Nifi的安装使用
爱购物 www.cqfenfa.comNifi安装
首先说一下Nifi的安装,这里Nifi可以支持Windows版和Linux,只需要去官网:http://nifi.apache.org/
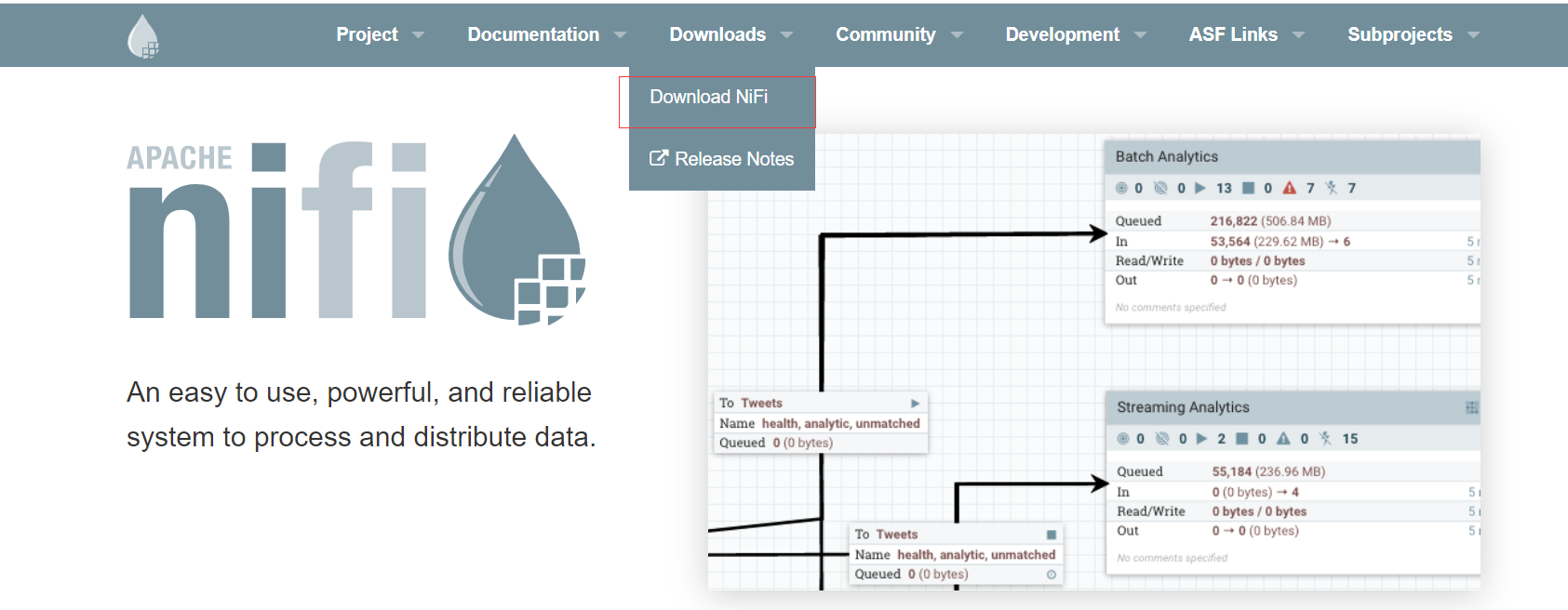
根据自己需要的版本,选择下载,然后安装解压就行
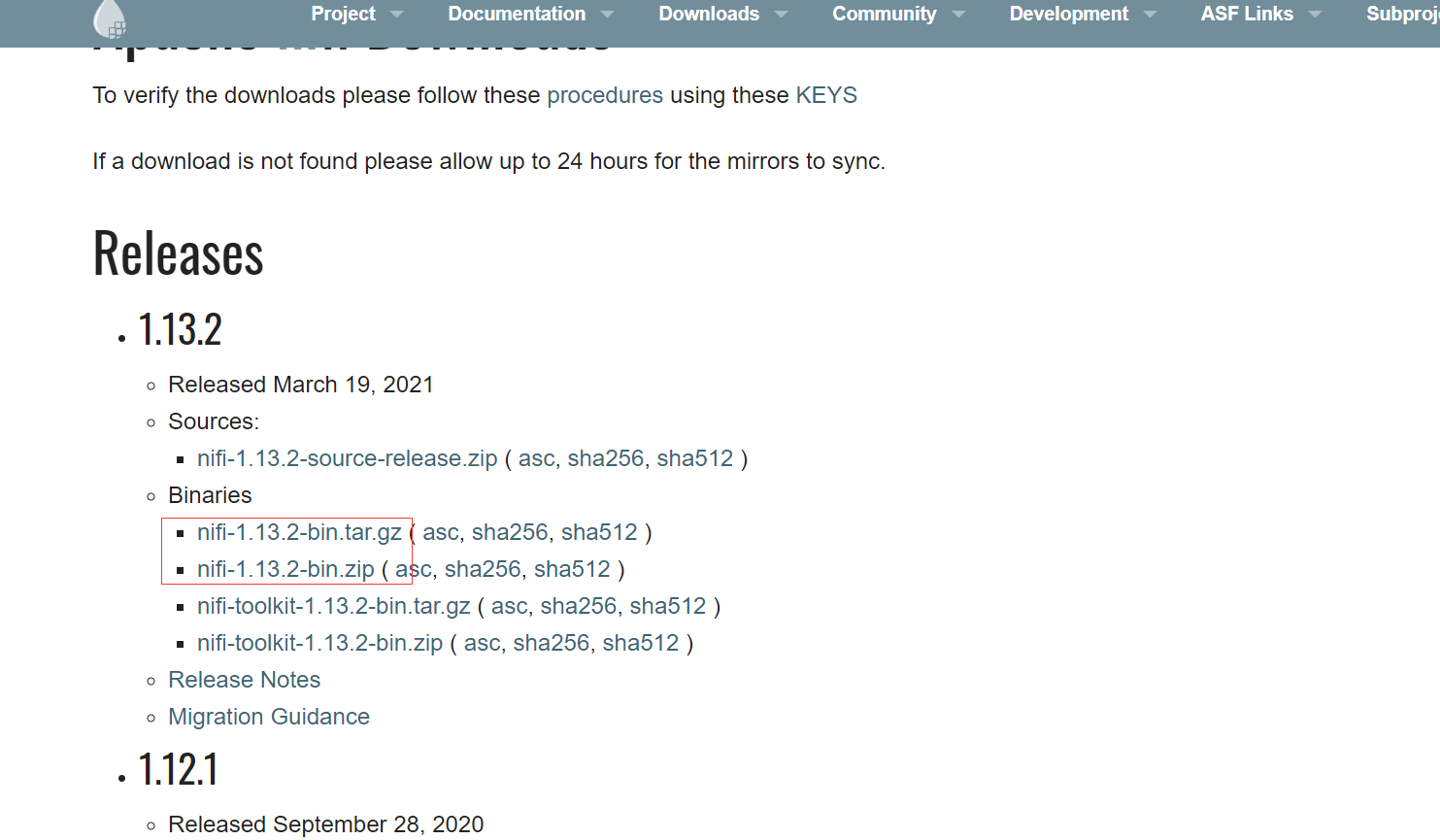
各目录及主要文件
解压安装以后的Nifi目录如下:
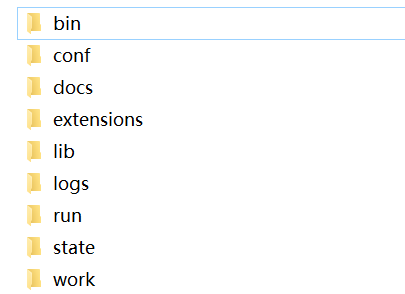
基本的,bin目录下放置了 整个系统的控制脚本,lib目录下放置的Nifi自带的一个个nar程序包(其实就是Nifi内置的一个个组件)和它本身的程序所需要的加载编译等等的底层包,state是运行期间的一些数据,docs和work 是Nifi的一些官方文档和学习样例
conf目录下放置的是Nifi的配置文件,这里详细说一下:
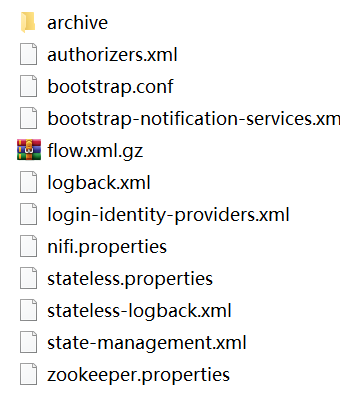
作为我们基本的使用,这里只需要注意两个文件就好,关于其他的配置,有兴趣的可以去Nifi官网查看,首先是 nifi-properties 文件,这个文件基本就是整个Nifi的配置中心,里面包含很多的基本配置,例如启动端口啊、内存分配啊等等,第二个就是 flow.xml.gz,这个文件主要是你整个nifi使用的全记录,解释的通俗点,如果你遇到了这么一个问题 “ 我在一台机器上部署了一个Nifi,并且进行了一段时间的使用,建立了很多流程和功能,这时候,需要换到别的机器的Nifi上进行开发”,你建立那些肯定不能挨个再在新环境上来一遍啊,这时候只需要把这个flow.xml.gz替换到新机器的Nifi环境里,重启新环境的Nifi就可以了。
logs目录里放的是Nifi运行后的主要的日志
这里运行后会有三个日志, 分别是:
nifi-app.log 整个应用的运行日志
nifi-bootstrap.log 底层类加载一系列的日志
