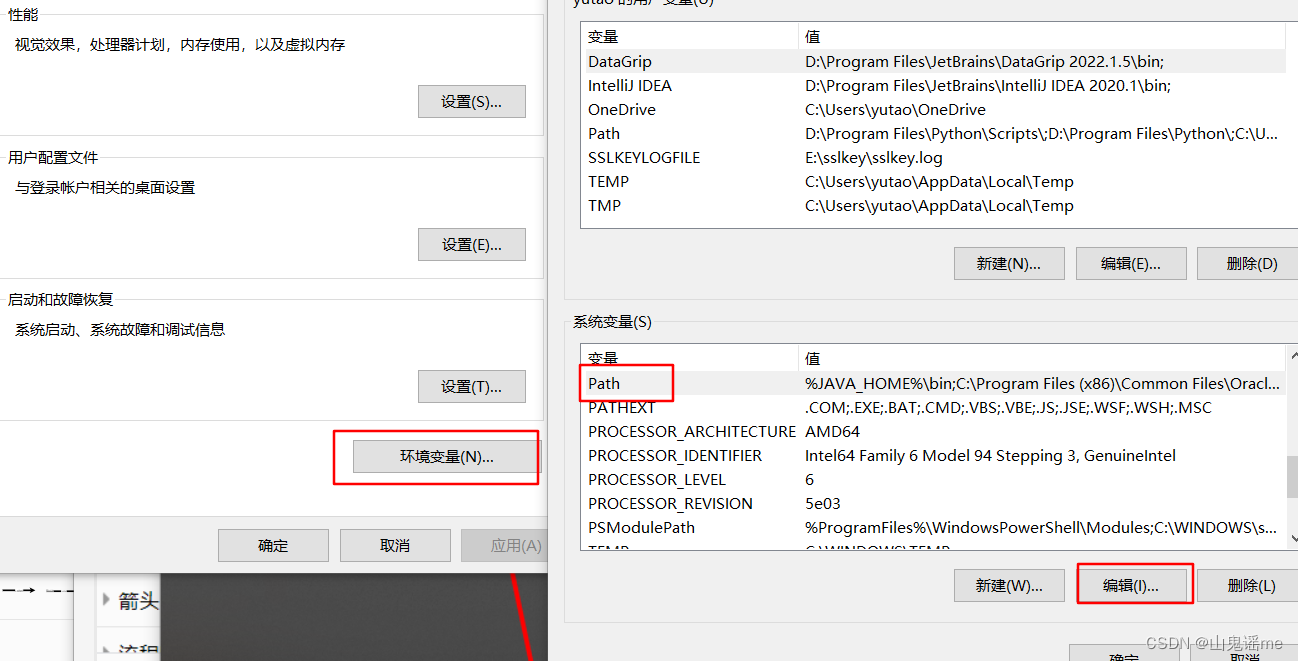
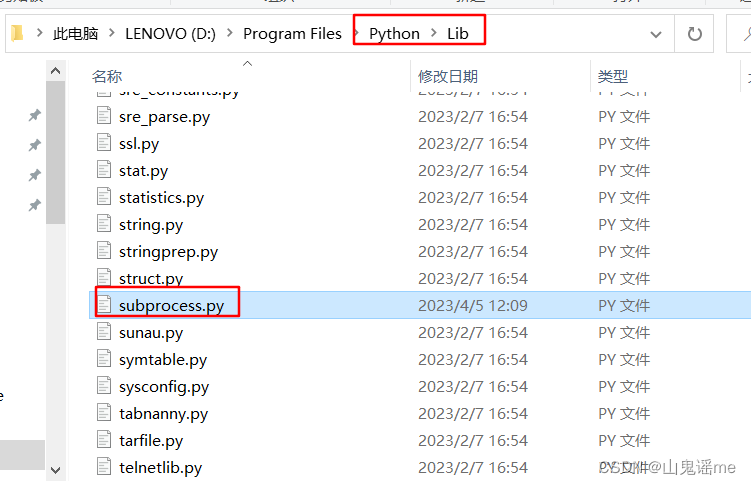
修改subprocess.py文件
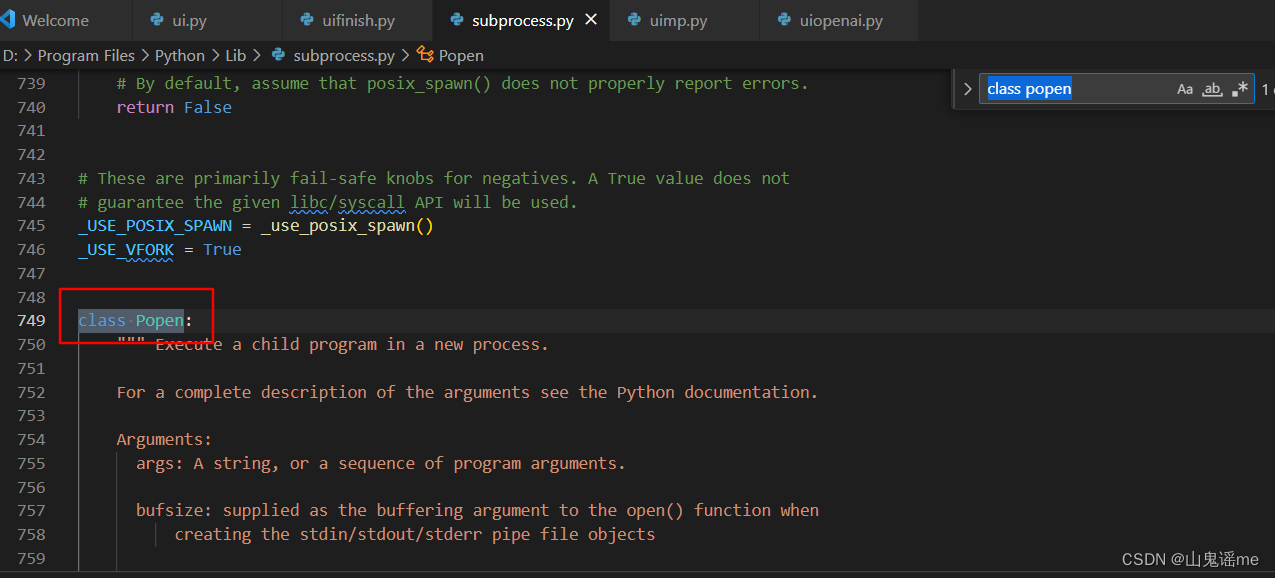
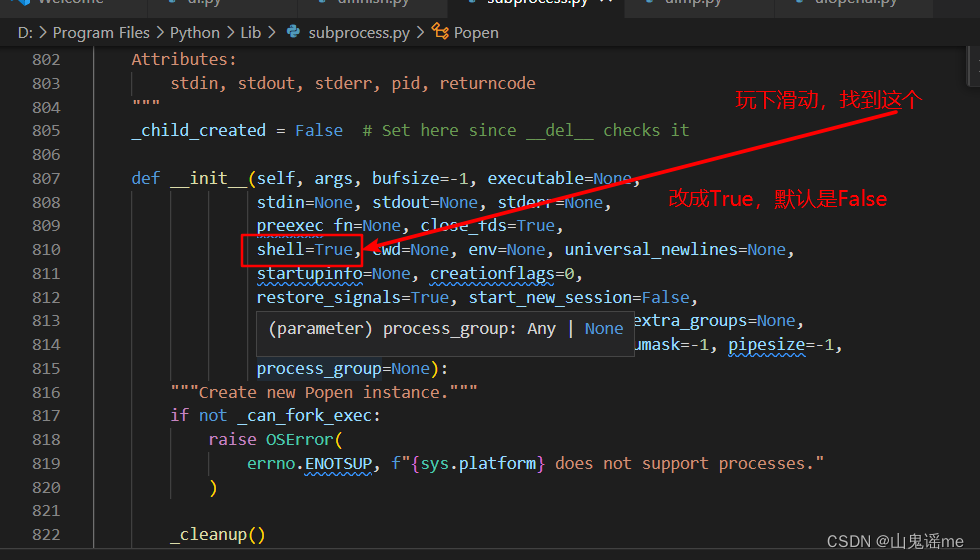
安装ffmpeg
https://ffmpeg.org/
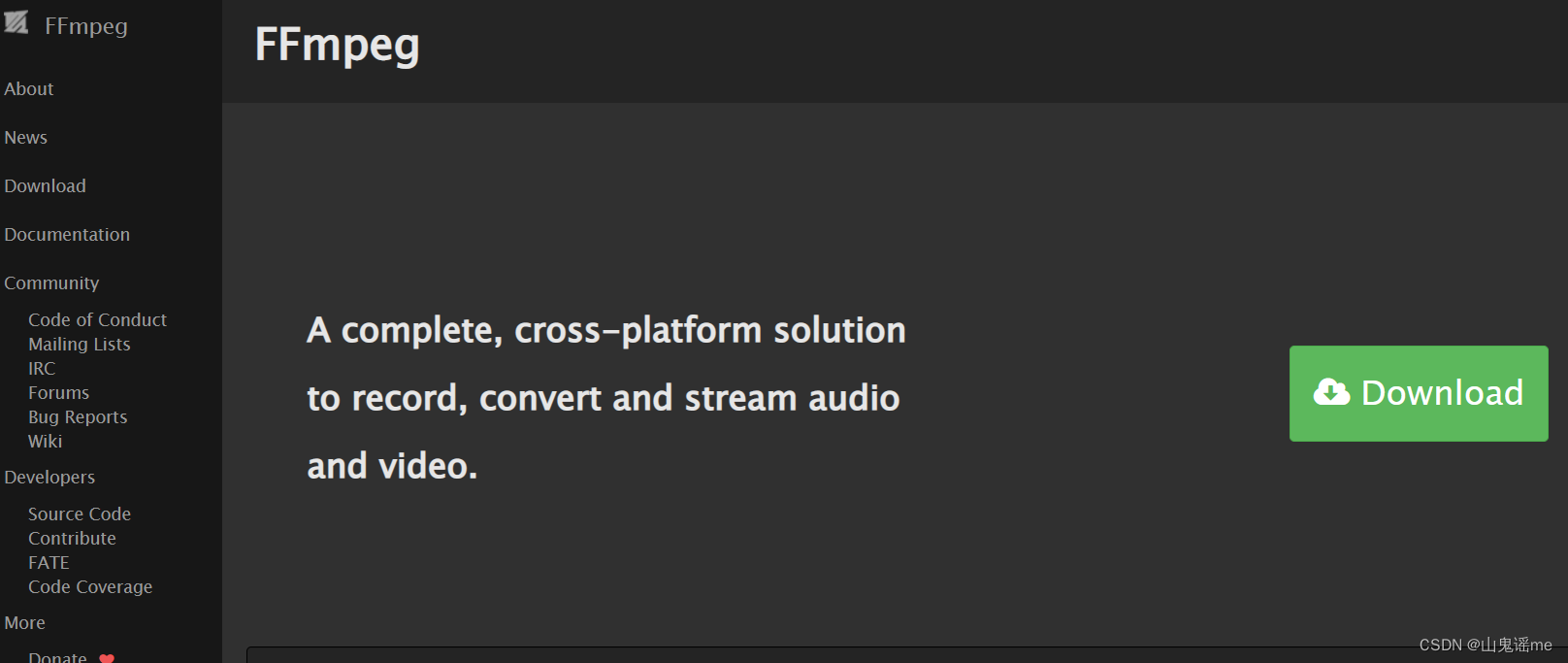
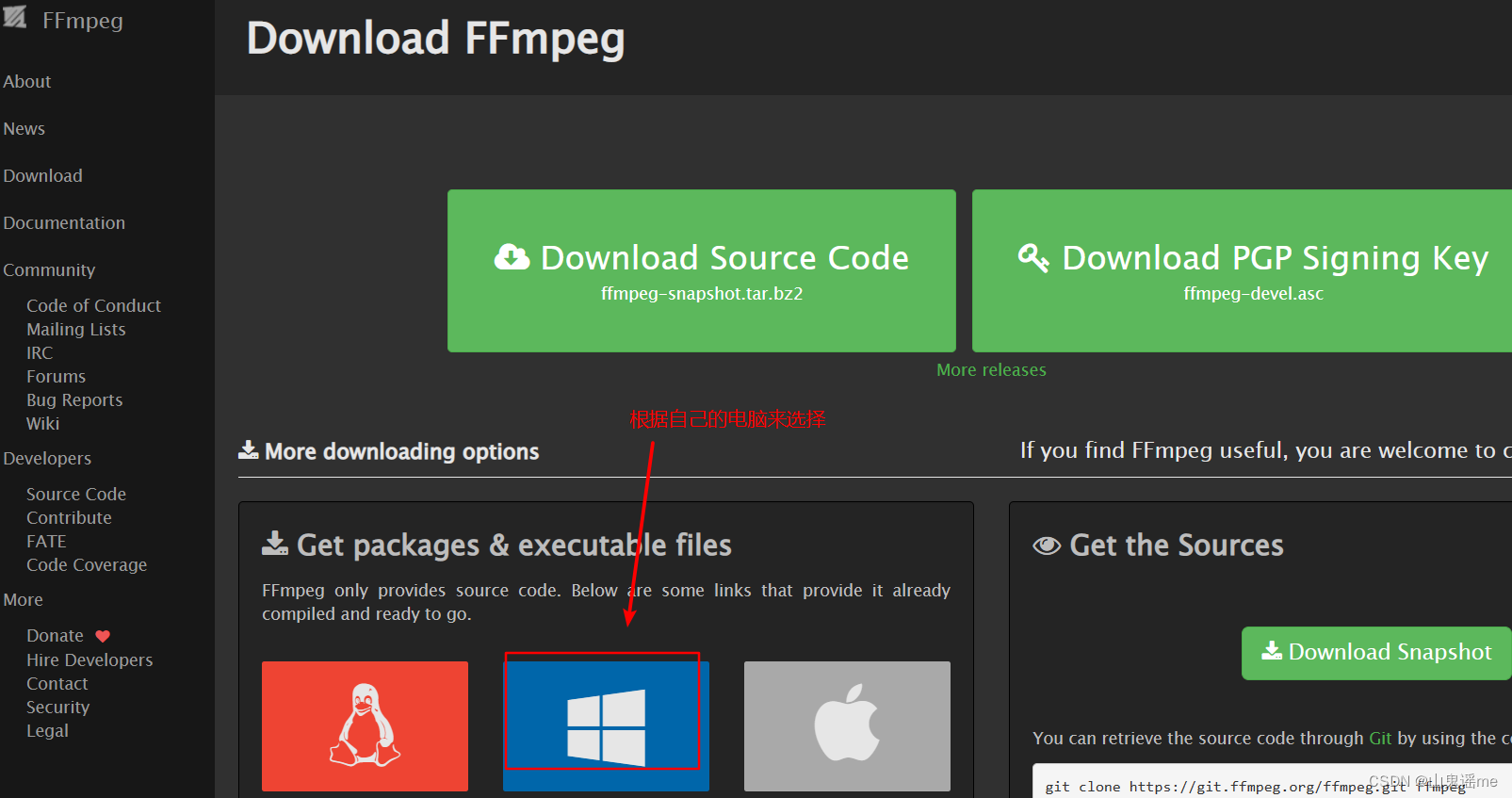
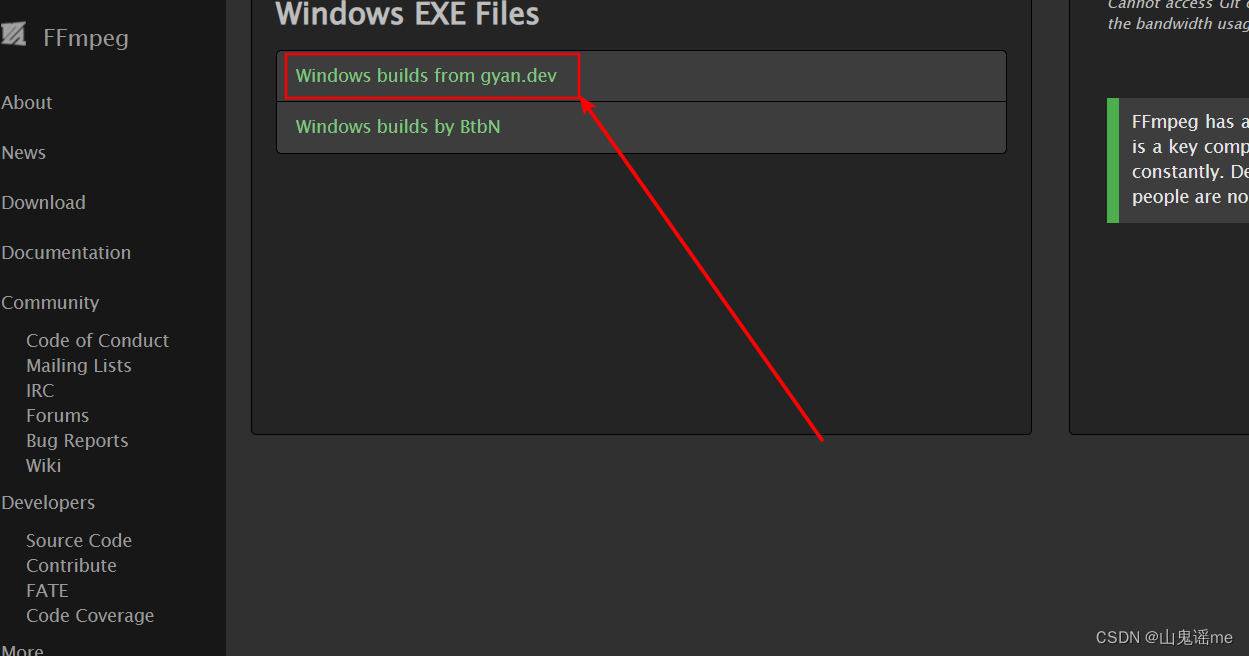
