前言
金三银四即将来临,整理了十道十分经典的消息队列面试题,看完肯定对面试有帮助的,大家一起加油哈~
- 什么是消息队列
- 消息队列的应用场景
- 消息队列如何解决消息丢失问题
- 消息队列如何保证消息的顺序性。
- 消息有可能发生重复消费吗?如何幂等处理?
- 如何处理消息队列的消息积压问题
- 消息队列技术选型,Kafka还是RocketMQ,还是RabbitMQ
- 消息中间件如何做到高可用?
- 如何保证数据一致性,事务消息如何实现
- 如果让你写一个消息队列,该如何进行架构设计?
1. 什么是消息队列
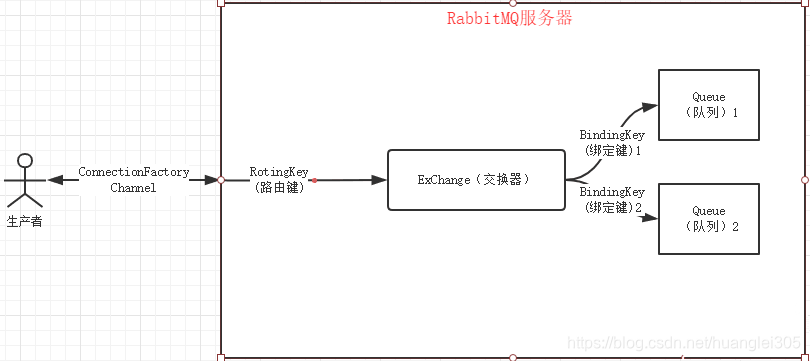
你可以把消息队列理解为一个使用队列来通信的组件。它的本质,就是个转发器,包含发消息、存消息、消费消息的过程。最简单的消息队列模型如下:
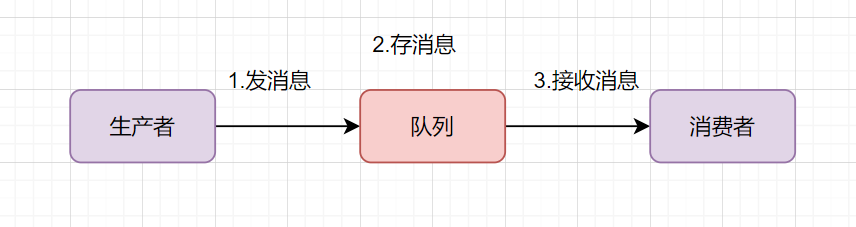
我们通常说的消息队列,简称MQ(Message Queue),它其实就指消息中间件,当前业界比较流行的开源消息中间件包括:RabbitMQ、RocketMQ、Kafka。
2. 消息队列有哪些使用场景。
有时候面试官会换个角度问你,为什么使用消息队列。你可以回答以下这几点:
- 应用解耦
- 流量削峰
- 异步处理
- 消息通讯
- 远程调用
2.1 应用解耦
举个常见业务场景:下单扣库存,用户下单后,订单系统去通知库存系统扣减。传统的做法就是订单系统直接调用库存系统:
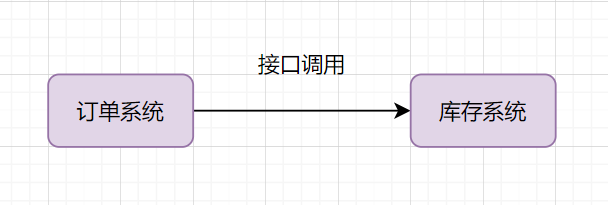
- 如果库存系统无法访问,下单就会失败,订单和库存系统存在耦合关系
- 如果业务又接入一个营销积分服务,那订单下游系统要扩充,如果未来接入越来越多的下游系统,那订单系统代码需要经常修改
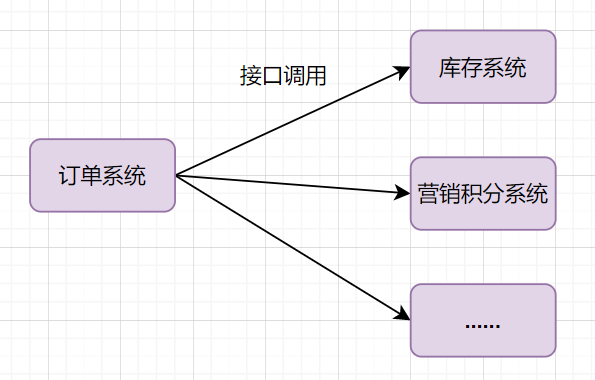
