一、什么是深度森林?
传统DNN的不足:
1、需要大量的数据集来训练;
2、DNN的模型太复杂;
3、DNN有着太多的超参数
gcForest的优势:
1、更容易训练;
2、性能更佳;
3、效率高且可扩展、支持小规模训练数据。
深度森林是一个新的基于树的集成学习方法,它通过对树构成的森林进行集成并串联起来达到让分类器做表征学习的目的,从而提高分类的效果。
二、深度森林的结构
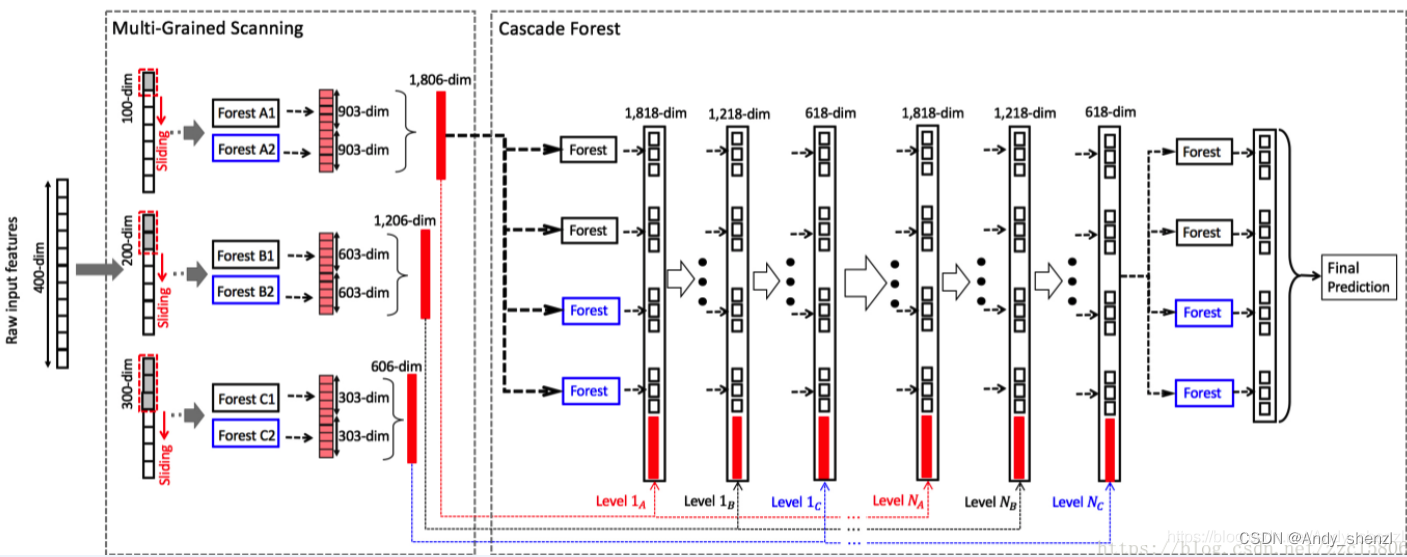
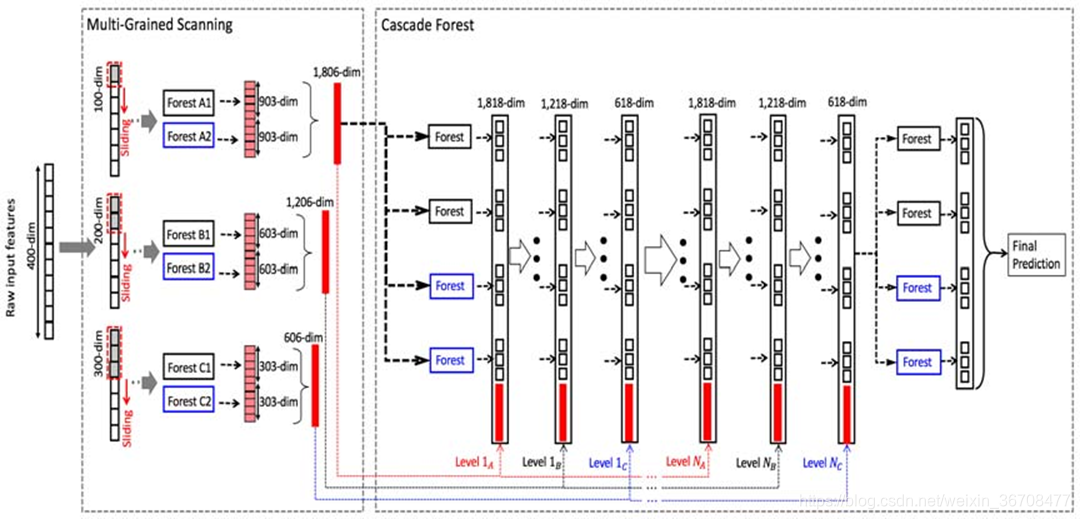
其结构主要包括级联森林和多粒度扫描。
1.级联森林
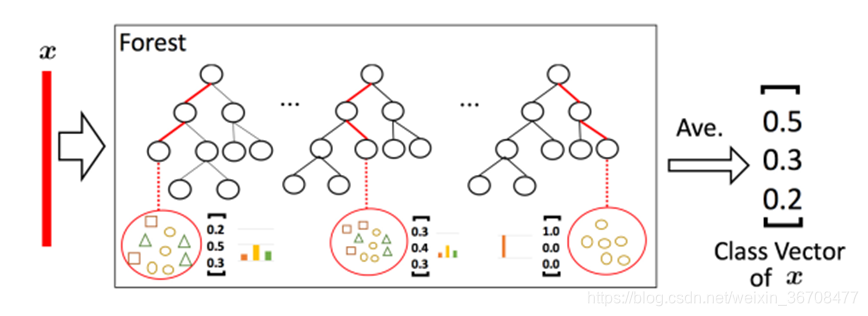
级联森林的构成:级联森林的每一个Level包含若干个集成学习的分类器(这里是决策树森林),这是一种集成中的集成的结构。
为了体现多样性,这里用了两种代表了若干不同的集成学习器。图中的级联森林每一层包括两个完全随机森林(黑色)和两个随机森林(蓝色)。这两种森林的主要区别在于候选特征空间,完全随机森林是在完整的特征空间中随机选取特征来分裂,而普通随机森林是在一个随机特征子空间内通过基尼系数来选取分裂节点。
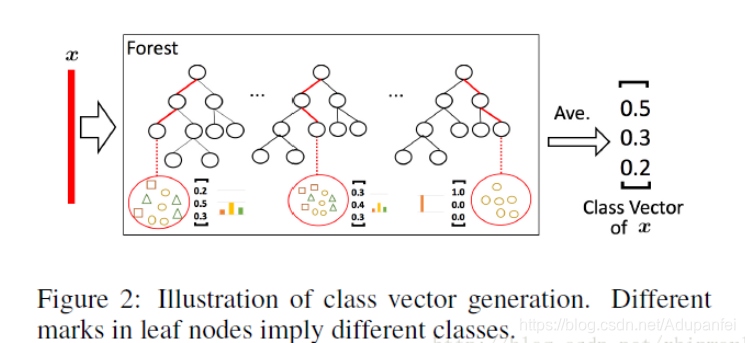
我们都知道决策树其实是在特征空间中不断划分子空间,并且给每个子空间打上标签(分类问题就是一个类别,回归问题就是一个目标值),所以给予一条测试样本,每棵树会根据样本所在的子空间中训练样本的类别占比生成一个类别的概率分布,然后对森林内所有树的各类比例取平均,输出整个森林对各类的比例。也就是每个森林都会生成一个长度为 C 的概率向量,假如 gcforest 的每一层由 N 个森林构成,那么每一层的输出就是 N 个 C 维向量连接在一起,即 C*N 维向量。