mahout 记录
mahout记录
输入
mahout 是以偏好(preference)的形式来表达的,一个偏好包含一个用户ID、一个物品ID、还有一个用户对物品偏爱程度的数值
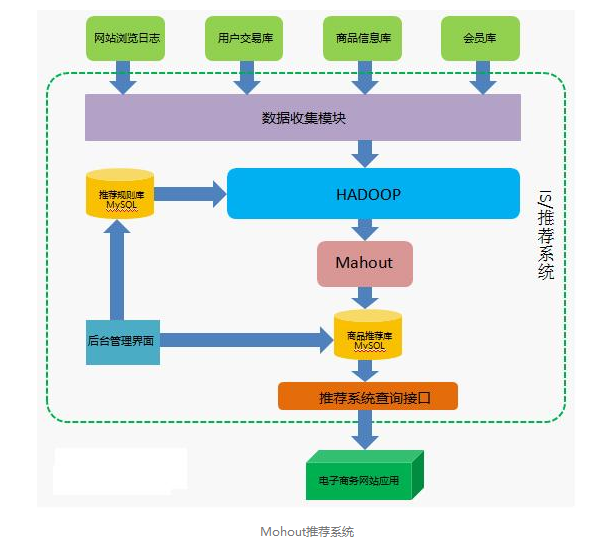
- 简单示意图:

DataModel 实现存储并为计算提供其所需的所有偏好、用户和物品数据。
UserSimilarity实现给出两个用户之间的相似度,可从多种可能度量或计算中选用一种来作为依据。
UserNeighborhood 实现明确了与给定用户最相似的一组用户。最后, Recommender 实现合并
所有这些组件为用户推荐物品。
DataModel
在Mahout中使用 DataModel 这种抽象机制对推荐程序的输入数据进行封装,而 DataModel
的实现为各类推荐算法提供了对数据的高效访问。

MySQLJDBCDataModel
mahout 提供了多种DataModel的实现,这里只说一种MySQL数据库实现的数据源读取
- 默认情况下,这个实现假设所有的偏好数据位于一个名为 taste_preferences 的表中,其中用户ID的列为 user_id ,物品ID的列为 item_id ,偏好值的列为 preference ,还可以包含Java long型的timestamp字段
| user_id | item_id | preference |
|---|---|---|
| BIGINT NOT NULL INDEX | BIGINT NOT NULL INDEX | FLOAT NOT NULL |
| PRIMARY KEY | PRIMARY KEY |
想要自定义实现其他的DataModel,可以继承DataModel来实现相关方法,例如改成spring集成的数据源管理
public interface DataModel extends Refreshable, Serializable {LongPrimitiveIterator getUserIDs() throws TasteException;PreferenceArray getPreferencesFromUser(long var1) throws TasteException;FastIDSet getItemIDsFromUser(long var1) throws TasteException;LongPrimitiveIterator getItemIDs() throws TasteException;PreferenceArray getPreferencesForItem(long var1) throws TasteException;Float getPreferenceValue(long var1, long var3) throws TasteException;Long getPreferenceTime(long var1, long var3) throws TasteException;int getNumItems() throws TasteException;int getNumUsers() throws TasteException;int getNumUsersWithPreferenceFor(long var1) throws TasteException;int getNumUsersWithPreferenceFor(long var1, long var3) throws TasteException;void setPreference(long var1, long var3, float var5) throws TasteException;void removePreference(long var1, long var3) throws TasteException;boolean hasPreferenceValues();float getMaxPreference();float getMinPreference();
}
PreferenceArray 是偏好聚合的接口,具有类似数组的API
FastByIDMap 和 FastIDSet
- 与 HashMap 类似, FastByIDMap 是基于散列的。但它在处理散列冲突时使用的是线性探测(linear probing),而非分离链接(separate chaining)。这样便不必为每个条目(entry)都增加一个额外的 Map.Entry 对象; Object 对内存的消耗是惊人的
- 在Mahout推荐程序中键(key)和成员(member)通常采用原始类型 long ,而非 Object 。使用 long 型的键可以节约内存并提升性能
- Set 实现的内部没有使用 Map
- FastByIDMap 可以作为高速缓存,因为它有一个最大空间的概念;超过这个大小时,若要新加入条目则会把不常用的移走
无偏好数据
当只表述关联,不含关联程度时,输入的偏好没有值
用GenericBooleanPrefDataModel构建DataModelBuilder
RecommenderEvaluator evaluator =new AverageAbsoluteDifferenceRecommenderEvaluator();RecommenderBuilder recommenderBuilder = new RecommenderBuilder() {public Recommender buildRecommender(DataModel model)throws TasteException {UserSimilarity similarity =new PearsonCorrelationSimilarity(model);UserNeighborhood neighborhood =new NearestNUserNeighborhood(10, similarity, model);returnnew GenericUserBasedRecommender(model, neighborhood, similarity);}};DataModelBuilder modelBuilder = new DataModelBuilder() {public DataModel buildDataModel(FastByIDMap<PreferenceArray> trainingData) {return new GenericBooleanPrefDataModel(GenericBooleanPrefDataModel.toDataMap(trainingData));}};double score = evaluator.evaluate(recommenderBuilder, modelBuilder, model, 0.9, 1.0);System.out.println(score);
