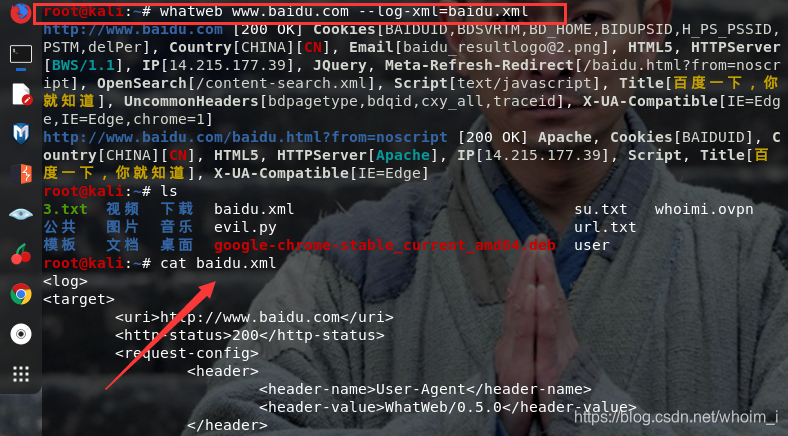
效果展示

项目目录:

引言
不知是否有小伙伴在学习Web安全相关的知识,如果有的话,那应该对XSS,SQL注入,文件上传,一句话脚本等等基本功应该是再熟悉不过了。最初学习的时候是它,实战最先测试的也是它,就跟饭前先洗手一样,成了固定习惯。
但是呢,这些基本功的使用是需要环境的,人家的网站不会“明目张胆”的把一个漏洞挂在首页上,并在旁边打上标注“这系个漏洞,一个你没油见过的船新漏洞,漏洞不用冲,金币全靠打,只需三翻钟,你奏会拥有介个网站的管理权限,快来锌动吧!”
为什么漏洞需要去“挖”呢?为什么安全从业者的工作叫“渗透”呢?就是因为没人知到漏洞在哪里,需要根据自己以往的经验以及平常的练习,猜测网站的设计在哪里可能存在疏忽,然后再去验证。用“大胆假设,谨慎验证”来描述其过程再合适不过了。
我们知道啊,如果想使用XSS,SQL注入之类的技巧,需要找到一个网站与用户进行数据交互的功能点,比如搜索框,评论区,文件上传功能点等等。在这些地方,服务器需要接受用户的输入数据进行一些处理,如果没有全面的过滤用户输入,就可能留下隐患。这些地方就大概率可以使用到我们平常练习的小技巧。
上面也说到了,没人会傻到让主页存在漏洞,或者说即使有漏洞,也早被人发现并修复了。这种现实情况会“劝退”一部分像我一样的“新手玩家”,找了个网站,主页看了半天,除了熟悉网站小字的内容外,好像和其他用户没什么区别,果断放弃此网站,下一个。然,下一个是同样的情况,果断放弃安全,说再见。
理想很丰满哈,现实比理想还丰满,一屁股坐下去能把理想坐出“奥利给”来。对于有经验的Web安全人员来说,他们在简单的分析了网站的whois域名、管理者信息,网站的基本设计情况后,就会开始寻找适合用“武力”的地方,比如,后台管理系统的登录入口界面:

(这是我从搜索引擎里随便找的,别去测试人家,你是需要负责的哦~)
我们可以看到,这种网页最适合我们使用技巧了,什么XSS,SQL啊都给它试一遍。(成功的概率会很低,因为随着大家安全意识的提高,以及各种CMS的出现,这种简单的漏洞越来越少,如今更多的隐患是网站设计时的逻辑疏忽。)
现在开发网站的框架越来越多,如果管理者很懒,很可能随便找了一个开始“填空”。这些框架,大部分都会提供后台管理功能,以方便管理者管理网站,但是为了避免随便什么人都能进入,就会提供上面的登录验证功能。
现在我们来看,上面功能点的目录:

asp…,呵,获得一个信息点(再说一遍,别去测试人家~)。
综上,在对一个Web站点进行安全测试的前期,会需要寻找网站的一些“易碎”网页,比如上面的登录点。那怎么知道网站的一些隐藏功能点的网址目录呢?就是这篇文章说的——对网站进行目录扫描。
简介
对网站目录进行扫描,原理很简单,事先准备子目录字典,如:

(这种资源很多,可以去github上找找哦)
然后将其逐个拼接到网站主目录后,形成新的网址,并对其发送HTTP请求,如果返回成功,则判断该页面存在。
其实跟端口扫描如出一辙,就是字典爆破。不过因为使用的协议不同了,建立链接的方式相应改变而已。
在学习过程中的小伙伴,可能会经常在一些靶场网站上练习,来强化自己的技能。如果刷题刷多了,我们会发现一个规律,题目需要的网页就那么几个,比如main.html,main.php,flag.php,flag.php3,robots.txt,index.html等等等等。这时,你就可以准备一个自己的刷题字典,每做一道题时,就先扫一遍。因为是特制的字典,不但针对性强,字典还很小,效率极其高,简直不要太爽。
下面说说缺点,可能有的小伙伴已经看到了。最开的动图里面扫出了两个页面index和robots,但是项目目录下有很多文件并没有扫到。为什么呢?对,就是因为事先准备的字典里没有。那第一个缺点就有了,它的扫描效果依赖字典的全面度。但是,当字典太大了,扫描时间又会变长,这也算是我们需要权衡的地方吧。
和端口扫描器一样啊,它也有特殊情况。在端口扫描里,有时建立连接失败恰恰说明端口开放,而网站目录扫描,在返回正常时,有时恰恰说明页面不存在。哈?理解不了。
其实这是开发者的一种安全手法,背后的逻辑就是,当用户访问不存在页面时,我给他统一返回一个指定的页面,比如跳转“主页”之类的。如此,每个请求都会成功,但是所请求页面却不一定存在。这会让许多扫描器丧失效果,那我们怎么处理这个问题呢?先记住这个问题,我们在实现的时候一点点想。
目前较为成熟的,或者比较出名的目录扫描器可能是“御剑”吧,听名字还挺修仙的,它应该属于早期的一款工具,感兴趣的小伙伴可以去了解下。
设计实现
类的设计
简单分析一下,需要的参数有什么呢?网站的主目录(host),这个是必须的。其次,还需要待拼接的子目录序列(paths),我们暂时将其设计成list。再有呢,就是多线程的数量(thread_num),毕竟扫描的太慢,我们也不太能接受。
属性完了,说行为。与端口扫描器差不多,需要一个开场动画animation,和启动扫描器的接口run。
能初步想到的就是这些,于是有:
| + host + thread_num + paths |
|---|
| + animation() + run() |
直接开始吧,依旧从init函数开始写起,因为它最明确,好设计。
class WebScanner(object):def __init__(self, host, thread_num, paths):"""initialization object"""self.host = host if host[-1] != '/' else host[:-1]self.thread_num = thread_numself.paths = paths
这里在初始化host的时候啊,我们做个判断看看最后是否有/,如果有的话就去掉。因为我们的子目录字典里的数据,默认格式都是开头有/的,为了避免重复,在这里多处理一下。
两个行为,最简单的当然是animation了。于是:
def animation(self):"""opening animation"""return r'''__ __ ___. _________
/ \ / \ ____\_ |__ / _____/ ____ _____ ____ ____ ___________
\ \/\/ // __ \| __ \ \_____ \_/ ___\\__ \ / \ / \_/ __ \_ __ \\ /\ ___/| \_\ \/ \ \___ / __ \| | \ | \ ___/| | \/\__/\ / \___ >___ /_______ /\___ >____ /___| /___| /\___ >__| \/ \/ \/ \/ \/ \/ \/ \/ \/ '''
