第1章 NiFi概述
1.1 NiFi是什么
简单的说,NiFi就是为了解决不同系统间数据自动流通问题而建立的。虽然dataflow这个术语在各种场景都有被使用,但我们在这里使用它来表示不同系统间的自动化的可管理的信息流。自企业拥有多个系统开始,一些系统会有数据生成,一些系统要消费数据,而不同系统之间数据的流通问题就出现了。这些问题出现的相应的解决方案已经被广泛的研究和讨论,其中企业集成就是一个全面且易于使用的方案。
NiFi旨在帮助解决这些现代数据流挑战,其中主要的是复杂的范围,需要适应的需求变化的速度以及大规模边缘情况的普遍化。
1.2 NiFi核心概念
| NiFi术语 | FBP Term | 描述 |
| FlowFile | Information Packet | FlowFile表示在系统中移动的每个对象,对于每个FlowFile,NIFI都会记录它一个属性键值对和0个或多个字节内容(FlowFile有attribute和content)。 |
| FlowFile Processor | Black Box | 实际上是处理器起主要作用。在eip术语中,处理器就是不同系统间的数据路由,数据转换或者数据中介的组合。处理器可以访问给定FlowFile的属性及其内容。处理器可以对给定工作单元中的零或多个流文件进行操作,并提交该工作或回滚该工作。 |
| Connection | Bounded Buffer | Connections用来连接处理器。它们充当队列并允许各种进程以不同的速率进行交互。这些队列可以动态地对进行优先级排序,并且可以在负载上设置上限,从而启用背压。 |
| Flow Controller | Scheduler | 流控制器维护流程如何连接,并管理和分配所有流程使用的线程。流控制器充当代理,促进处理器之间流文件的交换。 |
| Process Group | subnet | 进程组里是一组特定的流程和连接,可以通过输入端口接收数据并通过输出端口发送数据,这样我们在进程组里简单地组合组件,就可以得到一个全新功能的组件(Process Group)。 |
1.3 NiFi架构
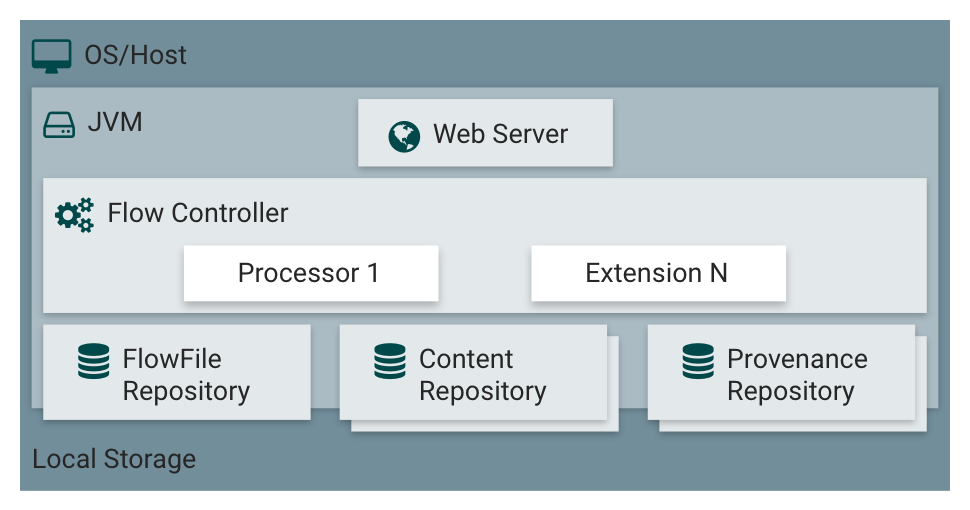
NiFi在操作系统上的JVM内执行。JVM上NiFi的主要组件如下:
| 组件名称 | 描述 |
| Web Server | web服务器的目的是承载NiFi基于http的命令和控制API |
| Flow Controller | 是整个操作的核心,为将要运行的组件提供线程,管理调度 |
| Extensions | 有各种类型的NIFI扩展,这些扩展在其他文档中进行了描述。这里的关键点是NIFI扩展在JVM中操作和执行 |
| FlowFile Repository | 对于给定一个流中正在活动的FlowFile,FlowFile Repository就是NIFI保持跟踪这个FlowFIle状态的地方。FlowFile Repository的实现是可插拔的(多种选择,可配置,甚至可以自己实现),默认实现是使用Write-Ahead Log技术(简单普及下,WAL的核心思想是:在数据写入库之前,先写入到日志.再将日志记录变更到存储器中。)写到指定磁盘目录 |