进行推荐
各个推荐组合可以定制,通常包含如下组件:
- 数据模型,由 DataModel 实现
- 用户间的相似性度量,由 UserSimilarity 实现
- 用户邻域的定义,由 UserNeighborhood 实现
- 推荐引擎,由一个 Recommender 实现
基于用户
算法
for every item i that u has no preference for yetfor every other user v that has a preference for icompute a similarity s between u and vincorporate v's preference for i, weighted by s, into a running average
return the top items, ranked by weighted average
相似性度量
mahout提供了多种相似性度量的实现
-
PearsonCorrelationSimilarity 基于皮尔逊相关系数的相似度 用来反映两个变量线性相关程度的统计量 范围:[-1,1],绝对值越大,说明相关性越强,负相关对于推荐的意义小。
1、 不考虑重叠的数量;2、 如果只有一项重叠,无法计算相似性(计算过程被除数有n-1);3、 如果重叠的值都相等,也无法计算相似性(标准差为0,做除数)。
-
EuclideanDistanceSimilarity 基于欧氏距离定义相似度 利用欧式距离d定义的相似度s,s=1 / (1+d)。范围:[0,1],值越大,说明d越小,也就是距离越近,则相似度越大。
同皮尔森相似度一样,该相似度也没有考虑重叠数对结果的影响,同样地,Mahout通过增加一个枚举类型(Weighting)的参数来使得重叠数也成为计算相似度的影响因子。
-
UncenteredCosineSimilarity 采用余弦相似性度量 多维空间两点与所设定的点形成夹角的余弦值。范围:[-1,1],值越大,说明夹角越大,两点相距就越远,相似度就越小。
在数学表达中,如果对两个项的属性进行了数据中心化,计算出来的余弦相似度和皮尔森相似度是一样的,在mahout中,实现了数据中心化的过程, 所以皮尔森相似度值也是数据中心化后的余弦相似度。另外在新版本中,Mahout提供了UncenteredCosineSimilarity类作为计算非中心化数据的余弦相似度。
-
TanimotoCoefficientSimilarity 忽略偏好值基于谷本系数计算相似度 又名广义Jaccard系数,是对Jaccard系数的扩展,范围:[0,1],完全重叠时为1,无重叠项时为0,越接近1说明越相似。
-
LogLikelihoodSimilarity 基于对数似然比更好地计算相似度 重叠的个数,不重叠的个数,都没有的个数
-
…
Weighting.WEIGHTED 进行similarity加权拓展
基于物品
算法
for every item i that u has no preference for yetfor every item j that u has a preference forcompute a similarity s between i and jadd u's preference for j, weighted by s, to a running average
return the top items, ranked by weighted average
Slope-one 推荐算法
两个物品之间存在某种线性关系,eg:Y=mX+b,所以此算法需要有预处理的步骤
for every item ifor every other item jfor every user u expressing preference for both i and jadd the difference in u's preference for i and j to an average
这基础上:
for every item i the user u expresses no preference forfor every item j that user u expresses a preference forfind the average preference difference between j and iadd this diff to u's preference value for jadd this to a running average
return the top items, ranked by these averages
slope-one是有代价的:内存消耗, MySQLJDBCDiffStorage 可以预先计算差异值并在数据库中更新它们。它们需要和JDBC支持的 DataModel 实现(比如MySQLJDBCDataModel )结合起来使用
利用 IDRescorer 修改推荐结果
调用如下方法实现
recommend(long userID, int howMany, IDRescorer rescorer)
DBCDiffStorage 可以预先计算差异值并在数据库中更新它们。它们需要和JDBC支持的 DataModel 实现(比如MySQLJDBCDataModel )结合起来使用
利用 IDRescorer 修改推荐结果
调用如下方法实现
recommend(long userID, int howMany, IDRescorer rescorer)
参考:
《mahout in action》
Mahout构建图书推荐系统