如何解决这个问题呢?可以引入消息队列
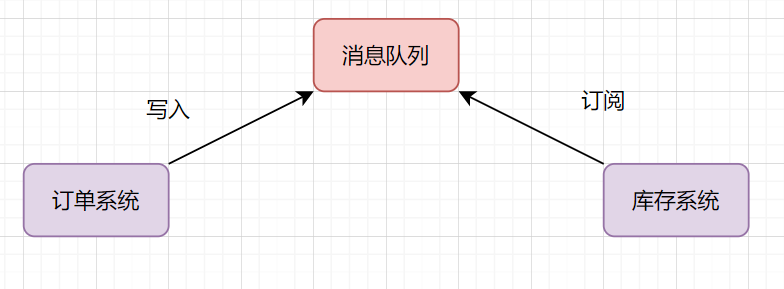
- 订单系统:用户下单后,消息写入到消息队列,返回下单成功
- 库存系统:订阅下单消息,获取下单信息,进行库存扣减操作。
2.2 流量削峰
流量削峰也是消息队列的常用场景。我们做秒杀实现的时候,需要避免流量暴涨,打垮应用系统的风险。可以在应用前面加入消息队列。
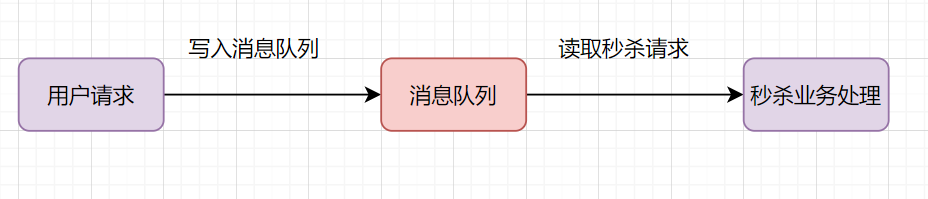
假设秒杀系统每秒最多可以处理2k个请求,每秒却有5k的请求过来,可以引入消息队列,秒杀系统每秒从消息队列拉2k请求处理得了。
有些伙伴担心这样会出现消息积压的问题,
- 首先秒杀活动不会每时每刻都那么多请求过来,高峰期过去后,积压的请求可以慢慢处理;
- 其次,如果消息队列长度超过最大数量,可以直接抛弃用户请求或跳转到错误页面;
2.3 异步处理
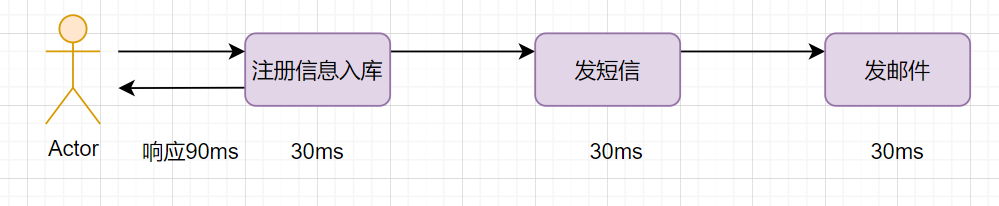
我们经常会遇到这样的业务场景:用户注册成功后,给它发个短信和发个邮件。
如果注册信息入库是30ms,发短信、邮件也是30ms,三个动作串行执行的话,会比较耗时,响应90ms:
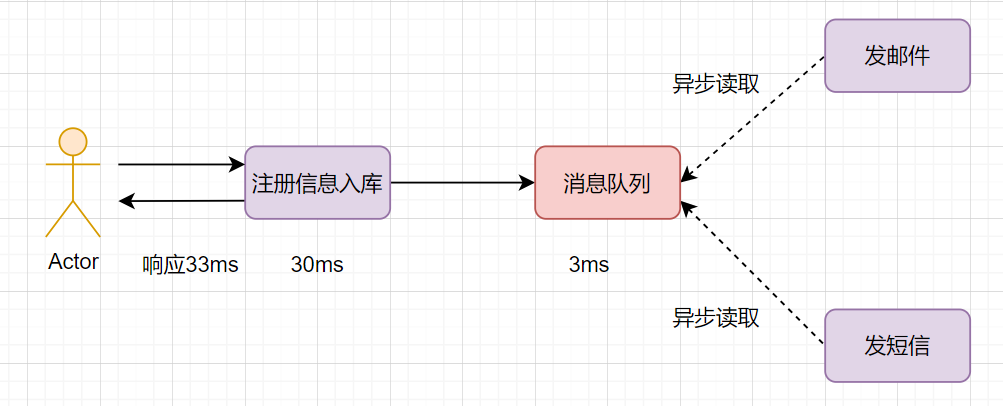
如果采用并行执行的方式,可以减少响应时间。注册信息入库后,同时异步发短信和邮件。如何实现异步呢,用消息队列即可,就是说,注册信息入库成功后,写入到消息队列(这个一般比较快,如只需要3ms),然后异步读取发邮件和短信。
2.4 消息通讯
消息队列内置了高效的通信机制,可用于消息通讯。如实现点对点消息队列、聊天室等。
2.5 远程调用
我们公司基于MQ,自研了远程调用框架。
3. 消息队列如何解决消息丢失问题?