nifi-user.log 就简单理解为用户的访问操作日志吧
Nifi的页面使用
Nifi默认启动端口是8080,使用 windows下就bin目录下双击 run-nifi.bat ,Linux下就 在/bin目录下,执行 ./nifi.sh start
主页面介绍
进入主页面以后,它整体就是一个画布的形式,最上方是个公共导航栏,左侧那个Navigate没啥用,不用在意,就是一个全局视角,下面的Operate是组件控制面板,可以进行单个组件的控制,也可以选中一片组件进行统一的启动,停止等等。
面板介绍
首先:

刚刚已经把Nifi的整个页面理解为一个工作台,最上方就是个导航栏了,从最上面开始,这里的导航栏分为两部分,上半部分是提供给我们工作的,下半部分是对整个Nifi环境下的一个监控信息。这里简单介绍一下
![]() 导航栏中的这个菜单,我们可以理解为处理器(Processor)商城,用鼠标单击拖出到画布上,便会出现处理器(Processor)菜单
导航栏中的这个菜单,我们可以理解为处理器(Processor)商城,用鼠标单击拖出到画布上,便会出现处理器(Processor)菜单
![]() 导航栏中这个菜单,我叫它为组,什么叫组呢,当你拉了很多处理器(Processor),形成了一个完整的流程的时候,我们可以单独把这块划分成一个整体了,这时候就要用组把它包裹起来。
导航栏中这个菜单,我叫它为组,什么叫组呢,当你拉了很多处理器(Processor),形成了一个完整的流程的时候,我们可以单独把这块划分成一个整体了,这时候就要用组把它包裹起来。
![]() 有了组以后,组和组之间可能也需要联通、通信,这时候就可以用入口和出口,把它们放在组内
有了组以后,组和组之间可能也需要联通、通信,这时候就可以用入口和出口,把它们放在组内
![]() 这个组件需要配合 Operate 中的 上传使用,主要是用来迁移模板的,这块后续会专门抽章节讲一下
这个组件需要配合 Operate 中的 上传使用,主要是用来迁移模板的,这块后续会专门抽章节讲一下
