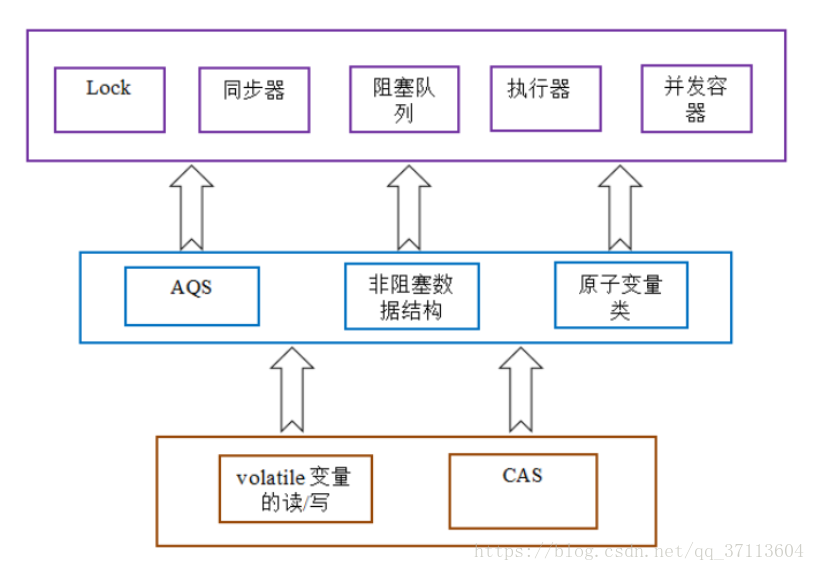
参考文章:Spark序列化
spark之kryo 序列化
Spark序列化入门
1. 什么是序列化和序列化?
- 序列化是什么
- 序列化的作用就是可以将对象的内容变成二进制, 存入文件中保存
- 反序列化指的是将保存下来的二进制对象数据恢复成对象
- 序列化对对象的要求
- 对象必须实现 Serializable 接口
- 对象中的所有属性必须都要可以被序列化, 如果出现无法被序列化的属性, 则序列化失败
- 限制
- 对象被序列化后, 生成的二进制文件中, 包含了很多环境信息, 如对象头, 对象中的属性字段等, 所以内容相对较大
- 因为数据量大, 所以序列化和反序列化的过程比较慢
- 序列化的应用场景
- 持久化对象数据
- 网络中不能传输 Java 对象, 只能将其序列化后传输二进制数据
2. Java序列化
Java序列化算法
- Serialization(序列化)是一种将对象以一连串的字节描述的过程;
- 反序列化deserialization是一种将这些字节重建成一个对象的过程。
- Java序列化API提供一种处理对象序列化的标准机制。
为什么要进行序列化?
Java中,一切都是对象,在分布式环境中经常需要将Object从这一端网络或设备传递到另一端。
这就需要有一种可以在两端传输数据的协议。
Java序列化机制就是为了解决这个问题而产生。
如何进行序列化?