一个消息从生产者产生,到被消费者消费,主要经过这3个过程:
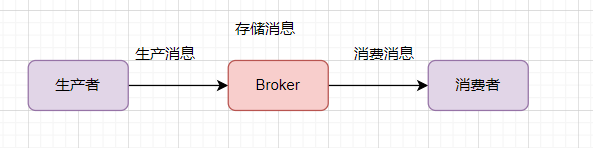
因此如何保证MQ不丢失消息,可以从这三个阶段阐述:
- 生产者保证不丢消息
- 存储端不丢消息
- 消费者不丢消息
3.1 生产者保证不丢消息
生产端如何保证不丢消息呢?确保生产的消息能到达存储端。
如果是RocketMQ消息中间件,Producer生产者提供了三种发送消息的方式,分别是:
- 同步发送
- 异步发送
- 单向发送
生产者要想发消息时保证消息不丢失,可以:
- 采用同步方式发送,send消息方法返回成功状态,就表示消息正常到达了存储端Broker。
- 如果send消息异常或者返回非成功状态,可以重试。
- 可以使用事务消息,RocketMQ的事务消息机制就是为了保证零丢失来设计的
3.2 存储端不丢消息
如何保证存储端的消息不丢失呢?确保消息持久化到磁盘。大家很容易想到就是刷盘机制。
刷盘机制分同步刷盘和异步刷盘:
- 生产者消息发过来时,只有持久化到磁盘,RocketMQ的存储端Broker才返回一个成功的ACK响应,这就是同步刷盘。它保证消息不丢失,但是影响了性能。
- 异步刷盘的话,只要消息写入PageCache缓存,就返回一个成功的ACK响应。这样提高了MQ的性能,但是如果这时候机器断电了,就会丢失消息。
Broker一般是集群部署的,有master主节点和slave从节点。消息到Broker存储端,只有主节点和从节点都写入成功,才反馈成功的ack给生产者。这就是同步复制,它保证了消息不丢失,但是降低了系统的吞吐量。与之对应的就是异步复制,只要消息写入主节点成功,就返回成功的ack,它速度快,但是会有性能问题。
3.3 消费阶段不丢消息
消费者执行完业务逻辑,再反馈会Broker说消费成功,这样才可以保证消费阶段不丢消息。
4. 消息队列如何保证消息的顺序性。
消息的有序性,就是指可以按照消息的发送顺序来消费。有些业务对消息的顺序是有要求的,比如先下单再付款,最后再完成订单,这样等。假设生产者先后产生了两条消息,分别是下单消息(M1),付款消息(M2),M1比M2先产生,如何保证M1比M2先被消费呢。
