-
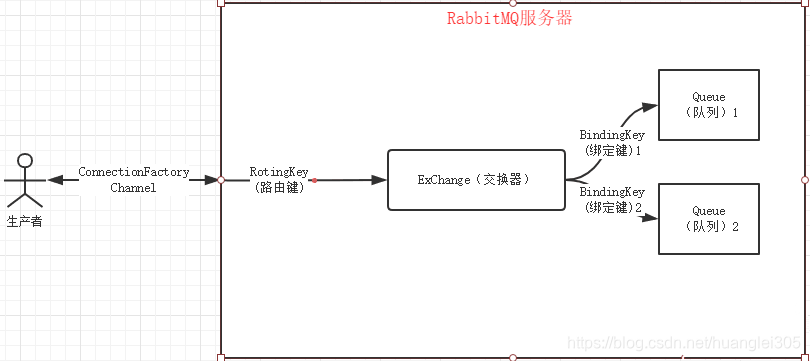
你们公司生产环境用的是什么消息中间件?
RabbitMQ、ActiveMQ、RocketMQ、Kafka优缺点与应用场景 -
为什么在你们系统架构中要引入消息中间件?
系统解耦、异步调用、流量削峰 -
说说系统架构引入消息中间件有什么缺点?
系统可用性降低(MQ挂了)、系统稳定性降低(MQ消息重发、丢失等)、分布式一致性问题(需要分布式事务方案来保障) -
消息中间件集群崩溃,如何保证百万生产数据不丢失?
把消息持久化写入到磁盘上去 -
如何保证消息队列的高可用?
RabbitMQ镜像集群模式、Kafka partition和replica机制 -
如何保证消息不被重复消费?
本质上还是问使用消息队列如何保证幂等性;e.g.
根据主键先查一下,如果这数据都有了,你就别插入了,update 一下;
使用set命令写redis;
全局唯一的 id;
数据库唯一键; -
如何保证消息的可靠性传输?
* RabbitMQ弄丢了数据
* Kafka弄丢了数据
设置如下 4 个参数- 给 topic 设置 replication.factor 参数:这个值必须大于 1,要求每个 partition 必须有至少 2 个副本。
- 在 Kafka 服务端设置 min.insync.replicas 参数:这个值必须大于 1,这个是要求一个 leader 至少感知到有至少一个 follower 还跟自己保持联系,没掉队,这样才能确保 leader 挂了还有一个 follower 吧。
- 在 producer 端设置 acks=all:这个是要求每条数据,必须是写入所有 replica 之后,才能认为是写成功了。
- 在 producer 端设置 retries=MAX(很大很大很大的一个值,无限次重试的意思):这个是要求一旦写入失败,就无限重试,卡在这里了。
-
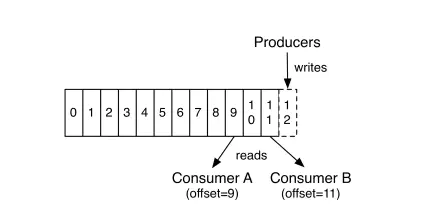
如何保证消息的顺序性?
* RabbitMQ
拆分多个 queue,每个 queue 一个 consumer,就是多一些 queue 而已,确实是麻烦点;或者就一个 queue 但是对应一个 consumer,然后这个 consumer 内部用内存队列做排队,然后分发给底层不同的 worker 来处理。

- Kafka
一个 topic,一个 partition,一个 consumer,内部单线程消费,单线程吞吐量太低,一般不会用这个。
写 N 个内存 queue,具有相同 key 的数据都到同一个内存 queue;然后对于 N 个线程,每个线程分别消费一个内存 queue 即可,这样就能保证顺序性。