粘包现象与解决粘包问题
一、引入
粘包问题主要出现在用TCP协议传输中才会出现的问题,UDP不会出现,因为TCP传输中他会服务端会一次性把所有东西一并丢入缓存区,而读取的内容大小有时候没法准确的做到一一读取,所有会存在粘包。
而UDP他传输的时候是吧一个个内容丢过去,不管客户端能否完全接受到内容他都会接受他制定大小的内容,而内容大于他接受设定的大小时候多余的东西会被丢到
注意:只有TCP才会出现粘包现象,
UDP永远不会出现粘包现象
一、粘包现象介绍
1.socket收发消息的原理
其实我们发送数据并不是直接发送给对方, 而是应用程序将数据发送到本机操作系统的缓存里边, 当数据量小, 发送的时间间隔短, 操作系统就会在缓存区先攒够一个TCP段再通过网卡一起发送, 接收数据也是一样的, 先在操作系统的缓存存着, 然后应用程序再从操作系统中取出数据
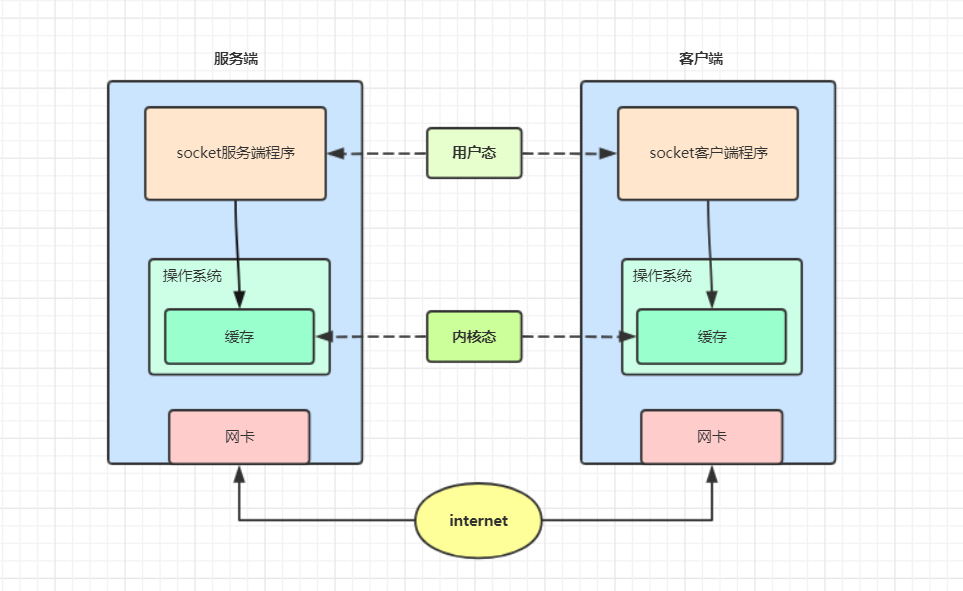
1.1缓冲区的作用:存储少量数据
- 如果你的网络出现短暂的异常或波动,接受数据就会出现短暂的中断,影响你的下载或者上传的效率,但是缓冲区解决了上传下载的传输效率的问题,带来了粘包问题
1.2收发的本质:不一定是一收一发
2.为什么产生黏包
-
主要原因 : TCP称为流失协议, 数据流会杂糅在一起, 接收端不清楚每个消息的界限, 不知道每次应该去多少字节的数据
-
次要原因 : TCP为了提高传输效率会有一个nagle优化算法, 当多次send的数据字节都非常少, nagle算法就会将这些数据合并成一个TCP段再发送, 这就无形中产生了黏包
3.什么是粘包?