| Content Repository | Content Repository是给定FlowFile的实际内容字节存储的地方。Content Repository的实现是可插拔的。默认方法是一种相当简单的机制,它将数据块存储在文件系统中。可以指定多个文件系统存储位置,以便获得不同的物理分区以减少任何单个卷上的争用。(所以环境最佳实践时可配置多个目录,挂载不同磁盘,提高IO) |
| Provenance Repository | Provenance Repository是存储所有事件数据的地方。Provenance Repository的实现是可插拔的,默认实现是使用一个或多个物理磁盘卷。在每个位置内的事件数据都是被索引并可搜索的 |
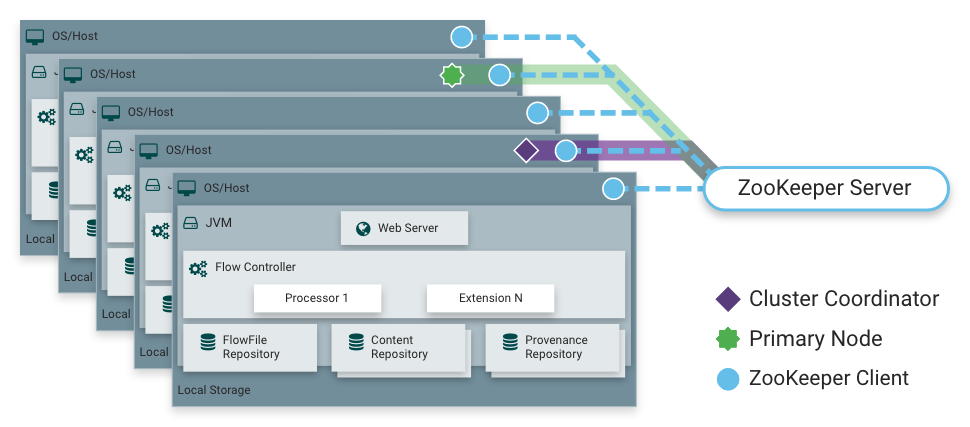
NiFi也能够在集群内运行,NIFI集群采用了Zero-Master Clustering模式。NiFi群集中的每个节点对数据执行相同的任务,但每个节点都在不同的数据集上运行。Apache ZooKeeper选择单个节点作为集群协调器,ZooKeeper自动处理故障转移。所有集群节点都会向集群协调器发送心跳报告和状态信息。集群协调器负责断开和连接节点。此外,每个集群都有一个主节点,主节点也是由ZooKeeper选举产生。我们可以通过任何节点的用户界面(UI)与NiFi群集进行交互,并且我们所做的任何更改都将复制到集群中的所有节点上。
第2章 NiFi安装
2.1 单机模式
2.1.1 Linux系统安装
下载地址:http://nifi.apache.org/download.html
解压:tar -zxf /apps/software/nifi-1.9.2-bin.tar.gz -C /apps/nifi
默认web界面端口是8080,如若冲突需要修改配置文件conf/nifi.properties
nifi.web.http.port=8080
启动/关闭:nifi.sh start/stop
访问web页面地址: http://[hostname]:8080/nifi
2.2 集群安装
2.2.1 集群概念
零主集群
NiFi采用Zero-Master Clustering范例。集群中的每个节点都对数据执行相同的任务,但每个节点都在不同的数据集上运行。其中一个节点自动选择(通过Apache ZooKeeper)作为集群协调器。然后,集群中的所有节点都会向此节点发送心跳/状态信息,并且此节点负责断开在一段时间内未报告任何心跳状态的节点。此外,当新节点选择加入集群时,新节点必须首先连接到当前选定的集群协调器,以获取最新的流。如果集群协调器确定允许该节点加入(基于其配置的防火墙文件),则将当前流提供给该节点,并且该节点能够加入集群,假设节点的流副本与集群协调器提供的副本匹配。如果节点的流配置版本与集群协调器的版本不同,则该节点将不会加入集群。
为什么集群?