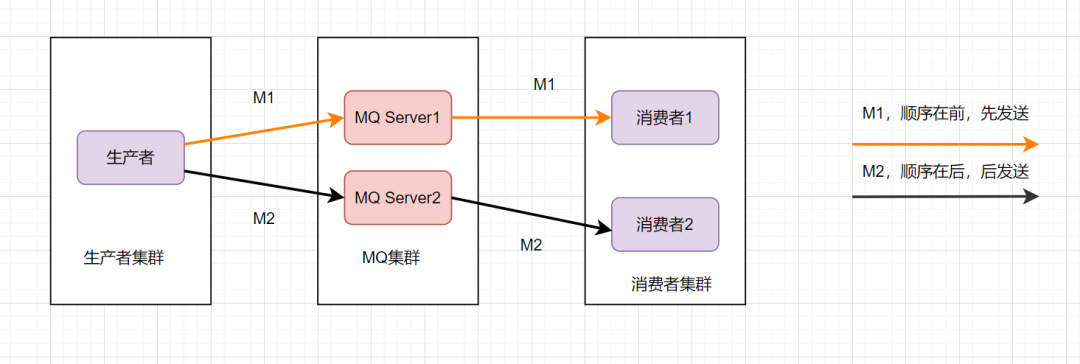
为了保证消息的顺序性,可以将M1、M2发送到同一个Server上,当M1发送完收到ack后,M2再发送。如图:
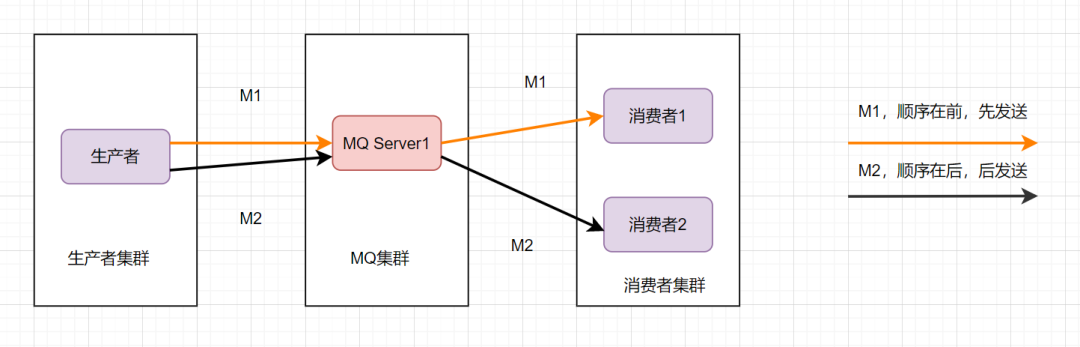
这样还是可能会有问题,因为从MQ服务器到消费端,可能存在网络延迟,虽然M1先发送,但是它比M2晚到。
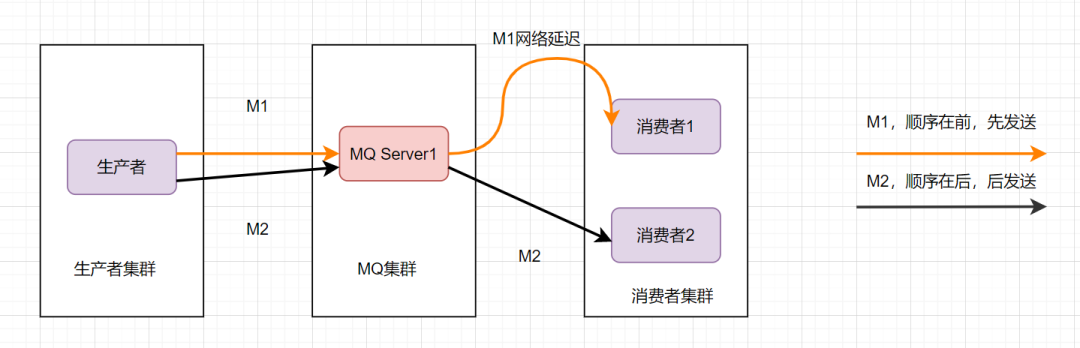
那还能怎么办才能保证消息的顺序性呢?将M1和M2发往同一个消费者,且发送M1后,等到消费端ACK成功后,才发送M2就得了。
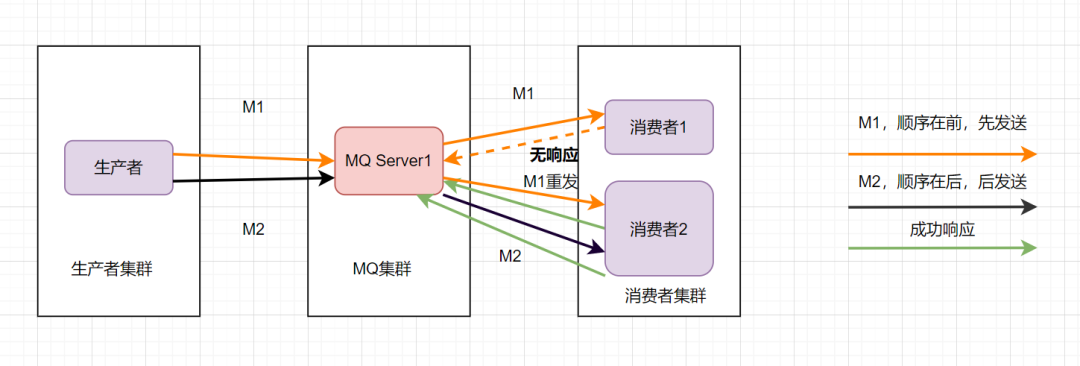
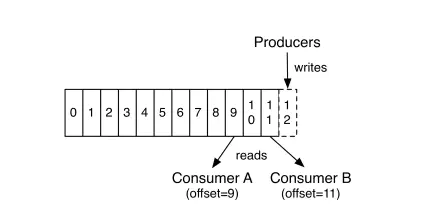
消息队列保证顺序性整体思路就是这样啦。比如Kafka的全局有序消息,就是这种思想的体现: 就是生产者发消息时,1个Topic只能对应1个Partition,一个 Consumer,内部单线程消费。
但是这样吞吐量太低,一般保证消息局部有序即可。在发消息的时候指定Partition Key,Kafka对其进行Hash计算,根据计算结果决定放入哪个Partition。这样Partition Key相同的消息会放在同一个Partition。然后多消费者单线程消费指定的Partition。
5.消息队列有可能发生重复消费,如何避免,如何做到幂等?
消息队列是可能发生重复消费的。
- 生产端为了保证消息的可靠性,它可能往MQ服务器重复发送消息,直到拿到成功的ACK。
- 再然后就是消费端,消费端消费消息一般是这个流程:拉取消息、业务逻辑处理、提交消费位移。假设业务逻辑处理完,事务提交了,但是需要更新消费位移时,消费者却挂了,这时候另一个消费者就会拉到重复消息了。
如何幂等处理重复消息呢?
幂等处理重复消息,简单来说,就是搞个本地表,带唯一业务标记的,利用主键或者唯一性索引,每次处理业务,先校验一下就好啦。又或者用redis缓存下业务标记,每次看下是否处理过了。