字符画的设计,在端口扫描器里做了分享,这里再提供下。如果自己有其它好用的也是可以的哈。(传送门)
接下来设计重头戏吧,启动函数run。对于run呢,我们采用相同的处理方式,让它建立相应数量的子线程,子线程的工作再分一个函数写,这样的结构更加明确些(虽然这里没什么必要)。
def run(self):"""start scanner"""for i in range(self.thread_num):threading.Thread(target=self._subthread).start()
那子线程函数的设计呢?其实并不复杂,简单分析下,线程要做的就是从paths中拿出来一个子目录(可以用list的pop实现此行为),与主目录host进行拼接,并对其发送HTTP请求,根据请求结果输出相应内容就好了。
def _subthread(self):"get url from dictionary and try to connect"while self.paths:sub_url = self.paths.pop()headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/51.0.2704.63 Safari/537.36'}url = self.host + sub_urlreq = urllib.request.Request(url=url, headers=headers)try:##Discard requests longer than two secondsrequest = urllib.request.urlopen(req, timeout=1)result = request.geturl(), request.getcode(), len(request.read())print(result)except:pass
对于HTTP链接的建立,我选择了标准库urllib,并没有什么特殊的原因,只是因为它是标准库,不用另外安装。而且因为它是标准库,在速度层面上也是比较快的,如果你习惯用requests等第三方库,完全由你决定,reqeusts其实也是封装了urllib,做的工作比urllib多了很多,相应的会慢些。
对于请求成功与否的处理,我没有找到像socket中的connect_ex一样,可以替代connect不抛出异常的方法,所以这里用异常来处理的,如果你有更好的方式处理它,就放弃异常(因为它一点都不优雅)。
第二个注意点是header的设计,这里根据网站的反爬机制相应设计就好,你也可以把它设计成接口,让用户来自定义这个值。
还有一点,还记的在简介里,我们留下的那个问题吗?回去看一眼,再看看我们print的时候,是怎么知道哪些页面是不存在,但不抛出异常的。
ok,任务完成。但是我仍旧希望有计时功能,毕竟能看到运行时间,会显得工具很秀(sao)。
那运行时间应当从什么时候开始,什么时候结束呢?其实如果你看了端口扫描器,这个结论很好得出。在run建立线程的时候开始计时,最后一个线程完成任务后结束计时。如:
_running_time = 0_number_of_threads_completed = 0def run(self):"""start scanner"""WebScanner._running_time = time.time()for i in range(self.thread_num):threading.Thread(target=self._subthread).start()def _subthread(self):"get url from dictionary and try to connect"while self.paths:sub_url = self.paths.pop()headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/51.0.2704.63 Safari/537.36'}url = self.host + sub_urlreq = urllib.request.Request(url=url, headers=headers)try:##Discard requests longer than two secondsrequest = urllib.request.urlopen(req, timeout=1)result = request.geturl(), request.getcode(), len(request.read())print(result)except:passWebScanner._number_of_threads_completed += 1if WebScanner._number_of_threads_completed == self.thread_num:print("Cost time {} seconds.".format(time.time() - WebScanner._running_time))
至此,整个类的设计完毕。
测试脚本
接下来就可以测试一下啦。首先啊,创建对象我们需要host,thread_num,和paths。host和thread_num都好说,这个paths列表怎么得到呢?因为我们的字典都是一些文件,需要我们读取文件内容生成列表,那接受的用户参数就来指定读取哪些文件就好了。
def create_parser():parser = argparse.ArgumentParser(description="The scanner of web catalog")parser.add_argument("host", help="The url of web which will be scaned")parser.add_argument("--asp", help="Add 'asp' dict into search list", \action="store_true")parser.add_argument("--aspx", help="Add 'aspx' dict into search list", \action="store_true")parser.add_argument("--dir", help="Add 'dir' dict into search list", \action="store_true")parser.add_argument("--jsp", help="Add 'jsp' dict into search list", \action="store_true")parser.add_argument("--mdb", help="Add 'mdb' dict into search list", \action="store_true")parser.add_argument("--php", help="Add 'php' dict into search list", \action="store_true")parser.add_argument("-t", "--thread", help="The numbers of threads", type=int, choices= \[1, 3, 5], default=1)args = parser.parse_args()return args
