Linux内存结构
Node
首先, 内存被划分为结点. 每个结点关联到系统中的一个处理器,内核中表示为pg_data_t的
实例. 系统中每个节点被链接到一个以NULL结尾的pgdat_list链表中<而其中的每个节点利用pg_data_tnode_next字段链接到下一节.而对于PC这种UMA结构的机器来说, 只使用了一个成为contig_page_data的静态pg_data_t结构。
Zone
Node又被分成不同的Zone,主要用来管理不同的内存区域,那为什么要把Node分成Zone呢?
1. ISA总线的直接内存存储DMA处理器有一个严格的限制 :他们只能对RAM的前16MB进行寻址。
2. 在具有大容量RAM的现代32位计算机中, CPU不能直接访问所有的物理地址, 因为线性地址空间太小, 内核不可能直接映射所有物理内存到线性地址空间。
Zone的内存范围划分:

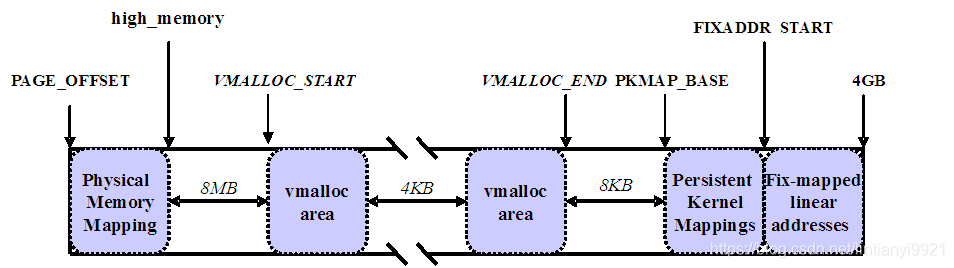
高端内存
因为在32位机器上,内存可访问的最大容量按理来说只有2^32=4G,但是实际上,32位的机器的内存有的并不止4G。在linux上,用户态可访问的内存是0-3G,内核态可访问的内存是3G-4G,因为逻辑地址只有4G而物理内存又超过了4G,所以就有了高端内存。在高端内存上,有128M的逻辑地址映射的物理地址是不固定的,这样,利用这128M的不固定的逻辑地址就可以访问到所有的物理地址。因为在64位的机器上不存在高端内存,所以这个就不详细说了。
Page
页是用来存储数据的基本单位,内存中的数据都是以页为单位来存储的。
CPU模型
UMA模型
定义:均匀访存模型(Uniform Memory Access)通常简称UMA,指所有的物理存储器被均匀共享,即处理器访问它们的时间是一样的。UMA亦称作统一寻址技术或统一内存存取。

SMP模型中的资源(CPU、IO、内存)都是共享的,所以SMP中的任何一个环节都有可能成为瓶颈,而最受限制的则是内存。由于每个CPU必须通过相同的内存总线访问相同的内存资源,因此随着CPU数量的增加,内存访问冲突将迅速增加,最终会造成CPU资源的浪费,使 CPU性能的有效性大大降低。实验证明,SMP服务器CPU利用率最好的情况是2至4个CPU。SMP是UMA模型的一种实现。
NUMA模型
定义:非统一内存访问架构(Non-uniform memory access,简称NUMA)是一种为多处理器的电脑设计的内存,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存快一些。