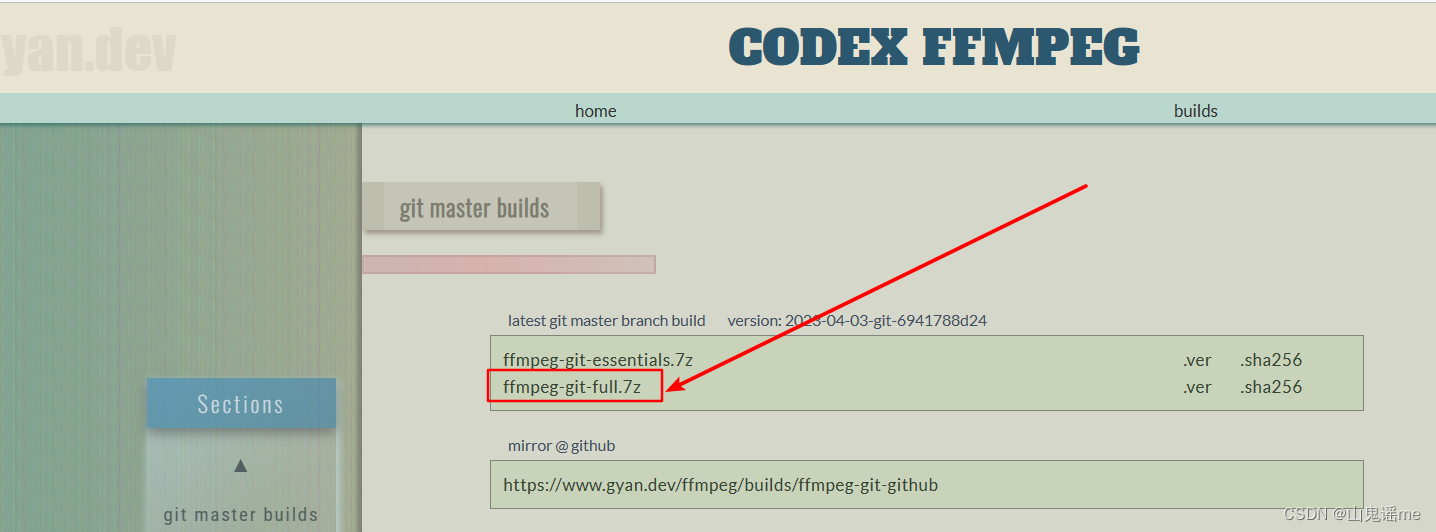
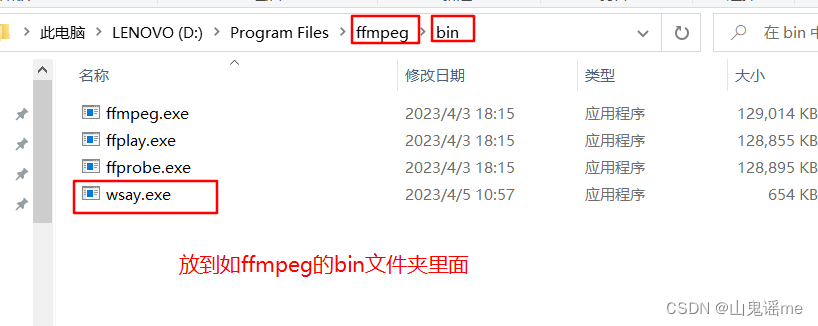
将下载好的安装包,进行解压,然后将解压后的文件夹放到平时自己喜欢的安装目录里。
比如:我的是D盘:D:\Program Files\ffmpeg。
WINDOWS系统文字转语音WSAY
https://github.com/p-groarke/wsay/releases/tag/v1.5.0
点击下图进行下载:
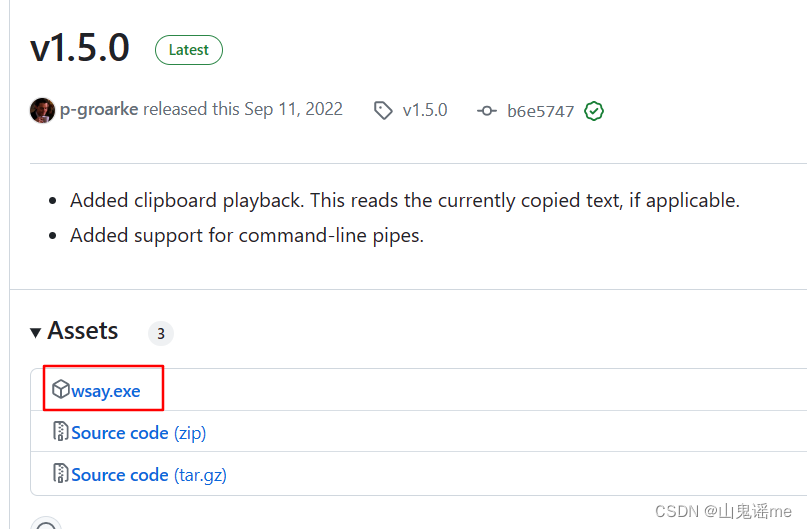
使用GRADIO建立用户界面
先创建一个项目文件夹,比如我的:E:\openai\project\Chatbot

然后打开我们之前下载好的vsCode,并打开相关目录。