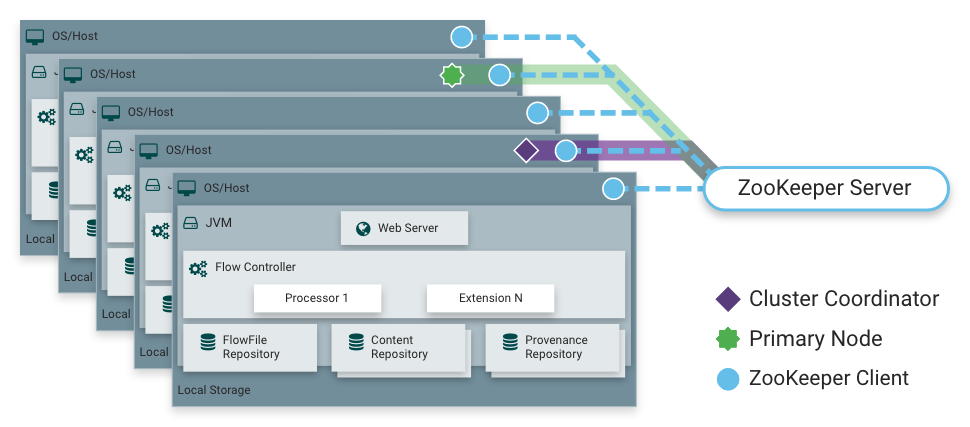
![]() 这一组件,是集群Nifi进行数据通信的时候用的
这一组件,是集群Nifi进行数据通信的时候用的
![]() 这一组件,就是个便签,用来写个备注呀啥的
这一组件,就是个便签,用来写个备注呀啥的
 这一组件就是个漏斗,主要作用就是把四散的数据可以汇集在一起。
这一组件就是个漏斗,主要作用就是把四散的数据可以汇集在一起。
Nifi的工作方式
这里侧重点是Nifi中的处理器应用,关于集群、组配合等等方式不在此篇记录的重点中。
基本方式
首先回顾我们上篇内容说的,Nifi其实就是一个数据接入、处理、清洗、分发的系统,它的工作方式就是将数据看作水管中的水,它是顺着某个流程管道流动,在这中间,可以在任意节点处堵截这个“水流”,并对它进行改造,然后放回管道继续向下流去。
这里的节点,其实就是Nifi的Processor,你叫它处理器也可以,叫他组件也好,它就是一个黑盒小模块,不同的模块有不同的功能
然后,节点和节点直接的通道,在Nifi里叫Relationship,我把它称之为管道,就像水管一样,它本身的意义就是充当水管,把上节点处理完的水传下去。
在nifi中,都是一个个的流程(处理器+管道),形成一个数据的处理通路。

像这个例子,GetFile组件负责从一个文件里读取数据,然后把读到的数据通过管道传到ExecuteScript组件(这个组件支持用脚本代码处理数据),经过ExecuteScript之后,流向PutFile组件(将数据写入到指定文件中)。
基本流程就是 : 选则一个处理器——>配置该组件至可运行状态——>关联下一组件建立管道
选择处理器
![]() 通过“组件商城” 图标进行处理器的选择, 处理器是最常用的组件,因为它负责数据的流入,流出,路由和操作。有许多不同类型的处理器。实际上,这是NiFi中非常常见的扩展点,这意味着许多供应商可能会实现自己的处理器来执行其所需的任何功能。将处理器拖动到画布上时,会向用户显示一个对话框:
通过“组件商城” 图标进行处理器的选择, 处理器是最常用的组件,因为它负责数据的流入,流出,路由和操作。有许多不同类型的处理器。实际上,这是NiFi中非常常见的扩展点,这意味着许多供应商可能会实现自己的处理器来执行其所需的任何功能。将处理器拖动到画布上时,会向用户显示一个对话框:

这里可以通过处理器的包、处理器的属性、处理器的名称等维度进行组件的筛选、选择。选中后,双击则可拖拉至画布中。
组件状态
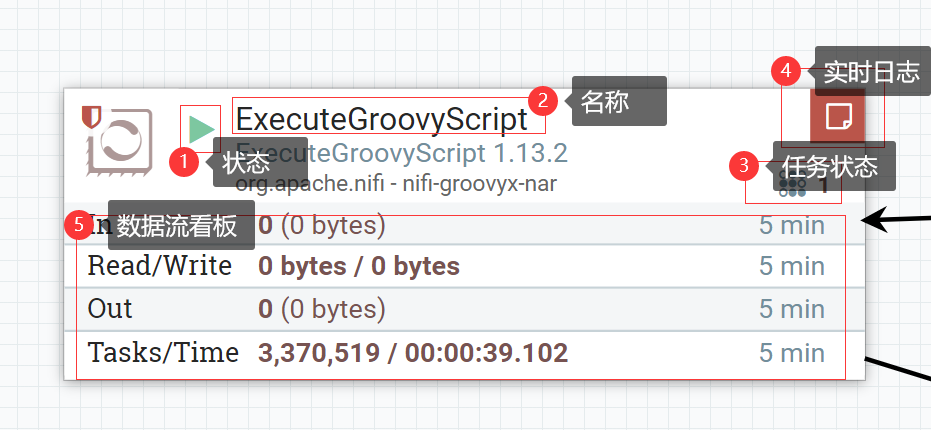
-
状态:显示处理器的当前状态。以下指标是可能的:
-
 正在运行:处理器当前正在运行。
正在运行:处理器当前正在运行。 -
 已停止:处理器有效并已启用但未运行。
已停止:处理器有效并已启用但未运行。 -
 无效:处理器已启用但当前无效且无法启动。将鼠标悬停在此图标上将提供工具提示,指示处理器无效的原因。一般情况下是需要我们完成必须的配置
无效:处理器已启用但当前无效且无法启动。将鼠标悬停在此图标上将提供工具提示,指示处理器无效的原因。一般情况下是需要我们完成必须的配置 -
 已禁用:处理器未运行,在启用之前无法启动。此状态不表示处理器是否有效。
已禁用:处理器未运行,在启用之前无法启动。此状态不表示处理器是否有效。
-
-
名称:这是处理器的用户定义名称。默认情况下组件的名称与它的Type相同。在示例中,此值为"ExecuteGroovyScript",是一个专门用于执行Groovy脚本的组件。
-
任务:此处理器当前正在执行的任务数。此数字受处理器配置对话框的计划选项卡中的并发任务设置的约束。在这里,我们可以看到处理器当前正在执行一项任务。如果NiFi实例是集群的,则此值表示当前正在集群中的所有节点上执行的任务数。
- 实时日志:这里是用于监控当前处理器状态的,当处理器内部出现问题,一般会在此处显示错误日志
- 数据流入流出看板:这里主要是展示处理数据过程中数据的流入流出情况,Nifi默认是5分钟更新一次页面上的看板情况,当然用户也可以在画布空白处,鼠标右键选择刷新,以达到实时查看的效果。