一个对象能够序列化的前提是实现Serializable接口,Serializable接口没有方法,更像是个标记。
有了这个标记的Class就能被序列化机制处理。
序列化过程:
a、实现Serializable接口
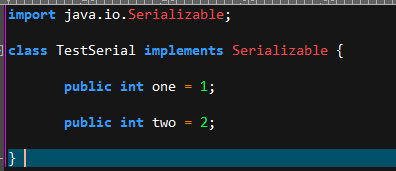
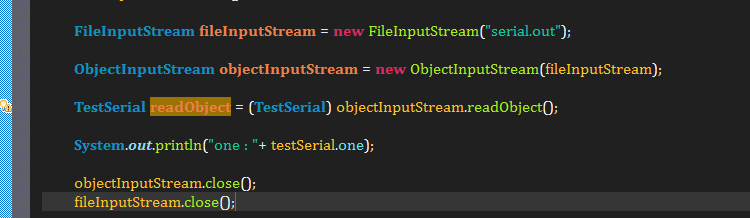
b、写个程序将对象序列化并输出(ObjectOutputStream能把Object输出成Byte流。将Byte流暂时存储到serial.out文件里)
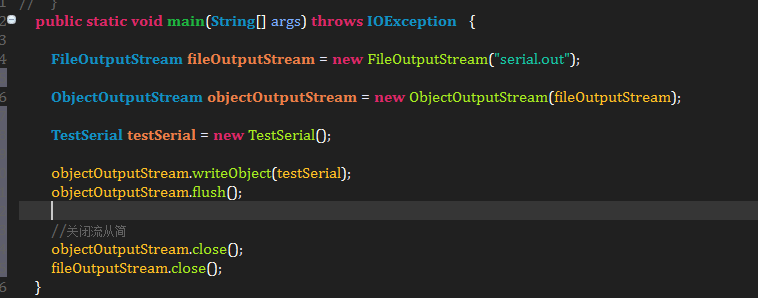
c、使用ObjectInputStream从持久的文件中读取Bytes重建对象
3. Spark序列化
大部分Spark程序都具有“内存计算”的天性,所以集群中的所有资源:CPU、网络带宽或者是内存都有可能成为Spark程序的瓶颈。
通常情况下,如果数据完全加载到内存那么网络带宽就会成为瓶颈,但是你仍然需要对程序进行优化,
例如采用序列化的方式保存RDD数据以便减少内存使用。
数据序列化不但能提高网络性能还能减少内存使用。几乎所有的资料都显示kryo 序列化方式优于java自带的序列化方式,而且在spark2.*版本中都是默认采用kryo 序列化。
在spark2.0+版本的官方文档中提到:spark默认提供了两个序列化库:Java自身的序列化和Kryo序列化
官网的解释是:java序列化灵活,但是速度缓慢。Kryo序列化速度更快且更紧凑,但是支持的类型较少。
而且spark现在已经默认RDD在shuffle的时候对简单类型使用了Kryo序列化。
3.1 Spark通过两种方式来创建序列化器
a. Java序列化
在默认情况下,Spark采用Java的ObjectOutputStream序列化一个对象。
该方式适用于所有实现了java.io.Serializable的类。
通过继承java.io.Externalizable,你能进一步控制序列化的性能。
Java序列化非常灵活,但是速度较慢,在某些情况下序列化的结果也比较大。
b. Kryo序列化
Spark也能使用Kryo(版本2)序列化对象。
Kryo 是 Spark 引入的一个外部的序列化工具, 可以增快 RDD 的运行速度,
因为 Kryo 序列化后的对象更小, 序列化和反序列化的速度非常快
Kryo不但速度极快, 而且产生的结果更为紧凑(通常能提高10倍)。
Kryo的缺点是不支持所有类型, 为了更好的性能, 需要提前注册程序中所使用的类(class)。
3.2 如何使用kryo序列化
可以在创建SparkContext之前,通过调用System.setProperty("spark.serializer", "spark.KryoSerializer"),
将序列化方式切换成Kryo。
但是Kryo需要用户进行注册,这也是为什么Kryo不能成为Spark序列化默认方式的唯一原因,
但是建议对于任何“网络密集型”(network-intensive)的应用,
都采用这种方式进行序列化方式。
Kryo文档描述了很多便于注册的高级选项,例如添加用户自定义的序列化代码。如果对象非常大,还需要增加属性spark.kryoserializer.buffer.mb的值。
该属性的默认值是32,但是该属性需要足够大以便能够容纳需要序列化的最大对象。如果不注册相应的类,Kryo仍然可以工作,