gcForest采用了DNN中的layer-by-layer结构,从前一层输入的数据和输出结果数据做concat作为下一层的输入。这个向量然后与输入到级联的下一层的原始特征向量相拼接(图 中粗红线部分),作为下一层的输入.这样我们就做了一次特征变化,并保留了原始特征继续后续处理,每一层都这样,最后一层将所有随机森林输出的三维向量加和求平均算出最大的一维作为最终输出。
例如,在图中的三分类问题中,每层由 4 个随机森林构成,而每个森林都将生成一个 3 维向量,因此,每层产生一个 4*3=12 维的特征向量,此特征向量将作为下一层的输入增强原始特征。

为了降低过拟合风险,每个森林生成的类向量是通过 k 折交叉验证产生的即,每个样本都会被 当作训练数据训练 k-1 次,产生 k-1 个类3维向量,然后对其取平均值即为这个森林最终特征向量,再将这4个森林的3维特征向量连在一起,作为下一层的增强特征向量.
那么这样一层一层接下去什么时候停止呢。在扩展一个新的层后,整个级联的性能将在验证集上进行评估,如果没有显着的性能提升,训练过程将终止 因此,级联中层的数量是自动确定的。
下图是每个森林的决策过程。
2.多粒度扫描
在日常生活中,由于数据的特征之间可能存在某种关系,例如,在图像识别中,位置相近的像素点之间有很强的空间关系,序列数据有顺序上的关系。gcForest 使用多粒度扫描对级联森林进行增强,即,它利用多种大小的滑动 窗口进行采样,以获得更多的特征子样本,从而达到多粒度扫描的效果。
比如图中的例子:
对于序列数据,假设我们的输入特征是400维,扫描窗口大小是100维,这样就得到301个100维的特征向量,每个100维的特征向量对应一个3分类的类向量(3维类向量),即得到:301个*3维类向量!最终每棵森林会得到903维的特征变量!特征就更多更丰富对于图像数据的处理和序列数据一样,图像数据的扫描方式当然是从左到右、从上到下,而序列数据只是从上到下。可以用各种尺寸不等的扫描窗口去扫描,这样就会得到更多的、更丰富的特征关系!