NiFi管理员或DataFlow管理器(DFM)可能会发现在单个服务器上使用一个NiFi实例不足以处理他们拥有的数据量。因此,一种解决方案是在多个NiFi服务器上运行相同的数据流。但是,这会产生管理问题,因为每次DFM想要更改或更新数据流时,他们必须在每个服务器上进行这些更改,然后单独监视每个服务器。通过集群NiFi服务器,可以增加处理能力以及单个接口,通过该接口可以更改数据流并监控数据流。集群允许DFM仅进行一次更改,然后将更改复制到集群的所有节点。通过单一接口,DFM还可以监视所有节点的健康状况和状态。
集群内的通信
如上所述,节点通过心跳与集群协调器通信。当选择集群协调器时,它会使用其连接信息更新Apache ZooKeeper中众所周知的ZNode,以便节点了解发送心跳的位置。如果其中一个节点发生故障,则集群中的其他节点将不会自动获取丢失节点的负载。DFM可以配置故障转移意外事件的数据流; 但是,这取决于数据流设计,并不会自动发生。
当DFM对数据流进行更改时,接收更改流的请求的节点会将这些更改传递给所有节点,并等待每个节点响应,表明它已对其本地流进行了更改。
2.2.2 集群术语
NiFi集群协调器(NiFi Cluster Coordinator):NiFi集群协调器是NiFi集群中的节点,负责执行任务以管理集群中允许的节点,并为新加入的节点提供最新的流量。当DataFlow Manager管理集群中的数据流时,他们可以通过集群中任何节点的用户界面执行此操作。然后,所做的任何更改都将复制到集群中的所有节点。
节点(Nodes):每个集群由一个或多个节点组成。节点执行实际的数据处理。
主节点(Primary Node):每个集群都有一个主节点。在此节点上,可以运行"隔离处理器"(见下文)。ZooKeeper用于自动选择主节点。如果该节点由于任何原因断开与集群的连接,将自动选择新的主节点。用户可以通过查看用户界面的"集群管理"页面来确定当前选择哪个节点作为主节点。
孤立的处理器:在NiFi集群中,相同的数据流在所有节点上运行。因此,流中的每个组件都在每个节点上运行。但是,可能存在DFM不希望每个处理器在每个节点上运行的情况。最常见的情况是使用的处理器使用不能很好扩展的协议与外部服务进行通信。例如,GetSFTP处理器从远程目录中提取。如果GetSFTP处理器在集群中的每个节点上运行并同时尝试从同一个远程目录中提取,则可能存在竞争条件。因此,DFM可以将主节点上的GetSFTP配置为独立运行,这意味着它仅在该节点上运行。通过适当的数据流配置,它可以提取数据并在集群中的其余节点之间对其进行负载平衡。请注意,虽然存在此功能,但仅使用独立的NiFi实例来提取数据并将其提供给集群也很常见。它仅取决于可用资源以及管理员决定配置集群的方式。
心跳:节点通过"心跳"将其健康状况和状态传达给当前选定的集群协调器,这使协调器知道它们仍然连接到集群并正常工作。默认情况下,节点每5秒发出一次心跳,如果集群协调器在40秒内没有从节点收到心跳,则由于"缺乏心跳"而断开节点。5秒设置可在_nifi.properties_文件中配置(请参阅集群公共属性)部分了解更多信息)。集群协调器断开节点的原因是协调器需要确保集群中的每个节点都处于同步状态,并且如果没有定期听到节点,协调器无法确定它是否仍与其余节点同步集群。如果在40秒后节点发送新的心跳,协调器将自动请求节点重新加入集群,以包括重新验证节点的流。一旦接收到心跳,由于心跳不足导致的断开连接和重新连接都会报告给用户界面中的DFM。
2.2.2 配置集群
需要Zookeeper环境,zk部署方式略,另外NiFi集群部署可以使用外部zk环境或者内部嵌套zk环境,这里使用外部zk环境部署,NiFi1.10版本以上zk指定为3.5版本
将三台节点都下载解压nifi的安装包:
解压:tar -zxf /apps/software/nifi-1.9.2-bin.tar.gz -C /apps/nifi
修改配置文件conf/nifi.properties以下属性:
nifi.web.http.host=[hostname]
nifi.web.http.port=58080 (web界面端口默认是8080)
nifi.cluster.is.node=true
nifi.cluster.node.address=[hostname] (每台节点的主机名)
nifi.cluster.node.protocol.port=58081 (将其设置为高于1024的开放端口)
nifi.cluster.flow.election.max.wait.time=1 mins (选择流等待的时间量)
nifi.cluster.flow.election.max.candidates=1 (指定群集中所需的节点数)
nifi.zookeeper.connect.string=[hostname]:2181, [hostname]:2181, [hostname]:2181 (zookeeper的地址)
编辑conf/state-management.xml文件,内容如下:
<cluster-provider>
