Deeplab V1
Background:
CNN的一个特性是invariance(不变性),这个特性使得它在high-level的计算机视觉任务比如classification中,取得很好的效果。但是在semantic segmentation任务中,这个特性反而是个障碍。毕竟语义分割是像素级别的分类,高度抽象的空间特征对如此low-level并不适用。
所以,要用CNN来做分割,就需要考虑两个问题,一个是feature map的尺寸,以及空间不变性。
Solution:
对于第一个问题,回忆一下之前的FCN,FCN通过反卷积层(现在反卷积层似乎有了更好的叫法,但是这里暂时沿用反卷积这个名字)将feature map还原到原图尺寸。
可是feature map为什么会变小呢?因为stride的存在。于是DeepLab就考虑,我直接把stride改成1,feature map不就变大了吗。将stride改小,确实能得到更加dense的feature map这个是毋庸置疑的,可是却也带来了另外一个问题即receptive field(RF)的改变问题。receptive field是直接和stride挂钩的,即
RFi+1 = RFi + (kernel-1)*stride (i越小越bottom)
按照公式,stride变小,要想保持receptive field不变,那么,就应该增大kernel size。于是就有了接下来的hole算法。
一开始,pooling layer stride = 2,convolution layer kernel size = 2,convolution layer第一个点的receptive field是{1,2,3,4},size为4

为了得到更加dense的feature map,将pooling layer stride改为1,如果这个时候保持convolution layer的kernel size不变的话,可以看到,虽然是更dense了,可是不再存在RF = {1,2,3,4}的点了。

当采用hole算法,在kernel里面增加“hole”,kernel size变大,相当于卷积的时候跨过stride减小额外带来的像素,RF就保持不变了,当然如果调整hole的size还能得到比原来更大的RF。

这个扩大后的卷积核直观上可以以通过对原卷积核填充0得到,不过在具体实现上填0会带来额外的计算量,所以实际上是通过im2col调整像素的位置实现的,这里不展开,有兴趣的可以看看caffe源码(hole算法已经集成在caffe里了,在caffe里叫dilation) 于是,通过hole算法,我们就得到了一个8s的feature map,比起FCN的32s已经dense很多了。
对于第二个问题,图像输入CNN是一个被逐步抽象的过程,原来的位置信息会随着深度而减少甚至消失。Conditional Random Field (CRF,条件随机场)在传统图像处理上的应用有一个是做平滑。CRF简单来说,能做到的就是在决定一个位置的像素值时(在这个paper里是label),会考虑周围邻居的像素值(label),这样能抹除一些噪音。但是通过CNN得到的feature map在一定程度上已经足够平滑了,所以short range的CRF没什么意义。于是作者采用了fully connected CRF,这样考虑的就是全局的信息了。