6. 如何处理消息队列的消息积压问题
消息积压是因为生产者的生产速度,大于消费者的消费速度。遇到消息积压问题时,我们需要先排查,是不是有bug产生了。
如果不是bug,我们可以优化一下消费的逻辑,比如之前是一条一条消息消费处理的话,我们可以确认是不是可以优为批量处理消息。如果还是慢,我们可以考虑水平扩容,增加Topic的队列数,和消费组机器的数量,提升整体消费能力。
如果是bug导致几百万消息持续积压几小时。有如何处理呢?需要解决bug,临时紧急扩容,大概思路如下:
- 先修复consumer消费者的问题,以确保其恢复消费速度,然后将现有consumer 都停掉。
- 新建一个 topic,partition 是原来的 10 倍,临时建立好原先10倍的queue 数量。
- 然后写一个临时的分发数据的 consumer 程序,这个程序部署上去消费积压的数据,消费之后不做耗时的处理,直接均匀轮询写入临时建立好的 10 倍数量的 queue。
- 接着临时征用 10 倍的机器来部署 consumer,每一批 consumer 消费一个临时 queue 的数据。这种做法相当于是临时将 queue 资源和 consumer 资源扩大 10 倍,以正常的 10 倍速度来消费数据。
- 等快速消费完积压数据之后,得恢复原先部署的架构,重新用原先的 consumer 机器来消费消息。
7. 消息队列技术选型,Kafka还是RocketMQ,还是RabbitMQ
先可以对比下它们优缺点:
| Kafka | RocketMQ | RabbitMQ | |
|---|---|---|---|
| 单机吞吐量 | 17.3w/s | 11.6w/s | 2.6w/s(消息做持久化) |
| 开发语言 | Scala/Java | Java | Erlang |
| 主要维护者 | Apache | Alibaba | Mozilla/Spring |
| 订阅形式 | 基于topic,按照topic进行正则匹配的发布订阅模式 | 基于topic/messageTag,按照消息类型、属性进行正则匹配的发布订阅模式 | 提供了4种:direct, topic ,Headers和fanout。fanout就是广播模式 |