-
-
In:处理器从其传入处理器的队列中提取的数据量。此值表示为count size,其中count是从队列中提取的FlowFiles的数量,size是这些FlowFiles内容的总大小
-
Read/Write:处理器从磁盘读取并写入磁盘的FlowFile内容的总大小。这提供了有关此处理器所需的I/O性能的有用信息。某些处理器可能只读取数据而不写入任何内容,而某些处理器不会读取数据但只会写入数据。其他可能既不会读取也不会写入数据,而某些处理器会读取和写入数据。
-
Out:处理器已传输到其出站连接的数据量。这不包括处理器自行删除的FlowFiles,也不包括路由到自动终止的连接的FlowFiles。与上面的"In"指标一样,此值表示为count size,其中count是已转移到出站Connections的FlowFiles的数量,size是这些FlowFiles内容的总大小。
-
Tasks/Time:此处理器在过去5分钟内被触发运行的次数,以及执行这些任务所花费的时间。时间格式为hour:minute:second。请注意,所花费的时间可能超过五分钟,因为许多任务可以并行执行。例如,如果处理器计划运行60个并发任务,并且每个任务都需要一秒钟才能完成,则所有60个任务可能会在一秒钟内完成。但是,在这种情况下,我们会看到时间指标显示它需要60秒,而不是1秒。
-
组件配置
Nifi的处理器,一般都有四个标签页,分别是SETTINGS,SCHEDULING,PROPERITIES,COMMENTS
除了PROPERITIES之外,另外三个几乎是通用的,这里主要说一下这三个实用的。
SETTINGS(通用配置)
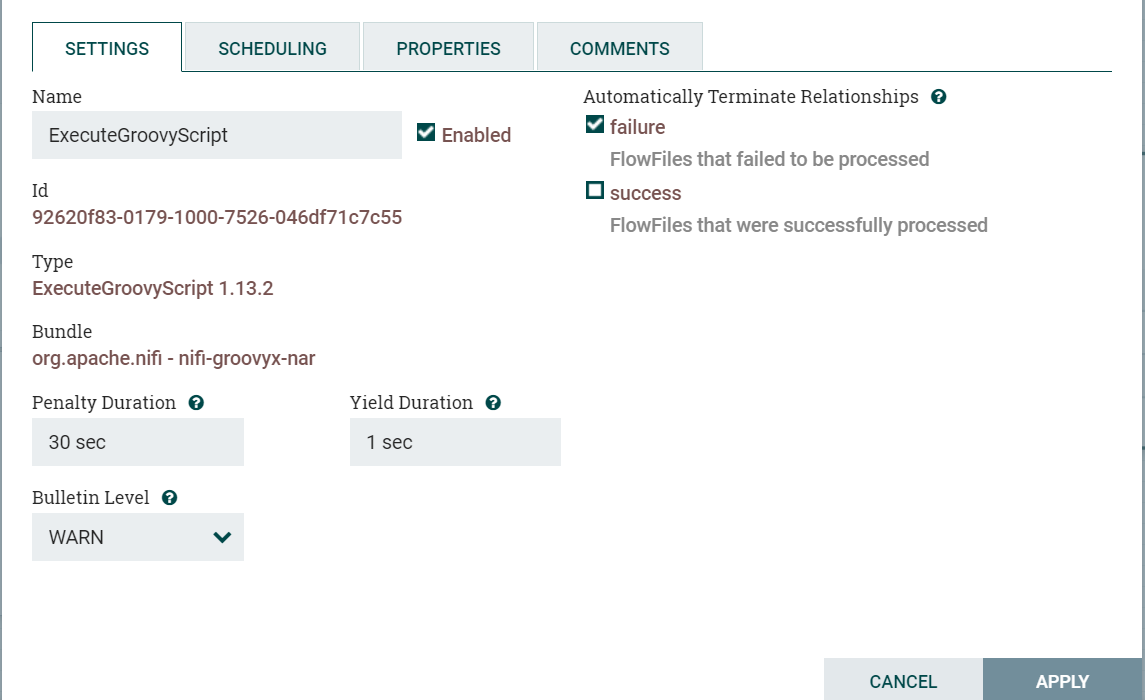
基本的Name这里就不说了,就是用户自定义的名称,Id、Type、Bundle这三个是这个处理器组件所属的代码包等基本信息,这里也不过多介绍,Enable这个选项,就是控制组件由启用到禁用 状态的切换。