可以看到,除了host和thread之外,添加了6个参数,他们的action值为“store_true”,它的作用是,当命令行有相应的参数时,此参数的值为True,单说不明白,举个例子。
如果命令行命令为:python 123.py http:xxxxx --dir --php
这里的parser.dir 和 parser.php的值就是True,换而言之,“store_true”的行为作用是,判断此参数是否存在。argparse module的使用:传送门
如此,读取文件生成列表就简单多了。
def read_dict(parser):''' load the dict '''combin = list()if parser.asp:with open('ASP.txt') as f:combin.extend(f.read().split())if parser.aspx:with open('ASPX.txt') as f:combin.extend(f.read().split())if parser.dir:with open('DIR.txt') as f:combin.extend(f.read().split())if parser.jsp:with open('JSP.txt') as f:combin.extend(f.read().split())if parser.mdb:with open('MDB.txt') as f:combin.extend(f.read().split())if parser.php:with open('PHP.txt') as f:combin.extend(f.read().split())return combin
我必须得承认,这里看着一点也不优雅,甚至有些丑陋,但是我忍了…(里面的文件,也都是和文章开头展示的文件一样,分别存着不同类型的子目录。通过分析网站的后台开发语言,有针对性的选择子目录范围,会有不错的效果~)
这样我们就生成了类需要的paths。那就写个测试脚本调用下吧。
完整节目单
import threading
import urllib.request
import argparse
import timeclass WebScanner(object):_running_time = 0_number_of_threads_completed = 0def __init__(self, host, thread_num, paths):"""initialization object"""self.host = host if host[-1] != '/' else host[:-1]self.thread_num = thread_numself.paths = pathsdef animation(self):"""opening animation"""return r'''__ __ ___. _________
/ \ / \ ____\_ |__ / _____/ ____ _____ ____ ____ ___________
\ \/\/ // __ \| __ \ \_____ \_/ ___\\__ \ / \ / \_/ __ \_ __ \\ /\ ___/| \_\ \/ \ \___ / __ \| | \ | \ ___/| | \/\__/\ / \___ >___ /_______ /\___ >____ /___| /___| /\___ >__| \/ \/ \/ \/ \/ \/ \/ \/ \/ '''def run(self):"""start scanner"""WebScanner._running_time = time.time()for i in range(self.thread_num):threading.Thread(target=self._subthread).start()def _subthread(self):"get url from dictionary and try to connect"while self.paths:sub_url = self.paths.pop()headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/51.0.2704.63 Safari/537.36'}url = self.host + sub_urlreq = urllib.request.Request(url=url, headers=headers)try:##Discard requests longer than two secondsrequest = urllib.request.urlopen(req, timeout=1)result = request.geturl(), request.getcode(), len(request.read())print(result)except:passWebScanner._number_of_threads_completed += 1if WebScanner._number_of_threads_completed == self.thread_num:print("Cost time {} seconds.".format(time.time() - WebScanner._running_time))def create_parser():parser = argparse.ArgumentParser(description="The scanner of web catalog")parser.add_argument("host", help="The url of web which will be scaned")parser.add_argument("--asp", help="Add 'asp' dict into