另外,CRF是后处理,是不参与训练的,在测试的时候对feature map做完CRF后,再双线性插值resize到原图尺寸,因为feature map是8s的,所以直接放大到原图是可以接受的。
DeepLab V2:DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs
v1之后,Liang-Chieh Chen很快又推出了DeepLab的v2版本。这里就简单讲讲改进的地方。
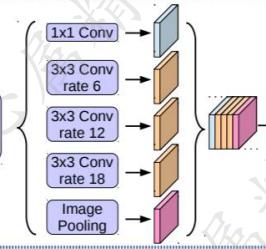
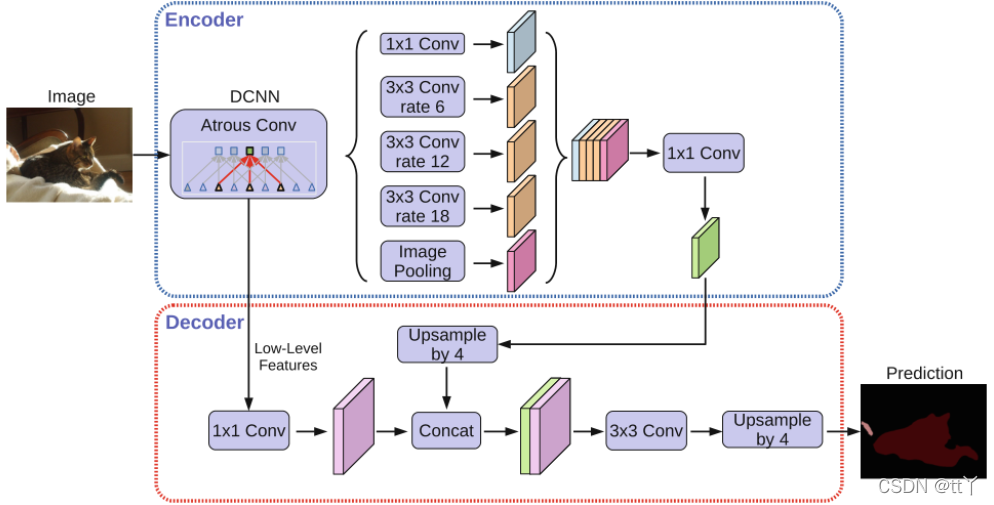
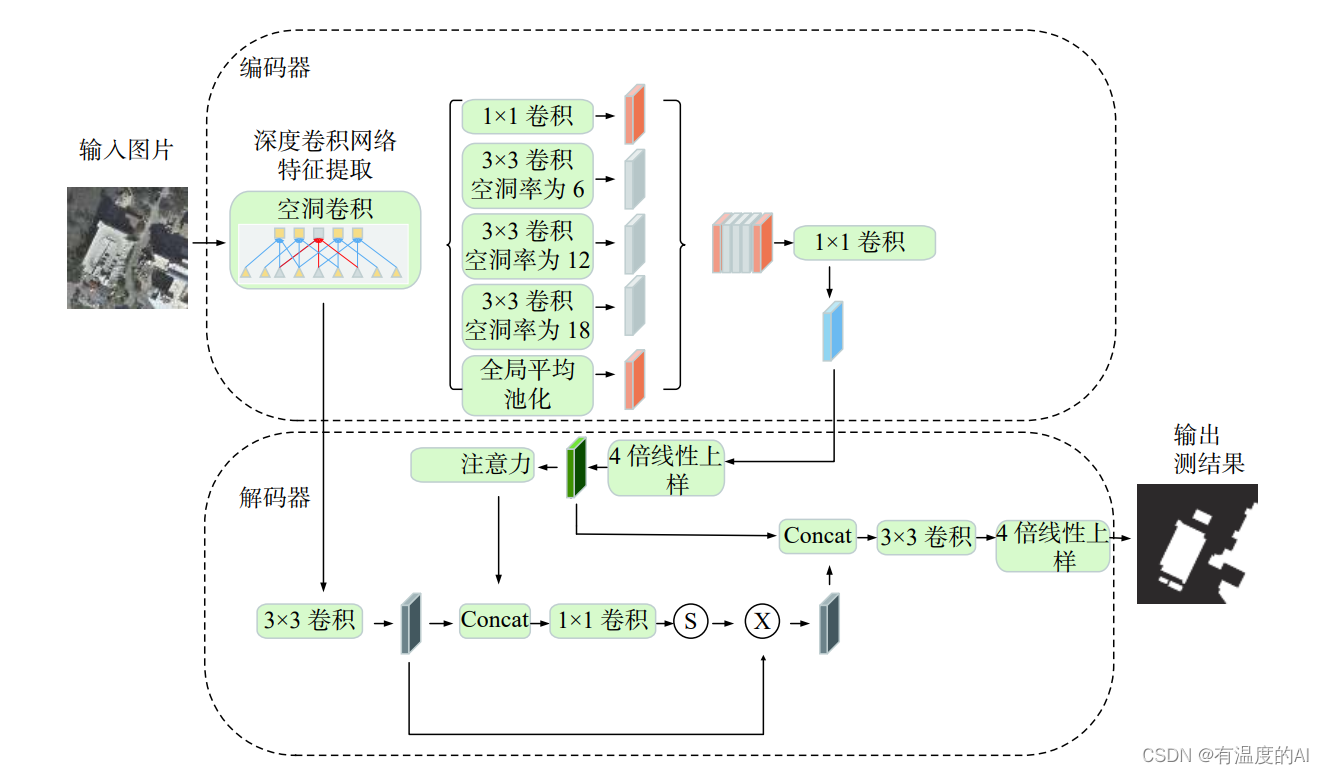
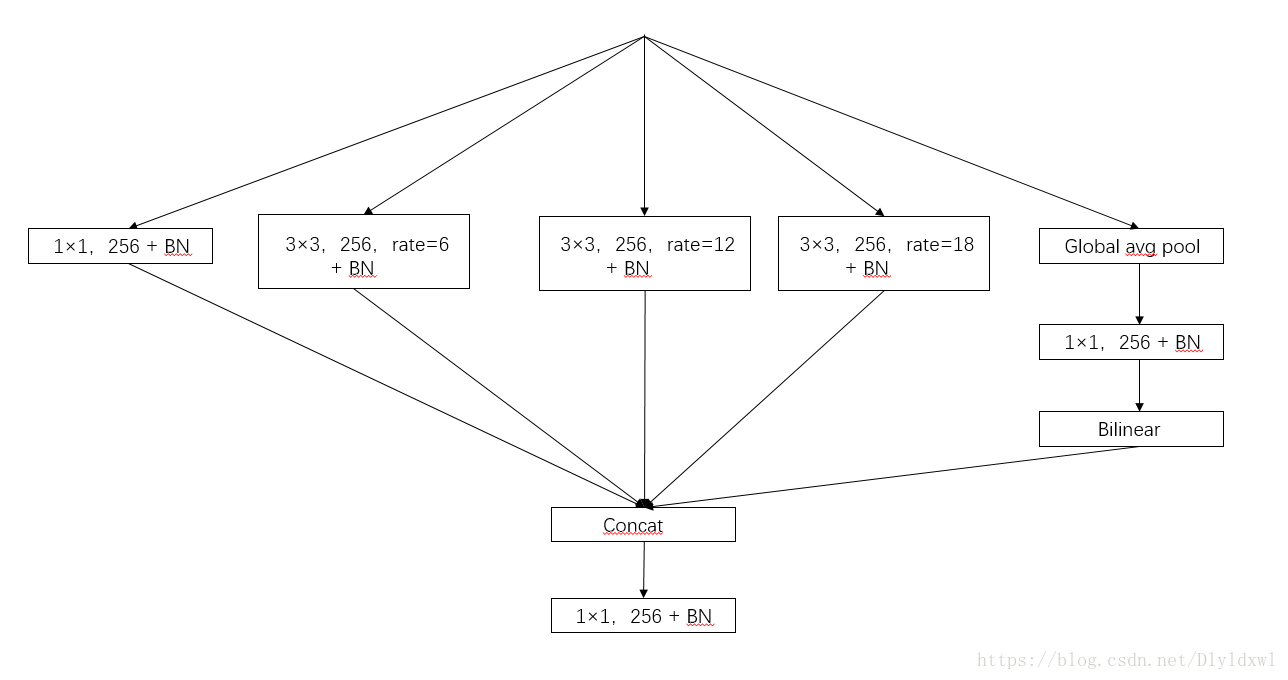
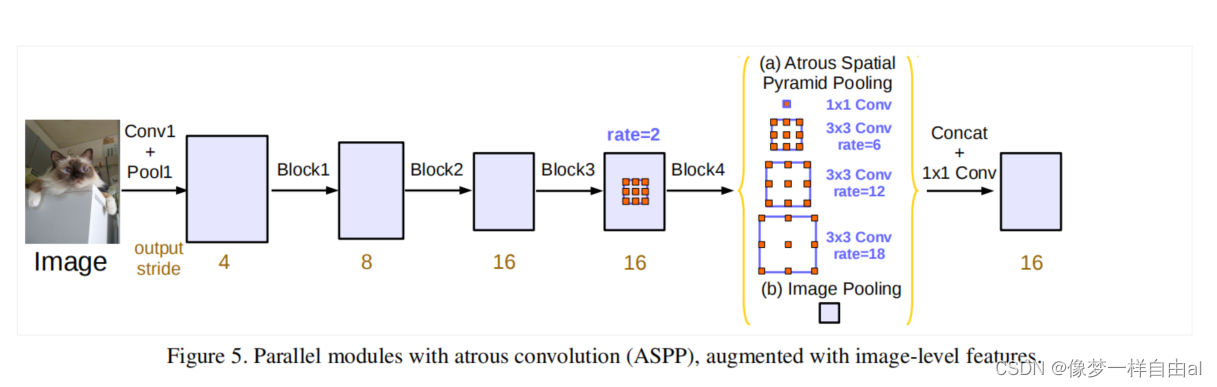
Multi-scale对performance提升很大,而我们知道,receptive field,视野域(或者感受野),是指feature map上一个点能看到的原图的区域,那么如果有多个receptive field,是不是相当于一种Multi-scale?出于这个思路,v2版本在v1的基础上增加了一个多视野域。具体看图可以很直观的理解。