最右边包含自动终止关系(Automatically Terminate Relationships)部分。此处列出了处理器定义的每个关系及其描述。为了使处理器被视为有效且能够运行,处理器定义的每个关系必须连接到下游组件或自动终止。我们可以通过选中它,例如图中选中Failure一样,来表示我们弃用这个输出,也就是不需要它指向下一个组件,这样这个处理器就变成只有一个对外输出数据的Relationship了。
接下来是两个用于配置Penalty Duration和Yield Duration的对话框。在处理一条数据(FlowFile)的正常过程中,可能发生事件,该事件指示处理器此时不能处理数据但是数据可以在稍后进行处理。在发生这种情况时,处理器可以选择Penalize FlowFile。这将阻止FlowFile在一段时间内被处理。例如,如果处理器要将数据推送到远程服务,但远程服务已经有一个与处理器指定的文件名同名的文件,则处理器可能会惩罚FlowFile。Penalty Duration允许DFM指定FlowFile应该受到多长时间的惩罚。默认值为30 seconds。(简单理解为推后一段时间再处理),类似的处理器可以确定存在某种情况,处理器没法进行处理数据。例如,如果处理器要将数据推送到远程服务并且该服务没有响应。这样的话处理器应该Yield,这将阻止处理器运行一段时间。通过设置Yield Duration来指定该时间段。默认值为1 second。
最下方Bulletin Level可以简单的理解为组件的日志输出等级的选择,有选择地进行日志等级输出
SCHEDULING(处理器调度)
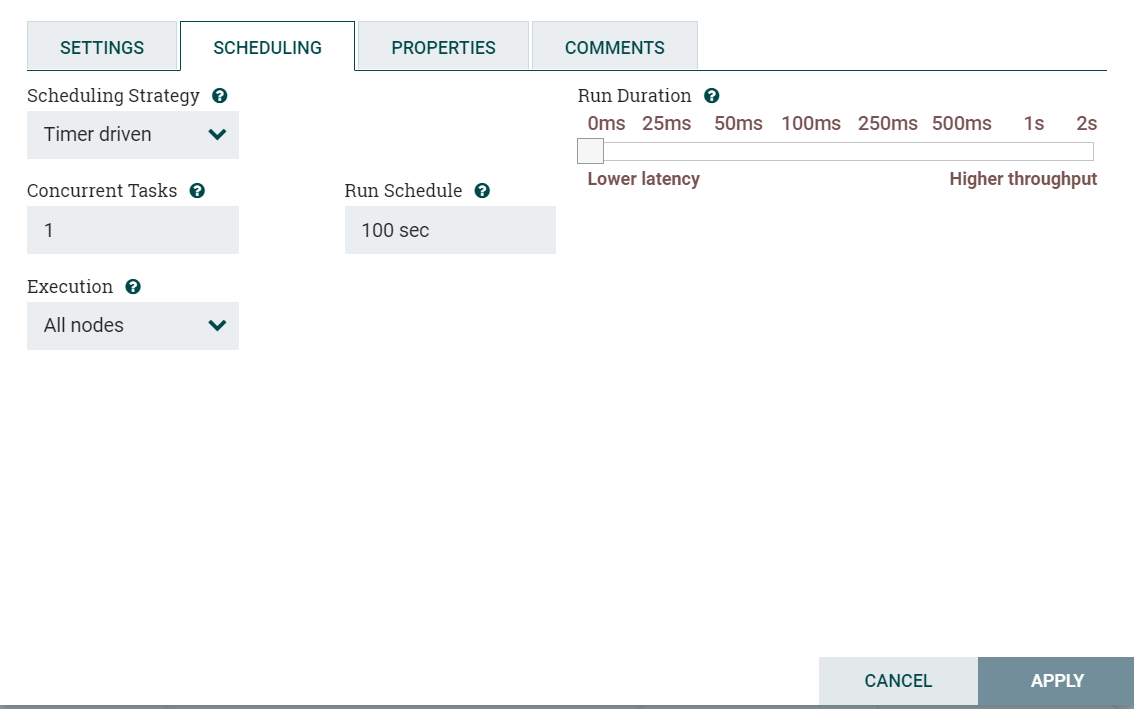
这一标签页,代表的就是如何驱动处理器,或者说处理器的运作方式:
第一个配置选项是调度策略(Scheduling Strategy)。调度有三种可能的选项:
- Timer driven:这是默认模式。处理器将定期运行。即多久运行一次,运行处理器的时间间隔由Run Schedule选项定义(当Run Schedule为0时,则代表瞬时执行)。