| 持久化 | 支持大量堆积 | 支持大量堆积 | 支持少量堆积 |
| 顺序消息 | 支持 | 支持 | 不支持 |
| 集群方式 | 天然的Leader-Slave,无状态集群,每台服务器既是Master也是Slave | 常用 多对’Master-Slave’ 模式,开源版本需手动切换Slave变成Master | 支持简单集群,'复制’模式,对高级集群模式支持不好。 |
| 性能稳定性 | 较差 | 一般 | 好 |
- RabbitMQ是开源的,比较稳定的支持,活跃度也高,但是不是Java语言开发的。
- 很多公司用RocketMQ,比较成熟,是阿里出品的。
- 如果是大数据领域的实时计算、日志采集等场景,用 Kafka 是业内标准的。
8. 消息中间件如何做到高可用
消息中间件如何保证高可用呢?单机是没有高可用可言的,高可用都是对集群来说的,一起看下kafka的高可用吧。
Kafka 的基础集群架构,由多个broker组成,每个broker都是一个节点。当你创建一个topic时,它可以划分为多个partition,而每个partition放一部分数据,分别存在于不同的 broker 上。也就是说,一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。
有些伙伴可能有疑问,每个partition放一部分数据,如果对应的broker挂了,那这部分数据是不是就丢失了?那还谈什么高可用呢?
Kafka 0.8 之后,提供了复制品副本机制来保证高可用,即每个 partition 的数据都会同步到其它机器上,形成多个副本。然后所有的副本会选举一个 leader 出来,让leader去跟生产和消费者打交道,其他副本都是follower。写数据时,leader 负责把数据同步给所有的follower,读消息时, 直接读 leader 上的数据即可。如何保证高可用的?就是假设某个 broker 宕机,这个broker上的partition 在其他机器上都有副本的。如果挂的是leader的broker呢?其他follower会重新选一个leader出来。