- 接收方没有及时接收缓冲区的包,造成多个包接收(客户端发送了一段数据,服务端只收了一小部分,服务端下次再收的时候还是从缓冲区拿上次遗留的数据,产生粘包)
recv会产生黏包(如果recv接受的数据量(1024)小于发送的数据量,第一次只能接收规定的数据量1024,第二次接收剩余的数据量) - 发送端需要等缓冲区满才发送出去,造成粘包(发送数据时间间隔很短,数据也很小,会合到一起,产生粘包)send 也可能发生粘包现象。(连续send少量的数据发到输出缓冲区,由于缓冲区的机制,也可能在缓冲区中不断积压,多次写入的数据被一次性发送到网络)
4.产生黏包的两种情况 :
- 发送端需要等待缓冲区满了才将数据发送出去, 如果发送数据的时间间隔很短, 数据很小, 就会合到一起, 产生黏包
- 接收方没有及时接收缓冲区的包, 造成多个包一起接收, 如果服务端一次只接收了一小部分, 当服务端下次想接收新的数据的时候, 拿到的还是上次缓冲区里剩余的内容
注意:粘包不一定发生,如果发生了:
- 可能是在客户端已经粘了。
- 客户端没有粘,可能是在服务端粘了。
二、解决粘包问题的两种方式
1、通过send数据长度的方式来控制接收(low版)
粘包问题的根源在于,接收端不知道发送端将要传送的字节流的长度,所以解决粘包的方法就是围绕如何让发送端在发送数据前,把自己将要发送的字节流总大小让接收端知晓,然后接收端来一个死循环接收完所有数据。
- 服务端
from socket import *
import subprocessserver = socket(AF_INET,SOCK_STREAM)
server.bind(("127.0.0.1",8090))
server.listen(5)while True:print("等待连接...")conn,addr = server.accept()print(f"来自{addr}的连接")while True:try:cmd = conn.recv(1024)if not cmd:'''当你的程序运用在linux系统中,客户端强制断开链接,服务端会收到空的数据,在这种情况下就会退出与当前客户端的通讯循环,并关闭与该客户端的连接, 并回收当前客户端在服务端当前所占的系统资源,还有另一种情况就是客户端正常使用close()断开连接, 服务端也会收到空的数据,'''breakobj = subprocess.Popen(cmd.decode("utf-8"),shell=True,stdout=subprocess.PIPE,stderr=subprocess.PIPE,)stdout = obj.stdout.read()stderr = obj.stderr.read()date = stdout + stderrdate_len = str(len(date)).encode("utf-8") # 得到数据长度conn.send(date_len) # 将数据的长度先发送conn.send(date) # 再发送真实数据except Exception:'''这里解决的问题是:当你的程序运行在windows系统中,客户端强制断开链接,服务端就会引发异常. 因此,就可以使用异常处理机制来监测这种异常,此时一旦监测出这种异常,就代表客户端强制断开了链接.在这种情况下就会退出与当前客户端的通讯循环,并关闭与该客户端的连接, 并回收当前客户端在服务端当前所占的系统资源,'''breakconn.close()- 客户端
from socket import *client = socket(AF_INET,SOCK_STREAM)
client.connect(("127.0.0.1",8090))while True:cmd = input("请输入命令 >>").strip()if not cmd:# 这里解决的问题:"""当客户端输入为空的时候,在客户端的操作系统缓存中,并没有数据能发送给服务端. 硬件不能识别你这个空的数据,只有我们这种逻辑层面才有这种空的数据的存在.因此服务端的recv操作会在服务端的操作缓存中拿取数据,但是与此同时,服务端的操作系统缓存中并没有数据,于是服务端一直在recv堵塞状态.接着客户端因为send发送了数据,处于recv等待服务端发送回来的数据的状态,因而两者会处于一种recv堵塞的状态,"""continueclient.send(cmd.encode("utf-8"))"""粘包问题出现:问题1: 服务端发送回来的数据很多收不完,剩下的数据会保存在客户端的操作系统缓存中并不会丢失.问题2: 有可能服务端的数据过大,服务端并不是一次性的给你发送过来,可能分多次发送过来,所以这里接收的话可能接收的是部分.(这里是服务端的问题)"""date_len = int(client.recv(1024).decode("utf-8")) # 先接收数据长度recv_len = 0'''粘包问题出现的原因:1、TCP是流式协议,数据像流水一样黏在一起,没有任何边界区分2、收数据没有收干净有残留, 就会与下次结果混淆在一起.解决核心: 保证每次都收干净, 不要任何残留- 服务端发送给客户端所需要发送数据的总大小,客户端拿到这个总大小,然后进行循环接收, 直至收取完毕, 结束本次收取数据的循环.'''while True:date = client.recv(1024)recv_len += len(date)print(date.decode("gbk"),end="")'''问题解决:尽最大量的收取客户端传输过来的数据量.- 缺点: 操作系统缓存有一定的容量,如果服务端发送过的数据量过大,本地操作系统缓存并不能一次性容纳,服务端的数据将会继续发送,因此,这种时候也不是一个好的解决方案,收取的数据也不一定收取全.'''if recv_len == date_len: break # 当数据长度与接收到的数据长度相等则结束
为何low?