- Event driven:选择此模式时,将由一个事件触发处理器运行,当FlowFiles进入连接此处理器的Connections时,将产生这个事件。此模式目前被认为是实验性的,并非所有处理器都支持。选择此模式时,Run Schedule选项不可配置。此外,只有此模式下Concurrent Tasks选项可以设置为0。这种情况,线程数仅受管理员配置的事件驱动线程池的大小限制。
- CRON驱动:这是定时执行模式,即通过cron表达式,进行定时运行的控制。
下面的配置就是线程的分配(Concurrent Tasks):这可以控制处理器将使用的线程数。换句话说,它控制此处理器应同时处理多少个FlowFiles。增加此值通常会使处理器在相同的时间内处理更多数据。但是,它是通过使用其他处理器无法使用的系统资源来实现此目的。这基本上提供了处理器的相对权重 - 应该将多少系统资源分配给此处理器而不是其他处理器。该字段适用于大多数处理器。但是,某些类型的处理器只能使用单个任务进行调度。
关于Execution,执行设置用于确定处理器将被调度执行的节点。选择"All Nodes"将导致在集群中的每个节点上调度此处理器。选择"Primary Node"将导致此处理器仅在主节点上进行调度。一般单节点的情况下,我们都使用Primary Node
"Run Duration"选项卡的右侧包含一个用于选择运行持续时间的滑块。这可以控制处理器每次触发时应安排运行的时间。在滑块的左侧,标记为"Lower latency(较低延迟)",而右侧标记为"Higher throughput(较高吞吐量)"。处理器完成运行后,必须更新存储库才能将FlowFiles传输到下一个Connection。更新存储库的成本很高,因此在更新存储库之前可以立即完成的工作量越多,处理器可以处理的工作量就越多(吞吐量越高)。这意味着在上一批数据处理更新此存储库之前,Processor是无法开始处理接下来的FlowFiles。结果是,延迟时间会更长(从开始到结束处理FlowFile所需的时间会更长)。因此,滑块提供了一个频谱,DFM可以从中选择支持较低延迟或较高吞吐量。