参照gradio官网写测试代码
https://gradio.app/quickstart/
测试代码1:页面
import gradio as grdef greet(name):return "Hello " + name + "!"demo = gr.Interface(fn=greet, inputs="text", outputs="text")demo.launch()
执行代码:
PS E:\openai\project\Chatbot> python ui.py
可以看到控制台会打印如下信息:
Running on local URL: http://127.0.0.1:7860
然后浏览器打开网址http://127.0.0.1:7860:

但是我们是需要做成语音的,所以我们需要调整下;
在官网找到:
https://gradio.app/docs/#audio
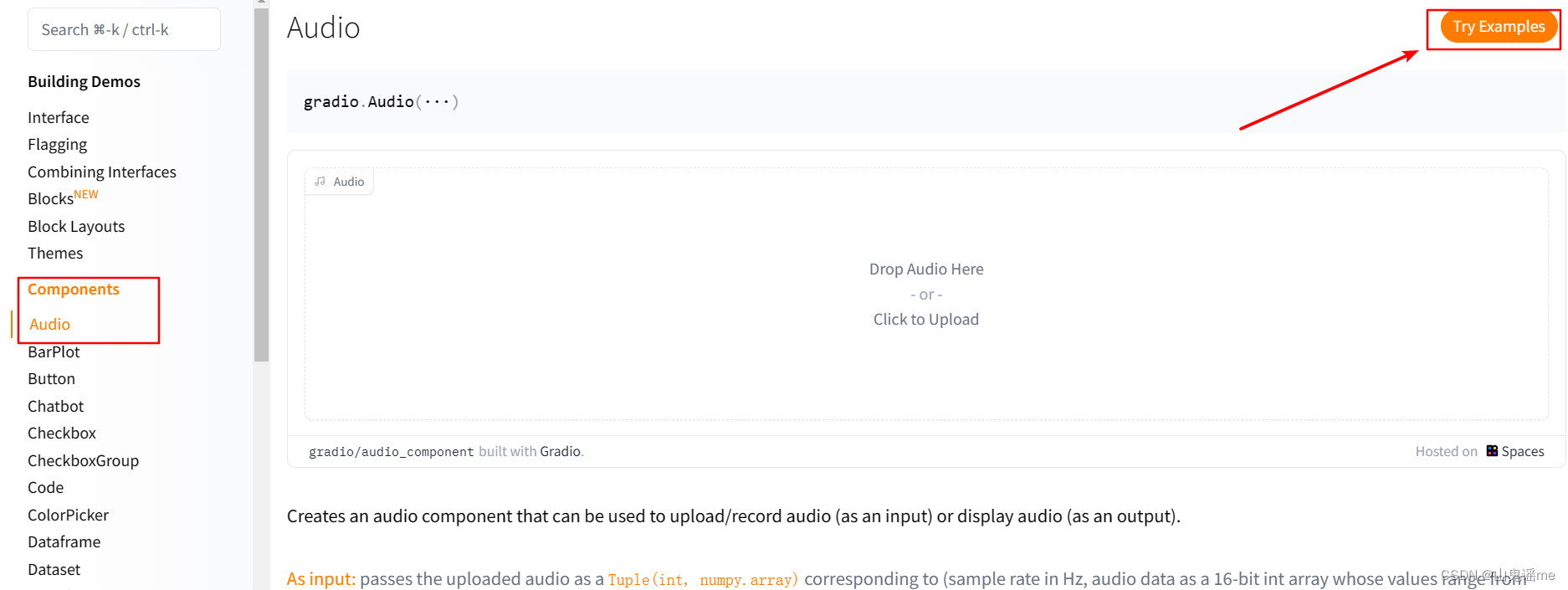
测试代码2:
import gradio as grdef transcribe(audio):print(audio)return "这里显示音频"demo = gr.Interface(fn=transcribe, inputs=gr.Audio(source="microphone"), outputs="text")demo.launch()
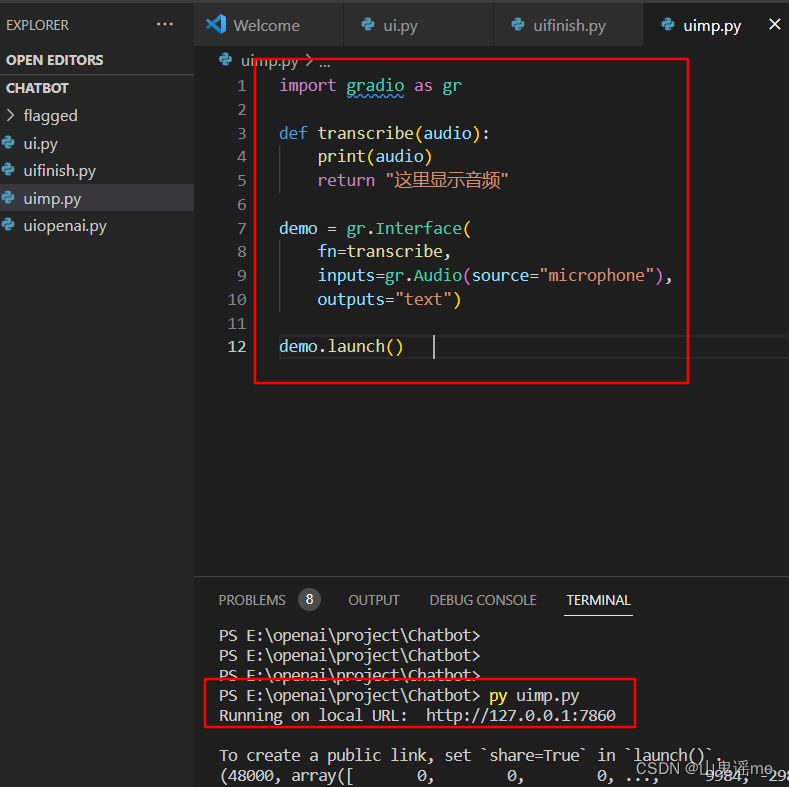
执行命令:py uimp.py
浏览器刷新地址如下页面:

接入openAI:
测试代码3:
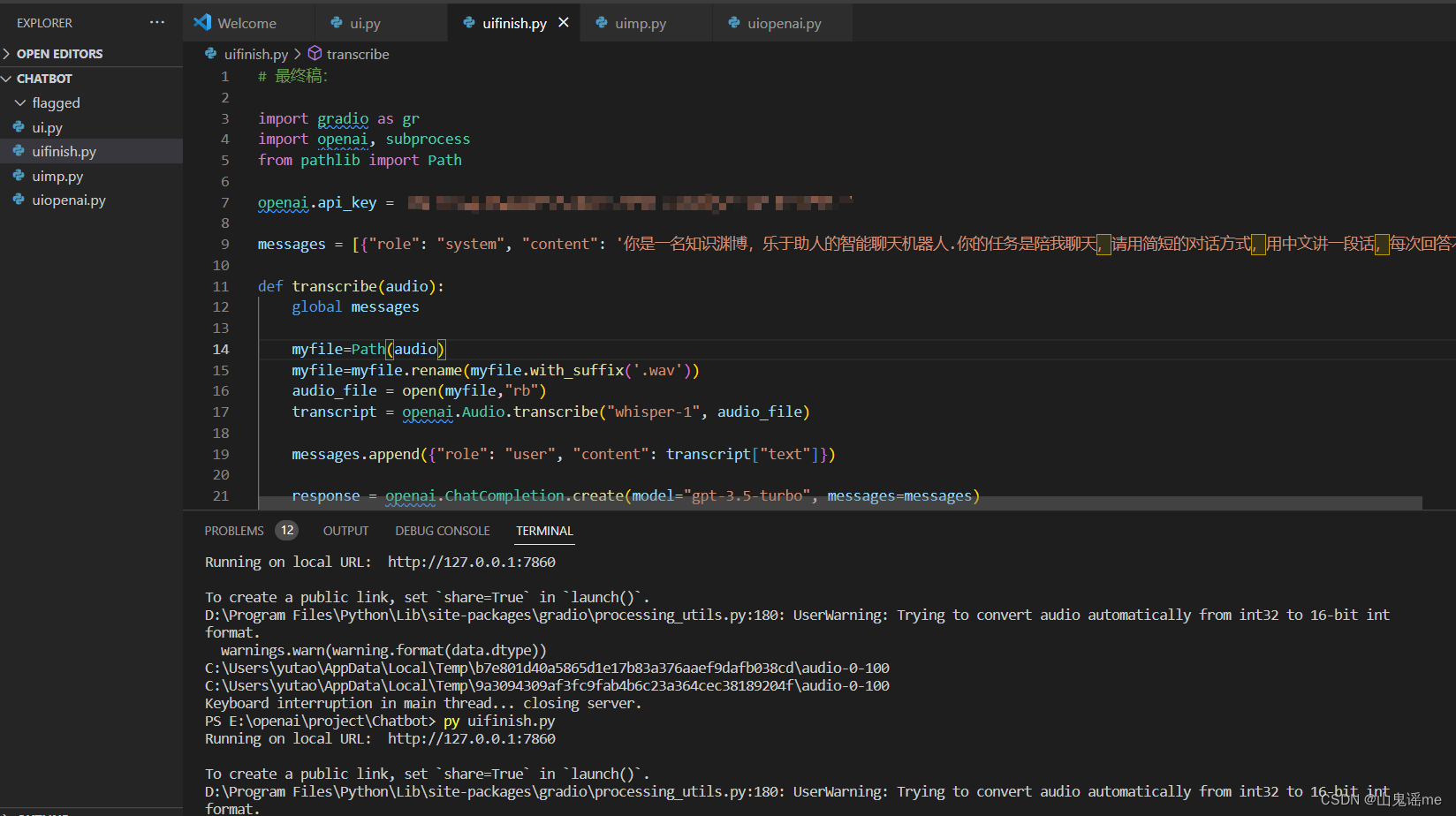
执行命令:py uifinish.py
# 最终稿:import gradio as gr
import openai, subprocess
from pathlib import Path# 换成你自己的api_key
openai.api_key = "XXXXXXXXXXXXXXXXXXXXXX"messages = [{"role": "system", "content": '你是一名知识渊博,乐于助人的智能聊天机器人.你的任务是陪我聊天,请用简短的对话方式,用中文讲一段话,每次回答不超过50个字!'