<id>zk-provider</id> <class>org.apache.nifi.controller.state.providers.zookeeper.ZooKeeperStateProvider</class>
<property name="Connect String">[hostname]:2181, [hostname]:2181, [hostname]:2181</property>
<property name="Root Node">/nifi</property>
<property name="Session Timeout">10 seconds</property>
<property name="Access Control">Open</property>
</cluster-provider>
编辑conf/logback.xml文件以下属性将日志记录级别更改为DEBUG:
<logger name="org.apache.nifi.web.api.config" level="INFO" additivity="false">
三台都启动nifi:nifi.sh start
2.3 安全配置
通过HTTPS而不是HTTP来访问用户界面:
修改配置文件conf/nifi.properties以下属性:
nifi.web.http.port:使该行变为nifi.web.http.port=
nifi.web.https.host:设为运行Nifi的主机名字
nifi.web.https.port:用58080 作为https端口
nifi.security.keystore=/apps/nifi/nifi-1.9.2/secrets/keystore.jks
nifi.security.keystoreType=JKS
nifi.security.keystorePasswd=DD01@admin
nifi.security.truststore=/apps/nifi/nifi-1.9.2/secrets/truststore.jks
nifi.security.truststoreType=JKS
nifi.security.truststorePasswd=DD01@admin
nifi.remote.input.secure=true (Nifi之间的Site-to-Site通信也用加密的方式)
如若nifi是集群还需配置: nifi.cluster.protocol.is.secure=true
2.3.1 生成证书
生成Keystore:
keytool -genkey -keyalg RSA -alias nifi -keystore keystore.jks -keypass [password] -storepass [password] -validity 365 -keysize 4096 -dname "CN=[hostname], OU=nifi"
其中,替换[password]为想设置的密码,替换[hostname]为运行Nifi的机器的hostname
生成PKCS12文件以及对应的Truststore:
keytool -genkey -keyalg RSA -alias client -keystore client_keystore.jks -keypass [password] -storepass [password] -validity 365 -keysize 4096 -dname "CN=[user], OU=nifi"
随便设置了一个密码[password],因为这个Keystore只是一个过渡的产物,最后不会用到,设置[user]
把这个keystore转化成PKCS12文件:
keytool -importkeystore -srckeystore client_keystore.jks -destkeystore client.p12 -srcstoretype JKS -deststoretype PKCS12 -srcstorepass [password] -deststorepass [client_password] -destkeypass [client_password] -srcalias client -destalias client
替换[client_password]为你想为PKCS12文件设置的密码,设置[password]
生成一个信任PKCS12密匙文件中的证书的truststore:
keytool -export -keystore client_keystore.jks -alias client -file client.der -storepass [password]
设置了一个密码[password]
证书引入到truststore.jks当中
keytool -import -file client.der -alias client -keystore truststore.jks -storepass [truststore_password] -noprompt
替换[truststore_password]为你想为truststore设置的密码