9. 如何保证数据一致性,事务消息如何实现
一条普通的MQ消息,从产生到被消费,大概流程如下:
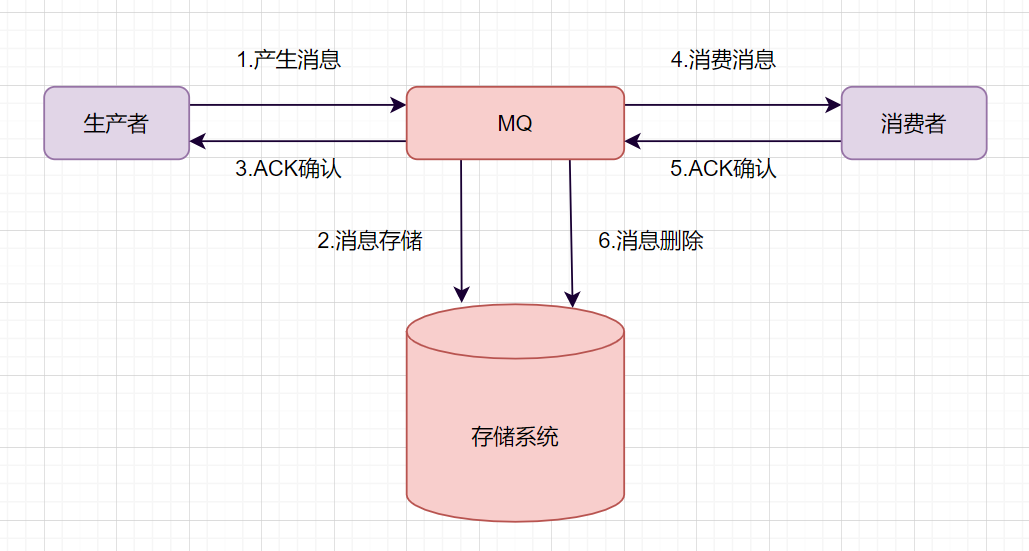
- 生产者产生消息,发送带MQ服务器
- MQ收到消息后,将消息持久化到存储系统。
- MQ服务器返回ACk到生产者。
- MQ服务器把消息push给消费者
- 消费者消费完消息,响应ACK
- MQ服务器收到ACK,认为消息消费成功,即在存储中删除消息。
我们举个下订单的例子吧。订单系统创建完订单后,再发送消息给下游系统。如果订单创建成功,然后消息没有成功发送出去,下游系统就无法感知这个事情,出导致数据不一致。
如何保证数据一致性呢?可以使用事务消息。一起来看下事务消息是如何实现的吧。
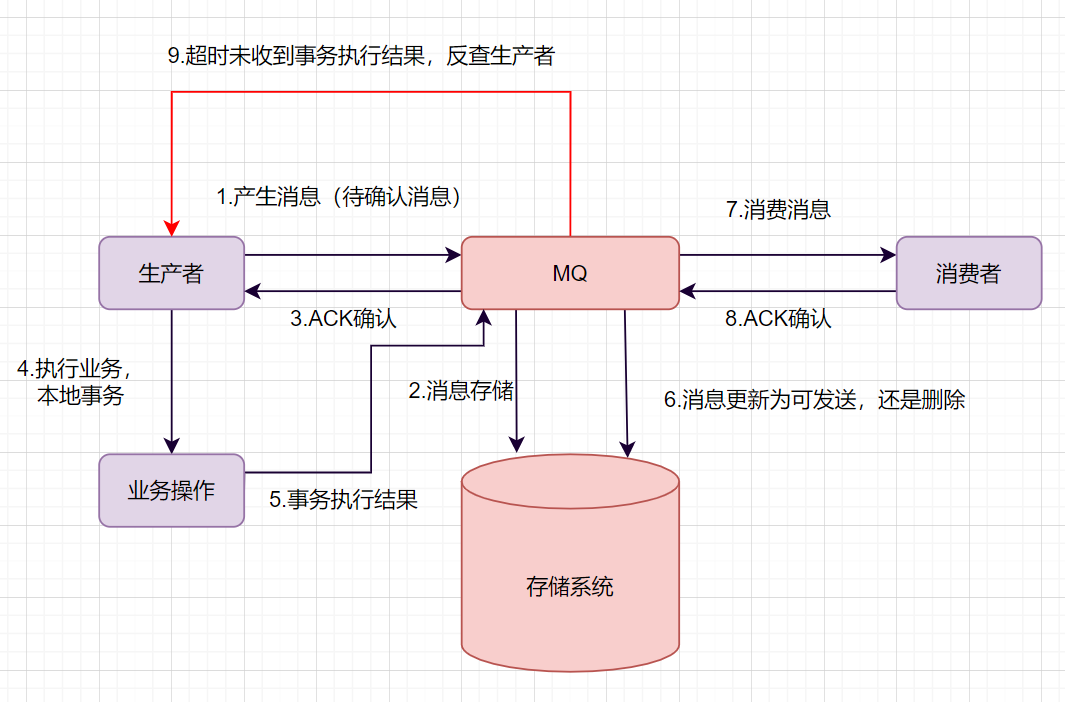
- 生产者产生消息,发送一条半事务消息到MQ服务器
- MQ收到消息后,将消息持久化到存储系统,这条消息的状态是待发送状态。
- MQ服务器返回ACK确认到生产者,此时MQ不会触发消息推送事件
- 生产者执行本地事务
- 如果本地事务执行成功,即commit执行结果到MQ服务器;如果执行失败,发送rollback。
- 如果是正常的commit,MQ服务器更新消息状态为可发送;如果是rollback,即删除消息。
- 如果消息状态更新为可发送,则MQ服务器会push消息给消费者。消费者消费完就回ACK。
- 如果MQ服务器长时间没有收到生产者的commit或者rollback,它会反查生产者,然后根据查询到的结果执行最终状态。
10. 让你写一个消息队列,该如何进行架构设计?
这个问题面试官主要考察三个方面的知识点:
- 你有没有对消息队列的架构原理比较了解
- 考察你的个人设计能力
- 考察编程思想,如什么高可用、可扩展性、幂等等等。
遇到这种设计题,大部分人会很蒙圈,因为平时没有思考过类似的问题。大多数人平时埋头增删改啥,不去思考框架背后的一些原理。有很多类似的问题,比如让你来设计一个 Dubbo 框架,或者让你来设计一个MyBatis 框架,你会怎么思考呢?
