目录
- 直接在main函数中执行语句
- 借助@Test来运行方法
- 删除表
- 修改表结构
- 列出来所有的表
- 插入一条数据
- 获取一行数据
- 创建表
- 批量读取文件中的数据,并且批量插入表中
- 获取一组数据的值
- 利用CellUtil改善读取数据方式
导入依赖
<dependency><groupId>org.apache.hbase</groupId><artifactId>hbase-client</artifactId><version>1.4.6</version></dependency>
直接在main函数中执行语句
需求:在hbase中创建一张表testAPI,有一个列簇cf1,并且修改列簇cf1的versions属性值为3
package Demo.hbase;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HColumnDescriptor;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;import java.io.IOException;public class demo1 {public static void main(String[] args) throws IOException {//1.创建一个配置文件,根据这个配置文件来决定怎么连接到hbase数据库Configuration conf = HBaseConfiguration.create();//配置ZK的地址,通过ZK可以找到Hbase//Hbase的元数据信息都存放在ZK里面,因此要操作Hbase,需要给出的是ZK的地址//"hbase.zookeeper.quorum"来自安装hbase时配置的hbase-site.xml里面的配置信息conf.set("hbase.zookeeper.quorum","master:2181,node1:2181,node2:2181");//2.根据上面的配置文件创建连接Connection conn = ConnectionFactory.createConnection(conf);//3.如果需要对表结构操作,则getAdmin// 对数据进行操作,则getTableAdmin admin = conn.getAdmin();//创建testAPI表,并指定一个列簇cf1,并将cf1的版本设置为3/*** 这里的思路应该是,首先要通过admin.createTable()语句建表,但是建表需要表的信息* 因此通过new HTableDescriptor的方式获取表的信息,但是HTableDescriptor创建完成后里面没有列簇的信息* 因此又通过new HColumnDescriptor的方式建立列簇的相关信息* 而列簇的具体属性配置等,有专门的方法,比如这里的setMaxVersions** 这样一环套一环,修改列簇属性,将修改后的列簇信息放入表信息* 最后admin.createTable(testAPI)利用表信息创建表*///HTableDescriptor包含了表的名字及其对应表的列族HTableDescriptor testAPI = new HTableDescriptor(TableName.valueOf("testAPI"));//创建一个列簇//HColumnDescriptor维护着关于列族的信息,例如版本号,压缩设置等HColumnDescriptor cf1 = new HColumnDescriptor("cf1");//对列簇进行配置cf1.setMaxVersions(3);//给testAPI表增加一个列簇testAPI.addFamily(cf1);//创建testAPI表admin.createTable(testAPI);//用完后关闭连接admin.close();conn.close();}
}