效率低 : 程序运行的速度远快于网络传输的速度, 如果在发送真实数据之前先send该数据的字节流长度, 那么就会放大网络延迟带来的性能损耗
2、使用 struct 模块实现精准数据字节接收(比较高效解决tcp协议的黏包方法)
解决粘包问题的核心就是:为字节流加上一个自定义固定长度的报头, 报头中就包含了该字节流长度, 然后只需要将整个数据加报头 send 一次到对端, 对端先取出固定长度的报头, 然后在取真实的数据
【温馨提示】:struct模块在前面已经介绍过了,👻struct模块传送门
- 服务端
from socket import *
import subprocess
import struct
import jsonserver = socket(AF_INET, SOCK_STREAM)
server.bind(("127.0.0.1", 8080))
server.listen(5)
while True:print("Wait...")conn, client_addr = server.accept()print("已经连接:", client_addr)while True:try:cmd = conn.recv(1024)if not cmd: breakobj = subprocess.Popen(cmd.decode('utf-8'),shell=True,stderr=subprocess.PIPE,stdout=subprocess.PIPE)stdout = obj.stdout.read()stderr = obj.stderr.read()'''1. 定制头部字典. 头部字典里面放,数据内容的大小,数据的描述信息,数据的md5值,等等数据,2. 接着将定制的头部json格式化成字符串,将字符串encode解码成bytes类型为了可以进行send操作3. 再使用struct将获取到的bytes数据的长度打包成固定长度, 这个第一个发送, 让客户端可以获取固定长度的bytes数据. 客户端获取到这个bytes类型的数据, 先decode解码, 再进行json反序列化拿到头部字典4. 客户端就可以通过获取到的头部字典拿到需要准备接收的数据的长度, 循环recv接收数据. 最终, 完美解决了黏包问题.'''# 制作一个报头字典(模板)header_dic = {"header_name": "jack","total_size": len(stderr) + len(stdout),"md5": "f3062575e23dbeb73c315ea525999295",}# 将报头(字典)序列化成字符串类型header_json = json.dumps(header_dic)# 将报头(字符串)转化成byte类型header_byte = header_json.encode("utf-8")# 将报头信息打包成4字节大小,里面包含的报头的长度header_size = struct.pack("i", len(header_byte))# 先发送打包的4bytes,4bytes包含了报头长度conn.send(header_size)# 在发送报头(客户端已经拿到了(解包出)报头的长度)conn.send(header_byte)# 发送真实数据data = stdout + stderrconn.send(data)# 可以合并到一起只send一次,但字符拼接又降低了效率(不推荐)# msg = header_size + header_byte + stdou t+ stderr# conn.send(msg)except Exception:breakconn.close()问题: 前面说到多次send会扩大网络延迟带来的效率问题, 那为什么还要分四次 send ?