3.整体结构
那么深度森林一个整体结构就如图所示:
在图中,假设有 3 个类,并且分别使用 100 维 200 维 300 维的窗口在原始 400 维的特征上进行滑动。(3个级联森林 每个级联森林都N层)得到特征向量后再使用级联森林进行训练,得到最后的预测模型和结果。
三、实践-简单分类实例
Paper:https://arxiv.org/abs/1702.08835v2
Github:https://github.com/kingfengji/gcForest
Website:http://lamda.nju.edu.cn/code_gcForest.ashx
南京大学机器学习与数据挖掘研究所提供了基于Python 2.7官方实现版本,在本文中,我们使用基于Python3实现的gcForest实现分类任务。
Github:https://github.com/pylablanche/gcForest
gcForest类与sklearn包装的分类器使用方法类似,使用 a .fit() 进行训练,使用a .predict() 进行预测。其中需要我们进行设置的属性为shape_1X和window。shape_1X由数据集决定(所有样本必须具有相同的形状),而window取决于我们自己的选择。
分类器构建时需要的参数如下所示:
shape_1X: int or tuple list or np.array (default=None)训练量样本的大小,格式为[n_lines, n_cols]. n_mgsRFtree: int (default=30)多粒度扫描时构建随即森林使用的决策树数量.window: int (default=None)多粒度扫描时的数据扫描窗口大小.stride: int (default=1)数据切片时的步长大小.cascade_test_size: float or int (default=0.2)级联训练时的测试集大小.n_cascadeRF: int (default=2)每个级联层的随机森林的大小.n_cascadeRFtree: int (default=101)每个级联层的随即森林中包含的决策树的数量.min_samples_mgs: float or int (default=0.1)多粒度扫描期间,要执行拆分行为时节点中最小样本数.min_samples_cascade: float or int (default=0.1)训练级联层时,要执行拆分行为时节点中最小样本数.cascade_layer: int (default=np.inf)级联层层数的最大值tolerance: float (default=0.0)判断级联层是否增长的准确度公差。如果准确性的提高不如tolerance,那么层数将停止增长。n_jobs: int (default=1)随机森林并行运行的工作数量。如果为-1,则设置为cpu核心数.
在这里,我们使用sklearn带有的Iris数据集进行分类测试,Iris数据集是常用的分类实验数据集。Iris也称鸢尾花卉数据集。数据集包含150个数据集,分为3类,每类50个数据,每个数据包含4个属性。可通过花萼长度,花萼宽度,花瓣长度,花瓣宽度4个属性预测鸢尾花卉属于(Setosa,Versicolour,Virginica)三个种类中的哪一类。
iris.data 原始数据集,150×4,4代表四个属性。
[[5.1 3.5 1.4 0.2] [4.9 3. 1.4 0.2] [4.7 3.2 1.3 0.2] [4.6 3.1 1.5 0.2] [5. 3.6 1.4 0.2]…...等等,不一一列出。
iris.target:目标分类结果数据集 150x1 。0、1、2分别代表3个类 ,每个类有50个样本。
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2]
具体代码如下所示:
# 对鸢尾花数据集进行测试
iris = load_iris()
X, y = iris.data, iris.target
#===iris.data这是150个数据集 每个数据有四个属性
#iris.target150个数据的分类结果 0 1 2 分别表示三个类
print('==========================Data Shape======================')
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
#从样本中随机的按比例选取train_data和test_data这里去0.3 即训练数据和测试数据都是随机选45个
model = GCForest.gcForest(shape_1X=4, window=2, tolerance=0.0)
model.fit(X_train, y_train) #fit(X,y) 在输入数据X和相关目标y上训练gcForest;
joblib.dump(model,'irisModel.sav') #持久化存储 保存模型 加载模型
model=joblib.load('irisModel.sav')
y_predict = model.predict_proba(X_test) #预测未知样本X的类概率;
y_predict = y_predict.tolist()
y_predict1 = model.predict(X_test) #预测未知样本X的类别;
print('==========================y_predict======================')
print('预测的分类结果',y_predict1)
print("---每个样本对应每个类别的概率---")
for one_res in y_predict:
print(one_res)
accuarcy = accuracy_score(y_true=y_test, y_pred=y_predict1)
print('gcForest accuarcy : {}'.format(accuarcy))