但是需要为了每一个对象保存其对应的全类名(full class name),这非常浪费。
spark中已经包含了kryo库,使用kryo只需要注册即可。官网只提供了scala版本的,java版本的如下:

或者:System.setProperty("spark.serializer", "org.apache.spark.serializer.KryoSerializer");
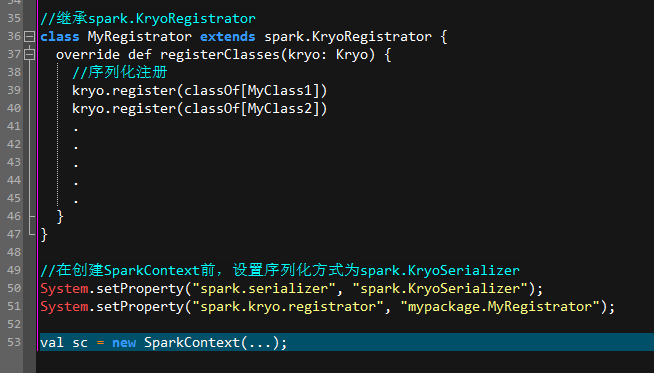
两者都可以用,但是测试好像没起到什么效果。于是需要手动注册:
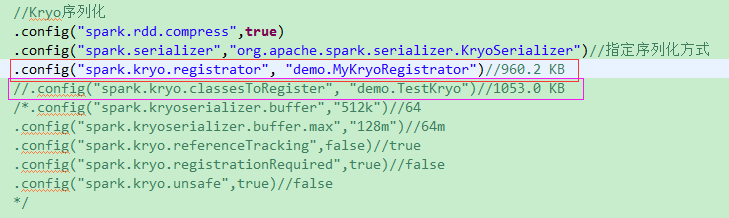
上图是关于kryo 的一些配置,可以单独注册自己的一个类,如紫色框线部分;
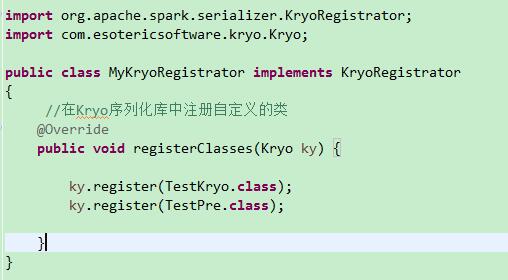
也可以像红色框线部分一样,自定义一个接口实现类MyKryoRegistrator,在这个类里面将所需的类全部注册。具体操作如下图:
如果需要序列化的类太多,就在这里逐一列举即可,当然被注册的类要实现java.io.Serializable,即:class TestKryo implements Serializable
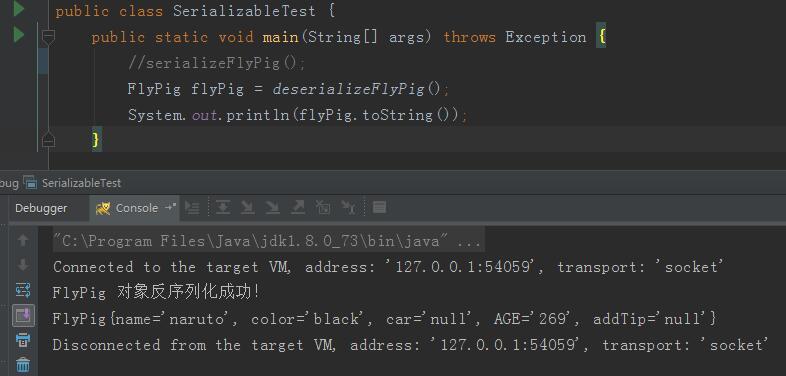
序列化的效果:
test程序验证效果:
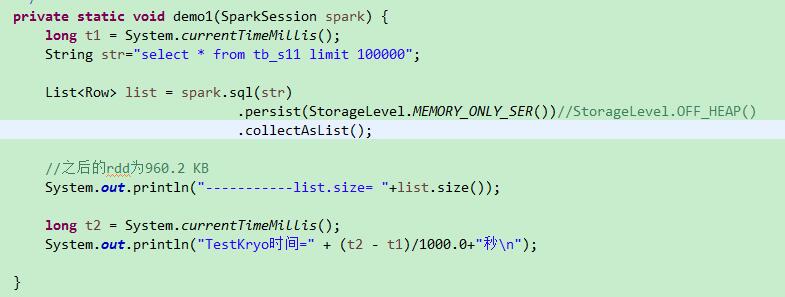
3.5 测试结果:
三种不同情况下的的RDD大小:
默认不序列化:2017.0 KB
在MyKryoRegistrator中序列化: 960.2 KB
只序列化demo.TestKryo:1053.0 KB
4. Spark 序列化和反序列化的应用场景
a.Task 分发
Task 是一个对象, 想在网络中传输对象就必须要先序列化
b.RDD 缓存
val rdd1 = rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
rdd1.cache
rdd1.collect
- RDD 中处理的是对象, 例如说字符串, Person 对象等
- 如果缓存 RDD 中的数据, 就需要缓存这些对象
- 对象是不能存在文件中的, 必须要将对象序列化后, 将二进制数据存入文件
c.广播变量

广播变量会分发到不同的机器上, 这个过程中需要使用网络, 对象在网络中传输就必须先被序列化
d. Shuffle 过程

- Shuffle 过程是由 Reducer 从 Mapper 中拉取数据, 这里面涉及到两个需要序列化对象的原因
- RDD 中的数据对象需要在 Mapper 端落盘缓存, 等待拉取
- Mapper 和 Reducer 要传输数据对象
- Spark Streaming 的 Receiver
Spark Streaming 中获取数据的组件叫做 Receiver, 获取到的数据也是对象形式, 在获取到以后需要落盘暂存, 就需要对数据对象进行序列化

d. 算子引用外部对象
class userserializable(i: Int)rdd.map(i => new Unserializable(i)).collect.foreach(println)
- 在 Map算子的函数中, 传入了一个 Unserializable 的对象