创建成功
借助@Test来运行方法
由于要写的方法太多,因此这里使用Junit框架,利用@Test来执行语句
首先给出要导入的全部jar包,以及 @Before 和 @After 方法,之后的所有方法都在这两个方法里面。这样每个@Test方法执行之前都会先执行@Before方法,执行完成之后都会自动执行@After方法
package Demo.hbase;import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.junit.After;
import org.junit.Before;
import org.apache.hadoop.conf.Configuration;
import org.junit.Test;import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;public class demo2 {Connection conn;Admin admin;@Beforepublic void createConn() throws IOException {// 1、创建一个配置文件Configuration conf = HBaseConfiguration.create();// 配置ZK的地址,通过ZK可以找到HBaseconf.set("hbase.zookeeper.quorum", "master:2181,node1:2181,node2:2181");// 2、创建连接conn = ConnectionFactory.createConnection(conf);// 3、创建Admin对象admin = conn.getAdmin();}@Afterpublic void close() throws IOException {admin.close();conn.close();}
}删除表
@Test//drop tablepublic void dropTable() throws IOException{TableName test2 = TableName.valueOf("test2");//判断表是否存在if(admin.tableExists(test2)){//在删除表之前要先禁用表admin.disableTable(test2);admin.deleteTable(test2);}}
结果为
hbase(main):002:0> list=> ["test", "test1", "test2", "testAPI"]hbase(main):004:0> list=> ["test", "test1", "testAPI"]
修改表结构
@Test//修改表结构//针对test表,将info列簇的ttl设置为10000,并增加一个新的列簇cf1public void modifyTable() throws IOException{TableName test = TableName.valueOf("test");//获取表原有的结构HTableDescriptor tableDescriptor = admin.getTableDescriptor(test);//在表原有的结构中,修改列簇的属性//获取test表中全部的列簇HColumnDescriptor[] columnFamilies = tableDescriptor.getColumnFamilies();//遍历表中的原有的全部列簇for (HColumnDescriptor c : columnFamilies) {//找到需要修改的列簇infoif("info".equals(c.getNameAsString())){c.setTimeToLive(10000);}}//新增一个列簇//要要新增一个列簇就需要在表信息test里面增加新列簇的信息//因此先创建新列簇的信息HColumnDescriptor cf1 = new HColumnDescriptor("cf1");//将cf1添加到表信息中tableDescriptor.addFamily(cf1);//根据修改后表信息admin.modifyTable(test,tableDescriptor);}
结果为
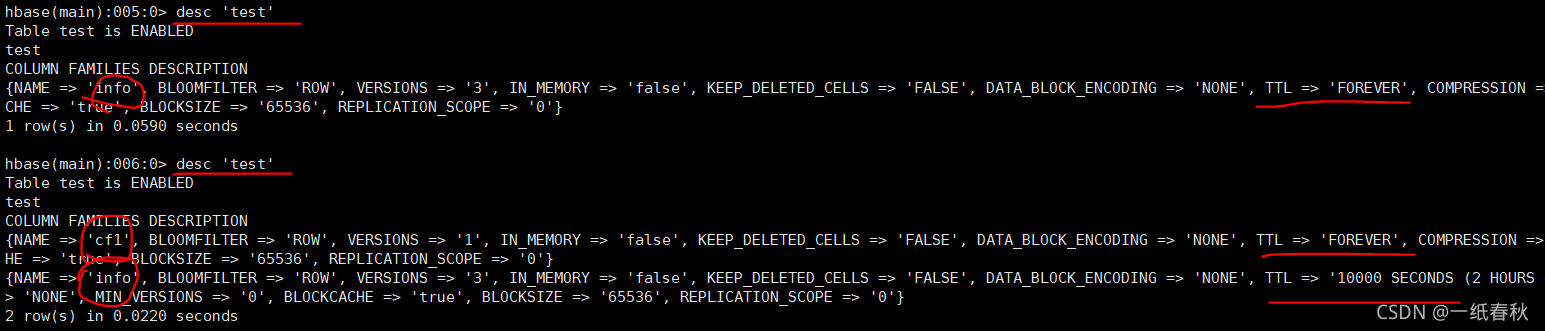
列出来所有的表
@Test//列出来所有的表public void listTable() throws IOException{TableName[] tableNames = admin.listTableNames();for (TableName tableName : tableNames) {System.out.println(tableName.getNameAsString());}}
结果为

插入一条数据
@Test//插入数据public void put() throws IOException{//之前修改表结构用的都是 getAdmin//这里要修改的是数据,因此用的是 getTableTable testAPI = conn.getTable(TableName.valueOf("testAPI"));//同样插入数据也需要对应的对象信息,这里是put//要想插入一条数据,需要rowkey和value,这里在创建put对象时指定rowkey//注意使用getBytes()转换为字节数组的形式Put put = new Put("0001".getBytes());//接下来获取要插入的value值//addColumn括号里面的参数从左到右依次为列簇,列名,具体的值put.addColumn("cf1".getBytes(),"name".getBytes(),"zhang".getBytes());//利用put对象信息插入数据testAPI.put(put);}
结果为
hbase(main):003:0> scan 'testAPI'
ROW COLUMN+CELL
0 row(s) in 0.0100 secondshbase(main):004:0> scan 'testAPI'
ROW COLUMN+CELL 0001 column=cf1:name, timestamp=1638286764676, value=zhang
1 row(s) in 0.0220 seconds
获取一行数据
@Test//获取数据public void get() throws IOException{Table testAPI = conn.getTable(TableName.valueOf("testAPI"));Get get = new Get("0001".getBytes());//利用get对象信息获取对应的结果resultResult result = testAPI.get(get);//获取rowkeybyte[] row = result.getRow();//row的类型是字节数组,所以应该借助Bytes转换成字符串输出System.out.println(Bytes.toString(row));//获取cellbyte[] name = result.getValue("cf1".getBytes(), "name".getBytes());System.out.println(Bytes.toString(name));}
结果为