访问Nifi UI,你必须先把生成的PKCS12文件导入到浏览器中。以Chrome为例,先进入设置 => 高级,找到 证书管理一项,将client.p12导入进去 (可以不操作)
2.4 用户认证
NiFi支持通过客户端证书,用户名/密码,Apache Knox或OpenId Connect进行用户身份验证, 用户名/密码的验证是由Login Identity Provider执行的,Login Identity Provider是一种可插拔的机制。要在 nifi.properties 文件中配置要使用的Login Identity Provider。目前,NiFi为轻量级目录访问协议(LDAP)和Kerberos提供了带有用户名/密码登陆的Login Identity Provider
以下是配置与Kerberos密钥分发中心(KDC)集成以验证用户身份的登录身份:
Kerberos安装部署(略)
修改nifi.properties文件属性:
nifi.security.user.login.identity.provider=kerberos-provider
修改 login-identity-providers.xml 以启用kerberos-provider:
<provider>
<identifier>kerberos-provider</identifier>
<class>org.apache.nifi.kerberos.KerberosProvider</class>
<property name="Default Realm">DD01.COM</property>
<property name="Authentication Expiration">12 hours</property>
</provider>
2.5 多租户授权
将NiFi配置为安全运行并具有身份验证机制后,必须配置谁有权访问系统以及他们的访问级别。可以使用多租户授权来执行此操作。多租户授权使多组用户(租户)可以使用不同的授权级别来命令,控制和观察数据流的不同部分。当通过身份验证的用户尝试查看或修改NiFi资源时,系统会检查该用户是否具有执行该操作的特权。这些特权由可以在系统范围或单个组件中应用的策略定义。
编辑authorizers.xml 文件:
<userGroupProvider>
<identifier>file-user-group-provider</identifier>
<class>org.apache.nifi.authorization.FileUserGroupProvider</class>
<property name="Users File">./conf/users.xml</property>
<property name="Legacy Authorized Users File"></property>
<property name="Initial User Identity 1">nifi@DD01.COM</property>
</userGroupProvider>
<accessPolicyProvider>
<identifier>file-access-policy-provider</identifier>
<class>org.apache.nifi.authorization.FileAccessPolicyProvider</class>
<property name="User Group Provider">file-user-group-provider</property>
<property name="Authorizations File">./conf/authorizations.xml</property>
<property name="Initial Admin Identity">nifi@DD01.COM</property>
<property name="Legacy Authorized Users File"></property>
<property name="Node Identity 1"></property>
</accessPolicyProvider>
2.5.1 全局访问政策授权
| Policy | Privilege | Global Menu Selection | Resource Descriptor |
| view the UI | 允许用户查看UI | N/A | /flow |
| access the controller | 允许用户查看/修改控制器,包括报告任务,控制器服务,参数上下文和集群中的节点 | Controller Settings | /controller |
| access parameter contexts | 允许用户查看/修改参数上下文。除非被覆盖,否则对参数上下文的访问将从“access the controller”策略继承。 | Parameter Contexts | /parameter-contexts |
| query provenance | 允许用户提交Provenance Search和请求血缘关系 | Data Provenance | /provenance |
