复杂网络建模的反问题是网络重构,获得节点之间的关系对于分析网络特性有着至关重要的作用。常用的网络重构方法有:1 相关性分析,2 压缩感知,3 动力学方程,4 因果分析,5 深度学习,6 概率图模型,7 微分方程。本文主要分析因果关系,格兰杰因果(granger casuality)是因果分析的常用方法。具体定义为:对于两个时间序列(一般为向量自回归时间序列(VAR))X,Y如果加入Y能够使得预测X的误差减小,则说明Y对X有因果关系:GCy-x。具体定义如下:


实际操作简单来说就是,如果我想检测X是不是Y的格兰杰因果,首先确定时滞P,因为时是VAR模型,下一时刻Xt由前面Xt-1......Xt-p 影响(也可以理解为用过于的P阶滞后去预测(回归))下一时刻的值,P确定好后,首先让X和Y的P阶延迟都参与预测Xt,接着再把Y的P阶延迟拿掉再进行预测,如果前者预测的误差比后者预测的少,则说明Y有助于X的预测,即Y是X的因。
实战:数学模型(或者叫N个时间序列之间的关系):
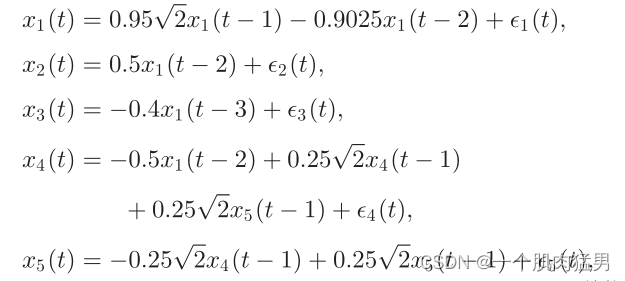
本身的因果关系:
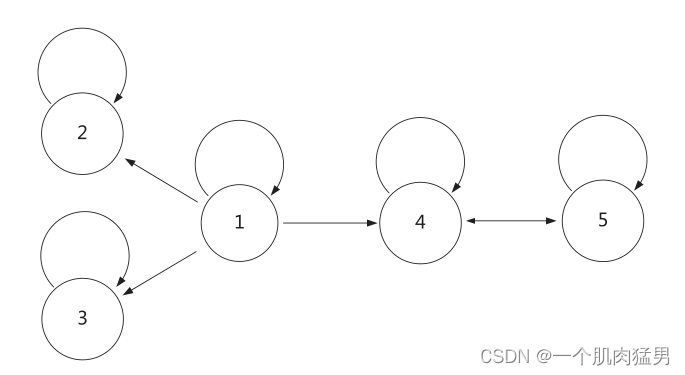
用格兰杰因果矩阵表示即:
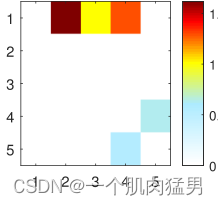
根据上面的模型,我们生成了大小为4096*5的时间序列数据,5条时间序列,每个时间序列包含4096个点的数值,我们需要用自己的方法将这些数据里的因果关系还原出来。
本文提出了基于循环神经网络,更具体的,是LSTM,LSTM是RNN的变种,有着比RNN好很多的记忆能力,十分适合用来做预测问题(回归),对于大小为4096*5的数据集,我们首先要进行预处理,得到想要的inputs和targets。P我取的是10,即用过去10个数据去预测第11个数据,所以我们要用一个10*5的窗口去遍历数据集,得到inputs:

那么显然标签集是啥呢?第11个数据第12个数据对吧:

这样遍历完整个4096*5的数据集后我们得到了想要的inputs(shape:4085*10*5) ,targets(shape:4085*1*5)
程序如下:
def load_sequence_data():simulation_name = 'realization_' + 'linear' + '_' + '4096' + '.mat'simulation_dir = 'simulation_difflen'simulation_name = os.path.join(simulation_dir, simulation_name)simulation_data = sio.loadmat(simulation_name)#5,4096simulation_data = np.array(simulation_data["data"]).transpose()#4096,5num_channel = simulation_data.shape[1]#5scaler = preprocessing.StandardScaler().fit(simulation_data)simulation_data = scaler.transform(simulation_data)min_max_scaler = preprocessing.MinMaxScaler()# scale data to [0. 1]data = min_max_scaler.fit_transform(simulation_data)#data.shape(4096,5)x, y = batch_sequence(data, num_shift=1,sequence_length=20)return x, y
def batch_sequence(x, sequence_length=20, num_shift=1):#x.shape(4096,5)num_points = x.shape[0]#4096inputs = []targets = []# for p in np.arange(0, num_points, max(num_shift, sequence_length // 5)):for p in np.arange(0, num_points, num_shift):# prepare inputs (we're sweeping from left to right in steps sequence_length long)if p + sequence_length + num_shift >= num_points:breakinputs.append(x[p: p + sequence_length, :])targets.append(x[p + sequence_length, :])inputs = np.array(inputs)targets = np.array(targets)idx = np.random.permutation(np.arange(inputs.shape[0]))#4085inputs = inputs[idx]#4085,10,5targets = targets[idx]#4085,5
x,y=load_sequence_data()这样返回的X和Y就是数据集和标签集啦
下面需要将数据集和标签集喂入神经网络进行训练,由于我们使用的是LSTM进行预测,而LSTM的输出是根据你输入的隐藏层的units决定的,因此需要在LSTM层后再加一层Dense(1),才能和Y的shape对上。损失函数由于是预测问题,其实也就是回归问题,因此选择了常用的均方误差(MSE),优化器选择的是RMSprop,也可以选择SGD或者adam,adagrad这类的。具体以tensorflow框架为基础的代码如下:
from __future__ import print_function, divisionimport numpy as npfrom keras.models import Sequential
from tensorflow.keras.optimizers import Adagrad
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.optimizers import RMSprop
from keras.layers import Dense, Dropout, Activation, Embedding
from keras.layers import LSTM, SimpleRNN, GRU
from keras.regularizers import l1, l2
from keras.callbacks import EarlyStopping
class CustomLSTM(object):def __init__(self, num_hidden=10, num_channel=5, weight_decay=0.0):if num_hidden is None:num_hidden = num_channelself.model = Sequential()self.model.add(LSTM(units=num_hidden, input_dim=num_channel, kernel_regularizer=l1(weight_decay),recurrent_regularizer=l1(weight_decay)))#units=30,input_dim=5self.model.add(Dense(1))self.model.summary()rms_prop = RMSprop(lr=0.001, rho=0.9, epsilon=1e-6)# adam = Adam(lr=0.01, beta_1=0.9, beta_2=0.999, epsilon=1e-8)# adagrad = Adagrad(lr=0.1, epsilon=1e-5)self.model.compile(loss='mean_squared_error', optimizer=rms_prop)def fit(self, x, y, batch_size=10, epochs=100):#x:4085*10*1 y:4085*1early_stopping = EarlyStopping(monitor='val_loss', patience=5)hist = self.model.fit(x, y,batch_size=batch_size,epochs=epochs,verbose=2,validation_split=0.2,callbacks=[early_stopping])return histdef predict(self, x):return self.model.predict(x)训练完后需要检测其因果关系了,如若检测时间序列0和1有没有因果关系,则首先将5条时间序列全部放进去进行预测:
var_denominator[0][k] = np.var(lstm.predict(x1[:, :, input_set]) - tmp_y, axis=0)接着,再将0拿掉,用剩下的4条时间序列放入LSTM.predict()进行预测:
tmp_x = x1[:, :, input_set]
channel_del_idx = input_set.index(j)
tmp_x[:, :, channel_del_idx] = 0
granger_matrix[j][k] = np.var(lstm.predict(tmp_x) - tmp_y, axis=0)以此类推,得到整个格兰杰因果矩阵。
代码如下:
import numpy as np
def GC():all_candidate = [[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4],[0,1,2,3,4]]granger_matrix = np.zeros([5, 5])#5*5var_denominator = np.zeros([1, 5])#1*5for k in range(5):tmp_y = np.reshape(y1[:, k], [y1.shape[0], 1]) input_set=all_candidate[k]hist_result = []lstm = CustomLSTM(num_hidden=30, num_channel=len(input_set))hist_res = lstm.fit(x1[:, :, input_set], tmp_y, batch_size=64, epochs=100)hist_result.append(hist_res)var_denominator[0][k] = np.var(lstm.predict(x1[:, :, input_set]) - tmp_y, axis=0)for j in range(5):if j not in input_set:granger_matrix[j][k] = var_denominator[0][k]elif len(input_set) == 1:tmp_x = x1[:, :, k]tmp_x = tmp_x[:, :, np.newaxis]granger_matrix[j][k] = np.var(lstm.predict(tmp_x) - tmp_y, axis=0)else:tmp_x = x1[:, :, input_set]channel_del_idx = input_set.index(j)tmp_x[:, :, channel_del_idx] = 0granger_matrix[j][k] = np.var(lstm.predict(tmp_x) - tmp_y, axis=0)granger_matrix = granger_matrix / var_denominatorfor i in range(5):granger_matrix[i][i] = 1granger_matrix[granger_matrix < 1] = 1granger_matrix = np.log(granger_matrix)return granger_matrixgranger_matrix=np.zeros((5,5))
for i in range(10):granger_matrix +=GC()
granger_matrix=granger_matrix/10
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
ax.matshow(granger_matrix)最后得到的格兰杰因果矩阵如下:
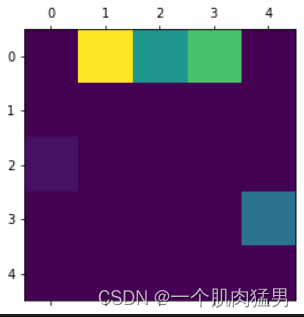
可以看到,绝大部分连边已经重构完成,多次实验即可获得最优值。