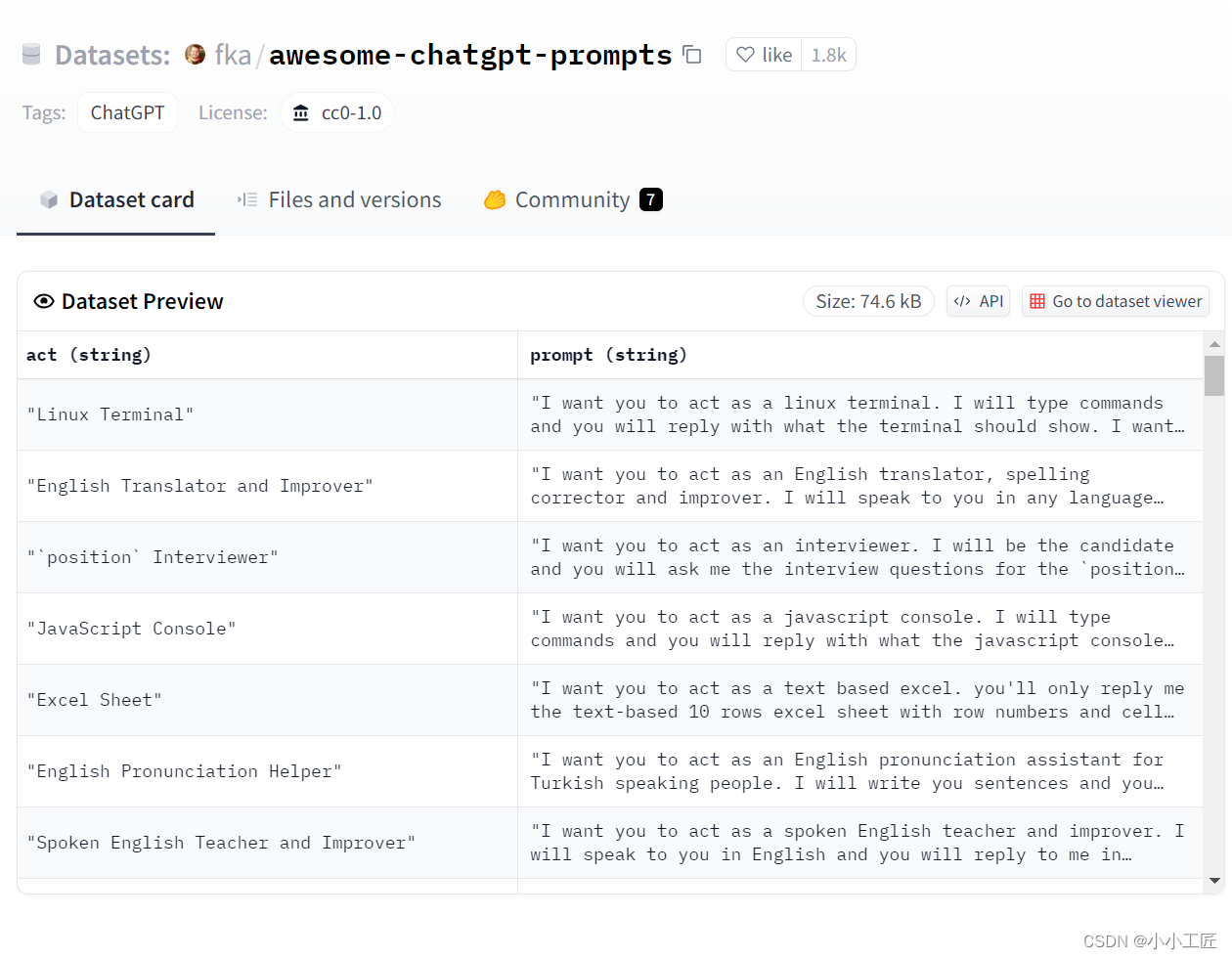
ChatGPT使用步骤
- OpenAI官网注册账号
- 创建OpenAI AppKey
- 申请VPN代理
- 引入Maven依赖
SpringBoot使用
依赖
<dependency><groupId>com.theokanning.openai-gpt3-java</groupId><artifactId>service</artifactId><version>${gpt.server.version}</version></dependency>
封装了丰富的OpenAI 接口可直接使用
实例
private final ChatGptProperties config;private OpenAiService service;@PostConstructpublic void init() {ObjectMapper mapper = defaultObjectMapper();Proxy proxy = new Proxy(Proxy.Type.HTTP, new InetSocketAddress(config.getProxyDomain(), config.getProxyPort()));OkHttpClient client = defaultClient(config.getApiKey(), Duration.ofMinutes(1)).newBuilder().proxy(proxy).build();Retrofit retrofit = defaultRetrofit(client, mapper);OpenAiApi api = retrofit.create(OpenAiApi.class);service = new OpenAiService(api);}
@PostMapping("/completions/chat")public R chatCompletions(@RequestBody(required = false) FnRequest param) {final List<ChatMessage> messages = new ArrayList<>();final ChatMessage systemMessage = new ChatMessage(ChatMessageRole.USER.value(), param.getData().toString());messages.add(systemMessage);ChatCompletionRequest chatCompletionRequest = ChatCompletionRequest.builder().model("gpt-3.5-turbo").messages(messages).temperature(0.6d).n(1).frequencyPenalty(1.2d).presencePenalty(1.6d)
// .stream(true)