search list", \action="store_true")parser.add_argument("--aspx", help="Add 'aspx' dict into search list", \action="store_true")parser.add_argument("--dir", help="Add 'dir' dict into search list", \action="store_true")parser.add_argument("--jsp", help="Add 'jsp' dict into search list", \action="store_true")parser.add_argument("--mdb", help="Add 'mdb' dict into search list", \action="store_true")parser.add_argument("--php", help="Add 'php' dict into search list", \action="store_true")parser.add_argument("-t", "--thread", help="The numbers of threads", type=int, choices= \[1, 3, 5], default=1)args = parser.parse_args()return argsdef read_dict(parser):''' load the dict '''combin = list()if parser.asp:with open('ASP.txt') as f:combin.extend(f.read().split())if parser.aspx:with open('ASPX.txt') as f:combin.extend(f.read().split())if parser.dir:with open('DIR.txt') as f:combin.extend(f.read().split())if parser.jsp:with open('JSP.txt') as f:combin.extend(f.read().split())if parser.mdb:with open('MDB.txt') as f:combin.extend(f.read().split())if parser.php:with open('PHP.txt') as f:combin.extend(f.read().split())return combinif __name__ == "__main__":parser = create_parser()scanner = WebScanner(parser.host, parser.thread, read_dict(parser))print(scanner.animation())scanner.run()关于main函数
前不久看到一篇微信服务号里的推文,作者很反感Python代码里面写“main函数”,我看了一下文章内容,作者反感它的原因是因为很多人根本不知道它的作用是什么,只是在“照猫画虎”的无脑模仿,并且认为这样比较规范。
这里也借助这个例子,我们来聊一聊Python的main函数。
“害,main函数有什么可聊的?不就是程序的入口嘛,我知道。”
这…,还真不是。Python里面所谓的main函数,和C&Java等语言里的main不同。它不是必须的,你在最开始写Python代码的时候,没有因为不写main导致程序运行不了的情况吧。
Python语言的设计和实现上,任何一个py文件(module)都可以作为程序入口,且为顺序执行。比如本文中的代码,当我们开始运行web.py(文件的保存名称)时,他会先执行import,将依赖module一个个导入,然后加载类,加载函数,最后执行到所谓的main函数,执行调用类和函数的脚本。而并不是我们以为然的程序从main函数开始执行。
那既然main没有用,它存在的意义是什么呢?这要从__name__这个变量说起。
每个module都维护着一个自己的name变量,相互之间没有影响。它主要用来标识当前module是自己在执行还是被调用了。
比如,我们直接运行web.py,此时name的值就是main,也因此代码中的if函数条件满足,所以之后的代码被执行了。当我们在另一个module通过import导入web这个module的时候,web.py整个内容会被执行,该加载的加载,该执行的执行。走到if条件语句的时候,这时候web的name值为“web”,即module本身的名字。简单讲,当自己执行时,name值为main;当被别人调用时,它的值为文件名(module名),如果调用它的module是直接执行的文件,那调用它的module里面的name为main;依次类推,如果调用它的module是被另个一module调用的,那调用它的module的name是它自己的文件名。(太绕,别迷糊了)
回到最初的问题上,它被设计出来的目的是什么呢?有一个比较简单能理解的作用,就是对当前写的单元做测试。比如文章里设计出来的scanner类,理应是被其他文件使用的,那当前代码有没有什么错误呢?写个脚本调用测试一下,就是那个所谓的main函数了。如果没有这个判断,当其他文件import web时,这里的脚本就会被执行,我们只是导入了module,结果模块里的测试脚本自己运行了,不就乱了套了吗。但是如果测试脚本是在main里面的,其他文件导入的时候,他就会因为判断条件不满足而不执行,这就是main函数的一种用处。
所以,我们的这种写法其实是为了偷懒。正确的设计方式应该是web里只有类的设计,对它的测试另外写一个py文件。如
web.py:
import threading
import urllib.request
import timeclass WebScanner(object):_running_time = 0_number_of_threads_completed = 0def __init__(self, host, thread_num, paths):"""initialization object"""self.host = host if host[-1] != '/' else host[:-1]self.thread_num = thread_numself.paths = pathsdef animation(self):"""opening animation"""return r'''__ __ ___. _________