创建表
@Test//创建表public void createTable() throws IOException{//表信息 studentHTableDescriptor student = new HTableDescriptor(TableName.valueOf("student"));//列簇信息 infoHColumnDescriptor info = new HColumnDescriptor("info");//将列簇信息info加入到表信息student里面student.addFamily(info);//根据表信息student建表admin.createTable(student);}
结果为
hbase(main):006:0> list=> ["student", "test", "test1", "testAPI"]
批量读取文件中的数据,并且批量插入表中
@Test//读取学生的全部信息并写入之前创建的student表中public void putAll() throws IOException{//读取学生信息BufferedReader br = new BufferedReader(new FileReader("data/students.txt"));//与hbase里面的student表建立连接Table student = conn.getTable(TableName.valueOf("student"));String line = null;//创建put的集合,用于批量插入数据,避免每次循环都执行一次put语句ArrayList<Put> puts = new ArrayList<>();int batchSize = 11;while((line=br.readLine())!=null){//写入hbase里面的student表String[] split = line.split(",");String id = split[0];String name = split[1];String age = split[2];String gender = split[3];String clazz = split[4];//往put对象里面放入rowkeyPut put = new Put(id.getBytes());//往put对象里面放入value//addColumn()括号里面的参数依次是列簇,列名,值byte[] info = "info".getBytes();put.addColumn(info,"name".getBytes(),name.getBytes());put.addColumn(info,"age".getBytes(),age.getBytes());put.addColumn(info,"gender".getBytes(),gender.getBytes());put.addColumn(info,"clazz".getBytes(),clazz.getBytes());//批量执行,将当前循环的新的put对象放入puts集合中puts.add(put);//当puts集合的大小和之前设定的batchSize大小一致时//利用getTable获取的student对象来调用put方法,将puts里面的数据写入student表//注意不要混淆,利用put方法,将puts集合中的多个put对象的数据写入student表if(puts.size() == batchSize){student.put(puts);//集合里面的数据都写入完后,清空集合,准备迎接下一批次的数据puts.clear();}}System.out.println(puts.isEmpty());System.out.println(puts.size());//这里还要注意一件事情,那就是students文件的数据总数是batchSize的整数倍时才能全部写入//否则会有几条语句因为不满batchSize的大小,没有触发student的put方法//因此在这里再加上一个判断,如果还有几条数据没有写入,那么写入if(!puts.isEmpty()){student.put(puts);}//关闭brbr.close();}结果为

这里的false说明还有几条数据没有被写入student表中,因为数据数量没有达到batchSize的值
下面的10,说明是每10条数据触发一次写入,即一次性写入十条数据进入student表中
结果为
hbase(main):008:0> count 'student'
Current count: 1000, row: 1500101000
1000 row(s) in 0.6270 seconds=> 1000
总共一千条数据,写入成功
获取一组数据的值
@Test//获取一组数据//利用scan读取student表里面的全部数据public void scanStudent() throws IOException{Table student = conn.getTable(TableName.valueOf("student"));//设置scan对象信息,指定扫描范围,有两种方法Scan scan = new Scan();//方法一,限制rowkey的值,左开右闭,【startRow,stopRow)scan.withStartRow("1500100100".getBytes());scan.withStopRow("1500100111".getBytes());//方法二,限制返回的条数scan.setLimit(10);//利用student对象调用getScanner方法,具体的扫描信息来源自上面定义的scan对象for (Result result : student.getScanner(scan)) {String id = Bytes.toString(result.getRow());String name = Bytes.toString(result.getValue("info".getBytes(),"name".getBytes()));String age = Bytes.toString(result.getValue("info".getBytes(),"age".getBytes()));String gender = Bytes.toString(result.getValue("info".getBytes(),"gender".getBytes()));String clazz = Bytes.toString(result.getValue("info".getBytes(),"clazz".getBytes()));//输出打印扫描到的每一行的数据System.out.println(id+","+name+","+age+","+gender+","+clazz);}}
结果为

利用CellUtil改善读取数据方式
@Test//利用CellUtil获取一行数据的全部单元格里面的值//向上面那个方法一个一个指定列名不仅麻烦,而且如果哪一行的列名不一致,又会读取null或者读取不到//因此使用listCells + CellUtil,可以不用考虑每条数据的结构public void scanWithCellUtil() throws IOException{Table student = conn.getTable(TableName.valueOf("student"));//给scan增加扫描范围限制,这次只扫描最后十行Scan scan = new Scan();scan.withStartRow("1500100990".getBytes());//利用scan获取一组数据for (Result result : student.getScanner(scan)) {//获取rowkeyString id = Bytes.toString(result.getRow());System.out.print(id+" "); //注意使用print,让rowkey和value在同一行//利用listCells将一行数据的全部cell列出来//然后再利用CellUtil从每一个cell中获取数据List<Cell> cells = result.listCells();for (Cell cell : cells) {String value = Bytes.toString(CellUtil.cloneValue(cell));System.out.print(value+" ");}System.out.println();//打印完最后一行数据后换行}}结果为

对于多版本(versions)的数据,必须使用CellUtil的方式取数据,否则只能取得最新版本的数据