rate也就是hole size
这个结构作者称之为ASPP(atrous spatial pyramid pooling),基于洞的空间金字塔。
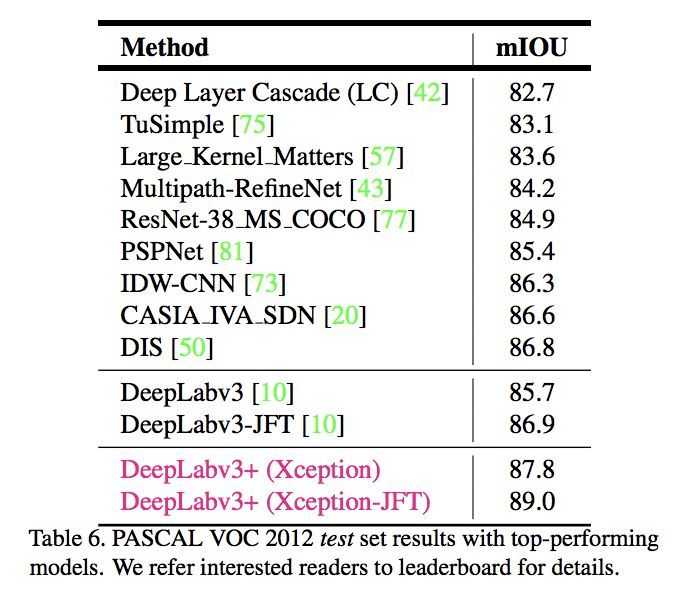
此外,DeepLab v2有两个基础网络结构,一个是基于vgg16,另外一个是基于resnet101的,目前性能是benchmark上的第一名。
本文转自:http://blog.csdn.net/c_row/article/details/52161394











![深度学习论文精读[13]:Deeplab v3+](https://img-blog.csdnimg.cn/img_convert/4a881284941cdcc5d276731f62152f9c.png)