/ \ / \ ____\_ |__ / _____/ ____ _____ ____ ____ ___________
\ \/\/ // __ \| __ \ \_____ \_/ ___\\__ \ / \ / \_/ __ \_ __ \\ /\ ___/| \_\ \/ \ \___ / __ \| | \ | \ ___/| | \/\__/\ / \___ >___ /_______ /\___ >____ /___| /___| /\___ >__| \/ \/ \/ \/ \/ \/ \/ \/ \/ '''def run(self):"""start scanner"""WebScanner._running_time = time.time()for i in range(self.thread_num):threading.Thread(target=self._subthread).start()def _subthread(self):"get url from dictionary and try to connect"while self.paths:sub_url = self.paths.pop()headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) ''Chrome/51.0.2704.63 Safari/537.36'}url = self.host + sub_urlreq = urllib.request.Request(url=url, headers=headers)try:##Discard requests longer than two secondsrequest = urllib.request.urlopen(req, timeout=1)result = request.geturl(), request.getcode(), len(request.read())print(result)except:passWebScanner._number_of_threads_completed += 1if WebScanner._number_of_threads_completed == self.thread_num:print("Cost time {} seconds.".format(time.time() - WebScanner._running_time))test.py:
import web
import argparsedef create_parser():parser = argparse.ArgumentParser(description="The scanner of web catalog")parser.add_argument("host", help="The url of web which will be scaned")parser.add_argument("--asp", help="Add 'asp' dict into search list", \action="store_true")parser.add_argument("--aspx", help="Add 'aspx' dict into search list", \action="store_true")parser.add_argument("--dir", help="Add 'dir' dict into search list", \action="store_true")parser.add_argument("--jsp", help="Add 'jsp' dict into search list", \action="store_true")parser.add_argument("--mdb", help="Add 'mdb' dict into search list", \action="store_true")parser.add_argument("--php", help="Add 'php' dict into search list", \action="store_true")parser.add_argument("-t", "--thread", help="The numbers of threads", type=int, choices= \[1, 3, 5], default=1)args = parser.parse_args()return argsdef read_dict(parser):''' load the dict '''combin = list()if parser.asp:with open('ASP.txt') as f:combin.extend(f.read().split())if parser.aspx:with open('ASPX.txt') as f:combin.extend(f.read().split())if parser.dir:with open('DIR.txt') as f:combin.extend(f.read().split())if parser.jsp:with open('JSP.txt') as f:combin.extend(f.read().split())if parser.mdb:with open('MDB.txt') as f:combin.extend(f.read().split())if parser.php:with open('PHP.txt') as f:combin.extend(f.read().split())return combinparser = create_parser()
scanner = WebScanner(parser.host, parser.thread, read_dict(parser))
print(scanner.animation())
scanner.run()
总结,main的存在可以简单理解,是为了测试代码不影响到未来可能import它的文件的运行结果。而我们这里写main,纯粹了为了偷懒,懒得再创建一个引用它的文件。
那这里可以去掉main吗?当然可以啊~,我们只用一个文件运行,有没有main没有任何的区别。我想这大概就是那个作者反感main的原因吧,本没有必要写,但在不明所以的情况下,当做语言规范写了。
如果大家是从C或Java语言转到的Python,把写main当成了一种习惯,也无可厚非,只是我们要知道,此main非彼main,他们的作用完全不可类比。
下篇尝试将这个工具做成桌面窗口版的,不知何时能写完(我是说文章哈,不是代码),暂定下周。
完。