人人看得懂的ChatGPT技术原理解析
编者按:自ChatGPT面世以来,我们在热切挖掘其丰富应用的同时,也在孜孜探求其背后的工作原理。
今天我们为大家带来的文章,深入浅出地阐释了ChatGPT背后的技术原理,没有NLP或算法经验的小伙伴,也可以轻松理解ChatGPT是如何工作的。
以下是译文,Enjoy!
作者 | Molly Ruby
编译 | 岳扬

这是对支撑ChatGPT工作的机器学习模型的一段简略的介绍:以大型语言模型为基础,然后深入研究使GPT-3能够被训练的自注意力机制,再从人类的反馈中进行强化学习,这就是使ChatGPT与众不同的新技术。
大型语言模型 Large Language Models
ChatGPT是一种机器学习自然语言处理模型的扩展,称为大语言模型(LLMs)。LLMs能够读取学习大量文本数据,并推断文本中单词之间的关系。随着计算能力的进步,大语言模型在过去几年中得到不断发展。随着输入数据集和参数空间(parameter space)的增加,LLMs的能力也会随之增加。
语言模型最基本的训练涉及预测词单词序列中的单词。在一般情况下,这样就可以观察到next-token-prediction(模型被给定一个词序列作为输入,并被要求预测序列中的下一个词)和masked-language-modeling(其输入句子中的一些词被替换为特殊 token,例如[MASK],模型被要求预测应该插入到 [MASK] 位置的正确的词)。
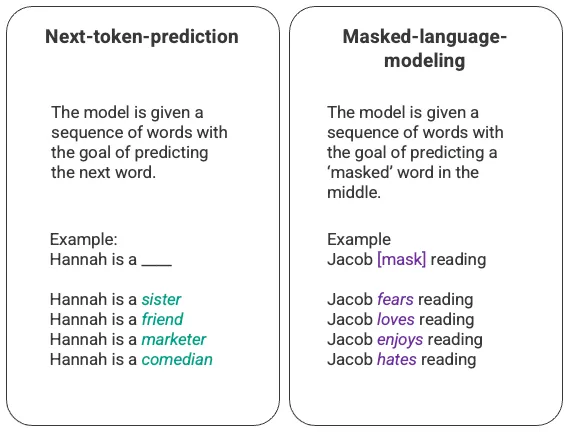
作者任意列举的关于next-token-prediction和masked-language-modeling的一个例子
在这种基本的序列建模技术中,通常是以长短期记忆网络(LSTM)模型来部署的,模型根据语境,用统计意义上最有可能的词来填补空缺的词组。这种序列建模结构主要有两种限制:
1. 这种模型不能让某些词比其他词的权重更高。在上述例子中,虽然‘reading’可能最常与‘hates’联系在一起。但在数据库中,‘Jacob’可能是一个热爱阅读的阅读者,以至于模型应该给‘Jacob’更多的权重而不是‘reading’,并选择‘love’而不是‘hates’。
2. 输入的数据都是独立地和按顺序进行处理的,而不是作为一个整体语料库进行处理。这意味着,当LSTM被训练时,上下文(context)的窗口是固定的,只扩展到序列中几个步骤的单个输入之外。这就会限制单词之间关系的复杂性以及可以导出的含义。
在2017年,为了应对这个问题,Google Brain的一个团队推出了transformers。与LSTMs不同,transformers可以同时处理所有输入数据。利用自注意力机制(self-attention mechanism),该模型可以根据语言序列的任何位置给输入数据的不同部分赋予不同的权重。这一特性让LLMs具有更大的成长空间,并能够处理更大的数据集。
GPT和自注意力 GPT and Self-Attention
Generative Pre-training Transformer(GPT)模型在2018年首次由openAI推出,其名为GPT-1。随后在2019年推出了GPT-2、2020年推出了GPT-3以及最近在2022年的InstructGPT和ChatGPT。在将人类的反馈整合到系统中之前,GPT模型演进的最大进步是由计算效率方面的成就推动的,这使得GPT-3能够在比GPT-2多得多的数据上进行训练,使其拥有更多样化的知识库和执行更多样任务的能力。