| access restricted components | 假设其他权限就足够了,允许用户创建/修改受限组件。受限组件可以指示需要哪些特定权限。可以授予特定限制的权限,也可以不受限制地授予权限。如果无论限制如何都授予许可,则用户可以创建/修改所有受限制的组件。 | N/A | /restricted-components |
| access all policies | 允许用户查看/修改所有组件的策略 | Policies | /policies |
| access users/user groups | 允许用户查看/修改用户和用户组 | Users | /tenants |
| retrieve site-to-site details | 允许其他NiFi实例检索站点到站点详细信息 | N/A | /site-to-site |
| view system diagnostics | 允许用户查看系统诊断 | Summary | /system |
| proxy user requests | 允许代理计算机代表他人发送请求 | N/A | /proxy |
| access counters | 允许用户查看/修改计数器 | Counters | /counters |
第3章 处理器
3.1 数据转换
- CompressContent:压缩或解压
- ConvertCharacterSet:将用于编码内容的字符集从一个字符集转换为另一个字符集
- EncryptContent:加密或解密
- ReplaceText:使用正则表达式修改文本内容
- TransformXml:应用XSLT转换XML内容
- JoltTransformJSON:应用JOLT规范来转换JSON内容
3.2 路由和调解
- ControlRate:限制流程中数据流经某部分的速率
- DetectDuplicate:根据一些用户定义的标准去监视发现重复的FlowFiles。通常与HashContent一起使用
- DistributeLoad:通过只将一部分数据分发给每个用户定义的关系来实现负载平衡或数据抽样
- MonitorActivity:当用户定义的时间段过去而没有任何数据流经此节点时发送通知。(可选)在数据流恢复时发送通知。
- RouteOnAttribute:根据FlowFile包含的属性路由FlowFile。
- ScanAttribute:扫描FlowFile上用户定义的属性集,检查是否有任何属性与用户定义的字典匹配。
- RouteOnContent:根据FlowFile的内容是否与用户自定义的正则表达式匹配。如果匹配,则FlowFile将路由到已配置的关系。
- ScanContent:在流文件的内容中搜索用户定义字典中存在的术语,并根据这些术语的存在或不存在来路由。字典可以由文本条目或二进制条目组成。。
- ValidateXml:以XML模式验证XML内容; 根据用户定义的XML Schema,判断FlowFile的内容是否有效,进而来路由FlowFile。
3.3 数据库访问
- ConvertJSONToSQL:将JSON文档转换为SQL INSERT或UPDATE命令,然后可以将其传递给PutSQL Processor
- ExecuteSQL:执行用户定义的SQL SELECT命令,结果为Avro格式的FlowFile
- PutSQL:通过执行FlowFile内容定义的SQL DDM语句来更新数据库
- SelectHiveQL:对Apache Hive数据库执行用户定义的HiveQL SELECT命令,结果为Avro或CSV格式的FlowFile
- PutHiveQL:通过执行FlowFile内容定义的HiveQL DDM语句来更新Hive数据库
3.4 属性提取
- EvaluateJsonPath:用户提供JSONPath表达式(类似于XPath,用于XML解析/提取),然后根据JSON内容评估这些表达式,用结果值替换FlowFile内容或将结果值提取到用户自己命名的Attribute中。
- EvaluateXPath:用户提供XPath表达式,然后根据XML内容评估这些表达式,用结果值替换FlowFile内容或将结果值提取到用户自己命名的Attribute中。
- EvaluateXQuery:用户提供XQuery查询,然后根据XML内容评估此查询,用结果值替换FlowFile内容或将结果值提取到用户自己命名的Attribute中。
- ExtractText:用户提供一个或多个正则表达式,然后根据FlowFile的文本内容对其进行评估,然后将结果值提取到用户自己命名的Attribute中。
- HashAttribute:对用户定义的现有属性列表的串联进行hash。
- HashContent:对FlowFile的内容进行hash,并将得到的hash值添加到Attribute中。
- IdentifyMimeType:评估FlowFile的内容,以确定FlowFile封装的文件类型。此处理器能够检测许多不同的MIME类型,例如图像,文字处理器文档,文本和压缩格式,仅举几例。