}]def transcribe(audio):global messagesmyfile=Path(audio)myfile=myfile.rename(myfile.with_suffix('.wav'))audio_file = open(myfile,"rb")transcript = openai.Audio.transcribe("whisper-1", audio_file)messages.append({"role": "user", "content": transcript["text"]})response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages)system_message = response["choices"][0]["message"]# print(response)messages.append(system_message)subprocess.call(["wsay", system_message['content']])chat_transcript = ""for message in messages:if message['role'] != 'system':chat_transcript += message['role'] + ": " + message['content'] + "\n\n"return chat_transcriptui = gr.Interface(fn=transcribe, inputs=gr.Audio(source="microphone", type="filepath"), outputs="text")
ui.launch()
效果如下:
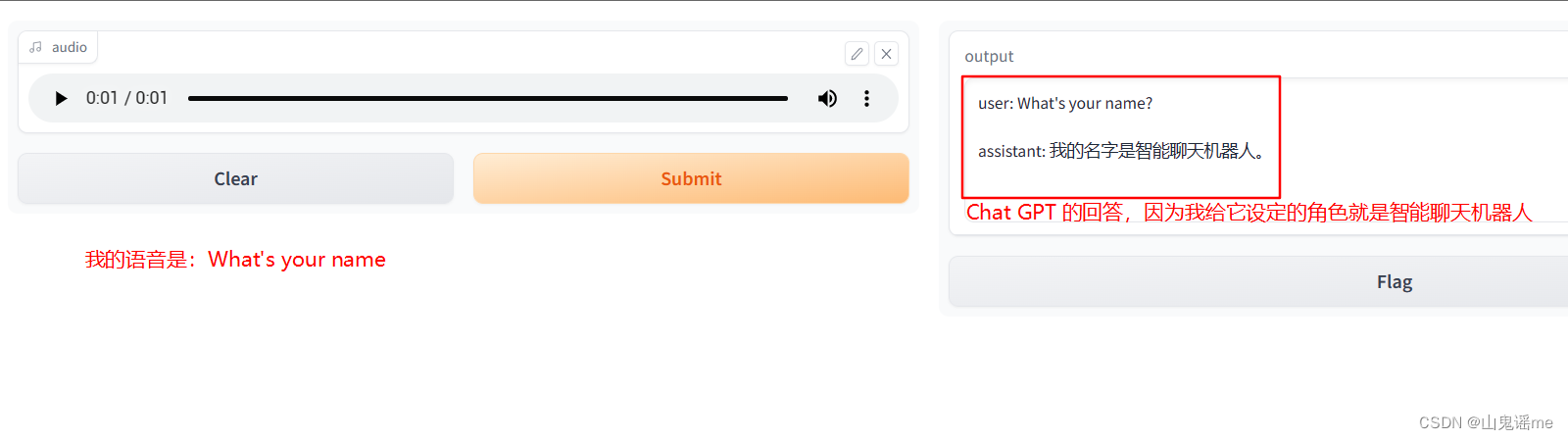
总结
- ffmpeg 来处理语音
- 利用WSAY,将文字转成语音
- 利用gradio,来生成UI页面,并提供语音输入
参考地址:
https://updayday.notion.site/Chat-GPT-WHISPER-API-GPT-3-5-TURBO-2af2630c857a4f0da92abcc763b4fd48
Whisper API cannot read files correctly
Renaming file extension using pathlib (python 3)
Path not found in Python