回答这类问题,并不要求你研究过那技术的源码,你知道那个技术框架的基本结构、工作原理即可。设计一个消息队列,我们可以从这几个角度去思考:
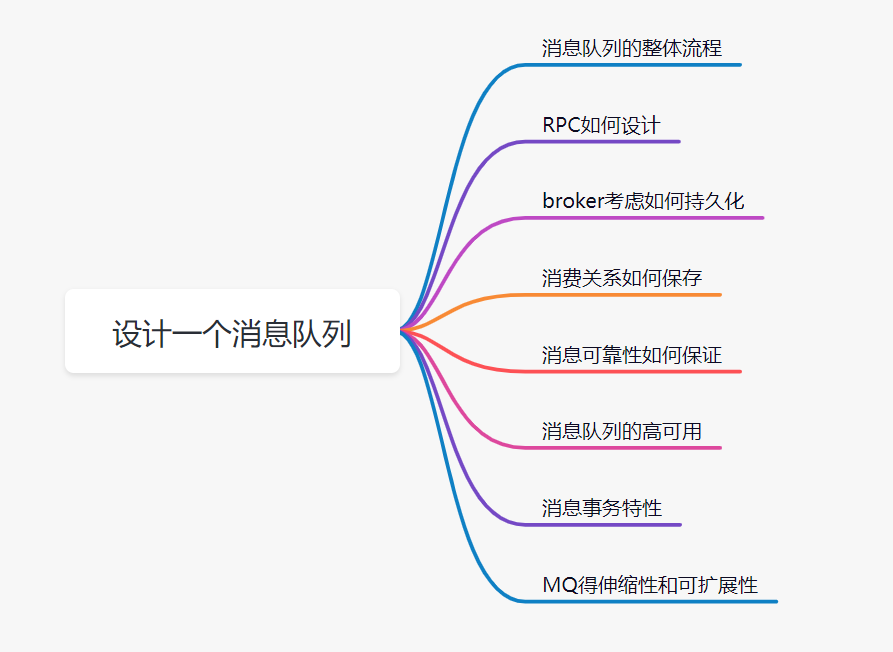
- 首先是消息队列的整体流程,producer发送消息给broker,broker存储好,broker再发送给consumer消费,consumer回复消费确认等。
- producer发送消息给broker,broker发消息给consumer消费,那就需要两次RPC了,RPC如何设计呢?可以参考开源框架Dubbo,你可以说说服务发现、序列化协议等等
- broker考虑如何持久化呢,是放文件系统还是数据库呢,会不会消息堆积呢,消息堆积如何处理呢。
- 消费关系如何保存呢?点对点还是广播方式呢?广播关系又是如何维护呢?zk还是config server
- 消息可靠性如何保证呢?如果消息重复了,如何幂等处理呢?
- 消息队列的高可用如何设计呢?可以参考Kafka的高可用保障机制。多副本 -> leader & follower -> broker 挂了重新选举 leader 即可对外服务。
- 消息事务特性,与本地业务同个事务,本地消息落库;消息投递到服务端,本地才删除;定时任务扫描本地消息库,补偿发送。
- MQ得伸缩性和可扩展性,如果消息积压或者资源不够时,如何支持快速扩容,提高吞吐?可以参照一下 Kafka 的设计理念,broker -> topic -> partition,每个 partition 放一个机器,就存一部分数据。如果现在资源不够了,简单啊,给 topic 增加 partition,然后做数据迁移,增加机器,不就可以存放更多数据,提供更高的吞吐量了?
参考与感谢
-
[1]阿里RocketMQ如何解决消息的顺序&重复两大硬伤?: https://dbaplus.cn/news-21-1123-1.html
-
[2]消息中间件面试题:如何解决消息队列的延时以及过期失效问题?: https://jsbintask.cn/2019/01/28/interview/interview-middleware-manymessage/
-
[3]消息队列设计精要: https://zhuanlan.zhihu.com/p/21649950
-
[4]MQ消息最终一致性解决方案: https://juejin.cn/post/6844903951448408071