- UpdateAttribute:向FlowFile添加或更新任意数量的用户定义的属性。这对于添加静态的属性值以及使用表达式语言动态计算出来的属性值非常有用。该处理器还提供"高级用户界面(Advanced User Interface)",允许用户根据用户提供的规则有条件地去更新属性
3.5 系统交互
- ExecuteProcess:运行用户自定义的操作系统命令。进程的StdOut被重定向,以便StdOut的内容输出为FlowFile的内容。此处理器是源处理器(不接受数据流输入,没有上游组件) - 其输出预计会生成新的FlowFile,并且系统调用不会接收任何输入。如果要为进程提供输入,请使用ExecuteStreamCommand Processor。
- ExecuteStreamCommand:运行用户定义的操作系统命令。FlowFile的内容可选地流式传输到进程的StdIn。StdOut的内容输出为FlowFile的内容。此处理器不能用作源处理器 - 必须传入FlowFiles才能执行。要使用源处理器执行相同类型的功能,请参阅ExecuteProcess Processor
3.6 数据提取
- GetFile:将文件内容从本地磁盘(或网络连接的磁盘)流式传输到NiFi,然后删除原始文件。此处理器应将文件从一个位置移动到另一个位置,而不是用于复制数据。
- GetFTP:通过FTP将远程文件的内容下载到NiFi中,然后删除原始文件。此处理器应将文件从一个位置移动到另一个位置,而不是用于复制数据。
- GetSFTP:通过SFTP将远程文件的内容下载到NiFi中,然后删除原始文件。此处理器应将文件从一个位置移动到另一个位置,而不是用于复制数据。
- GetJMSQueue:从JMS队列下载消息,并根据JMS消息的内容创建FlowFile。可选地,JMS属性也可以作为属性复制。
- GetJMSTopic:从JMS主题下载消息,并根据JMS消息的内容创建FlowFile。可选地,JMS属性也可以作为属性复制。此处理器支持持久订阅和非持久订阅。
- GetHTTP:将基于HTTP或HTTPS的远程URL的请求内容下载到NiFi中。处理器将记住ETag和Last-Modified Date,以确保不会持续摄取数据。
- ListenHTTP:启动HTTP(或HTTPS)服务器并侦听传入连接。对于任何传入的POST请求,请求的内容将作为FlowFile写出,并返回200响应。
- ListenUDP:侦听传入的UDP数据包,并为每个数据包或每个数据包创建一个FlowFile(取决于配置),并将FlowFile发送到"success"。
- GetHDFS:监视HDFS中用户指定的目录。每当新文件进入HDFS时,它将被复制到NiFi并从HDFS中删除。此处理器应将文件从一个位置移动到另一个位置,而不是用于复制数据。如果在集群中运行,此处理器需仅在主节点上运行。要从HDFS复制数据并使其保持原状,或者从群集中的多个节点流式传输数据,请参阅ListHDFS处理器。
- ListHDFS / FetchHDFS:ListHDFS监视HDFS中用户指定的目录,并发出一个FlowFile,其中包含它遇到的每个文件的文件名。然后,它通过分布式缓存在整个NiFi集群中保持此状态。然后可以在集群中,将其发送到FetchHDFS处理器,后者获取这些文件的实际内容并发出包含从HDFS获取的内容的FlowFiles。
- FetchS3Object:从Amazon Web Services(AWS)简单存储服务(S3)获取对象的内容。输出的FlowFile包含从S3接收的内容。
- GetKafka:从Apache Kafka获取消息,特别是0.8.x版本。消息可以作为每个消息的FlowFile发出,也可以使用用户指定的分隔符一起进行批处理。
- GetMongo:对MongoDB执行用户指定的查询,并将内容写入新的FlowFile。
- GetTwitter:允许用户注册过滤器以收听Twitter"garden hose"或企业端点,为收到的每条推文创建一个FlowFile
3.7 数据出口/发送数据
- PutEmail:向配置的收件人发送电子邮件。FlowFile的内容可选择作为附件发送。
- PutFile:将FlowFile的内容写入本地(或网络连接)文件系统上的目录。
- PutFTP:将FlowFile的内容复制到远程FTP服务器。
- PutSFTP:将FlowFile的内容复制到远程SFTP服务器。
- PutJMS:将FlowFile的内容作为JMS消息发送到JMS代理,可选择将Attributes添加JMS属性。
- PutSQL:将FlowFile的内容作为SQL DDL语句(INSERT,UPDATE或DELETE)执行。FlowFile的内容必须是有效的SQL语句。属性可以用作参数,FlowFile的内容可以是参数化的SQL语句,以避免SQL注入攻击。
- PutKafka:将FlowFile的内容作为消息发送到Apache Kafka,特别是0.8.x版本。FlowFile可以作为单个消息或分隔符发送,例如可以指定换行符,以便为单个FlowFile发送许多消息。
- PutMongo:将FlowFile的内容作为INSERT或UPDATE发送到Mongo。
3.8 分裂和聚合