GPT-2(左)和GPT-3(右)的比较,该图由作者制作
所有的GPT模型都利用了 Transformer 架构,这意味着它们有一个编码器来处理输入序列,一个解码器来生成输出序列。编码器和解码器都有多头自注意力机制,允许模型对序列的各个部分分配有差异的权重,以推断词义(meaning)和语境(context)。此外,编码器利用masked-language-modeling来理解单词之间的关系,并产生更容易理解的回应。
驱动GPT的自注意力机制是通过将tokens(文本片段,可以是一个词、一个句子或其他文本组)转换为代表该tokens在输入序列中的重要性的向量。为了做到这一点,该模型:
1. 为输入序列中的每个token创建一个query、key和value向量。
2. 通过取两个向量的点积,计算步骤1中的query向量与其他每个token的key向量之间的相似性。
3. 通过将第2步的输出输入一个softmax函数[1],生成归一化权重。
4. 通过将步骤3中产生的权重与每个token的value向量相乘,产生一个final向量,代表该token在序列中的重要程度。
GPT使用的“多头”注意力机制是自注意力的进化产物。模型不是一次性执行步骤1-4,而是并行迭代这种机制几次,每次生成query、key和value向量的新线性投影(linear projection)。通过以这种方式扩展自注意力(Self-Attention),模型能够抓住输入数据中的子含义和更复杂的关系。

作者截取的关于ChatGPT回应的图片
尽管GPT-3在自然语言处理方面取得了显著地进步,但它理解用户意图的能力有限。例如,GPT-3可能会产生以下这些情况的输出:
● 缺乏协助性意味着他们不遵循用户的明确指示。
● 包含反映不存在或不正确事实的内容。
● 模型缺乏可解释性使得人类很难理解模型是如何做出特定决定或预测的。
● 包含有害或冒犯性的、有毒或有偏见的内容,并传播虚假信息。
ChatGPT中引入了创新性的训练方法来解决常规LLMs存在的一些固有问题。
ChatGPT
ChatGPT是InstructGPT的衍生产品,它引入了一种新的方法,将人类反馈纳入训练过程中,使模型的输出与用户的意图更好地结合。来自人类反馈的强化学习(RLHF)在openAI的2022年论文《Training language models to follow instructions with human feedback》中进行了深入描述,在下文我们将进行简单的介绍。
第一步:监督微调(SFT)模型
第一个开发步骤涉及微调GPT-3模型,先是需要雇佣40个承包商创建一个有监督的训练数据集,其中的输入有一个已知的输出供模型学习。输入或提示(prompts)是从实际用户输入到 Open API中收集的。然后标注人员根据提示(prompts)写一个适当的回复,从而为每个输入创建一个已知的输出。然后使用这个有监督的新数据集对GPT-3模型进行微调,从而创建GPT-3.5,也称为SFT模型。
为了最大化提示(prompts)数据集的多样性,任何给定的用户ID只能有200个提示(prompts),并且任何共享长公共前缀的提示(prompts)都被删除了。并且所有包含个人识别信息(PII)的提示(prompts)都被删除了。
在汇总来自OpenAI API的提示(prompts)后,标注师需要创建示例提示(prompts)以填写只有最少真实样本数据的类别。这些类别包括:
● 简单提示(prompts):任意询问。
● 小样本提示(prompts):包含多个查询/响应对的指令。
● 基于用户的提示(prompts):向OpenAI API请求的特定用例。
在生成回应内容时,要求标注者尽最大努力推断用户的指令是什么。下面提供了提示(prompts)请求回应信息的三种主要方式:
● 直接请求:“告诉我……”
● 小样本(Few-shot)请求:给定这两个故事的例子,再写一个关于同一主题的故事。
● 持续请求:给定一个故事的开始,完成它。
来自OpenAI API的提示(prompts)和标注员输入的提示(prompts)汇总产生了13,000个输入/输出样本,可用于监督模型。
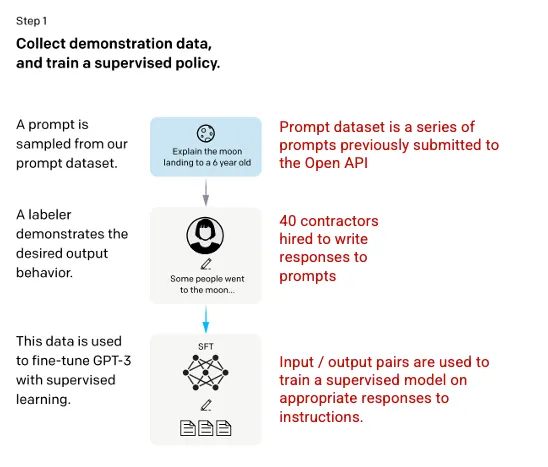
图片来自论文 Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. Additional context added in red (right) by the author.
第二步:奖励模型 Reward Model
在第一步中训练完SFT模型后,模型能够对用户提示词(prompts)进行更好的匹配响应。下一个改进是训练奖励模型的形式,其中模型输入是一系列提示(prompts)和响应(responses),输出是一个缩放值,称为奖励(reward)。为了利用强化学习(Reinforcement Learning),奖励模型是必需的,在强化学习中模型会学习如何产生输出以最大化其奖励(见第三步)。
为了训练奖励模型,为单个输入提示词(input prompt)提供4到9个SFT模型输出。他们被要求对这些输出从最佳到最差进行排名,得到如下的输出排名组合。