-
其实在前面socket收发消息的原理图哪里就给出了答案,数据是先发送到字节操作系统的缓存内,时间间隔短,数据量小的会被和在一起发送,这就是TCP协议nagle优化算法做的事(有提升效率的功能,当然也带来了黏包问题)
-
客户端
from socket import *
import json
import structclient = socket(AF_INET, SOCK_STREAM)
client.connect(('127.0.0.1', 8080))
while True:cmd = input("请输入你要执行的命令>>>:").strip()if not cmd: continue"""接收头部, 解析头部, 获取有用信息:1. 使用struct获取自定义固定长度, 2. 再拿到bytes格式json格式的dic内容, 3. 接着通过decode解码, 4. 然后再使用json反序列化获取dic, 5. 再由dic拿到数据量的大小,接着再通过循环收取数据,"""client.send(cmd.encode("utf-8"))# 接受byte_4byte_4 = client.recv(4)# 解包出报头长度header_len = struct.unpack("i", byte_4)[0]# 使用长度接受byteheader_byte = client.recv(header_len)# byte---->strheader_str = header_byte.decode("utf-8")# str---->dicheader_dic = json.loads(header_str)# 拿到真正数据的大小tatal_size = header_dic["total_size"]recv_size = 0while True:data = client.recv(1024)recv_size += len(data)print(data.decode("gbk"), end="")if recv_size == tatal_size: break3、UDP没有粘包问题
udp 被称为数据报协议, 每次发送的数据都是一个数据报, 一次 sendto 对应一次 recvfrom, 不会产生黏包
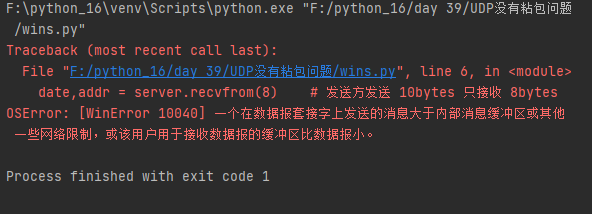
udp 又被称为不可靠协议, 不可靠在哪里? 比如发送方发送了 10bytes 的数据, 而接收方只接收 8bytes 的数据, 那么剩下的两个 bytes 将会被丢弃, 并且在不同的平台有不同的表现, 下面我们来进行试验 :
- windows平台下实验客户端
from socket import *client = socket(AF_INET,SOCK_DGRAM)msg = "1234567890".encode("utf-8") # "utf-8"编码格式的数字和字母都是1bytes
msg2 = "12345".encode("utf-8") # 发送 5bytes
msg3 = "123".encode("utf-8") # 发送 3bytesclient.sendto(msg,("127.0.0.1",8989))
client.sendto(msg2,("127.0.0.1",8989))
client.sendto(msg3,("127.0.0.1",8989))
- 服务端
from socket import *server = socket(AF_INET,SOCK_DGRAM)
server.bind(("127.0.0.1",8989))date,addr = server.recvfrom(8) # 发送方发送 10bytes 只接收 8bytes
date2,addr2 = server.recvfrom(3) # 发送方发送 5bytes 只接收 3bytes
date3,addr3 = server.recvfrom(1) # 发送方发送 3bytes 只接收 1bytesprint(date.decode("utf-8"))
print(date2.decode("utf-8"))
print(date3.decode("utf-8"))
- 运行结果如下:
- linux平台运行下实验客户端
from socket import *client = socket(AF_INET,SOCK_DGRAM)msg = "1234567891".encode("utf-8")
msg2 = "12345".encode("utf-8")
msg3 = "123".encode("utf-8")client.sendto(msg,("192.168.12.53",8848))
client.sendto(msg2,("192.168.12.53",8848))
client.sendto(msg3,("192.168.12.53",8848))
- 服务端
from socket import *
server=socket(AF_INET,SOCK_DGRAM)
server.bind(("192.168.12.53",8848))
date,addr=server.recvfrom(8)
date2,addr2=server.recvfrom(3)
date3,addr3=server.recvfrom(1)
print(date.decode("utf-8")) # 注意:如果发送方发送的是汉字, 一个汉字三个字节, >如果接受不完整解码出来会报错
print(date2.decode("utf-8"))
print(date3.decode("utf-8"))- 运行结果如下:



![[pwn]ROP:绕过ASLRNX](https://img-blog.csdnimg.cn/20190527155350872.png?x-oss-process=image/watermark,type_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L0JyZWV6ZV9DQVQ=,size_16,color_FFFFFF,t_70)

![[二进制学习笔记]Ubuntu20.04关闭开启ASLR](https://img-blog.csdnimg.cn/d0062767cefd4a1e857031dcb618560d.png)





![[ASLR,地址空间,Linux,随机化,Windows]ASLR 是如何保护 Linux 系统免受缓冲区溢出攻击的](https://img-blog.csdnimg.cn/img_convert/21258bfe71ae90be1683ab5e6a1ace84.png)