NUMA 服务器的基本特征是具有多个 CPU 模块,每个 CPU 模块由多个 CPU( 如 4 个 ) 组成,并且具有独立的本地内存、 I/O 槽口等。由于其节点之间可以通过互联模块 ( 如称为 Crossbar Switch) 进行连接和信息交互,因此每个 CPU 可以访问整个系统的内存 ( 这是 NUMA 系统与 MPP 系统的重要差别 ) 。显然,访问本地内存的速度将远远高于访问远地内存 ( 系统内其它节点的内存 ) 的速度,这也是非一致存储访问 NUMA 的由来。由于这个特点,为了更好地发挥系统性能,开发应用程序时需要尽量减少不同 CPU 模块之间的信息交互。每个CPU和一块内存组成一个Node。
NUMA模型和Mysql的问题
由于Mysql的数据是存储在磁盘上的,访问磁盘的速度很慢,所以Innodb有一个很大的缓存区域叫做buffer-pool,用来缓存一些常用的热点数据,这个区域一般都比较大,会占用系统的至少1G的内存,当然这个可以配置,不过buffer-pool越大性能也就越好。NUMA的CPU一般会使用临近的Node的内存,这样速度会快一点,但是当临近的Node的内存耗尽时,NUMA默认的策略不是去使用其他Node的内存,而是选择swap区域,把内存的数据换出到磁盘,这样以来mysql访问内存的数据时就会比较慢。
分段机制
在8086处理器诞生之前,内存寻址方式就是直接访问物理地址。8086处理器为了寻址1M的内存空间,把地址总线扩展到了20位。但是,一个尴尬的问题出现了,ALU的宽度只有16位,也就是说,ALU不能计算20位的地址。为了解决这个问题,分段机制被引入,登上了历史舞台。
为了支持分段,8086处理器设置了四个段寄存器:CS, DS, SS, ES.每个段寄存器都是16的,同时访问内存的指令中的地址也是16位的。但是,在送入地址总线之前,CPU先把它与某个段寄存器内的值相加。这里要注意:段寄存器的值对应于20位地址总线的中的高16位,所以相加时实际上是16位内存地址(即段内偏移值)的高12位与段寄存器中的16位相加,而低4位保留不变,这样就形成一个20位的实际地址,也就实现了从16位内存地址到20位实际地址的转换,或者叫“映射”。

实际分段机制寻址过程:

实际寻址过程是CPU拿到一个32位的逻辑地址,CPU会判断这个逻辑地址是在局部段描述符表(LDT还是GDT中),从而选择拿到寄存器中的段选择符,再根据偏移量拿到该段的物理地址的首地址。因为分段机制在linux也可以说没有用到,所以页简单带过。
分页机制
分页机制是linux的内存管理机制,所以会详细的介绍。
分页的基本方法是将地址空间人为地等分成某一个固定大小的页;每一页大小由硬件来决定,或者是由操作系统来决定(如果硬件支持多种大小的页)。目前,以大小为4KB的分页是绝大多数PC操作系统的选择.
页
页:为了更高效和更经济的管理内存,线性地址被分为以固定长度为单位的组,成为页。页内部连续的线性地址空间被映射到连续的物理地址中。这样,内核可以指定一个页的物理地址和对应的存取权限,而不用指定全部线性地址的存取权限。这里说页,同时指一组线性地址以及这组地址包含的数据。
页框
页框:分页单元把所有的 RAM 分成固定长度的页框(page frame)(有时叫做物理页)。每一个页框包含一个页(page),也就是说一个页框的长度与一个页的长度一致。页框是主存的一部分,因此也是一个存储区域。区分一页和一个页框是很重要的,前者只是一个数据块,可以存放在任何页框或磁盘中。
页表
页表:把线性地址映射到物理地址的数据结构称为页表(page table)。
寻址过程
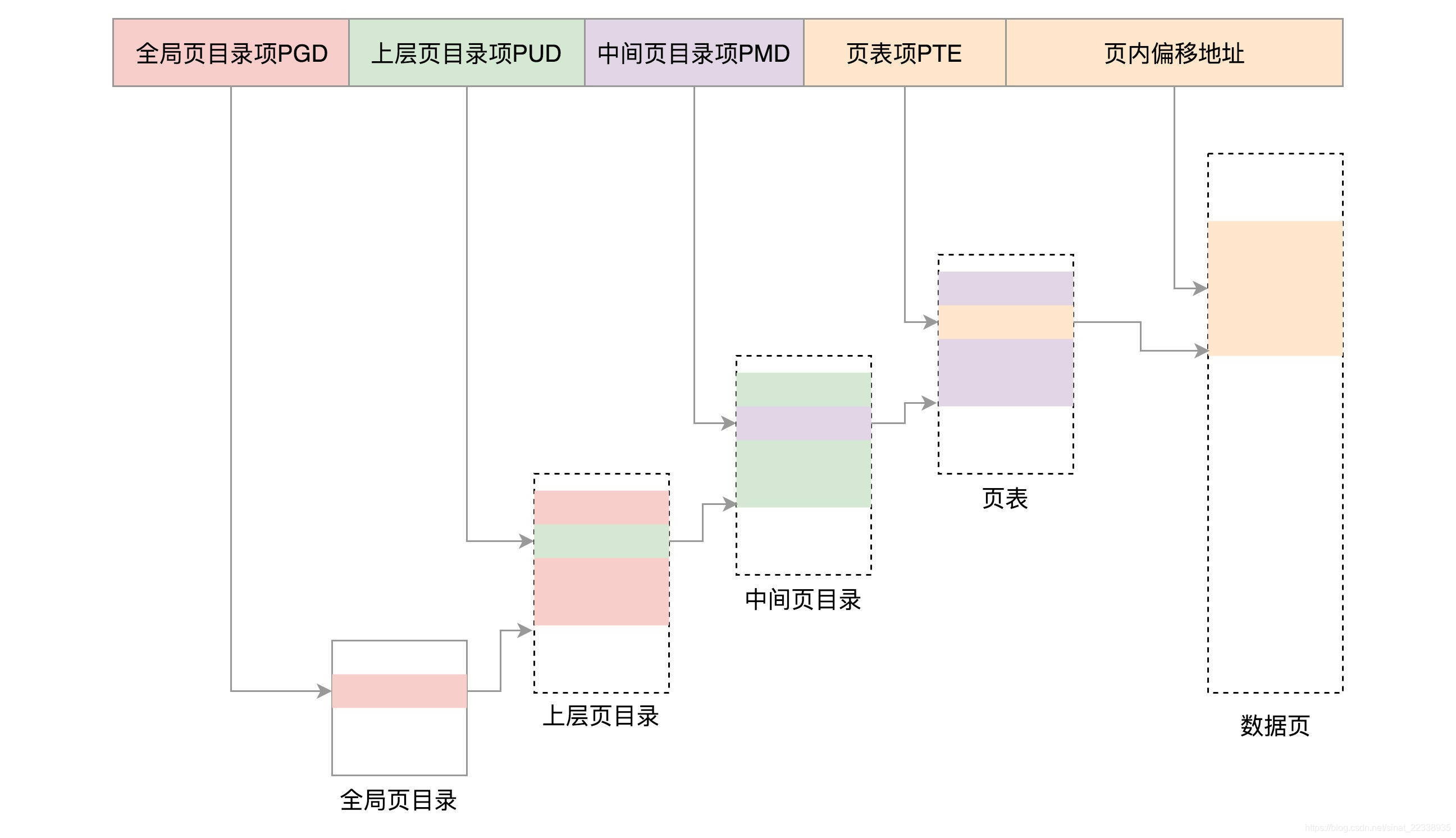
在32位的机器上,一般会把32位划分成三个段,就是目录、页表、偏移量。
在实际寻址的时候,CPU接受到一个32位的逻辑地址,根据然后从CR3寄存器中拿到Page Directory在内存中的首地址,再根据逻辑地址中的目录拿到Page Table在内存中的首地址,跟根据逻辑地址中的Table拿到Offset Table中的首地址,最后根据偏移量拿到最终的物理地址。说了这么多其实就说了一个重点,就是从寄存器中拿到一个首地址,再根据相应的偏移量拿到下一个表的首地址。所以目录、页表、偏移量都是相对的偏移量,不用死记。

那么问题来了,为什么寻址要用三级页表呢?为什么不直接用一个页表寻址呢?
因为如果只使用一级页表,那么每个页的大小是2^12=4K,一级页表的个数就是2^20,每个条目(也叫PDE)4个字节,那么维护一个页表就需要4M,每个进程都需要一个页表来维护,如果计算机有100个进程,就需要400M的大小。如果采用多级页表可以把20分为两个10位,也就是10+10+12,这样当二级页表里面整个页表都没有使用到时,就不用建立二级页表和三级页表,这样就大大节省了页表占用的内存空间。
64位分页
64位机器寻址过程:

其实64位的寻址过程和32位的相比,只不过是多了几级页表。
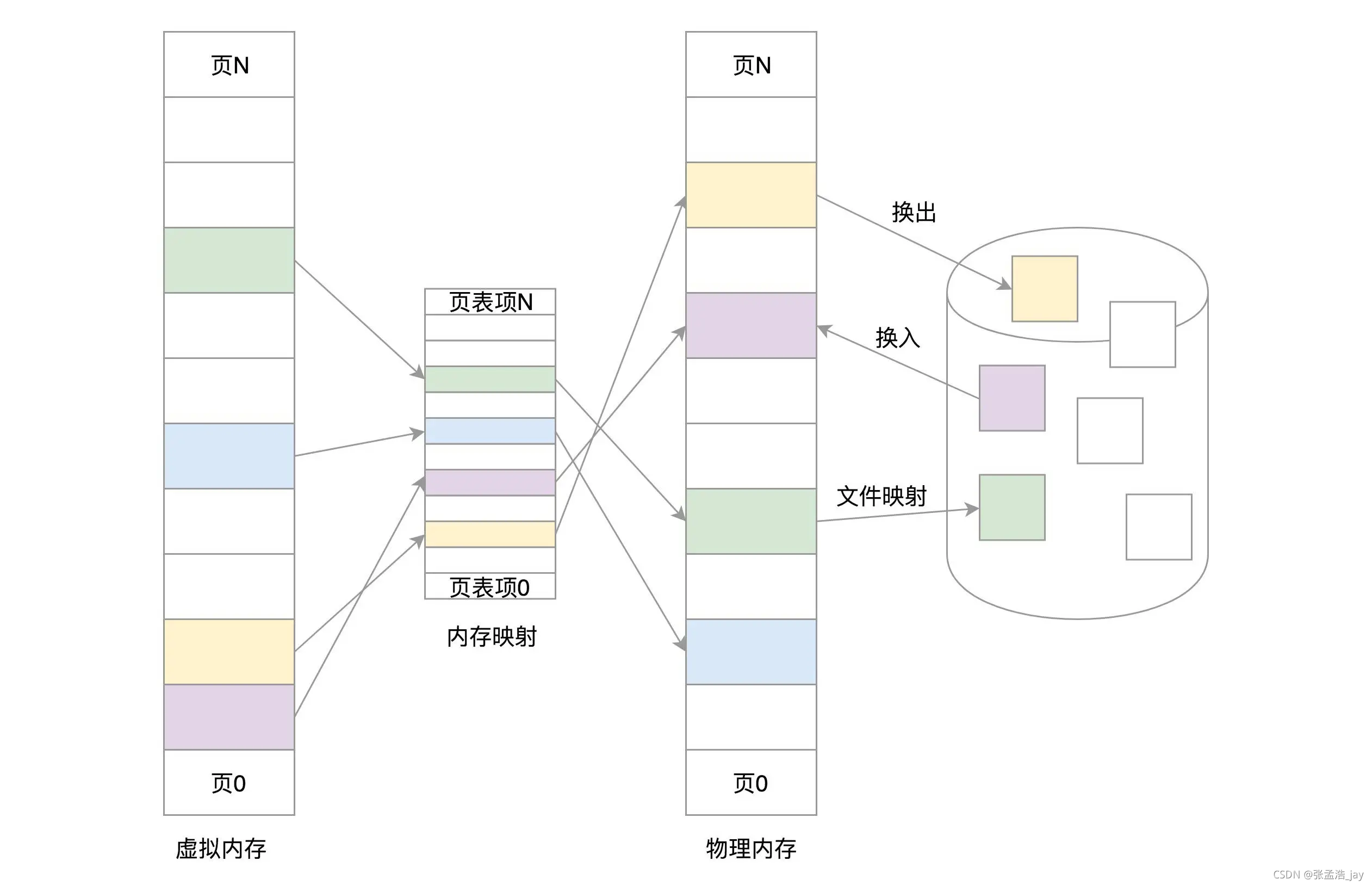
页面置换算法
https://www.cnblogs.com/fkissx/p/4712959.html
总结
在分页机制中,我们能看出来系统采用了时间换空间的方法,因为采用了多级页表节省了内存空间导致每次寻址至少要进行三次,因为每次寻址都会在内存中找到相应的页表,最后寻址到物理内存。
PAE技术
前面提到了,32位的机器最大的能支持的内存只有2^32=4G,但是我们会常常看到一些32的机器可以加内存到8G、16G,这就是PAE技术的出现。
早期Intel处理器从80386到Pentium使用32位物理地址,理论上,这样可以访问4GB的RAM。然而,大型服务器需要大于4GB的RAM来同时运行数以千计的进程,近几年来这对Intel造成了压力,所以必须扩展32位80x86所支持的RAM容量。
Intel通过在它的处理器上把管脚数从32增加到36已经满足了这些需求,可以寻址64GB。同时引入了一种新的分页机制PAE(Physical Address Extension,物理地址扩展)把32位线性地址转换为36位物理地址才能使用所增加的物理内存,通过设置CR4的第5位来开启对PAE的支持。引入PAE就是为了访问大于4GB的RAM,线性地址仍然是32位,而物理地址是36位。
PAE寻址每页4K大小:

PAE寻址每页2M大小:

为什么32位的逻辑地址可以映射到36位的物理地址?
因为开启PAE分页的话,每个进程会保存多套页表,这样一来,进程可以根据需要改变CR3中的值去访问不同的页表。也就是说,进程在运行过程中会修改CR3的值从而指向不同的页表来访问不同的物理地址。
TLB技术
在两级页表中,每次访问内存至少都要经过三次内存访问才能拿到物理地址,这样一来效率会变得很低,所以就有了TLB(Translation Lookaside Buffer)技术。TLB是MMU(负责把虚拟地址转换成物理地址)一块高速缓存,用来缓存页号(32位地址中的前20位称为页号)对应的数据(包括物理地址和访问控制信息)。

- CPU把一个虚拟地址交给MMU。
- MMU查找TLB是否有该虚拟地址的缓存,若有则TLB hit,直接从TLB中拿到页框的物理地址。
- 若TLB miss,执行TTW(Translation Table Walk简称TTW,就是从页表中查找物理地址),然后更新TLB。
- 查询Cache中是否有Page数据,上面拿到只不过是页框的物理地址,还要拿到真正的数据。
- 若Cache hit则从Cache中拿到数据,否则从内存中拿到数据,更新Cache。
PCID技术
因为每个CPU有一个TLB,所以每次不同的进程被CPU选中执行的时候,TLB里面的数据都要被刷新掉,所以刚开始进程运行的时候TLB里面的数据都是空的,等运行时间长了,TLB才会慢慢被填满,TLB的命中率才会变高。这样一来TLB的性能就不是很好,因为每次都要重新开始添加数据,所以就有了PCID技术。
每个进程都要一个自己的PCID来唯一表示该进程,这样一来,TLB存储数据的时候会加上PCID这个标识来表示该条数据是哪个进程的,这样一来就不需要每次切换进程的时候都刷新TLB,但PCID技术在linux很后面的版本才开始支持的,因为PCID技术同样存在问题。
当我们更新一个进程的TLB缓存的时候,相应的其他CPU里面的TLB也需要做更新,这样一来性能并没有很好的提升。
伙伴系统
在linux中,前面分页机制只是建立的从虚拟地址到物理地址的映射关系,但还要考虑物理内存如何分配,伙伴系统的产生页解决了linux系统的外碎片的问题。
伙伴系统把内存按照2^n次幂分为大小不同的内存块,然后使用链表把各个内存块链接起来。

举例:假设RAM有1M,当系统需要一个63K的内存块时,首先会去找2^6的链表中找是否有空闲的内存,若没有则去2^7的链表中去找,依次类推,当找到2^20链表中时,就会把分裂2^20中的一个内存块假设位a1,a2,那么a1和a2就互为伙伴,a1继续分裂,a2就加入到2^19=512k的链表中,a1分裂至2^n-1<63K<=2^n。
slab机制
slab是Linux操作系统的一种内存分配机制。其工作是针对一些经常分配并释放的对象,如进程描述符等,这些对象的大小一般比较小,如果直接采用伙伴系统来进行分配和释放,不仅会造成大量的内碎片,而且处理速度也太慢。而slab分配器是基于对象进行管理的,相同类型的对象归为一类(如进程描述符就是一类),每当要申请这样一个对象,slab分配器就从一个slab列表中分配一个这样大小的单元出去,而当要释放时,将其重新保存在该列表中,而不是直接返回给伙伴系统,从而避免这些内碎片。slab分配器并不丢弃已分配的对象,而是释放并把它们保存在内存中。当以后又要请求新的对象时,就可以从内存直接获取而不用重复初始化。