- Map 算子的函数是会在整个集群中运行的, 那 Unserializable 对象就需要跟随 Map 算子的函数被传输到不同的节点上
- 如果 Unserializable 不能被序列化, 则会报错
e. RDD 的序列化

- RDD 的序列化
RDD 的序列化只能使用 Java 序列化器, 或者 Kryo 序列化器
- 为什么?
RDD 中存放的是数据对象, 要保留所有的数据就必须要对对象的元信息进行保存, 例如对象头之类的 保存一整个对象, 内存占用和效率会比较低一些
- Kryo序列化示例
val conf = new SparkConf().setMaster("local[2]").setAppName("KyroTest")conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")conf.registerKryoClasses(Array(classOf[Person]))val sc = new SparkContext(conf)rdd.map(arr => Person(arr(0), arr(1), arr(2)))
f.DataFrame 和 Dataset 中的序列化
历史的问题
RDD 中无法感知数据的组成, 无法感知数据结构, 只能以对象的形式处理数据
DataFrame 和 Dataset 的特点:
- DataFrame 和 Dataset 是为结构化数据优化的
- 在 DataFrame 和 Dataset 中, 数据和数据的 Schema 是分开存储的
spark.read.csv("...").where($"name" =!= "").groupBy($"name").map(row: Row => row).show()- DataFrame 中没有数据对象这个概念, 所有的数据都以行的形式存在于 Row 对象中, Row 中记录了每行数据的结构, 包括列名, 类型等

- Dataset 中上层可以提供有类型的 API, 用以操作数据, 但是在内部, 无论是什么类型的数据对象 Dataset 都使用一个叫做 InternalRow 的类型的对象存储数据
val dataset: Dataset[Person] = spark.read.csv(...).as[Person]总结
- 当需要将对象缓存下来的时候, 或者在网络中传输的时候, 要把对象转成二进制, 在使用的时候再将二进制转为对象, 这个过程叫做序列化和反序列化
- 在 Spark 中有很多场景需要存储对象, 或者在网络中传输对象
- Task 分发的时候, 需要将任务序列化, 分发到不同的 Executor 中执行
- 缓存 RDD 的时候, 需要保存 RDD 中的数据
- 广播变量的时候, 需要将变量序列化, 在集群中广播
- RDD 的 Shuffle 过程中 Map 和 Reducer 之间需要交换数据
- 算子中如果引入了外部的变量, 这个外部的变量也需要被序列化
- RDD 因为不保留数据的元信息, 所以必须要序列化整个对象, 常见的方式是 Java 的序列化器, 和 Kyro 序列化器
- Dataset 和 DataFrame 中保留数据的元信息, 所以可以不再使用 Java 的序列化器和 Kyro 序列化器, 使用 Spark 特有的序列化协议, 生成 UnsafeInternalRow 用以保存数据, 这样不仅能减少数据量, 也能减少序列化和反序列化的开销, 其速度大概能达到 RDD 的序列化的 20 倍左右