文章目录
- 1. 写在前面
- 2. 问题阐述
- 3. 解释
- 3.1 一些不够完整的解释
- 3.2 一种完整的解释
- 3.2.1 去地址
- 3.2.2 节省空间
- 4. 小节
- 参考链接
1. 写在前面
我们应该都用过各种序列化(serialization)的方法(如Python中的pickle.dumps),甚至自己也写过一些序列化的小工具。
维基百科对于序列化的解释比较冗长;相比之下,百度百科的解释更为简单:
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程
这里面重点强调了两个概念:格式的转变和转变的目的
- [格式的转变] 转变前的格式是对象状态信息,转变后的格式是“可以存储或传输的形式”
- [转变的目的] 转变成字节流后的目的主要有两个:1. 存储到磁盘; 2. 通过网络进行传输
存储和传输的本质是一样的,都是I/O。我们后面就以磁盘存储为例进行说明。
转变后的格式(即:可存储或传输的形式)比较抽象。因为我们以磁盘存储为例进行说明,为方便表述,我们后面就以“存储格式”简称该转变后的格式。
序列化的作用又可以简单理解为:把内存中的数据存储到磁盘中的过程。
那么,一个随之而来的问题便是:
- 对象状态格式和存储格式的本质区别是什么?
- 或者:内存数据和磁盘数据的本质区别是什么?
2. 问题阐述
我们知道,内存和磁盘本质上都是存储二进制数据的。
那么,
- 为什么不直接把内存中的数据复制一份到磁盘中呢?
- 为什么要进行序列化?
- 如果只是为了数据持久化,直接进行数据的拷贝可以吗?
- 内存中数据格式和磁盘中数据格式的本质区别是什么?
- 既然内存和磁盘的存储本质是一样的,不考虑内存和磁盘的数据存取速度差异,使用磁盘直接和cache、CPU进行数据交互可以吗(即跳过内存这一级别)?这个想法似乎和NVM有些不谋而合了。
这些问题其实说的是同一个问题。
3. 解释
3.1 一些不够完整的解释
以上一系列问题中,“为什么要进行序列化”这个问题可能是最直接的。在网上也能搜索到一些答案,包括:
- 跨语言:某种编程语言(Java)在磁盘上存储的数据,有可能被别的编程语言(C++)读取
- 跨平台:这个问题在网络传输时更为突出,在A机器上可能为小端序,在B机器上则为大端序
这些答案虽然也有道理,但我觉得还不够完整。
假设我们使用同一门编程语言,在同一个机器上,还需要进行序列化吗?
答案是:可能需要。
3.2 一种完整的解释
我们知道,序列化其实主要是进行了数据格式的转换,即从内存格式转换为磁盘格式。
进行该转换还有两个很重要的原因:去地址和节省空间。
3.2.1 去地址
对于一些包含地址或引用的数据结构(如二叉树),对象第一次在内存中的地址,和数据落盘后重新加载到内存中的地址,极有可能是不同的。
因此,需要对这种数据结构的对象,进行一些“去地址”的操作。该操作往往便是通过“序列化”来完成。
可能有人会想到在将对象落盘时,同时记录下对象中的内存地址。第二次加载对象时,按照之前记录的地址进行内存分配。
但内存一般是由多个应用共享的,第二次加载对象时,之前地址对应的内存空间可能已经被占用了。
3.2.2 节省空间
前面提到一个问题:为什么不直接把内存中的数据复制一份到磁盘中呢?
复制操作对于一些简单的数据结构(尤其是内存连续的数据结构)是可行的,比如说一个byte。在不考虑字节顺序(大/小端序)的前提下,一个int也是可行的。实际上,序列化操作对于这些简单数据结构也是这么复制处理的。
但对于二叉树这种复杂的数据结构,复制操作便不可行了。
现代操作系统的内存管理往往了采用了“内存分页”、“逻辑空间”的机制。逻辑空间连续的页面在物理空间中往往是分散的。
对于二叉树这种复杂的数据结构,树中不同的节点可能存储在不同的内存页面中,这些页面分散在内存的不同地方。
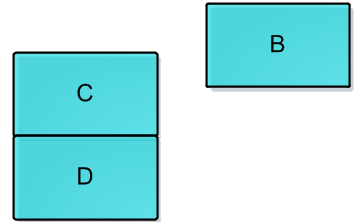
如下图所示,一棵二叉树的三个节点分别对应内存中编号为1,10,15的三块内存空间。如果进行简单复制,需要将1~15编号的整块内存数据复制到磁盘中,即使2,3,4等编号的内存空间跟当前二叉树无关。这便造成了严重的磁盘空间浪费。

这里引申出另外一个问题:既然物理内存是共享使用的(如,编号为2的内存空间可以由其他对象甚至应用使用),那么磁盘空间可以共享使用吗?如将红色框中的磁盘空间也提供给别的应用使用。这似乎可以解决“磁盘空间浪费”的问题。
理论上这是可以的,但这要求在磁盘管理层面对这些“可共享”的空间进行记录、管理和再分配。相当于在磁盘层面实现一套类似于“内存分页”和“逻辑空间”映射的机制,这大大增加了磁盘管理的复杂度。
采用“序列化”的方法的目的之一,也是为了解决“磁盘空间浪费”的问题。与磁盘层面的管理不同,“序列化”相当于在应用层面进行了管理,将数据更紧密地存储在一起,如下图所示:

4. 小节
序列化操作的本质是将对象中的字节组织成(顺序的)字节流的过程。
序列化的主要目的包括四点:
- 实现数据的跨语言使用
- 实现数据的跨平台使用
- 数据去内存地址
- 降低磁盘存储空间
实现后两者目的的根本原因是:对象对内存地址的操作。
参考链接
- Understanding serialization
- 维基百科 - 序列化
- 百度百科 - 序列化
- Why do we use serialization?
- Why do we serialize data?
- 实体类为啥要序列化