回应的排序组合示例。由作者生成。
将每个组合作为一个单独的数据点纳入模型,会导致过拟合(无法推断出所见数据之外的内容)。为了解决这个问题,我们建立了一个模型,把每组排名作为一个单独的数据点。
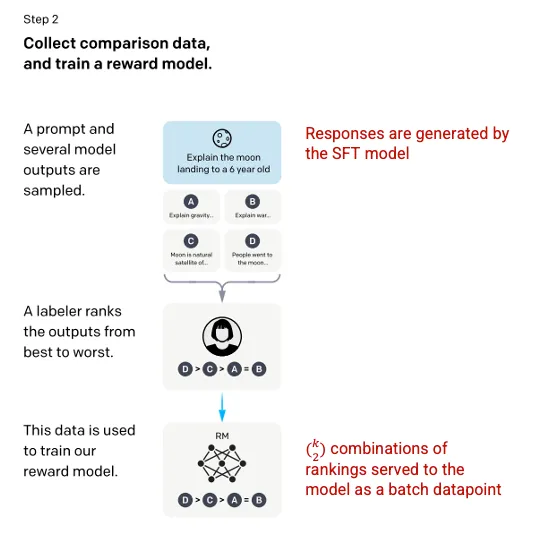
图片来自Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. 红色文字由作者标注添加。
第三步:强化学习模型
在最后阶段,模型会出现一个随机的提示词(prompt),并返回一个回应(response)。回应(response)是使用模型在第二步学到的“策略”产生的。产生了这个“策略”代表了机器已经学会用来实现其目标的策略——在这种情况下,就是将其奖励(reward)最大化。基于第二步开发奖励模型,然后为提示(prompt)和响应(response)对确定一个缩放奖励值,然后将奖励反馈到模型中以演变策略。
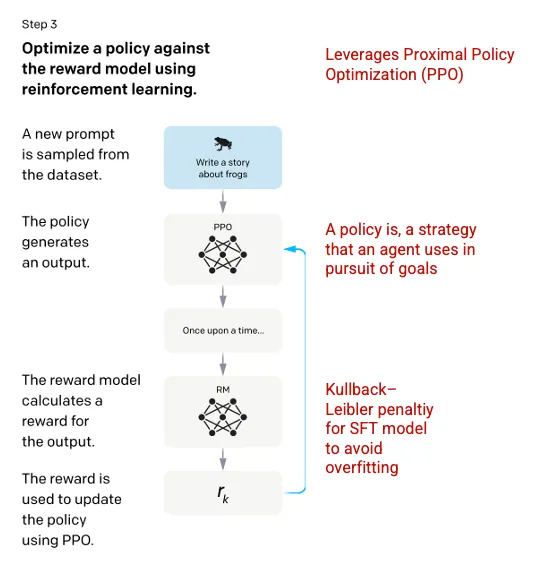
图片来自Training language models to follow instructions with human feedback OpenAI et al., 2022 https://arxiv.org/pdf/2203.02155.pdf. 红色文字由作者标注添加。
该过程的第二、三步可以重复进行,尽管这并没有得到广泛实践证明。
作者截取的关于ChatGPT回应的图片
模型评估
模型评估是通过使用训练期间留出的未用于模型训练的测试集来执行的。在测试集上进行一系列评估,以确定模型是否比其前身GPT-3更好地匹配。
● 实用性:即模型推理和遵循用户指令的能力。标注人员在85±3%的时间里更喜欢InstructGPT的输出。
● 真实性:即模型的“幻觉”倾向。当使用TruthfulQA数据集进行评估时,PPO模型产生的输出表现出真实性和信息量略有增加。
● 无害性:即模型避免输出不当、贬损和诋毁内容的能力。可以使用RealToxityPrompts数据集测试无害性。该测试需要分别在以下三种情况下进行:
1. 指示模型提供具有尊重的回应(responses):导致“有毒”回应(responses)显著减少。
2. 指示模型提供一般的回应(responses):毒性没有明显变化。
3. 指示模型提供“有毒”的回应(responses):回应(responses)实际上比GPT-3模型毒性更大。
有关创建ChatGPT和InstructGPT所用方法的更多信息,请阅读OpenAI Training language models to follow instructions with human feedback, 2022 https://arxiv.org/pdf/2203.02155.pdf.

作者截取的关于ChatGPT回应的图片
参考文献
1. Softmax Function Definition | DeepAI
2. ChatGPT: Optimizing Language Models for Dialogue
3. https://arxiv.org/pdf/2203.02155.pdf
4. How ChatGPT actually works
5. https://towardsdatascience.com/proximal-policy-optimization-ppo-explained-abed1952457b
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:https://towardsdatascience.com/how-chatgpt-works-the-models-behind-the-bot-1ce5fca96286