- SplitText:SplitText接收单个FlowFile,其内容为文本,并根据配置的行数将其拆分为1个或多个FlowFiles。例如,可以将处理器配置为将FlowFile拆分为多个FlowFile,每个FlowFile只有一行。
- SplitJson:允许用户将包含数组或许多子对象的JSON对象拆分为每个JSON元素的FlowFile。
- SplitXml:允许用户将XML消息拆分为多个FlowFiles,每个FlowFiles包含原始段。这通常在多个XML元素与"wrapper"元素连接在一起时使用。然后,此处理器允许将这些元素拆分为单独的XML元素。
- UnpackContent:解压缩不同类型的存档格式,例如ZIP和TAR。然后,归档中的每个文件都作为单个FlowFile传输。
- MergeContent:此处理器负责将许多FlowFiles合并到一个FlowFile中。可以通过将其内容与可选的页眉,页脚和分界符连接在一起,或者通过指定存档格式(如ZIP或TAR)来合并FlowFiles。FlowFiles可以根据公共属性进行分箱(binned),或者如果这些流是被其他组件拆分的,则可以进行"碎片整理(defragmented)"。根据元素的数量或FlowFiles内容的总大小(每个bin的最小和最大大小是用户指定的)并且还可以配置可选的Timeout属性,即FlowFiles等待其bin变为配置的上限值最大时间。
- SegmentContent:根据某些已配置的数据大小将FlowFile划分为可能的许多较小的FlowFile。不对任何类型的分界符执行拆分,而是仅基于字节偏移执行拆分。这是在传输FlowFiles之前使用的,以便通过并行发送许多不同的部分来提供更低的延迟。而另一方面,MergeContent处理器可以使用碎片整理模式重新组装这些FlowFiles。
- SplitContent:将单个FlowFile拆分为可能的许多FlowFile,类似于SegmentContent。但是,对于SplitContent,不会在任意字节边界上执行拆分,而是指定要拆分内容的字节序列。
3.9 HTTP
- GetHTTP:将基于HTTP或HTTPS的远程URL的内容下载到NiFi中。处理器将记住ETag和Last-Modified Date,以确保不会持续摄取数据。
- ListenHTTP:启动HTTP(或HTTPS)服务器并侦听传入连接。对于任何传入的POST请求,请求的内容将作为FlowFile写出,并返回200响应。
- InvokeHTTP:执行用户配置的HTTP请求。此处理器比GetHTTP和PostHTTP更通用,但需要更多配置。此处理器不能用作源处理器,并且需要具有传入的FlowFiles才能被触发以执行其任务。
- PostHTTP:执行HTTP POST请求,将FlowFile的内容作为消息正文发送。这通常与ListenHTTP结合使用,以便在无法使用s2s的情况下在两个不同的NiFi实例之间传输数据(例如,节点无法直接访问并且能够通过HTTP进行通信时代理)。 注意:除了现有的RAW套接字传输之外,HTTP还可用作s2s传输协议。它还支持HTTP代理。建议使用HTTP s2s,因为它更具可扩展性,并且可以使用具有更好用户身份验证和授权的输入/输出端口的方式来提供双向数据传输。
- HandleHttpRequest / HandleHttpResponse:HandleHttpRequest Processor是一个源处理器,与ListenHTTP类似,启动嵌入式HTTP(S)服务器。但是,它不会向客户端发送响应(比如200响应)。相反,流文件是以HTTP请求的主体作为其内容发送的,所有典型servlet参数、头文件等的属性作为属性。然后,HandleHttpResponse能够在FlowFile完成处理后将响应发送回客户端。这些处理器总是彼此结合使用,并允许用户在NiFi中可视化地创建Web服务。这对于将前端添加到非基于Web的协议或围绕已经由NiFi执行的某些功能(例如数据格式转换)添加简单的Web服务特别有用
3.10 亚马逊网络服务
- FetchS3Object:获取存储在Amazon Simple Storage Service中的对象的内容(S3)。然后,从S3检索的内容将写入FlowFile的内容。
- PutS3Object:使用配置的凭据,密钥和存储桶名称将FlowFile的内容写入Amazon S3对象。
- PutSNS:将FlowFile的内容作为通知发送到Amazon Simple Notification Service(SNS)。
- GetSQS:从Amazon Simple Queuing Service(SQS)中提取消息,并将消息内容写入FlowFile的内容。
- PutSQS:将FlowFile的内容作为消息发送到Amazon Simple Queuing Service(SQS)。
- DeleteSQS:从Amazon Simple Queuing Service(SQS)中删除消息。这可以与GetSQS一起使用,以便从SQS接收消息,对其执行一些处理,然后仅在成功完成处理后才从队列中删除该对象。