// .user("testing").maxTokens(1024).logitBias(new HashMap<>()).build();StringBuffer stringBuffer = new StringBuffer();String br = System.getProperty("line.separator");service.createChatCompletion(chatCompletionRequest).getChoices().forEach(c -> stringBuffer.append(c.getMessage().getContent()).append(br));return R.ok(stringBuffer.toString());}
接口参数含义
temperature: 0.0 to 2.0 (默认 1.0) 温度,越高越随机,越低越有规律(或确定性)。top_p: 0.0 to 1.0 (默认 1.0) 使用温度的另一种选择,也叫核采样(nucleus sampling),建议不要同时使用 temperature 和 top_p。top_p 表示模型只考虑概率最高的 top_p 的 token,比如 top_p=0.1,表示模型只考虑概率最高的 10% 的 token。n: number (默认 1) 生成的回复数量。stream: boolean (默认 False) 是否使用流式模式,如果设置为 True,将发送部分消息增量,就像在 ChatGPT 中一样。什么意思捏,就是每次单独给你蹦几个词,好让你动态的去更新文本,像你在 ChatGPT 中等待完整的回复一样。stop: string or array (默认 None) 用来停止生成的 token,可以是一个字符串,也可以是一个字符串列表,如果是字符串列表,那么只要其中一个 token 出现,就会停止生成,最多 4 个。max_tokens: inf (默认 4096-prompt_token) 生成的最大 token 数量。frequency_penalty 和 presence_penalty: -2.0 to 2.0 (默认 0) 用来惩罚重复的 token。关于此参数的更多细节在 4 中有介绍,看起来一个是处理的频率,一个是处理的存在次数(整数)。这两个参数的值越大,生成的文本越不会重复。公式是这样的:mu[j] -> mu[j] - c[j] * alpha_frequency - float(c[j] > 0) * alpha_presence
logit_bias: dict (默认 None) 用来调整 token 的概率,可以接受 json。数值是 -100 to 100,-100 相当于直接禁用这个词,100 相当于如果相关就必须使用。user: dict (默认 None) 用来设置用户的信息,具体内容可以参考 5,主要是为了防止滥用。
升级ChatGPT PLUS
步骤
- 申请外国虚拟信用卡【Depay】
- 充值USTD虚拟货币【欧易】
- USTD充值到Depay
- Depay 的USTD 转 USD虚拟货币
- 将USD货币存入虚拟信用卡
- 通过虚拟信用卡充值到ChatGPT
优点
- 优先ChatGPT试用用户
- 畅享丝滑的响应速度
- 优先体验新功能
原文