COMMENTS(备注区)
这块把它称之为”备注区“,即用来为用户提供一个区域,以包含适用于此组件的任何注释。
PROPERITIES(属性区)
这一标签页差别较大,一般不同的组件所需要的配置各不相同,具体如果想了解对应组件的属性配置可以参考官网文档:http://nifi.apache.org/docs.html
队列管道操作
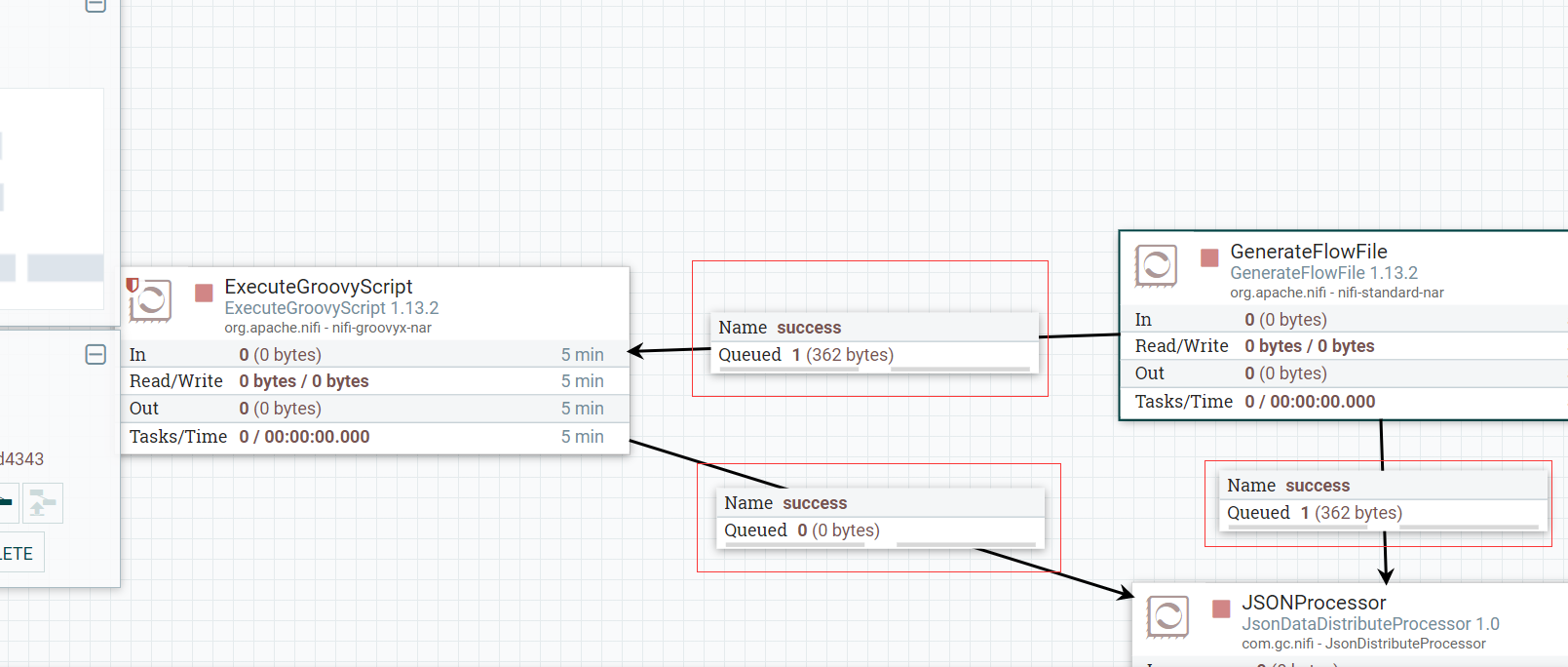
对于队列管道,它即是数据从一个处理器流向另一个处理器的中间队列,最多的用处就是用来监控数据是否正常流通,以及在开发使用过程中,可能调试定位问题等需要查看一下管道的数据,这里主要从管道的来源、手动清空、查看数据、设置超时清空、删除来描述一下对于管道队列
管道的来源:
管道的建立十分简单,两个组件进行一下拖拉连线即可,管道建立后,就需要选择前置处理器选用哪个Relationship输出的数据作为管道的源头,也就是上面配置项那里的Relationship。
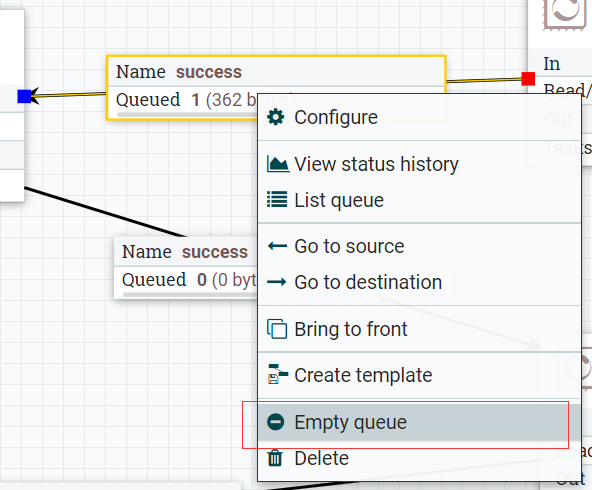
手动清空管道:
管道内的数据承载是有限的,有些时候(阻塞或者需要删除组件)需要进行手动清空管道的数据,操作方式是:选中管道,右键会出现:
查看数据
查看管道中的数据可以选中管道,右键后的 List queue选项
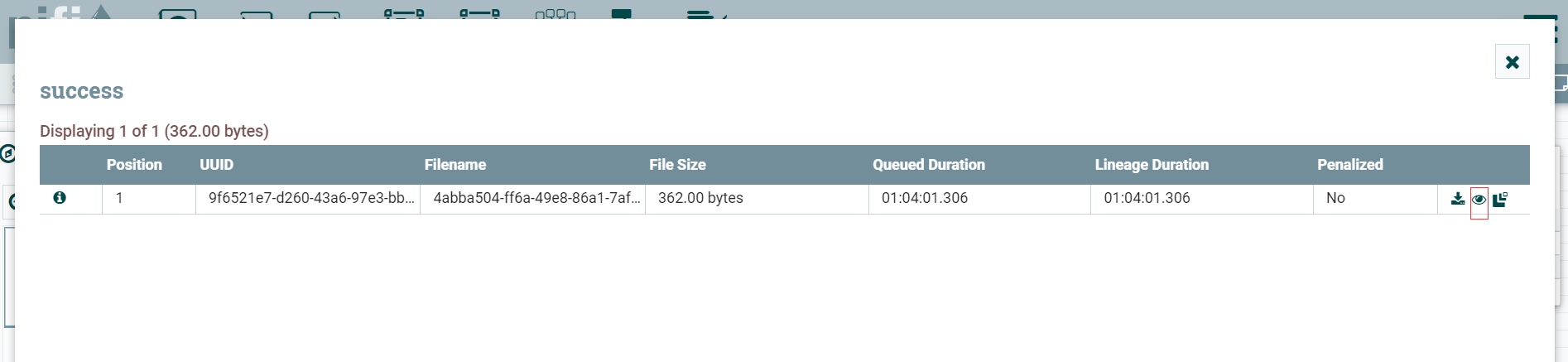
同时还可对数据进行下载等操作
设置超时清空
当有些组件处理速度过慢,导致阻塞(允许数据丢失的情况下),我们不能挨个进行手动的清空,这时候可以 在管道的 右键 configure 选项中进入管道的配置页面

在FlowFile Expiration进行超时自动清空的设置,默认为0是不做自动清空
删除
一般删除处理器之前,是需要断开所有与其关联的管道,即删除管道,删除时如果管道中有数据,需要手动制空后,选则 Delete。